
图1. 基于DeepLabV3+的图像分割结果示意图。
目录
图像分割属于图像处理领域最重要的几个问题之一。随着自动驾驶,广告推荐,手机照片处理,知识图谱等智能应用的快速普及,基于语义分析的图像分割、理解与识别变得越来越重要。近年来比较热的视觉领域工作,很大比重是围绕如何使用大规模数据,结合结构优良的深度网络模型,实现图像分割计算。今天,我们就来学习一项该领域的著名工作(DeepLabV3+)。
DeepLabV3+[1]于2018年由谷歌的研究人员提出。该工作基于DeepLabv3,通过增加一个高效的解码器模块,以获得更加精准的分割边缘。整体上,该项工作基于空间金字塔池化技术,通过融合多种模型的优点,构建了核心网络架构,得到一个性能良好的,基于深度网络结构的编解码器。实验证明,该结构在PASCAL VOC 2012 and Cityscapes测试集上能够得到89.0% and 82.1%的分割精度,同时不需要复杂的预处理过程。该模型包括了一些模块,如在DeepLabV2就使用的空洞空间卷积池化金字塔(Atrous spatial pyramid pooling), Xception model[3] 以及 Depthwise separable convolution (我没有深入研究,但上面两项内容应该是经过谷歌的研究人员优化后的三通道卷积网络结构,有兴趣希望深入了解的同学参看:Depthwise卷积与Pointwise卷积 - 知乎)。
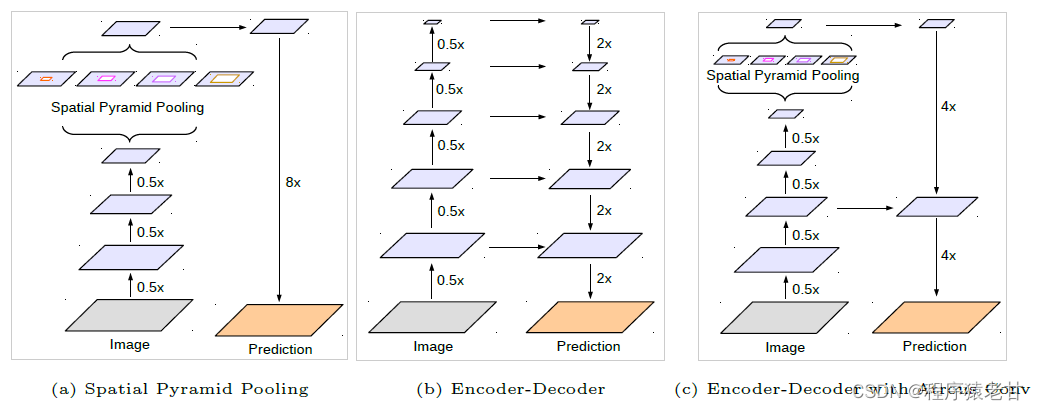
图2. DeepLabV3+结构示意图。
图2展示了DeepLabV3+的基本结构。前两个模块基本继承自DeepLabV3[7],而改进部分主要是在第三个模块里,通过编码模块学到更多的语义信息,然后在解码模块,以一个非常高效的方式将分割边缘通过解码实现恢复。这样使得分割结果的细节更加精确。通过使用空洞卷积(Atro Conv),编码器可以从任意分辨率的数据中提取特征。以上就是DeepLabV3+的基本结构。下面我们就具体看一下该结构的细节内容。
DeepLabV3+的核心结构由两个神经网络构成,分别是空间金字塔池化模块[4]和编解码结构[5]。第一个结构用来捕获丰富的语义信息,通过对不同的分辨率进行特征池化来实现,第二个结构用来获得更加准确的边界。在具体实现中,DeepLabV3+应用了几个并行的,伴随不同速率的Atrous convolution,被称为Atrous空间金字塔池化(ASPP), 同时使用PSPNet[6]在不同的网格尺度执行池化运算。作者在介绍中谈到,只使用池化技术,其计算效率,对分辨率的鲁棒性会存在缺陷。但是组合了编解码器,问题会被明显改善。而DeepLabV3+相比DeepLabV3的主要性能提升,就在于引入了编解码器,以解决不同分辨率下的特征抽取精度,获得更好的边界信息,如图2C部分所示。总结本文贡献,包括:提出一个基于DeepLabv3的编解码器;任意的分辨率控制;在分割任务中使用了Xception模型,结合ASPP以及解码模块,建立了效率更高,准确率更好的编解码网络。
注:在我看来,本文的主要贡献就是在特征抽取与分析过程,利用编解码器,解决多分辨率问题,强化了特征精度,以获得更好的分割边界。
基于Atrous Convolution的编解码
Atrous convolution用来精确控制特征的分辨率。该结构通过深度神经网络和调节卷积层的视野,实现对多尺度信息的捕获,建立标准的卷积运算。在二维信号处理中,对于输出特征图y和一个卷积层w的一个位置i,atrous convolution被应用在输入特征图x的对应位置:
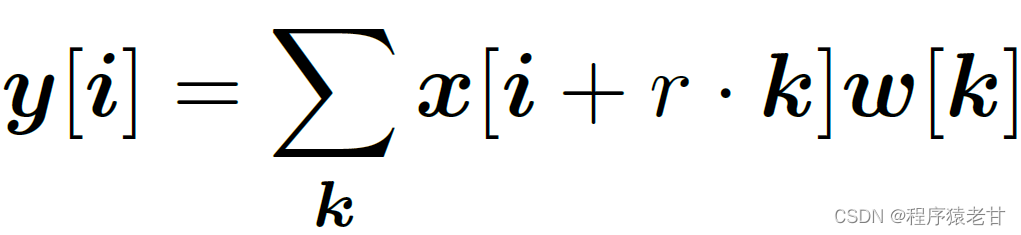
其中,atrous速率r决定我们采样输入信号的步调,更详细的信息参看文献[8]。
Depthwise分离卷积将一个标准卷积分解为Depthwise卷积,结合pointwise卷积,以减少计算开销。在Atrous卷积中引入depthwise卷积,就构成了Atrous depthwise卷积,如图3C所示。这里我没有深入的去研究什么是Depthwise以及Atrous,直观的理解就是一种多尺度卷积方法。
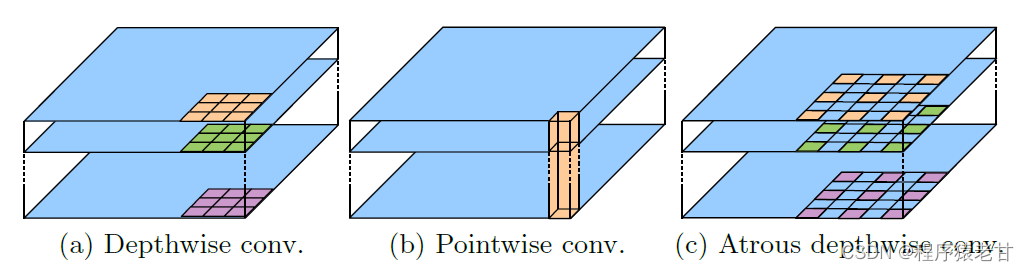
图3. Depthwise分离卷积示意图。
