本文作者:李杰
TF计算图从逻辑层来讲,由op与tensor构成。op是项点代表计算单元,tensor是边代表op之间流动的数据内容,两者配合以数据流图的形式来表达计算图。那么op对应的物理层实现是什么?TF中有哪些op,以及各自的适用场景是什么?op到底是如何运行的?接下来让我们一起探索和回答这些问题。
op代表计算图中的节点,是tf.Operation对象,代表一个计算单元。用户在创建模型和训练代码时,会创建一系列op及其依赖关系,并将这些op和依赖添加到tf.Graph对象中(一般为默认图)。比如:tf.matmul()就是一个op,它有两个输入tensor和一个输出tensor。
op的分类一般有多个视角,比如按是否内置划分、按工作类型划分。
按是否内置划分,一般分为:内置op和自定义op(见“二、自定义op”部分介绍)。
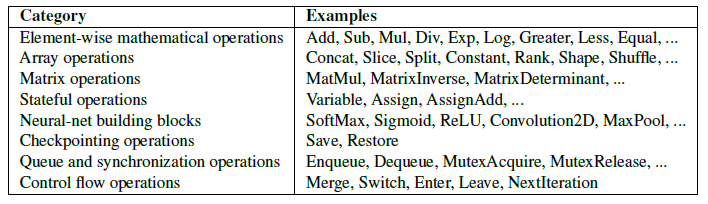
按工作类型划分,一般分为:常见数学op、数组op、矩阵op、有状态op、神经网络op、检查点op、队列与同步op、控制流op。TF白皮书对内置op的分类总结如下:
op一般都有名称且代表一个抽象的计算过程。op可以设置若干属性,但这些属性必须在编译期提供或推理得到,因为它们用来实例化一个节点对象从而执行真正的计算。属性的经典用法就是拿来支持类型多态,比如两个浮点张量的矩阵乘法与两个整型张量的矩阵乘法。
kernel是op在指定设备类型(CPU/GPU)上的具体实现。TF二进制库通过注册机制定义了一系列op及对应的kernel实现,用户可以提供额外的op定义与kernel实现进行扩充。一般来说,一个op对应多个kernel实现。
接下来让我们一起用矩阵乘法MatMul算子的相关代码来理解op与kernel的关系(此处不必纠结代码细节,只需体会op与kernel关系即可):
// 首先给出op注册的定义。其中输入输出支持泛型,其合法类型在Attr中进行枚举。
// 代码位置 tensorflow1.15.5\tensorflow\core\ops\math_ops.cc
REGISTER_OP("MatMul")
.Input("a: T")
.Input("b: T")
.Output("product: T")
.Attr("transpose_a: bool = false")
.Attr("transpose_b: bool = false")
.Attr(
"T: {bfloat16, half, float, double, int32, int64, complex64, "
"complex128}")
.SetShapeFn(shape_inference::MatMulShape);
// MatMul的实现,采用类模板机制
// 代码位置 tensorflow1.15.5\tensorflow\core\kernels\matmul_op.cc
template <typename Device, typename T, bool USE_CUBLAS>
class MatMulOp : public OpKernel {
public:
explicit MatMulOp(OpKernelConstruction* ctx)
: OpKernel(ctx), algorithms_set_already_(false) {
OP_REQUIRES_OK(ctx, ctx->GetAttr("transpose_a", &transpose_a_));
OP_REQUIRES_OK(ctx, ctx->GetAttr("transpose_b", &transpose_b_));
LaunchMatMul<Device, T, USE_CUBLAS>::GetBlasGemmAlgorithm(
ctx, &algorithms_, &algorithms_set_already_);
use_autotune_ = MatmulAutotuneEnable();
}
// 省略了很多代码...
