Nova是Openstack最核心的服务,负责维护和管理云环境的计算资源。OpenStack作为Iaas的云操作系统,虚拟机生命周期管理就是通过Nova来实现的。
用途与功能:
架构:
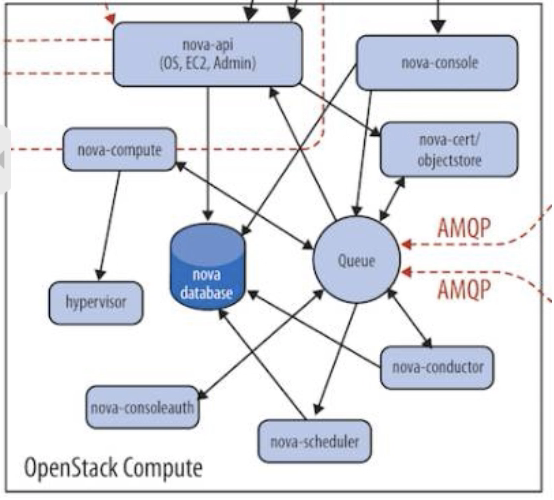
Nova的架构比较复杂,包含很多组件。这些组件以子服务(后台deamon进程)的形式运行,可以分为以下几类:
是整个Nova组件的门户,接收和响应客户的API调用。所有对Nova的请求都首先由nova-api处理。nova-api向外界暴露若干HTTP REST API接口。在keyston e中我们可以查询nova-api的endpoints。
客户端就可以将请求发送到endpoints指定的地址,向nova-api请求操作。当然,作为最终用户的我们不会直接发送Rest API请求。Openstack CLI,Dashboard和其他需要跟Nova交换的组件会使用这些API。
Nova-api对接收到的HTTP API请求会做如下处理:
Nova-api 接收哪些请求?
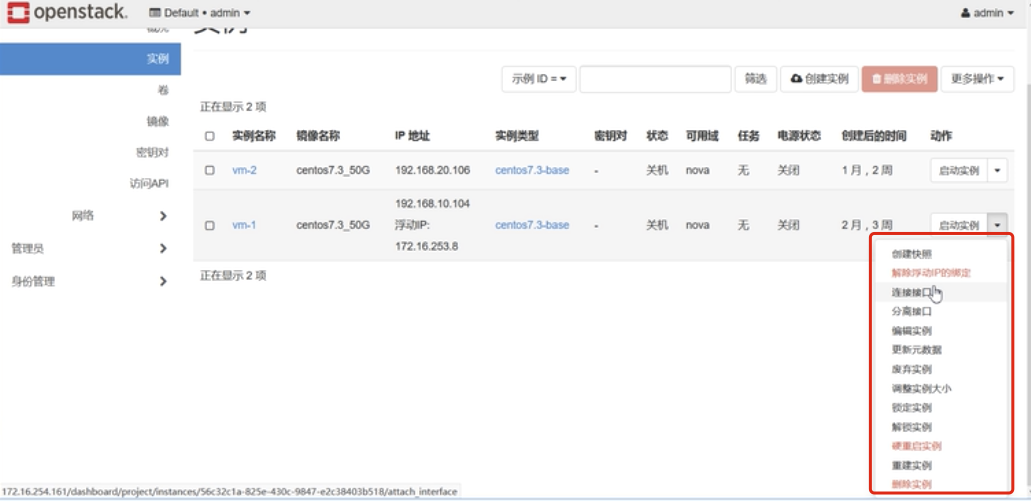
简单的说,只要是跟虚拟机生命周期相关的操作,nova-api都可以响应。大部分操作都可以在Dashboard上找到。打开Instance管理界面能看到,先登陆到openstack的管理后台,点击“实例”,能看到当前管理的kvm实例,在动作下拉列表能看到一组操作,这些操作都能通过调用nova-api来实现。
虚机调度服务,负责决定在哪个计算节点上运行虚机。创建Instance时,用户会提出资源需求,例如CPU、内存、磁盘各需要多少。OpenStack将这些需求定义在flavor中,用户只需要指定用哪个flavor就可以了。