如前所述,DeepLabV3的编码器用以学习语义特征。一般的,最终特征图的空间分辨率要小于输入图像的分辨率(差32倍),即输出步频(Output stride)为32。对于语义分割任务,可以通过移除最后一个或两个block以防止特征压缩,进而输出更低的步频16或8,获得更密的分辨率。本文在最后两个block中实际使用的速率为2和4,对应输出步频为8。这里我没明白rate和Output stride的关系,但是应该是有对应的,整体就是一个特征压缩程度的描述。最终,编码器输出包含256个通道的特征图以及丰富的语义信息。利用Atrous convolution,可以对任意分辨率数据进行特征提取,这依赖于计算开销。
解码器是本文的核心创新点。如图4所示,通过编码器获得的特征,利用双线性上采样首先计算一个4倍的超采,并连接到之前利用1*1卷积(用以减少通道数)获得的低级特征。然后再用一个3*3的卷积来提升特征,再用一个双线性上采样,得到一个新的4倍超采。这里的两次提升用于平衡之前的Output stride。图4展示了整个编解码过程的细节。

图4. DeepLabV3+的编解码结构。
修改后的 Aligned Xception
Xception model[9] 已经被证明在图像分类任务中的性能。MSRA的团队改善了Xception model,提出Aligned Xception[10]。DeepLabV3对Aligned Xception做了一点调整,以获得更好的效果,包括更深的Xceoption;所有的最大池化操作被替换为跨步的depthwise separable convolution,使得可以利用atrous separable 卷积在任意分辨率提取特征;额外的batch normalization以及ReLU激活被添加到3*3的depthwise卷积,类似于MobileNet[11]的设计。整个结构如图5所示。
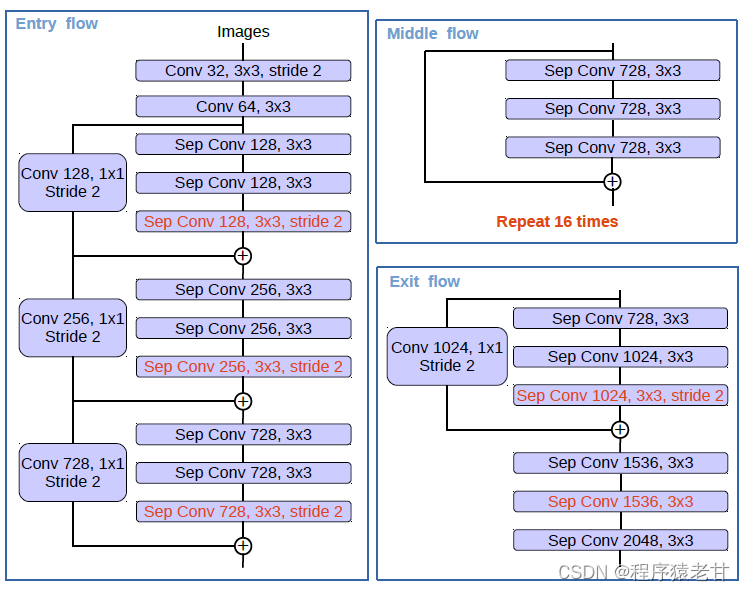
图5. Xception model结构。
我使用的代码并非原文章提供的代码,而是用pytorch重写的。
项目链接:https://github.com/VainF/DeepLabV3Plus-Pytorch
环境配置:基于Python3.8,requirement包含的相关包为torch, torchvosion, numpy, pillow, pcikit-learn, tqdm, matplotlib, visdom。我在pycharm里没有指定版本,直接就是默认pip安装。我把列表放在这里,供参考。

数据下载:
原始的数据库包括Pascal VOC2012和Cityscapes。可以不用下载原库,而直接使用预训练参数模型, 地址为:
HRNet backbone:谷歌云盘链接
所有预训练模型:腾讯微云网盘链接
程序调用命令:
python predict.py
--input samples/1_image.png #输入图片
--dataset cityscapes #训练数据集,街道cityscapes, 一般图片voc
--model deeplabv3plus_mobilenet #选择网络模型
--ckpt checkpoints/best_deeplabv3plus_mobilenet_cityscapes_os16.pth #选择预训练参数
--save_val_results_to test_results #输出路径网络模型可以参看下表:
| DeepLabV3 | DeepLabV3+ |
|---|---|
| deeplabv3_resnet50 | deeplabv3plus_resnet50 |
| deeplabv3_resnet101 | deeplabv3plus_resnet101 |
| deeplabv3_mobilenet | deeplabv3plus_mobilenet |
| deeplabv3_hrnetv2_48 | deeplabv3plus_hrnetv2_48 |
| deeplabv3_hrnetv2_32 | deeplabv3plus_hrnetv2_32 |
对应的预训练参数文件列表为:
可以看到,网络结构包括resnet50,101和mobilenet。原文章推荐使用mobilenet。
然后我们来看一下预测代码predict.py:
# Set up model (all models are 'constructed at network.modeling)
model = network.modeling.__dict__[opts.model](num_classes=opts.num_classes, output_stride=opts.output_stride)
if opts.separable_conv and 'plus' in opts.model:
