文章目录
体验了一下new bing,很不错,但是最近觉得这种模型还是搭建在自己电脑上最好,看了下github上的chatGLM项目,这个项目在致力于将一个大语言模型搭建在个人机上,我对此惊叹不已,就按照其流程下载下来搭建在自己电脑上了,这种模型运行在自己电脑上的感觉不会有那种隐私被偷窥的感觉,同时自己可以对其进行自定义优化,很好
首先感谢ChatGPT,终于不用在搜索引擎的各种垃圾信息堆里找食吃了,不用再看各种妖魔鬼怪装逼了
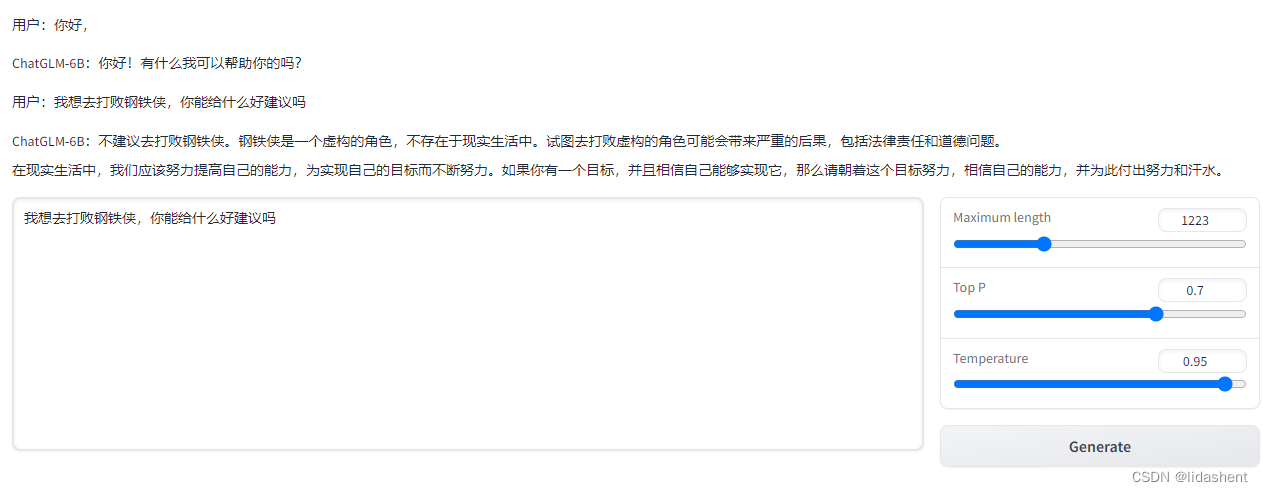
随意交谈,同时也可以让其归纳语言和写代码,很不错
电脑配置环境:
可是怎么事先知道那个版本的windows系统,显卡型号,pytorch版本,python版本,cuda,cudnn是相互配合的呢?
先看显卡,看看显卡支持到哪里?