openstack是一个大的集群架构, 它下面管理很多kvm虚拟化节点,这些节点叫做“计算节点”。
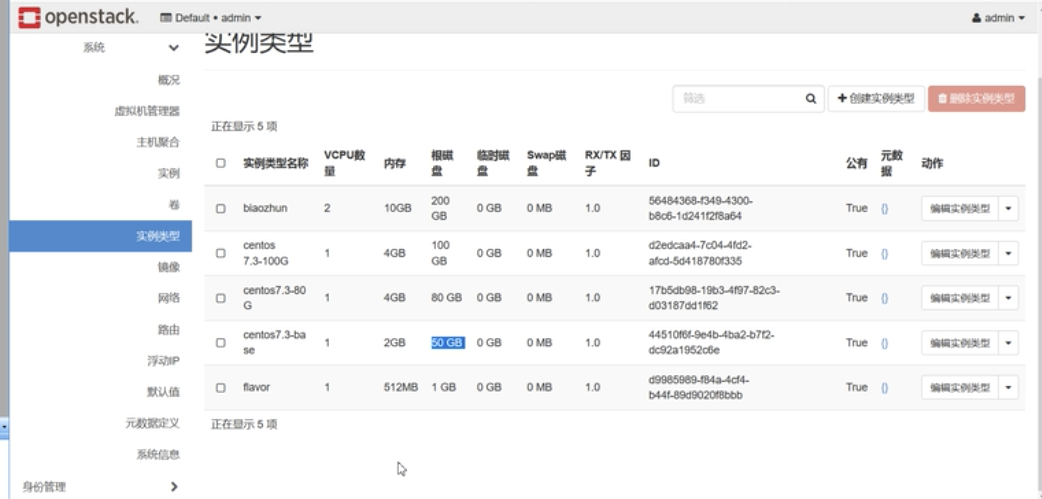
我们在openstack后台可以配置实例类型(flavor),也就是一个什么样的配置是一条记录,也就是要配置一组“实例的模板”,当用户需要一个具体配置的虚机时,可以从这个实例类型列表中匹配。
下面介绍nova-scheduler是如何实现调度的。在/etc/nova/nova.conf中,nova通过driver=filter_scheduler这个参数来配置nova-scheduler。
driver=filter_schedulerFilter scheduler是nova-scheduler默认的调度器,调度过程分为两步:
nova允许使用第三方scheduler,配置scheduler_driver即可。这又一次体现了Openstack的开放性。Scheduler可以使用多个filter依次进行过滤,过滤之后的节点再通过计算权重选出最合适的节点。
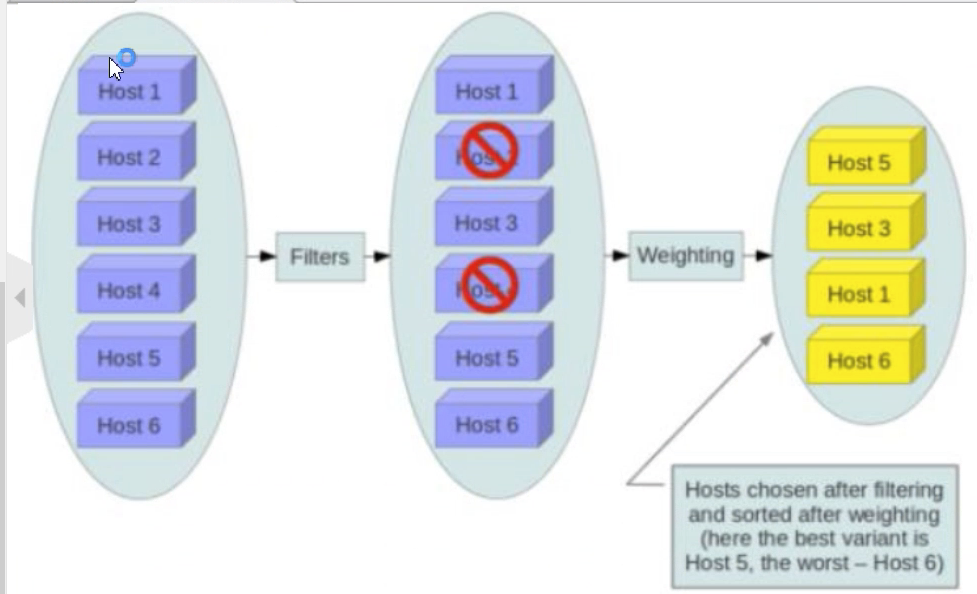
集群中有6个计算节点,根据用户选择的实例模板配置,筛选支持的计算节点,比如筛选出了4个。怎么获取最优的那一个节点呢?获取资源剩余做多的计算节点,用于启动虚拟机。
当Filter scheduler需要执行调度操作时,会让filter对计算节点进行判断,filter返回True或False。经过前面一堆filter的过滤,nova-scheduler选出了能够部署instance的计算节点。
如果有多个计算节点通过了过滤,那么最终选择哪个节点呢?