private:
std::vector<int64> algorithms_;
bool algorithms_set_already_;
bool use_autotune_;
bool transpose_a_;
bool transpose_b_;
};
// MatMul的op定义与kernel实现绑定处理
// 代码位置 tensorflow1.15.5\tensorflow\core\kernels\matmul_op.cc
#define REGISTER_CPU_EIGEN(T) /*cpu与eigen组合对应实现*/ \
REGISTER_KERNEL_BUILDER( \
Name("MatMul").Device(DEVICE_CPU).TypeConstraint<T>("T").Label("eigen"), \
MatMulOp<CPUDevice, T, false /* cublas, ignored for CPU */>);
#define REGISTER_CPU(T) /*cpu对应实现(eigen与非eigen)*/ \
REGISTER_KERNEL_BUILDER( \
Name("MatMul").Device(DEVICE_CPU).TypeConstraint<T>("T"), \
MatMulOp<CPUDevice, T, false /* cublas, ignored for CPU */>); \
REGISTER_CPU_EIGEN(T);
#define REGISTER_GPU(T) /*gpu对应实现(cublas与非cublas)*/ \
REGISTER_KERNEL_BUILDER( \
Name("MatMul").Device(DEVICE_GPU).TypeConstraint<T>("T"), \
MatMulOp<GPUDevice, T, true /* cublas, true by default */>); \
REGISTER_KERNEL_BUILDER(Name("MatMul") \
.Device(DEVICE_GPU) \
.TypeConstraint<T>("T") \
.Label("cublas"), \
MatMulOp<GPUDevice, T, true /* cublas */>)
用户编写的模型训练代码一般由TF原生的op算子及其依赖关系组成,但有时候我们定义的计算逻辑在TF中没有相应的op实现。根据TensorFlow官网的建议,我们应当先组合python op算子或python函数进行尝试。完成尝试之后再决定要不要自定义op。
一般来说,需要自定义op的场景有如下3个:
在此举个例子方便大家理解。假如我们要实现一个新计算实逻:中位数池化(median pooling),过程中要在滑动窗口不断求得中位数。检索TF文档没有发现对应op,因此我们先考虑用TF python op组合来实现它,果然通过ExtractImagePatches and TopK就可以实现这个功能。经测试前述组合方案并不是计算和存储高效的,因此我们就有必要将median pooling在一个op中进行高效实现。
自定义op一般遵循5个基本步骤:
接下来我们就以官网最简单的ZeroOut同步式自定义op(继承OpKernel)为例,结合代码来讲述上述5个步骤。下面先给出步骤1和步骤2用C++实现的代码(官方推荐用bazel编译so文件):
// 步骤1:注册op
REGISTER_OP("ZeroOut")
.Input("to_zero: int32")
.Output("zeroed: int32")
.SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) {
c->set_output(0, c->input(0)); //c's input and output type is std::vector<ShapeHandle>
return Status::OK();
});
// 步骤2:定义kernel(常规CPU设备),并把kernel与op绑定
class ZeroOutOp : public OpKernel {
public:
explicit ZeroOutOp(OpKernelConstruction* context) : OpKernel(context) {}
void Compute(OpKernelContext* context) override {
// Grab the input tensor from OpKernelContext instance
const Tensor& input_tensor = context->input(0);
auto input = input_tensor.flat<int32>();
// Create an output tensor
Tensor* output_tensor = NULL;
OP_REQUIRES_OK(context, context->allocate_output(0, input_tensor.shape(),
&output_tensor)); // OP_REQUIRES_OK第二个参数一般为方法调用,此处为输出张量分配内存空间
auto output_flat = output_tensor->flat<int32>();
// Set all but the first element of the output tensor to 0.
const int N = input.size();
for (int i = 1; i < N; i++) {
output_flat(i) = 0;
}
// Preserve the first input value if possible.
