SQL:查询结果升序、降序排列
SQL 查询时,查询结果按照某一列参数升序或者降序排列后再输出是常见的用法,本文主要介绍了利用 order by 对输出结果进行排序的用法
本文部分内容参考自:
SQL37 查找后多列排序
SQL38 查找后降序排列
一句话说明:order by 可以按照降序或者升序对检索结果进行排序
强调:order by 默认按照 ASC 升序排列,可以选择 DESC 降序排列
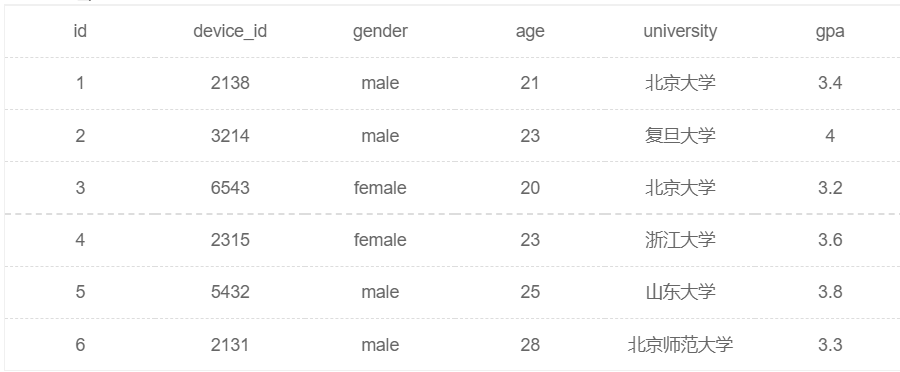
例题1:现在运营想要取出用户信息表中的年龄和gpa数据,并先按照gpa升序降序,再按照年龄降序排序输出,请取出相应数据。
//升序排列ASC可以省略,降序排列DESC不可省略!
SELECT device_id,gpa,age FROM user_profile ORDER BY gpa DESC,age DESC
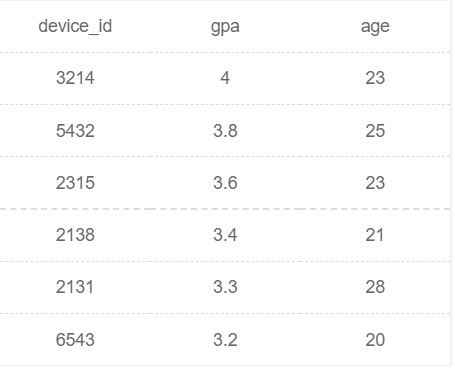
例题2:现在运营想要取出用户信息表中的年龄和gpa数据,并先按照gpa升序升序,再按照年龄升序排序输出,请取出相应数据。
SELECT device_id,gpa,age FROM user_profile ORDER BY gpa ASC,age ASC
or
//默认ASC,因此可以省略
SELECT device_id,gpa,age FROM user_profile ORDER BY gpa ,age
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我有这样的哈希trial_hash={"key1"=>1000,"key2"=>34,"key3"=>500,"key4"=>500,"key5"=>500,"key6"=>500}我按值降序排列:my_hash=trial_hash.sort_by{|k,v|v}.reverse我现在是这样理解的:[["key1",1000],["key4",500],["key5",500],["key6",500],["key3",500],["key2",34]]但我希望当值相同时按键的升序排序。我该怎么做?例如:上面的散列将以这种方式排序:[["key1",1000],["key3",500
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我已经搜索过这个问题的答案,但没有成功,有一个类似的问题,但答案在这种情况下不起作用,它按数字项目排序。SimilarQuestion-Thatdidnotwork我正在尝试使用ruby的sort_by对一个项目进行降序排序和另一个升序排序。我只能找到一个。代码如下:#PrimarysortLastNameDescending,withtiesbrokenbysortingAreaofinterest.people=people.sort_by{|a|[a.last_name,a.area_interest]}任何指导肯定会有所帮助。示例数据:输入罗素,逻辑欧拉,图论伽罗瓦,抽象代
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params