Scheduler会对每个计算节点打分,得分最高的获胜。打分的过程就是weight,翻译过来就是计算权重值,那么scheduler是根据什么来计算权重值呢?
目前nova-scheduler的默认实现是根据计算节点空闲的内存量计算权重值:空闲内存越多,权重越大,instance将被部署到当前空闲内存最多的计算节点上。
nova-compute是管理虚拟机的核心服务,在计算节点上运行。通过调用Hypervisor API实现节点上的instance的生命周期管理。OpenStack对instance的操作,最后都是交给nova-compute来实现的。nova-compute与Hypervisor一起实现Openstack对instance生命周期的管理。
通过Driver架构支持多种Hypervisor。Hypervisor是计算节点上跑的虚拟化管理程序,虚机管理最底层的程序。不同虚拟化技术提供自己的Hypervisor。常用的Hypervisor有KVM, Xen,VMWare等。nova-compute为这些Hypervisor定义了统一的接口,Hypervisor只需要实现这些接口,就可以Driver的形式即插即用到OpenStack系统中。下面是Nova Driver的架构示意图。
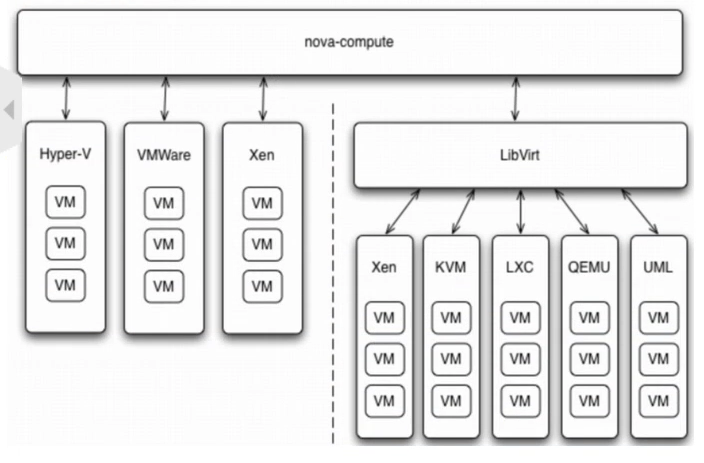

上图中的yunwei4机器是一个计算节点,上面部署了nova-compute服务,kvm虚拟机。我们可以创建虚拟机,但是我们不是通过在上面直接执行kvm的命令,而是通过nova-computer。它会调用kvm提供的api去管理instance。
