🌠作者:@阿亮joy.
🎆专栏:《数据结构与算法要啸着学》
🎇座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根
目录
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
- void push(int x) 将元素 x 压入栈顶。
- int pop() 移除并返回栈顶元素。
- int top() 返回栈顶元素。
- boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。
注意:
- 你只能使用队列的基本操作 —— 也就是 push to back、peek/pop from front、size 和 is empty
这些操作。- 你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 ,只要是标准的队列操作即可。
示例:
输入:
["MyStack", "push", "push", "top", "pop", "empty"]
[[], [1], [2],[], [], []]
输出:
[null, null, null, 2, 2, false]解释:
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // 返回 2
myStack.pop(); // 返回 2
myStack.empty(); // 返回False
提示:
- 1 <= x <= 9
- 最多调用100 次 push、pop、top 和 empty
- 每次调用 pop 和 top 都保证栈不为空
进阶:你能否仅用一个队列来实现栈。
因为队列是先进先出的结构,而栈是后进先出的结构,那我们用两个队列实现一个栈呢?其实可以这样子实现:当入数据的时候,往不为空的队列入,保持另一个队列为空;当出数据的时候,依次出队头的数据,转移到另一个队列中保存,只剩一个数据的时候,pop 掉。如下图所示:

将这篇博客实现的队列拷贝过来,然后将要求的函数接口就行了。具体代码见下方:
typedef int QDataType;
typedef struct QueueNode
{
QDataType data;
struct QueueNode* next;
}QNode;
typedef struct Queue
{
QNode* head; // 头指针
QNode* tail; // 尾指针
int size; // 节点的个数
}Queue;
void QueueInit(Queue* pq);
void QueueDestroy(Queue* pq);
void QueuePush(Queue* pq, QDataType x);
void QueuePop(Queue* pq);
QDataType QueueFront(Queue* pq);
QDataType QueueBack(Queue* pq);
bool QueueEmpty(Queue* pq);
int QueueSize(Queue* pq);
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = pq->tail = NULL;
pq->size = 0;
}
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* del = cur;
cur = cur->next;
free(del);
}
pq->head = pq->tail = NULL;
}
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
else
{
newnode->data = x;
newnode->next = NULL;
}
// 队列中没有节点
if (pq->tail == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
pq->size++;
}
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
// 队列中只有一个节点
if (pq->head->next == NULL)
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
QNode* del = pq->head;
pq->head = pq->head->next;
free(del);
//del = NULL;
}
pq->size--;
}
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->data;
}
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
//return pq->head == NULL && pq->tail == NULL;
}
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
//核心思路:
//1.入数据,往不为空的队列入,保持另一个队列为空
//2.出数据的时候,依次出队头的数据,转移到另一个队列中保存
//只剩一个数据时,pop掉
//不能改变队列的结构,只能调用提供的函数接口
typedef struct
{
Queue q1;
Queue q2;
} MyStack;
MyStack* myStackCreate()
{
// 注意局部变量,出了作用域会销毁
MyStack* st = (MyStack*)malloc(sizeof(MyStack));
//初始化队列
QueueInit(&st->q1);
QueueInit(&st->q2);
return st;
}
void myStackPush(MyStack* obj, int x)
{
// 往不为空的队列中入数据
if(!QueueEmpty(&obj->q1))
{
QueuePush(&obj->q1, x);
}
else
{
QueuePush(&obj->q2, x);
}
}
int myStackPop(MyStack* obj)
{
// 找出谁是空队列
Queue* empty = &obj->q1;
Queue* nonEmpty = &obj->q2;
if(!QueueEmpty(&obj->q1))
{
empty = &obj->q2;
nonEmpty = &obj->q1;
}
// 非空队列前N-1个数据导入空队列,剩下的一个数据就是栈顶元素
while(QueueSize(nonEmpty) > 1)
{
QueuePush(empty, QueueFront(nonEmpty));
QueuePop(nonEmpty);
}
int top = QueueFront(nonEmpty);
QueuePop(nonEmpty);
return top;
}
int myStackTop(MyStack* obj)
{
if(!QueueEmpty(&obj->q1))
{
return QueueBack(&obj->q1);
}
else
{
return QueueBack(&obj->q2);
}
}
bool myStackEmpty(MyStack* obj)
{
return QueueEmpty(&obj->q1) && QueueEmpty(&obj->q2);
}
void myStackFree(MyStack* obj)
{
QueueDestroy(&obj->q1);
QueueDestroy(&obj->q2);
free(obj);
}