找到nvidia控制面板,看一下支持的cuda版本信息,要小于显卡所标识的最大版本号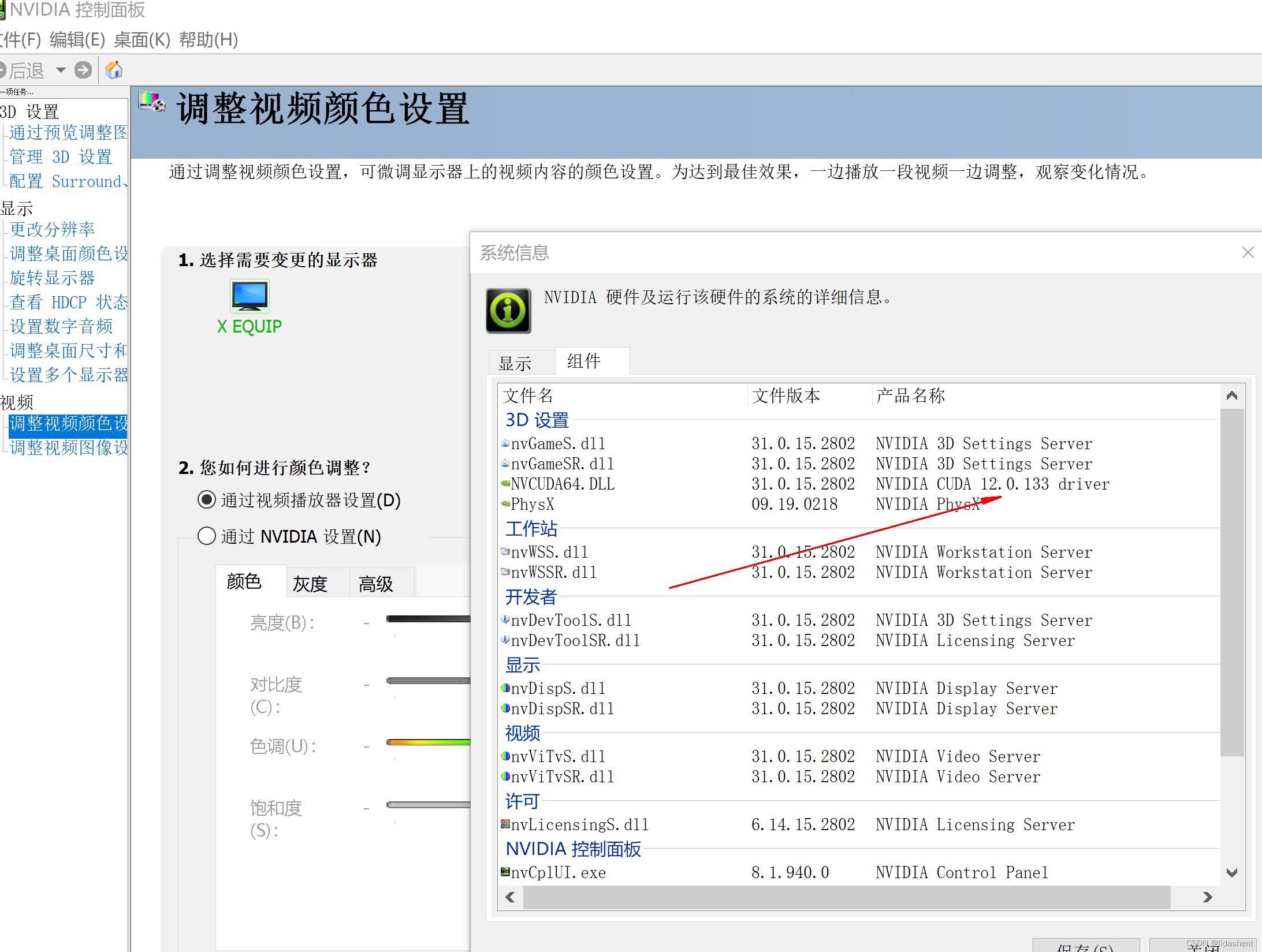
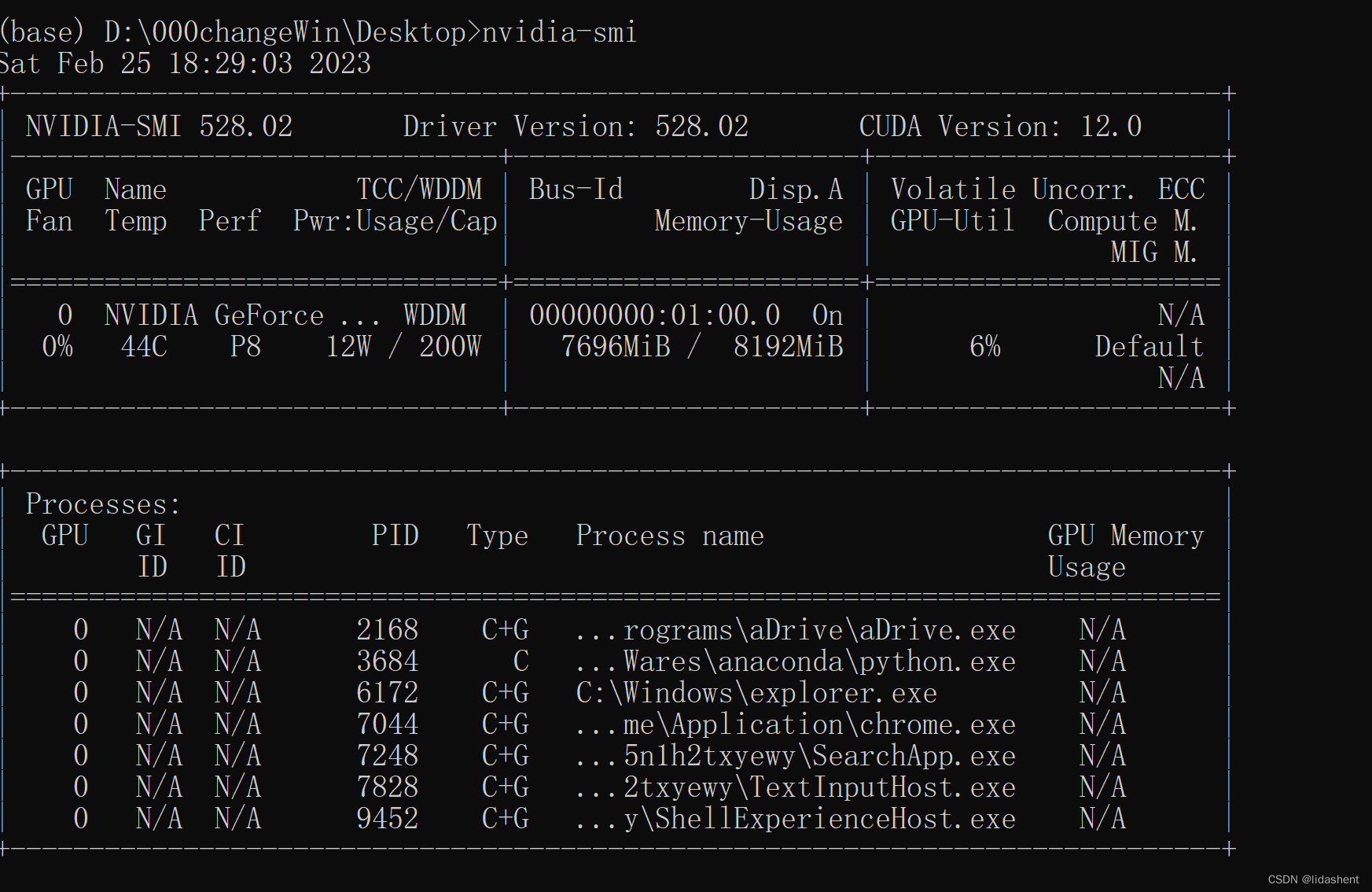
cmd输入nvidia-smi,查询驱动器版本号,
心中已经对显卡支持的版本有了大致了解,然后去pytorch官网,他们给的有版本配置单,按着来就行了
https://pytorch.org/get-started/locally/
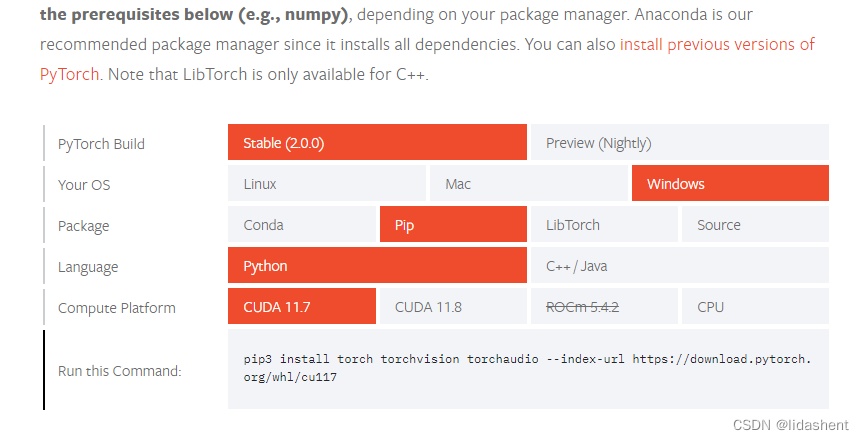
哦吼,完美支持,我cuda12.0的,向下兼容,去英伟达官网安装cuda11.7的加速计算包完全可行
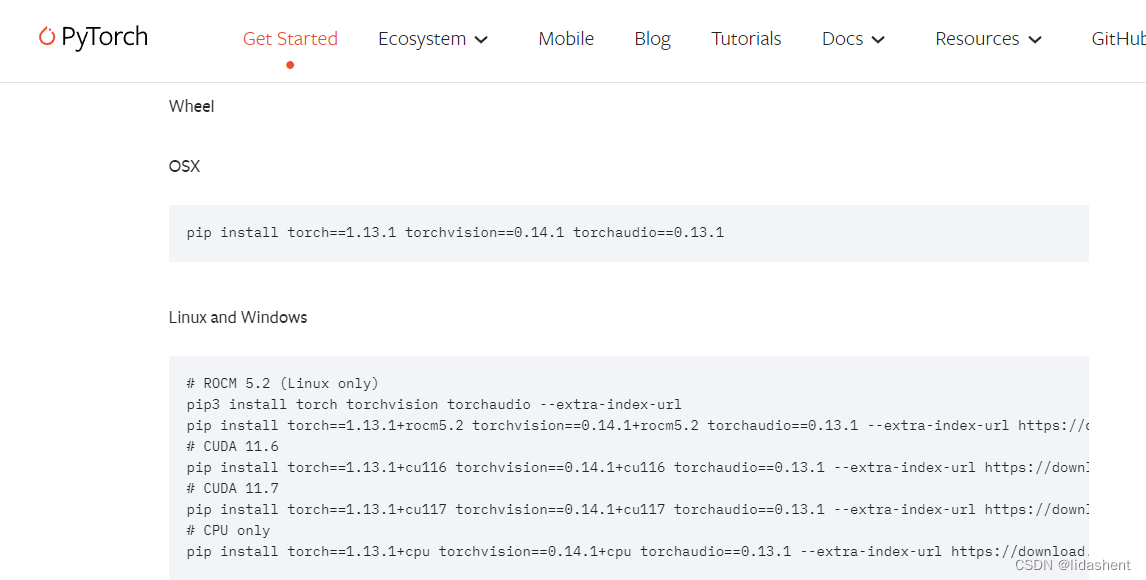