nova-compute经常需要更新数据库,比如更新和获取虚机的状态。出于安全性和伸缩性的考虑,nova-compute并不会直接访问数据库,而是讲这个任务委托给nova-conductor。
nova-console: 用户可以通过多种方式访问虚机的控制台;
nova-novncproxy: 基于Web浏览器的VNC访问;
nova-spicehtml5proxy: 基于HTML5浏览器的SPICE访问;
nova-xvpnvncproxy:基于java客户端的VNC访问;
nova-consoleauth: 负责对访问虚机控制请求提供Token认证;
nova-cert: 提供x509证书支持;
Nova会有一些数据需要存放到数据库中,一般使用Mysql。数据库安装在控制节点上。Nova使用命令为“nova”的数据库。
在前面我们了解到Nova包含众多的子服务,这些子服务之间需要相互协调和通信。为解耦各个子服务,Nova通过Message Queue作为子服务的信息中转站。所以在架构图上我们看到了子服务之间没有直接的连线,是通过Message Queue联系的。
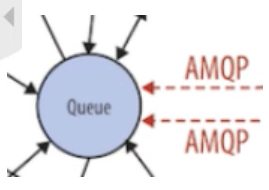
OpenStack默认是用RabbitMQ作为Message Queue。MQ是OpenStack的核心基础组件,我们后面也会详细介绍。
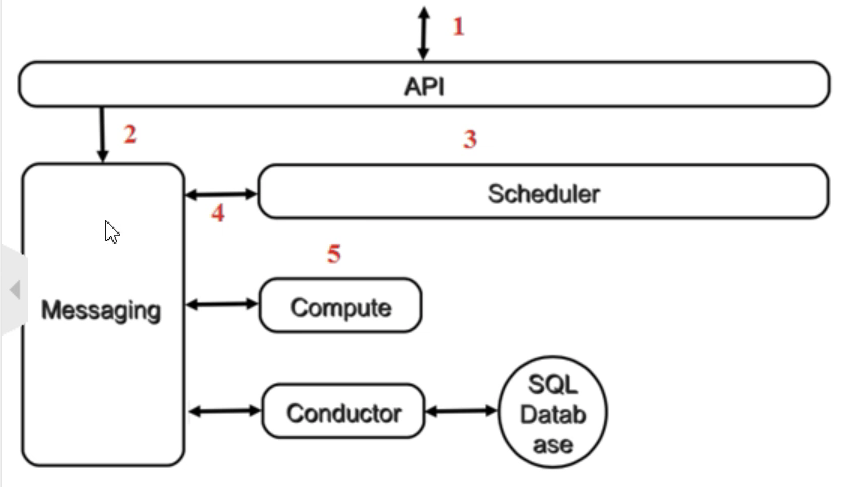
以上是创建虚机最核心的步骤,这几个步骤向我们展示了nova~* 子服务之间的协作的方式,也体现了OpenStack整个系统的分布式设计思想,掌握了这种思想对我们深入理解Openstack会非常有帮助。
创建mysql数据库,一共三个, nova-api、nova、nova-cell0.