if (N > 0) output_flat(0) = input(0);
}
};
REGISTER_KERNEL_BUILDER(Name("ZeroOut").Device(DEVICE_CPU), ZeroOutOp);步骤3加载上述so文件(自动完成前后端op映射);步骤4是可选项,此处不需要;步骤5基于python api测试op功能。相应代码如下:
import tensorflow as tf
zero_out_module = tf.load_op_library('./zero_out.so') # 加载so文件生成python module
with tf.Session(''):
zero_out_module.zero_out([[1, 2], [3, 4]]).eval()
# Prints
array([[1, 0], [0, 0]], dtype=int32)关于op的技术话题还有很多,我们在此简述一些要点:
整体来看,op与kernel都有其结构描述与统一的注册管理中心。而OpDefBuilder有两个包装类OpDefBuilderWrapper和OpDefBuilderReceiver,前者支持op构建的链式语法,后者接受op构建结果并进行注册。众所周知,op是编译期概念,而kernel是运行期概念,在AI编译器的后端处理流程中会进行op的算子选择,此过程会基于一系列策略为op匹配最合适的kernel实现。
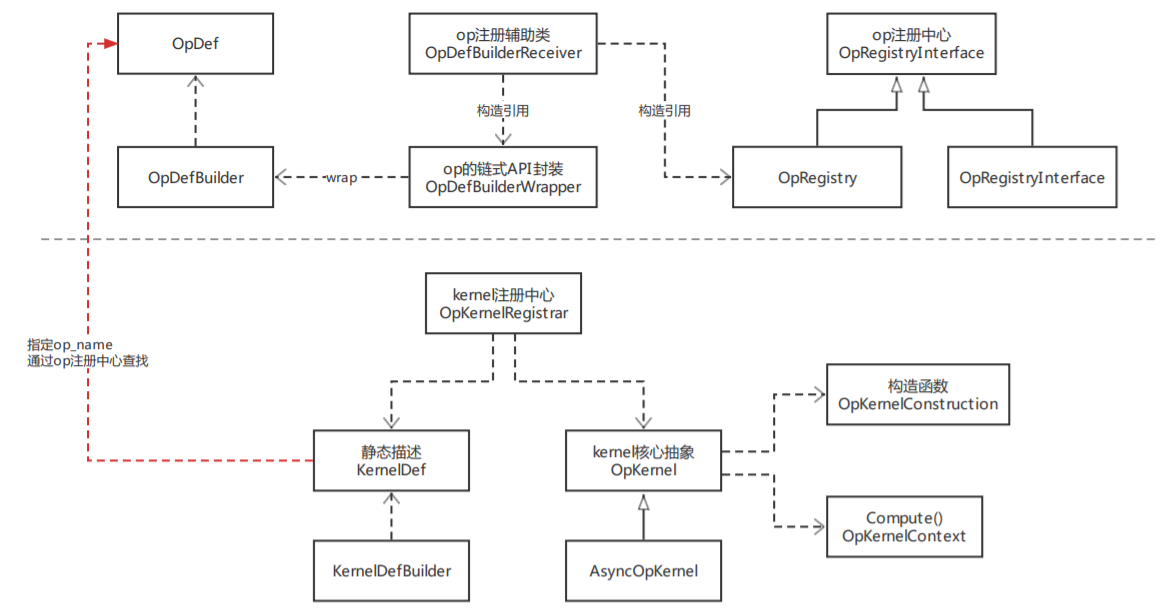
首先,我们来看一下大家在使用TensorFlow过程中经常碰到的libtensorflow_framework.so。按照tf1.15.5/tensorflow/BUILD中的描述,libtensorflow_framework.so定义了op和kernel的注册机制而不涉及具体实现。