用一个栈如何实现队列呢?其实也很简单,当一个数据入队时,先将该数据入队,然后再将在该数据前面的数据依次 pop 掉,然后又依次入队,就能实现后进先出的栈结构了。如下图所示:

typedef int QDataType;
typedef struct QueueNode
{
QDataType data;
struct QueueNode* next;
}QNode;
typedef struct Queue
{
QNode* head; // 头指针
QNode* tail; // 尾指针
int size; // 节点的个数
}Queue;
void QueueInit(Queue* pq);
void QueueDestroy(Queue* pq);
void QueuePush(Queue* pq, QDataType x);
void QueuePop(Queue* pq);
QDataType QueueFront(Queue* pq);
QDataType QueueBack(Queue* pq);
bool QueueEmpty(Queue* pq);
int QueueSize(Queue* pq);
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = pq->tail = NULL;
pq->size = 0;
}
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* del = cur;
cur = cur->next;
free(del);
}
pq->head = pq->tail = NULL;
}
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
else
{
newnode->data = x;
newnode->next = NULL;
}
// 队列中没有节点
if (pq->tail == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
pq->size++;
}
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
// 队列中只有一个节点
if (pq->head->next == NULL)
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
QNode* del = pq->head;
pq->head = pq->head->next;
free(del);
//del = NULL;
}
pq->size--;
}
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->data;
}
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
//return pq->head == NULL && pq->tail == NULL;
}
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
typedef struct
{
Queue q;
} MyStack;
MyStack* myStackCreate()
{
MyStack* obj = (MyStack*)malloc(sizeof(MyStack));
QueueInit(&obj->q);
return obj;
}
void myStackPush(MyStack* obj, int x)
{
// 数据先入队
QueuePush(&obj->q, x);
// 前面的数据依次出队,再依次入队
int i = 0;
while(i < QueueSize(&obj->q) - 1)
{
int front = QueueFront(&obj->q);
QueuePop(&obj->q);
QueuePush(&obj->q, front);
i++;
}
}
int myStackPop(MyStack* obj)
{
int top = QueueFront(&obj->q);
QueuePop(&obj->q);
return top;
}
int myStackTop(MyStack* obj)
{
int top = QueueFront(&obj->q);
return top;
}
bool myStackEmpty(MyStack* obj)
{
return QueueEmpty(&obj->q);
}
void myStackFree(MyStack* obj)
{
QueueDestroy(&obj->q);
free(obj);
}

请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
- void push(int x) 将元素 x 推到队列的末尾
- int pop() 从队列的开头移除并返回元素
- int peek()返回队列开头的元素
- boolean empty() 如果队列为空,返回 true ;否则,返回 false
说明:
你只能使用标准的栈操作 —— 也就是只有 push to top, peek/pop from top, size, 和 is empty 操作是合法的。你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例 1:
输入:
["MyQueue", "push", "push", "peek", "pop", "empty"]
[[], [1], [2],[], [], []]
输出:
[null, null, null, 1, 1, false]
解释:
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false
提示:
- 1 <= x <= 9
- 最多调用 100 次 push、pop、peek 和 empty
- 假设所有操作都是有效的(例如,一个空的队列不会调用 pop 或者 peek 操作)
用两个栈实现队列的这道题和用两个队列实现栈的思路差不多。先在队列中定义两个栈,分别是入数据的栈pushST和出数据的栈popST。当入数据的时候,直接向栈pushST入数据。当出数据时,需要考虑两种情况:如果栈popST中没有数据,就将pushST中的数据导过去,再将栈pushST栈顶的数据 pop 掉;如果popST中有数据,直接 pop 掉栈顶的数据就行了。

typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void StackInit(ST* ps);
void StackDestroy(ST* ps);
void StackPush(ST* ps, STDataType x);
void StackPop(ST* ps);
STDataType StackTop(ST* ps);
bool StackEmpty(ST* ps);
int StackSize(ST* ps);
void StackInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->capacity = ps->top = 0;
}
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->capacity = ps->top = 0;
}
void StackPush(ST* ps, STDataType x)
{
assert(ps);
if (ps->capacity == ps->top)
{
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType* tmp = (STDataType*)realloc(ps->a, newcapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("relloc fail");
exit(-1);
}
ps->a = tmp;
ps->capacity = newcapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
ps->top--;
}
STDataType StackTop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
//匿名结构体
typedef struct
{
ST pushST;
ST popST;
} MyQueue;
MyQueue* myQueueCreate()
{
MyQueue* q = (MyQueue*)malloc(sizeof(MyQueue));
StackInit(&q->pushST);
StackInit(&q->popST);
return q;
}
void myQueuePush(MyQueue* obj, int x)
{
StackPush(&obj->pushST, x);
}
int myQueuePop(MyQueue* obj)
{
//如果popST中没有数据,将pushST中的数据导过去
//popST中的数据就符号先进先出的顺序了
//如果popST中有数据,那么就直接pop popST中的数据
if(StackEmpty(&obj->popST))
{
while(!StackEmpty(&obj->pushST))
{
StackPush(&obj->popST, StackTop(&obj->pushST));
StackPop(&obj->pushST);
}
}
int front = StackTop(&obj->popST);
StackPop(&obj->popST);
return front;
}
int myQueuePeek(MyQueue* obj)
{
if(StackEmpty(&obj->popST))
{
while(!StackEmpty(&obj->pushST))
{
int top = StackTop(&obj->pushST);
StackPop(&obj->pushST);
StackPush(&obj->popST, top);
}
}
return StackTop(&obj->popST);
}
bool myQueueEmpty(MyQueue* obj)
{
return StackEmpty(&obj->pushST) && StackEmpty(&obj->popST);
}
void myQueueFree(MyQueue* obj)
{
StackDestroy(&obj->pushST);
StackDestroy(&obj->popST);
free(obj);
}