创建三个mysql用户并分配权限,能访问上面三个库。
openstack创建一个用户叫nova。给nova用户添加service项目中的角色admin
创建一个nova服务。
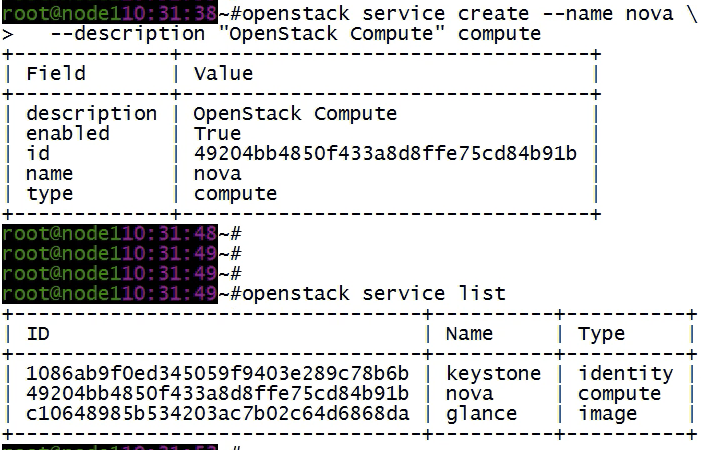
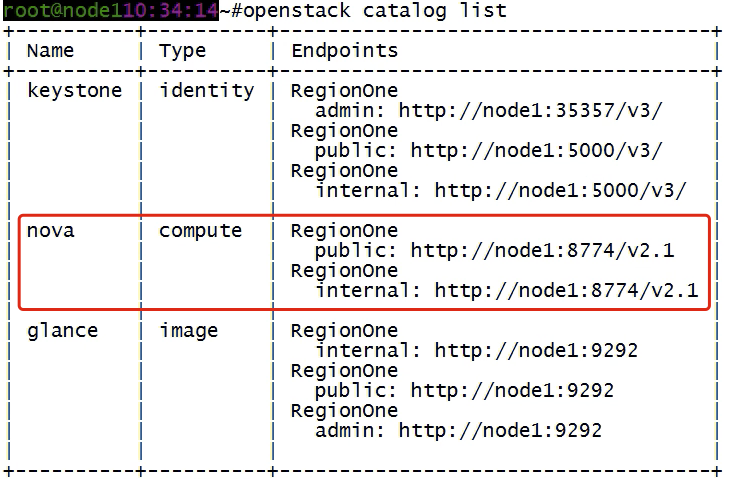
创建nova服务端点endpoint,端口8778,要三个,分别是public、internal、admin
openstack创建一个用户叫placement。给用户添加service项目中的角色admin 。
创建服务叫placement。
给placement服务创建服务端点,端口8778,要三个,分别是public、internal、admin
当nova和placement配置好了以后,可以安装nova了。

修改配置文件 /etc/nova ,具体看官方文档说明。
启动nova相关的五个服务。
我们分为控制节点和计算节点。一个节点可以即是控制节点又是计算节点,公用nov.conf。
计算节点要配置vnc控制台地址,要确保机器上有kvm等虚拟化。
我正在使用OpenShift,我想知道Go语言(golang)的.htaccess文件应该放在哪里。我用其他语言尝试了所有位置,但都没有用。编辑:是的,我用Go语言cartridge创建了一个1smallgear应用。一切都是默认的,所以它是TheGoCartridge 最佳答案 我猜你正在使用Gocartridge;据我所知,.htaccess文件应该在网络服务器上。您的Web服务器应该在主要设备上运行,但如果没有任何其他信息,很难提供有意义的答案。 关于使用Go的OpenStack的
1、搭建和使用OpenStack,至少安装以下模块:Horizon、Keystone、Nova、Neutron、Glance、Cinder。;2、操作和熟悉各模块功能和相互关系,加深对课本相关概念理解;3、在搭建好的OpenStack,使用openstack功能创建一台虚拟机给假想用户使用;4、让假想用户,通过自己的凭证,使用该虚拟机;5、记录实验步骤,精确描述实验遇到的问题,以及你解决该问题所使用的方法;搭建环境主机:CPU:Intelcorei5-8265U机带RAM:8.00GB虚拟机:VmwareWorkstationProCentos7内存:10GB硬盘:40GB虚拟机ip:192.
