 知识图谱是一种非常强大的表示工具,它可以通过一张图表达复杂的概念,这就是为什么常说“一图胜千言”。但是,如果我们在没有明确定义的模式下创建知识图谱,就会存在一些问题。这就是为什么需要一种模式来限制链接的类型,充当文档,提供和机器可读的语义,并确保软件按照预期的方式来组织信息。对于知识图谱而言,良好的模式设计比关系数据库更为重要和核心。不幸的是,对于如何完成相对简单的任务而言,目前缺乏详细的指导。根据我的经验,我想至少提供一些帮助。为了更好地了解模式设计的模式和原则,我们可以使用TerminusCMS。虽然其中许多想法也适用于其他领域。
知识图谱是一种非常强大的表示工具,它可以通过一张图表达复杂的概念,这就是为什么常说“一图胜千言”。但是,如果我们在没有明确定义的模式下创建知识图谱,就会存在一些问题。这就是为什么需要一种模式来限制链接的类型,充当文档,提供和机器可读的语义,并确保软件按照预期的方式来组织信息。对于知识图谱而言,良好的模式设计比关系数据库更为重要和核心。不幸的是,对于如何完成相对简单的任务而言,目前缺乏详细的指导。根据我的经验,我想至少提供一些帮助。为了更好地了解模式设计的模式和原则,我们可以使用TerminusCMS。虽然其中许多想法也适用于其他领域。{ "@type" : "Class",
"@id" : "Person",
"first_name" : "xsd:string",
"family_name" : "xsd:string",
"date_of_birth" : "xsd:dateTime"
}{ "@type" : "Class",
"@id" : "Person",
"first_name" : "xsd:string",
"family_name" : "xsd:string",
"date_of_birth" : "xsd:dateTime",
"friends" : { "@type" : "Set", "@class" : "Person" }
}{ "@type" : "Enum",
"@id" : "Unit",
"@value" : [ "meters", "kilograms" ] }
{ "@type" : "Class",
"@id" : "UnitValue",
"@subdocument" : [],
"value" : "xsd:decimal",
"unit" : "Unit" }{ "@type" : "Class",
"@id" : "Person",
"first_name" : "xsd:string",
"family_name" : "xsd:string",
"date_of_birth" : "xsd:dateTime",
"friends" : { "@type" : "Set", "@class" : "Person" }
"height" : "UnitValue",
"weight" : "UnitValue",
}{ "@type" : "Class",
"@id" : "Company",