设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
你的实现应该支持如下操作:
- MyCircularQueue(k): 构造器,设置队列长度为 k。
- Front: 从队首获取元素。如果队列为空,返回 -1 。
- Rear: 获取队尾元素。如果队列为空,返回 -1 。
- enQueue(value): 向循环队列插入一个元素。如果成功插入则返回真。
- deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。
- isEmpty(): 检查循环队列是否为空。
- isFull():检查循环队列是否已满。
示例:
MyCircularQueue circularQueue = newMyCircularQueue(3); // 设置长度为 3
circularQueue.enQueue(1); // 返回 truecircularQueue.enQueue(2); // 返回truecircularQueue.enQueue(3); // 返回 truecircularQueue.enQueue(4); // 返回 false,队列已满
circularQueue.Rear(); // 返回 3
circularQueue.isFull(); // 返回 truecircularQueue.deQueue(); // 返回truecircularQueue.enQueue(4); // 返回 truecircularQueue.Rear(); //返回 4
提示:
- 所有的值都在 0 至 1000 的范围内;
- 操作数将在 1 至 1000 的范围内;
- 请不要使用内置的队列库。
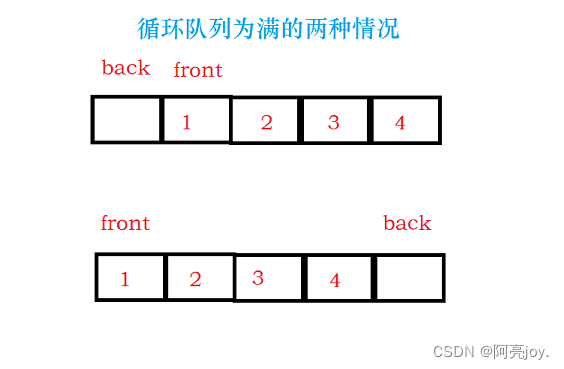
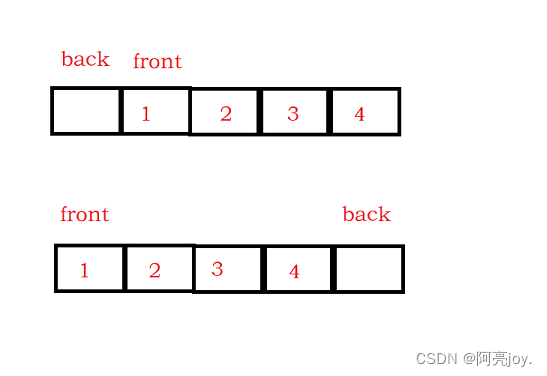
本道题需要实现的函数接口有:创建循环链表、判断循环链表是否为空、判断循环链表是否为满、数据入队、数据出队、返回队头数据、返回队尾数据以及销毁循环队列。循环队列可以采用数组或者链表的形式实现,但不管使用数组还是链表来实现循环队列,需要多开一个空间或者加个size记录循环队列中数据的个数,否则无法将队列为空和队列为满两种情况区分开。
//重点:循环队列,无论使用数组实现还是链表实现,都要
//多开一个空间,也就意味着,要是一个存k个数据的循环队列
//要开k+1个空间,否则无法实现判空和判满。
//数组实现:空:front == tail 满:(tail+1)%(k+1) == front
//链表实现:空:tail == tail 满:tail->next == front
typedef struct
{
int* a;
int front;
int back;
int N;
} MyCircularQueue;
MyCircularQueue* myCircularQueueCreate(int k)
{
MyCircularQueue* obj = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));
obj->a = (int*)malloc(sizeof(int)*(k+1));
obj->front = obj->back = 0;
obj->N = k + 1;
return obj;
}
bool myCircularQueueIsEmpty(MyCircularQueue* obj)
{
return obj->front == obj->back;
}
bool myCircularQueueIsFull(MyCircularQueue* obj)
{
return (obj->back + 1) % obj->N == obj->front;
}
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)
{
if(myCircularQueueIsFull(obj))
return false;
obj->a[obj->back] = value;
obj->back++;
// 当back在最后一个位置时,让back回到下标为0的位置
obj->back %= obj->N;
return true;
}
bool myCircularQueueDeQueue(MyCircularQueue* obj)
{
if(myCircularQueueIsEmpty(obj))
return false;
obj->front++;
// 当front在最后一个位置时,让front回到下标为0的位置
obj->front %= obj->N;
return true;
}
int myCircularQueueFront(MyCircularQueue* obj)
{
if(myCircularQueueIsEmpty(obj))
return -1;
else
return obj->a[obj->front];
}
int myCircularQueueRear(MyCircularQueue* obj)
{
// if(myCircularQueueIsEmpty(obj))
// return -1;
// else if(obj->back == 0)
// return obj->a[obj->N -1];
// else
// return obj->a[obj->back - 1];
if(myCircularQueueIsEmpty(obj))
return -1;
else
return obj->a[(obj->back - 1 + obj->N) % obj->N];
}
void myCircularQueueFree(MyCircularQueue* obj)
{
free(obj->a);
free(obj);
}