视频讲解:keystone简单来说是用来做认证的概念详解:User:使用Openstack组件的客户端可以是人、服务。系统,任何访问Openstack组件的客户端都需要有一个用户名Project:1、是一个人或服务所拥有的资源集合。不同的Project之间资源是隔离的,资源可以设置配额;2、在一个Project中可以包含多个User,每个User都会根据权限的划分来使用Project中的资源。3、User访问Project的资源前,必须要与该Project关联,并且指定User在Project下的Role,一个关联即:Project-User-RoleRole:1、用于权限的划分。通过给Use
目录ArbitrumArbitrumOneArbitrumNitroArbitrumNovaNovaVSOneArbitrumArbitrum 是OffchainLabs推出的一款Layer2扩容方案,通过采用多轮交互型设计的OptimisticRollup方案,以实现对以太坊网络的扩容目标。Arbitrum基于OptimisticRollup打造,通过多轮交互型欺诈性证明保证同步到Layer1的数据是有效的。目前Arbitrum技术栈总体的方案如下图。ArbitrumOneArbitrumOne是ArbitrumOptimisticRollup方案具体应用的一条公链,也是一条独立的Evm兼容
我想为Openstack做贡献。牢记这一点,我在WindowsXP上使用Ubuntu14:0的虚拟机上克隆了devstack。在此之后,我运行了./stack.sh。它不工作。我无法启动实例。我尝试删除devstack并再次克隆git。即使现在它也不起作用。gitclonehttps://github.com/openstack-dev/devstack.git我收到以下错误。我以管理员身份使用我的计算机。sudomysql-uroot-pa2350bf7c5f41b70a808-h127.0.0.1-e'GRANTALLPRIVILEGESON*.*TO'\''root'\''@'\
LVM后端创建LVM的RedHat管理介绍:https://access.redhat.com/documentation/zh-cn/red_hat_enterprise_linux/7/html/logical_volume_manager_administration/indexcinder_volume_group:“cinder-volumes”pvcreate/dev/sdb#sdb是需要干净的存储位vgcreatecinder-volumes/dev/sdb使用过滤器控制LVM设备扫描/etc/lvm/lvm.conffilter=[“a/sdX/”,“r/.*/”]通过在lvm
COA考试模拟题version:201911ExamTasksYouarethecloudadministratorofafictitiouscompanynamedESCloud.YouhavebeentaskedwithsettingupOpenstackEnvironmentsformarketingandfinancedepartments.您是一家名为ESCloud的虚拟公司的云管理员。您的任务是为市场和财务部门设置Openstack环境。Task1Thecompanyhastwodepartments,namedmarketingandfinance.Foreachofthetwo
今天继续给大家介绍Linux运维相关知识,本文主要内容是openstackNova节点基本原理。一、OpenstackNova节点简介Nova是openstack中最早出现的模块之一,主要是为openstack提供计算服务。在openstack中,Nova又分为计算节点和控制节点。我们把安装有nova-compute的节点称为计算节点,其他的节点称为控制节点。nova的计算节点只负责创建虚拟机,而nova的控制节点负责控制。Nova主要有以下服务:1、API。负责接收和响应外部请求,支持openstackapi、EC2(亚马逊云)API等。2、Cert。负责进行身份认证。3、Scheduler
OpenStack中各大组件的作用Glance:负责管理镜像(镜像的上传、删除、下载)Swift:提供镜像存储的空间Nova:负责配额的修改、启动云主机(实例)、创建密钥对、绑定弹性IP等Keystone:提供租户以及用户的管理Neutron:负责网络、子网、安全组、安全组规则、浮动IP等Cinderr:提供云硬盘将small.img镜像上传到控制节点通过Mobaxterm或者WinSCP将镜像文件上传到控制节点[root@Controller~]#lltotal348452......drwxr-xr-x.2rootroot6Jan1209:21Public-rw-r--r--1rootro
目录一.novnc简介二.openstack中的novnc工作流程三.源码分析一.novnc简介 noVNC是一个支持HTML5的VNC客户端,主要作用就是与远端的vncserver进行互通,从而实现对于远端主机的控制。说白了,我们可以通过VNC客户端或者支持HTML5的浏览器访问远端安装了vncserver的服务器桌面从而进行控制。 但是vncserver发送的数据都是基于TCP之上的,而novnc处理的数据都是基于WebSocket之上的数据,所以vnc客户端无法直接与vncserver进行通讯,因此中间加入了一个代理服务器:WebSockify来实现WebSockify和TC