"name" : "xsd:string" }
{ "@type" : "Class",
"@id" : "Shareholder",
"name" : "xsd:string" }
{ "@type" : "Class",
"@id" : "Company",
"@inherits" : "Shareholder" }
{ "@type" : "Class",
"@id" : "Person",
"@inherits" : "Shareholder" }
{ "@type" : "Class",
"@id" : "Shareholding",
"quantity" : "xsd:decimal",
"shares_in" : "Company",
"held_by" : "Shareholder",
"from" : "xsd:date",
"to" : { "@type" : "Optional", "@class" : "xsd:date" }}{ "@type" : "Class",
"@id" : "TemporalScope"
"from" : "xsd:date",
"to" : { "@type" : "Optional", "@class" : "xsd:date" }
}{ "@type" : "Class",
"@id" : "Event"
"at" : "xsd:date"
}{ "@type" : "Class",
"@id" : "GeographicScope",
"geometry" : "Geometry" }{ "@type" : "Class",
"@id" : "Source",
"source" : "xsd:anyURI"
}
{ "@type" : "Class",
"@id" : "WebScrape",
"@inherits" : ["Event", "Source"],
"page" : "xsd:string",
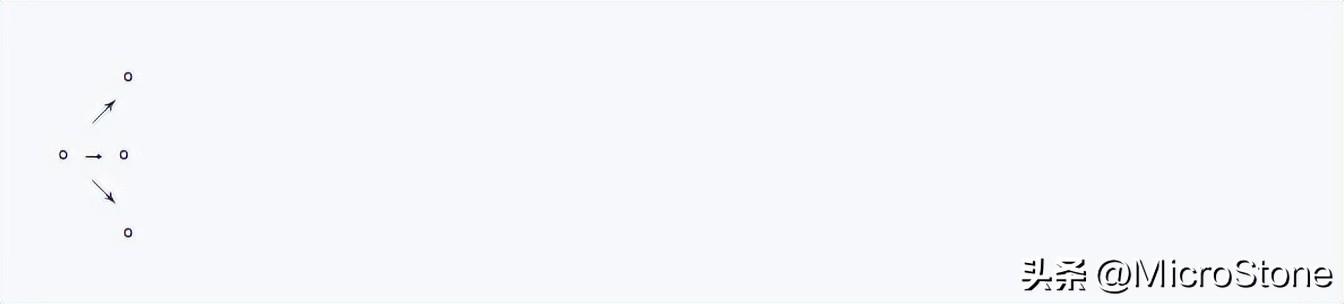
}
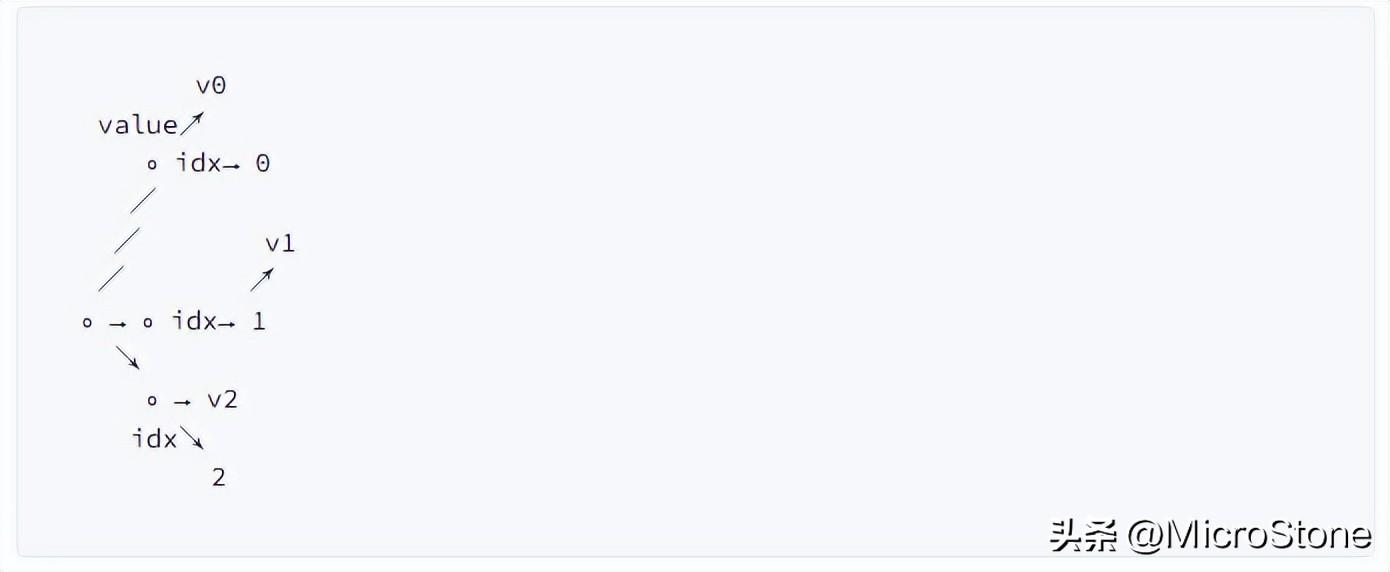 数组中的每个值元素都有一个附加的(隐藏)间接对象,带有索引(或多维数组的多个索引)。这使得我们不仅可以有顺序,还可以有多个维度来表示“间隔”。当返回 JSON 中的值时,我们将返回一个多维数组,其中包含未填充区域的null字段。但实际上,这些未填充区域并没有在数据库中出现。
数组中的每个值元素都有一个附加的(隐藏)间接对象,带有索引(或多维数组的多个索引)。这使得我们不仅可以有顺序,还可以有多个维度来表示“间隔”。当返回 JSON 中的值时,我们将返回一个多维数组,其中包含未填充区域的null字段。但实际上,这些未填充区域并没有在数据库中出现。∘ → ∘ rest→ ∘ rest→ ∘ rest→ rdf:nil
↓ first ↓ first ↓ first
v0 v1 v2总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此