有的人电脑配置不行,就去看历史版本,如果不支持cuda11.7,就去看历史版本,看相关配置
https://pytorch.org/get-started/previous-versions/
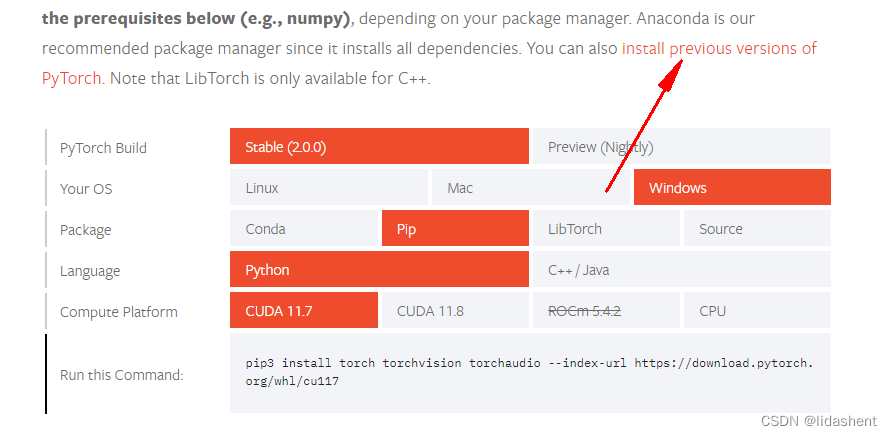
既然支持cuda11.7,那就去英伟达官网去下载cuda11.7安装包
https://developer.nvidia.com/cuda-downloads
选择历史版本
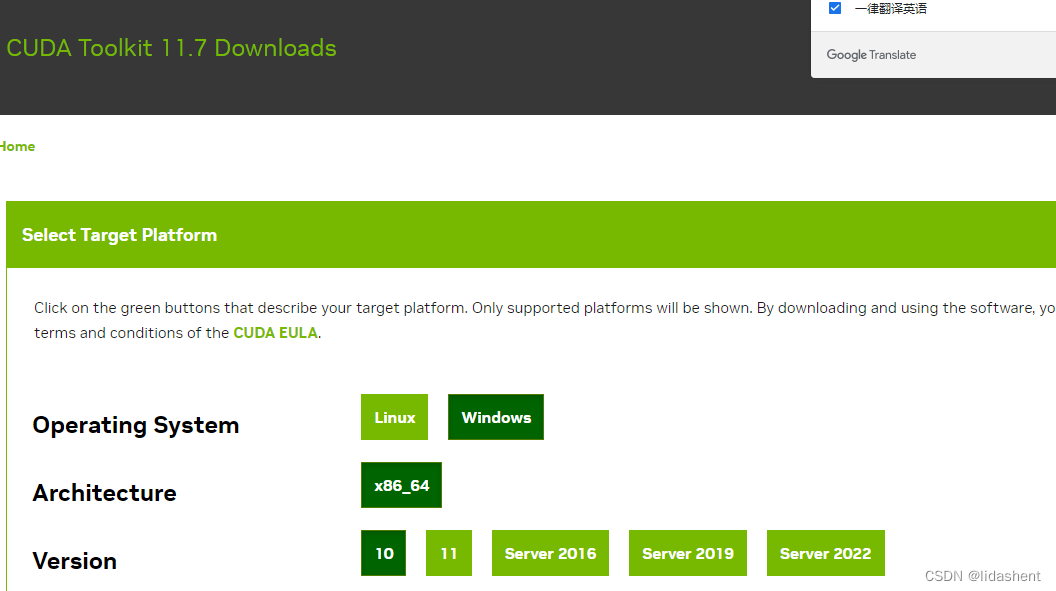
然后下载所需版本即可,比如我这里的cuda11.7
然后再下载cudnn,找到和cuda11.7配套的
https://developer.nvidia.com/rdp/cudnn-download