// rootdir=tensorflow1.15.5
// ${rootdir}/tensorflow/BUILD
/*
# A shared object which includes registration mechanisms for ops and
# kernels. Does not include the implementations of any ops or kernels. Instead,
# the library which loads libtensorflow_framework.so
# (e.g. _pywrap_tensorflow_internal.so for Python, libtensorflow.so for the C
# API) is responsible for registering ops with libtensorflow_framework.so. In
# addition to this core set of ops, user libraries which are loaded (via
# TF_LoadLibrary/tf.load_op_library) register their ops and kernels with this
# shared object directly.
*/
tf_cc_shared_object(
name = "tensorflow_framework",
framework_so = [],
linkopts = select({
"//tensorflow:macos": [],
"//tensorflow:windows": [],
"//tensorflow:freebsd": [
"-Wl,--version-script,$(location //tensorflow:tf_framework_version_script.lds)",
"-lexecinfo",
],
"//conditions:default": [
"-Wl,--version-script,$(location //tensorflow:tf_framework_version_script.lds)",
],
}),
linkstatic = 1,
per_os_targets = True,
soversion = VERSION,
visibility = ["//visibility:public"],
deps = [
"//tensorflow/cc/saved_model:loader_lite_impl",
"//tensorflow/core:core_cpu_impl",
"//tensorflow/core:framework_internal_impl", /* 展开此target进行查看 */
"//tensorflow/core:gpu_runtime_impl",
"//tensorflow/core/grappler/optimizers:custom_graph_optimizer_registry_impl",
"//tensorflow/core:lib_internal_impl",
"//tensorflow/stream_executor:stream_executor_impl",
"//tensorflow:tf_framework_version_script.lds",
] + tf_additional_binary_deps(),
)
// ${rootdir}/tensorflow/core/BUILD
tf_cuda_library(
name = "framework_internal_impl",
srcs = FRAMEWORK_INTERNAL_PRIVATE_HEADERS + glob( // 可以查看FRAMEWORK_INTERNAL_PRIVATE_HEADERS内容
[
"example/**/*.cc",
"framework/**/*.cc",
"util/**/*.cc",
"graph/edgeset.cc",
"graph/graph.cc",
"graph/graph_def_builder.cc",
"graph/node_builder.cc",
"graph/tensor_id.cc",
"graph/while_context.h",
"graph/while_context.cc",
],
// 省略了诸多代码
)
// FRAMEWORK_INTERNAL_PRIVATE_HEADERS的内容
FRAMEWORK_INTERNAL_PRIVATE_HEADERS = [
"graph/edgeset.h",
"graph/graph.h",
"graph/graph_def_builder.h",
"graph/node_builder.h",
"graph/tensor_id.h",
] + glob(
[
"example/**/*.h",
"framework/**/*.h", // 这里就是重点,查看${rootdir}/tensorflow/core/framework/op.h和opkernel.h
"util/**/*.h",
]
)
// 先来看op.h
#define REGISTER_OP(name) REGISTER_OP_UNIQ_HELPER(__COUNTER__, name)
#define REGISTER_OP_UNIQ_HELPER(ctr, name) REGISTER_OP_UNIQ(ctr, name)
#define REGISTER_OP_UNIQ(ctr, name) \
static ::tensorflow::register_op::OpDefBuilderReceiver register_op##ctr \
TF_ATTRIBUTE_UNUSED = \
::tensorflow::register_op::OpDefBuilderWrapper<SHOULD_REGISTER_OP( \
name)>(name)
// 再来看看opkernel.h
#define REGISTER_KERNEL_BUILDER(kernel_builder, ...) \
REGISTER_KERNEL_BUILDER_UNIQ_HELPER(__COUNTER__, kernel_builder, __VA_ARGS__)
#define REGISTER_KERNEL_BUILDER_UNIQ_HELPER(ctr, kernel_builder, ...) \
REGISTER_KERNEL_BUILDER_UNIQ(ctr, kernel_builder, __VA_ARGS__)
#define REGISTER_KERNEL_BUILDER_UNIQ(ctr, kernel_builder, ...) \
constexpr bool should_register_##ctr##__flag = \
SHOULD_REGISTER_OP_KERNEL(#__VA_ARGS__); \
static ::tensorflow::kernel_factory::OpKernelRegistrar \
registrar__body__##ctr##__object( \
should_register_##ctr##__flag \
? ::tensorflow::register_kernel::kernel_builder.Build() \
: nullptr, \
#__VA_ARGS__, \
[](::tensorflow::OpKernelConstruction* context) \
-> ::tensorflow::OpKernel* { \
return new __VA_ARGS__(context); \
});
参照上述同样的流程,我们可以发现libtensorflow.so中涉及op与kernel的具体实现,同时也包括Session的具体实现。
最后,我们再来讲讲REGISTER_OP宏背后的具体原理。我们在上面已经给出了此宏的定义,此处针对它的实现展开谈谈:
// 先来看op.h
#define REGISTER_OP(name) REGISTER_OP_UNIQ_HELPER(__COUNTER__, name)
#define REGISTER_OP_UNIQ_HELPER(ctr, name) REGISTER_OP_UNIQ(ctr, name)
#define REGISTER_OP_UNIQ(ctr, name) \
static ::tensorflow::register_op::OpDefBuilderReceiver register_op##ctr \
TF_ATTRIBUTE_UNUSED = \
::tensorflow::register_op::OpDefBuilderWrapper<SHOULD_REGISTER_OP( \
name)>(name)
// REGISTER_OP的一般用法如下
REGISTER_OP("ZeroOut")
.Input("to_zero: int32")
.Output("zeroed: int32")
.SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) {
c->set_output(0, c->input(0));
return Status::OK();
});
// op定义的链式规则是通过OpDefBuilderWrapper类实现的
class OpDefBuilderWrapper<true> {
public:
explicit OpDefBuilderWrapper(const char name[]) : builder_(name) {}
OpDefBuilderWrapper<true>& Input(string spec) {
builder_.Input(std::move(spec));
return *this; // 显而易见,调用Input仍然返回OpDefBuilderWrapper<true>本身
}
OpDefBuilderWrapper<true>& Output(string spec) {
builder_.Output(std::move(spec));
return *this;
}
OpDefBuilderWrapper<true>& SetShapeFn(
Status (*fn)(shape_inference::InferenceContext*)) {
builder_.SetShapeFn(fn);
return *this;
}
const ::tensorflow::OpDefBuilder& builder() const { return builder_; }
private:
mutable ::tensorflow::OpDefBuilder builder_;
};
// 当通过链式规划构建好op后,再通过OpDefBuilderReceiver完成op的注册
// op.h
struct OpDefBuilderReceiver {
// To call OpRegistry::Global()->Register(...), used by the
// REGISTER_OP macro below.
// Note: These are implicitly converting constructors.
OpDefBuilderReceiver(
const OpDefBuilderWrapper<true>& wrapper); // NOLINT(runtime/explicit)
constexpr OpDefBuilderReceiver(const OpDefBuilderWrapper<false>&) {
} // NOLINT(runtime/explicit)
};
// op.cc,然后在OpDefBuilderReceiver构造函数内部完成OpDefBuilderWrapper的全局注册
OpDefBuilderReceiver::OpDefBuilderReceiver(
const OpDefBuilderWrapper<true>& wrapper) {
OpRegistry::Global()->Register(
[wrapper](OpRegistrationData* op_reg_data) -> Status {
return wrapper.builder().Finalize(op_reg_data);
});
}本文为大家系统讲解了TensorFlow的核心抽象op及其kernel实现。需要自定义op的具体场景,以及op的运行框架及若干技术细节。读罢此文,读者应该有如下几点收获:
1.《TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems》: https://arxiv.org/abs/1603.04467
2.Graphs and Sessions: https://github.com/tensorflow/docs/blob/master/site/en/r1/guide/graphs.md
3.Adding a New Op: https://github.com/tensorflow/docs/blob/master/site/en/r1/guide/extend/op.md
4.跨设备通信send/recv: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/sendrecv_ops.h
5.OpKernel definition: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/op_kernel.h
6.tensorflow源码解析之framework-resource: https://www.cnblogs.com/jicanghai/p/9535504.html
7.tensorflow源码解析之framework-op: https://www.cnblogs.com/jicanghai/p/9539513.html
**本文作者:李杰**我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315