network.convert_to_separable_conv(model.classifier)
utils.set_bn_momentum(model.backbone, momentum=0.01)
if opts.ckpt is not None and os.path.isfile(opts.ckpt):
# https://github.com/VainF/DeepLabV3Plus-Pytorch/issues/8#issuecomment-605601402, @PytaichukBohdan
checkpoint = torch.load(opts.ckpt, map_location=torch.device('cpu'))
model.load_state_dict(checkpoint["model_state"])
model = nn.DataParallel(model)
model.to(device)
print("Resume model from %s" % opts.ckpt)
del checkpoint
else:
print("[!] Retrain")
model = nn.DataParallel(model)
model.to(device)
#denorm = utils.Denormalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # denormalization for ori images
if opts.crop_val:
transform = T.Compose([
T.Resize(opts.crop_size),
T.CenterCrop(opts.crop_size),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
else:
transform = T.Compose([
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
if opts.save_val_results_to is not None:
os.makedirs(opts.save_val_results_to, exist_ok=True)
with torch.no_grad():
model = model.eval()
for img_path in tqdm(image_files):
ext = os.path.basename(img_path).split('.')[-1]
img_name = os.path.basename(img_path)[:-len(ext)-1]
img = Image.open(img_path).convert('RGB')
img = transform(img).unsqueeze(0) # To tensor of NCHW
img = img.to(device)
#这句代码就是输入图像到model里,并输出对应的分割预测结果
pred = model(img).max(1)[1].cpu().numpy()[0] # HW
#这里是我添加的代码。pred存储了针对像素分类的结果
print(np.shape(pred))
#我把预测数据输入到一个txt文件中,以方便其他程序使用
np.savetxt(os.path.join(opts.save_val_results_to, img_name+'.txt'),pred)
colorized_preds = decode_fn(pred).astype('uint8')
colorized_preds = Image.fromarray(colorized_preds)
if opts.save_val_results_to:
colorized_preds.save(os.path.join(opts.save_val_results_to, img_name+'.png'))比较重要语句包括:
#这句代码就是输入图像到model里,并输出对应的分割预测结果
pred = model(img).max(1)[1].cpu().numpy()[0]
#这里是我添加的代码。pred存储了针对像素分类的结果
print(np.shape(pred))
#我把预测数据输入到一个txt文件中,以方便其他程序使用
np.savetxt(os.path.join(opts.save_val_results_to, img_name+'.txt'),pred)TXT 预测结果:

基于像素的分割可视化结果:




我发现DeepLabV3+的一作Liang-Chieh (Jay) Chen博士确实是个大佬,Google引用4万+,多年来一致深耕语义图像分割领域。最高引用文章为DeepLab[8],1万+。由此可见,坚持不懈,只做一个问题,也能开花结果。这哥们是台湾国立交通大学毕业的,查了一下,该学校理工实力还是蛮强的。联想到之前学习的PointNet的一作也是台湾人,平心一想,觉得台湾的学者还是很厉害的,原创能力和深耕能力都不容小觑。

针对图像语义分割这个研究方向,Liang-Chieh (Jay) Chen博士已经迭代了三个大版本的网络了。到了DeepLabV3+,基本确定了技术路线,大量的工作是在完善之前的模块。以我的看法,之后若想获得更大的进步,还是要引入图网络实现语义交叉感知学习,建立知识图谱向视觉的迁移。多尺度特征学习已经针对图像语义信息描述做到很好的性能了,对于混杂的像素信息,仅凭单对象训练结构,我觉得很难在推进精度。基于上下文的,更复杂的语义结构关联性信息,应该要作为下一代网络的研究重点,以便获得更加鲁棒与精准的分割模型。
[1] LC. Chen, Y. Zhu, G. Papandreou, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]. Proceedings of the European conference on computer vision (ECCV). 2018: 801-818.
[2] O. Ronneberger, P. Fischer, T. Brox. U-net: Convolutional networks for biomedical image segmentation[C]. International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
[3] M. Wang, B. Liu, H. Foroosh. Factorized convolutional neural networks[C]. Proceedings of the IEEE International Conference on Computer Vision Workshops. 2017: 545-553.
[4] K. Grauman, T. Darrell. The pyramid match kernel: Discriminative classification with sets of image features. In: ICCV (2005).
[5] V. Badrinarayanan, A. Kendall, R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. PAMI (2017).
[6] H. Zhao, J. Shi, X. Qi, et al. Pyramid scene parsing network. In: CVPR (2017).
[7] LC. Chen, G. Papandreou, F. Schroff, et al. Rethinking atrous convolution for semantic image segmentation. arXiv:1706.05587 (2017).
[8] LC. Chen, G. Papandreou, I. Kokkinos, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI (2017).
[9] F. Chollet. Xception: Deep learning with depthwise separable convolutions. In:CVPR (2017).
[10] H. Qi, Z. Zhang, B. Xiao, et al. Deformable convolutional networks - coco detection and segmentation challenge 2017 entry. ICCV COCO Challenge Workshop (2017).
[11] AG. Howard, M. Zhu, B. Chen, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861 (2017)
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p