自定义循环队列
a:整型指针,指向申请的空间
front:队头的位置
back:队尾位置的下一个位置
N:数组的长度 = k + 1
typedef struct
{
int* a;
int front;
int back;
int N;
} MyCircularQueue;
创建循环链表
需要注意的是,要给队列循环申请 k + 1个空间,来区分队列是空还是满
MyCircularQueue* myCircularQueueCreate(int k)
{
MyCircularQueue* obj = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));
obj->a = (int*)malloc(sizeof(int)*(k+1));
obj->front = obj->back = 0;
obj->N = k + 1;
return obj;
}
判断循环队列是否为空
当
obj->front == obj->back时,循环队列为空
bool myCircularQueueIsEmpty(MyCircularQueue* obj)
{
return obj->front == obj->back;
}
判断循环队列是否为满
当
(obj->back + 1) % obj->N == obj->front时,循环队列为满
bool myCircularQueueIsFull(MyCircularQueue* obj)
{
return (obj->back + 1) % obj->N == obj->front;
}
数据入队
1.当循环队列为满时,返回 false
2.当循环队列不为满时,数据入队obj->a[obj->back] = value, obj->back++
3.当back在最后一个位置时,让back回到下标为 0 的位置obj->back %= obj->N
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)
{
if(myCircularQueueIsFull(obj))
return false;
obj->a[obj->back] = value;
obj->back++;
// 当back在最后一个位置时,让back回到下标为0的位置
obj->back %= obj->N;
return true;
}
数据出队
1.当循环队列为空时,返回 false
2.当循环队列不为空时,数据出队obj->front++
3.当front在最后一个位置时,让front回到下标为 0的位置obj->front %= obj->N
bool myCircularQueueDeQueue(MyCircularQueue* obj)
{
if(myCircularQueueIsEmpty(obj))
return false;
obj->front++;
// 当front在最后一个位置时,让front回到下标为0的位置
obj->front %= obj->N;
return true;
}
返回队头数据
1.当循环队列为空时,返回 false
2.当循环队列不为空时,返回队头数据return obj->a[obj->front]
int myCircularQueueFront(MyCircularQueue* obj)
{
if(myCircularQueueIsEmpty(obj))
return -1;
else
return obj->a[obj->front];
}
返回队尾数据
1.当循环队列为空时,返回 false
2.当循环队列不为空时,返回队尾数据return obj->a[(obj->back - 1 + obj->N) % obj->N]
int myCircularQueueRear(MyCircularQueue* obj)
{
// if(myCircularQueueIsEmpty(obj))
// return -1;
// else if(obj->back == 0)
// return obj->a[obj->N -1];
// else
// return obj->a[obj->back - 1];
if(myCircularQueueIsEmpty(obj))
return -1;
else
return obj->a[(obj->back - 1 + obj->N) % obj->N];
}
销毁循环队列
void myCircularQueueFree(MyCircularQueue* obj)
{
free(obj->a);
free(obj);
}
现有一循环队列,其队头为front,队尾为rear,循环队列长度为N,最多存储N-1个数据。其队内有效长度为( )
A.(rear - front + N) % N + 1
B.(rear - front + N) % N
C.(rear - front) % (N + 1)
D.(rear - front + N) % (N - 1)
答案:
B
解析:有效长度一般是rear-front,但是循环队列中rear有可能小于front,减完之后可能是负数,所以需要+N,此时结果刚好是队列中有效元素个数,但如果rear大于front,减完之后就是有效元素个数了,再加N后有效长度会超过N,故需要%N。
本篇博客主要讲解三道 OJ 题,主要考察的是大家对栈和队列性质的理解。以上就是本篇博客的全部内容了,如果大家觉得有收获的话,可以点个三连支持一下!谢谢大家啦!💖💝❣️
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar