今天讲的是用selenium库写一个淘宝抢购程序,10.19亲测可用
本教程所有配套资料索取方式如下:点赞三连后Q裙搜索:652892456找管理员获取(或直接加小助理微信:python5180 ){备注:UR的出不克}
学习或其他资料也可+Q群:652892456,告别孤单,共同进步!
1.先打开淘宝的官网,点击登录
2.账号的登录
3.打开我的购物车
3.计算时间对购物车进行提交
4.付款,当我们提交了商品付款,东西就是我们的了只要在规定时间内付款就行
1.导入模块
from selenium.webdriver.common.by import By
from selenium import webdriver创建浏览器页面并打开,这里我用的Chrome
#Chrome有很多好的扩展,打开的页面也很快
driver = webdriver.Chrome()
driver.maximize_window()
对页面进行get请求淘宝网的链接,找到登录的文本用selenium里的筛选功能
筛选文本TEXT“亲,请登录”然后点击就可以进入到登录的页面
#注意链接载入到浏览器需要时间,导入time模块,使休眠3秒钟
import time
driver.get("https://www.taobao.com")
time.sleep(3)做一个小的检测,检测“亲,请登录”是否加载完毕
if driver.find_element(By.LINK_TEXT, "亲,请登录"):
driver.find_element(By.LINK_TEXT, "亲,请登录").click()
这样我们就打开了第二个链接,到了账号登录的环节
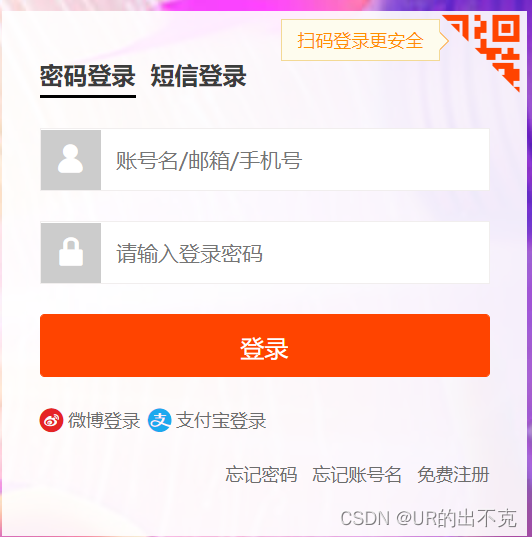
我们要通过扫码登录,所以要点击右上角的二维码,通过xpath定位还是比较好找的
给我们预留了三十秒的扫码确定时间
driver.find_element(By.XPATH,'//*[@id="login"]/div[1]/i').click()
print("请在30秒内完成扫码")
time.sleep(30)#我们是通过selenium自动化模块进行操作的,从头到尾在一个真实的浏览器中
可以记录我们的cookie不用重复登录
2.当等待了三十秒后我们就可以向购物车页面发送请求并等待三秒钟
https://cart.taobao.com/cart.htmurl3 = "https://cart.taobao.com/cart.htm" # 淘宝购物车
driver.get(url3)
time.sleep(3)打开购物车页面后对商品进行全选,然后写时间的判断,时间一到就点击付款按钮
#这里我们用到datetime模块
获取实时的时间,并与我们要抢的商品时间进行对比,时间一到对付款点击最快的取得商品
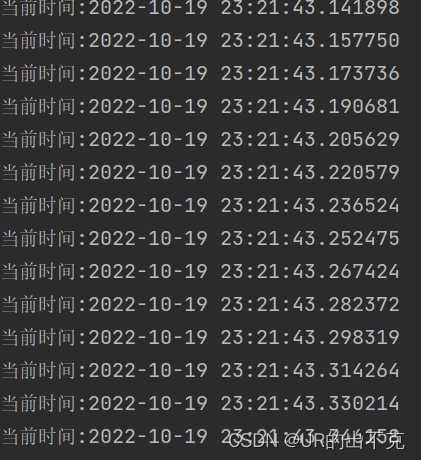
可以看得到时间的刷新非常快速,所以我们很容易就可以抢到商品 now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
# 对比时间,时间到的话就点击结算
if now >= buytime:
print("与预定时间1进行比较")对时间的判定结束后第一时间点击结算,这里用while循环加一个报错异常处理
因为页面不会时间一到就给出结算的链接,不加异常处理得话也是会报错的代码如下
try:
# 点击结算按钮
# if driver.find_element(By.ID, "J_Go"):
if driver.find_element(By.XPATH, '//*[@class="submit-btn"]/span'):
driver.find_element(By.XPATH, '//*[@class="submit-btn"]/span').click() # 结算
print("程序锁定商品,结算成功")
break
except:
time.sleep(0.001)
3.这样我们的代码就差不多写完了,已经是一个合格抢购脚本了基本能够满足我们的需求
但是依旧会报错,作为一个合格的程序员仍需要将报错改掉,并优化代码结构
from selenium.webdriver.common.by import By
from selenium import webdriver
import datetime
import time
driver = webdriver.Chrome()
driver.maximize_window()
def login():
# 打开淘宝登录页,并进行扫码登录
driver.get("https://www.taobao.com")
time.sleep(3)
if driver.find_element(By.LINK_TEXT, "亲,请登录"):
driver.find_element(By.LINK_TEXT, "亲,请登录").click()
driver.find_element(By.XPATH,'//*[@id="login"]/div[1]/i').click()
print("请在30秒内完成扫码")
time.sleep(30)
url3 = "https://cart.taobao.com/cart.htm" #淘宝购物车
driver.get(url3)
time.sleep(3)
# 点击购物车里全选按钮
if driver.find_element(By.ID,"J_SelectAll1"):
driver.find_element(By.ID,"J_SelectAll1").click()
else:
print("找不到购买按钮,请手动点击商品")
now = datetime.datetime.now()
print('login success:', now.strftime('%Y-%m-%d %H:%M:%S:%f'))
def buy(buytime):
while True:
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
# 对比时间,时间到的话就点击结算
if now >= buytime:
print("与预定时间1进行比较")
while True:
try:
# 点击结算按钮
if driver.find_element(By.XPATH, '//*[@class="submit-btn"]/span'):
driver.find_element(By.XPATH, '//*[@class="submit-btn"]/span').click() #结算
print("程序锁定商品,结算成功")
break
except:
time.sleep(0.001)
# 点击提交订单按钮
while True:
try:
# time.sleep(1)
if driver.find_element(By.XPATH, '//*[@id="submitOrderPC_1"]/div/a[2]'):
driver.execute_script('window.scrollBy(0,250)')
driver.find_element(By.XPATH, '//*[@id="submitOrderPC_1"]/div/a[2]').click() #提交订单
print("订单提交成功")
break
except:
time.sleep(0.01)
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
print("已经抢到商品啦,抢到的时间:" + now)
break
print("当前时间:" + now)
time.sleep(0.01)
if __name__ == "__main__":
login()
buy("2022-10-19 23:22:00.000000")
#每日一更
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
参考文章搭建文章gitte源码在线体验可以注册两个号来测试演示图:一.整体介绍 介绍SignalR一种通讯模型Hub(中心模型,或者叫集线器模型),调用这个模型写好的方法,去发送消息。 内容有: ①:Hub模型的方法介绍 ②:服务器端代码介绍 ③:前端vue3安装并调用后端方法 ④:聊天室样例整体流程:1、进入网站->调用连接SignalR的方法2、与好友发送消息->调用SignalR的自定义方法 前端通过,signalR内置方法.invoke() 去请求接口3、监听接受方法(渲染消息)通过new signalR.HubConnectionBuilder().on
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
Asitcurrentlystands,thisquestionisnotagoodfitforourQ&Aformat.Weexpectanswerstobesupportedbyfacts,references,orexpertise,butthisquestionwilllikelysolicitdebate,arguments,polling,orextendeddiscussion.Ifyoufeelthatthisquestioncanbeimprovedandpossiblyreopened,visitthehelpcenter提供指导。9年前关闭。我打算学习Seleni
我一直在工作中使用seleniumIDE。现在我们决定将Seleniumwebdriver与Ruby结合使用。我完全不知道如何设置我的Mac,MacProYosemite10.10.5。在我的终端中,我运行了这些命令:$ruby-e"$(curl-fsSLhttps://raw.githubusercontent.com/Homebrew/install/master/install)"$brewdoctorYoursystemisreadytobrew.$brewinstallruby==>Summary/usr/local/Cellar/openssl/1.0.2d_1:464fi