需要注意的是下载cudnn需要登陆

然后cuda和cudnn就下载好了,但是先别急着安装,还需要安装vs2019和anaconda,
不安装vs2019 cuda无法安装成功,不安装anaconda不容易安装pytorch
先把这两个重要文件安装下

cuda安装需要vs环境,适配的组件在vs2019中都具备了,因此要先安装vs2019
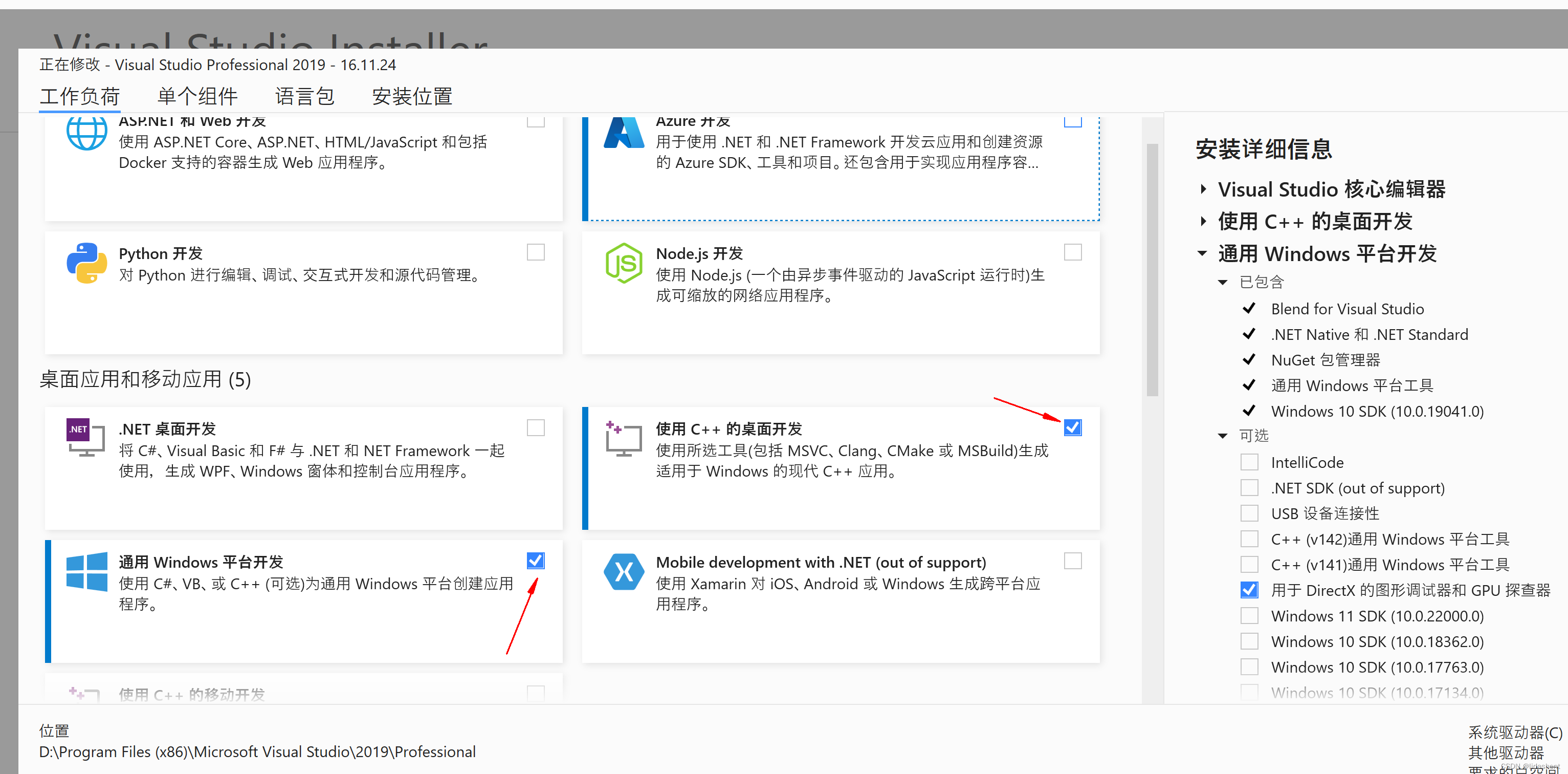
需要注意的是在安装时勾选以下组件,否则还是没有cuda运行环境
从网上下载个vs2019安装器,然后勾选如下即可,等待安装完成
cuda第一开始显示的文件路径框是自解压,选择一个空白文件夹即可,安装完毕后其会将解压的文件自动删除
然后没什么可说的,要注意选择自定义,全部勾选,下一步下一步
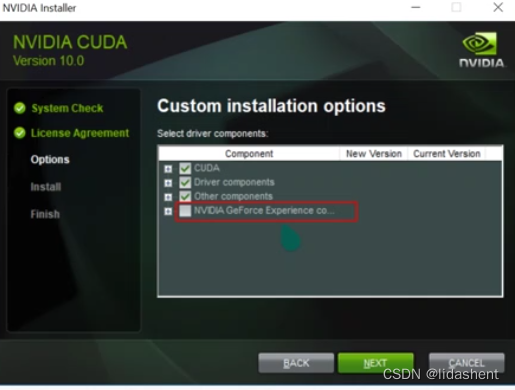
安装后看一下如下路径是否有此驱动(这是以前的老图,大差不差,路径类似,无非是11.0换成11.7,cupti64后换个日期)
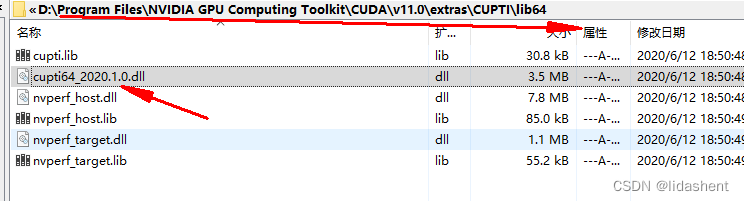
然后配置系统变量,需要注意的是path的搜索有先后顺序,如果搜索到前面的,后面的就会被忽略
如果有多个cuda版本,应该把最需要的cuda版本放在上面,比如安装了cuda11.7和cuda11.0的,就有扫描顺序先后之分,如果想要执行cuda11.7就需要把配置路径放在前面
我自定义了路径,安装到d盘了,可能大家看着dev,doc不是很懂,其实就是development和document文件夹,我自定义文件夹了
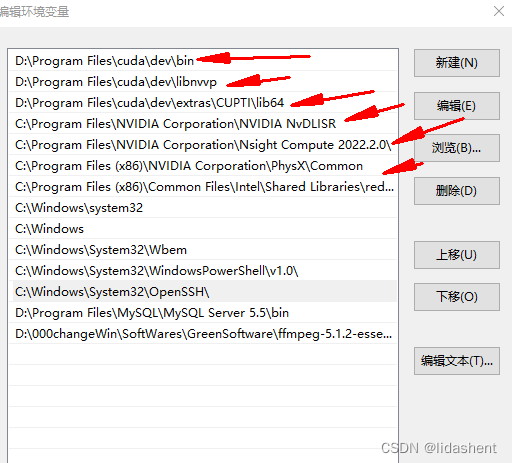
其实就是解压的文件夹,将cudnn中的三个文件复制放入cuda的安装目录如下
cudnn解压后的文件夹,全选复制一下
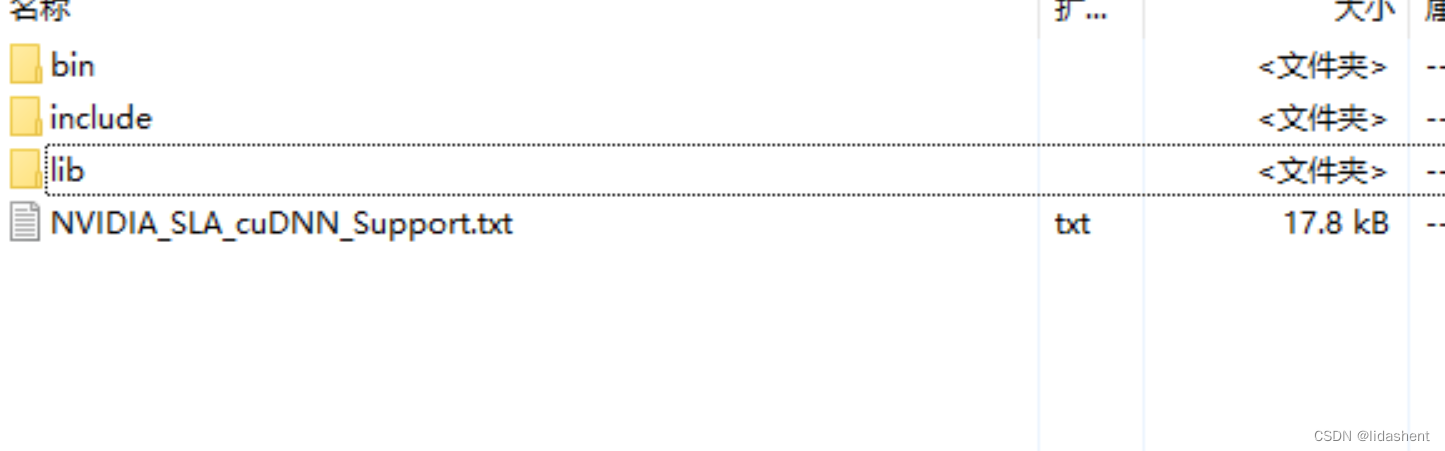
粘贴到cuda安装目录(以前的老图,方便理解)
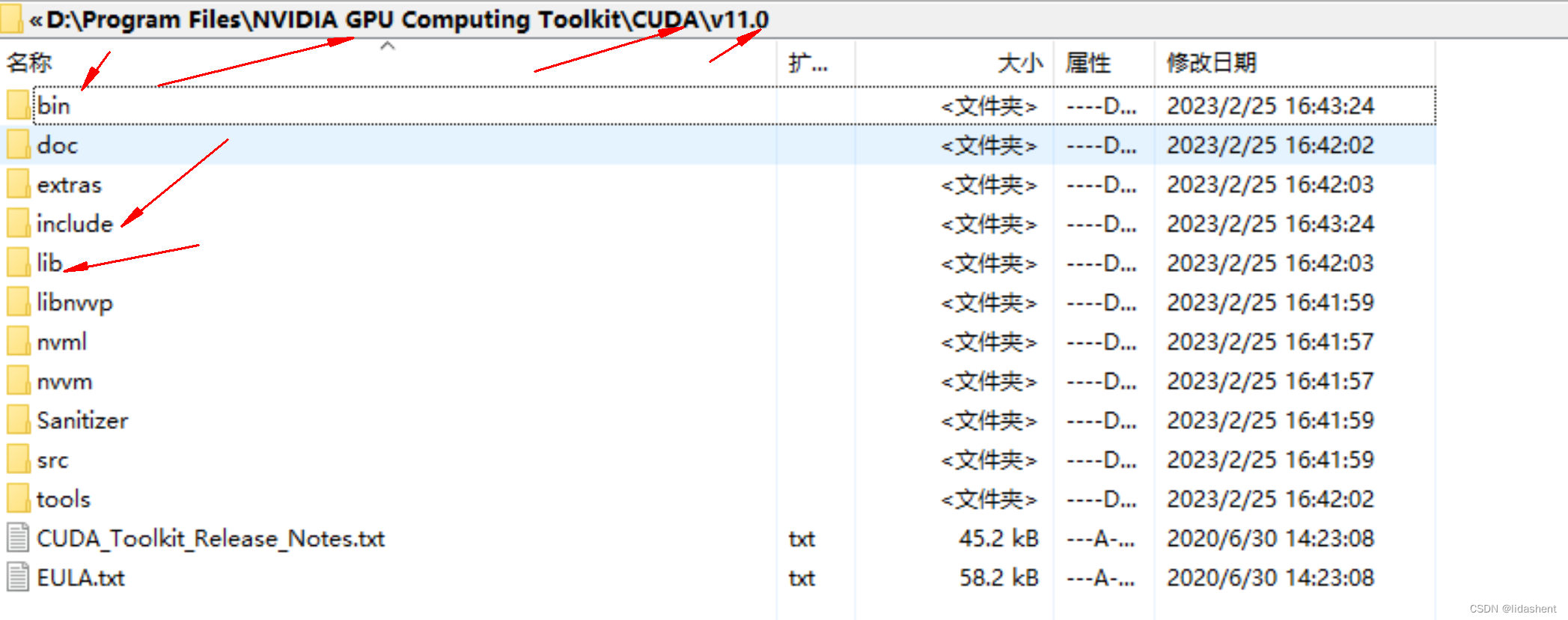
然后cmd输入nvcc看看战绩
至此,cudnn和cuda,python就安装好了,版本之间的对应关系要注意对应,否则互相不兼容
还记得去pytorch官网查配置时底下的命令行吗?输入anaconda就能从他们官网自动下载配置了


等待自动配置安装即可
然后进入pycharm找个命令测试下是否可以运行
import torch
print(torch.__version__):查看torch版本
print(torch.cuda.is_available()):看安装好的torch和cuda能不能用,也就是看GPU能不能用
提示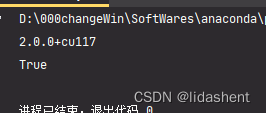
配置成功
然后进入github官网,下载ChatGlm工程
https://github.com/THUDM/ChatGLM-6B
downloadZip即可
下载然后解压,执行
pip install -r requirements.txt
等待其自动结束配置,
然后运行示例代码等待自动配置即可见到效果
如果需要网页版交流,就使用web_demo.py
以后会更新如何训练此类似模型,仿写以及调优
使用过程中实际会发现,运行话语多句之后内存溢出就会崩,实际上,可以单次提问,相当于浏览器的一问一答模式
聊天会丧失记忆,但是用于代写代码很不错
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
model = model.eval()
def toChat(speechWords):
response, history = model.chat(tokenizer, speechWords, history=[])
print(response)
while(1):
speechWords=input("用户:\n")
print("AI思考中...")
toChat(speechWords)
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur