文章目录
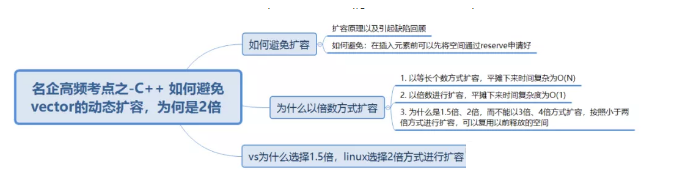
在面试时vector的扩容问题会经常被问到,比如:
一系列问题下来,是否有种被吊打的感觉呢?本节我们再来深究vector扩容背后所包含的细节问题,让你的面试不再尴尬。
当向vector中插入元素时,如果元素有效个数size与空间容量capacity相等时,vector内部会触发扩容机制:
开辟新空间
注意:每次扩容新空间不能太大,也不能太小,太大容易造成空间浪费,太小则会导致频繁扩容而影响程序效率。
如果要避免扩容而导致程序效率过低问题,其实非常简单:如果在插入之前,可以预估vector存储元素的个数,提前将底层容量开辟好即可。如果插入之前进行reserve,只要空间给足,则插入时不会扩容,如果没有reserve,则会边插入边扩容,效率极其低下。
#include <iostream>
#include <vector>
int main ()
{
size_t sz;
std::vector<int> foo;
// foo.reserve(100); // 先将vector底层空间扩增到100个,然后插入
sz = foo.capacity();
std::cout << "making foo grow:\n";
for (int i=0; i<100; ++i)
{
foo.push_back(i);
if (sz!=foo.capacity())
{
sz = foo.capacity();
std::cout << "capacity changed: " << sz << '\n';
}
}
}
vs:运行结果:
making foo grow:
capacity changed: 1
capacity changed: 2
capacity changed: 3
capacity changed: 4
capacity changed: 6
capacity changed: 9
capacity changed: 13
capacity changed: 19
capacity changed: 28
capacity changed: 42
capacity changed: 63
capacity changed: 94
capacity changed: 141
g++运行结果:
making foo grow:
capacity changed: 1
capacity changed: 2
capacity changed: 4
capacity changed: 8
capacity changed: 16
capacity changed: 32
capacity changed: 64
capacity changed: 128
等长个数方式扩容,新空间大小就是将原空间大小扩增到capacity+K个空间(capacity为旧空间大小)。假设需要向vector中插入100个元素,K为10,那么就需要扩容10次;每次扩容都需要将旧空间元素搬移到新空间,第i次扩容拷贝的元素数量为:ki(第1次扩容,新空间大小为20,旧空间中有10个元素,需要搬移到新空间中;第2次扩容,新空间大小为30,旧空间中有20个元素,需要全部搬移到新空间中),假设元素插入与元素搬移为1个单位操作,则n个元素push_back()的总操作次数为:

假设有n个元素需要像vector插入,倍增因子为m,则完成n个元素像vector的push_back操作需要扩容log以m为低n的次方。比如:以二倍方式扩容,当向vector插入1000个元素,需要扩容log以2为底1000次方,就是扩容10次,第i次增容会把m的i次方个元素搬移到新空间,n次push_back的总操作次数为:

可以看到以倍数的方式扩容比以等长个数的扩容方式效率高。
扩容原理为:申请新空间,拷贝元素,释放旧空间,理想的分配方案是在第N次扩容时如果能复用之前N-1次释放的空间就太好了,如果按照2倍方式扩容,第i次扩容空间大小如下:

可以看到,每次扩容时,前面释放的空间都不能使用。比如:第4次扩容时,前2次空间已经释放,第3次空间还没有释放(开辟新空间、拷贝元素、释放旧空间),即前面释放的空间只有1 + 2 = 3,假设第3次空间已经释放才只有1+2+4=7,而第四次需要8个空间,因此无法使用之前已释放的空间,但是按照小于2倍方式扩容,多次扩容之后就可以复用之前释放的空间了。如果倍数超过2倍(包含2倍)方式扩容会存在:
空间浪费可能会比较高,比如:扩容后申请了64个空间,但只存了33个元素,有接近一半的空间没有使用。
无法使用到前面已释放的内存。

使用2倍(k=2)扩容机制扩容时,每次扩容后的新内存大小必定大于前面的总和。
而使用1.5倍(k=1.5)扩容时,在几次扩展以后,可以重用之前的内存空间了。
因为STL标准并没有严格说明需要按何种方式进行扩容,因此不同的实现厂商都是按照自己的方式扩容的,即:linux下是按照2倍的方式扩容的,而vs下是按照1.5倍的方式扩容的。
Windows中堆管理系统会对释放的堆块进行合并,因此:vs下的vector扩容机制选择使用1.5倍的方式扩容,这样多次扩容之后,就可以使用之前已经释放的空间。


目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
有没有办法在Ruby中动态创建数组?例如,假设我想遍历用户输入的书籍数组:books=gets.chomp用户输入:"TheGreatGatsby,CrimeandPunishment,Dracula,Fahrenheit451,PrideandPrejudice,SenseandSensibility,Slaughterhouse-Five,TheAdventuresofHuckleberryFinn"我把它变成一个数组:books_array=books.split(",")现在,对于用户输入的每一本书,我想用Ruby创建一个数组。伪代码来做到这一点:x=0books_array.
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
我正在尝试动态构建一个多维数组。我想要的基本上是这样的(为简单起见写出来):b=0test=[[]]test[b]这给了我错误:NoMethodError:undefinedmethod`test=[[],[],[]]而且它工作正常,但在我的实际使用中,我不会事先知道需要多少个数组。有一个更好的方法吗?谢谢 最佳答案 不需要像您正在使用的索引变量。只需将每个数组附加到您的test数组:irb>test=[]=>[]irb>test[["a","b","c"]]irb>test[["a","b","c"],["d","e","f"]]
如何只加载map边界内的标记gmaps4rails?当然,在平移和/或缩放后加载新的。与此直接相关的是,如何获取map的当前边界和缩放级别? 最佳答案 我是这样做的,我只在用户完成平移或缩放后替换标记,如果您需要不同的行为,请使用不同的事件监听器:在你看来(index.html.erb):{"zoom"=>15,"auto_adjust"=>false,"detect_location"=>true,"center_on_user"=>true}},false,true)%>在View的底部添加:functiongmaps4rail
如何在对象上调用方法名称的嵌套哈希?例如,给定以下哈希:hash={:a=>{:b=>{:c=>:d}}}我想创建一个方法,给定上面的散列,执行以下操作:object.send(:a).send(:b).send(:c).send(:d)我的想法是我需要从一个未知的关联中获取一个特定的属性(这个方法不知道,但程序员知道)。我希望能够指定一个方法链来以嵌套哈希的形式检索该属性。例如:hash={:manufacturer=>{:addresses=>{:first=>:postal_code}}}car.execute_method_hash(hash)=>90210
我有一个ruby程序,我想接受用户创建的方法,并使用该名称创建一个新方法。我试过这个:defmethod_missing(meth,*args,&block)name=meth.to_sclass我收到以下错误:`define_method':interningemptystring(ArgumentError)in'method_missing'有什么想法吗?谢谢。编辑:我以不同的方式让它工作,但我仍然很好奇如何以这种方式做到这一点。这是我的代码:defmethod_missing(meth,*args,&block)Adder.class_evaldodefine_method
假设我们有A、B、C类。Adefself.inherited(sub)#metaprogramminggoeshere#takeclassthathasjustinheritedclassA#andforfooclassesinjectprepare_foo()as#firstlineofmethodthenrunrestofthecodeenddefprepare_foo#=>prepare_foo()neededhere#somecodeendendBprepare_foo()neededhere#somecodeendend如您所见,我正在尝试将foo_prepare()调用注入
这里我想输出带有动态组名的json而不是单词组@tickets.eachdo|group,v|json.group{json.array!vdo|ticket|json.partial!'tickets/ticket',ticket:ticketend}end@ticket是这样的散列{a:[....],b:[.....]}我想要这样的输出{a:[.....],b:[....]} 最佳答案 感谢@AntarrByrd,这个问题有类似的答案:JBuilderdynamickeysformodelattributes使用上面的逻辑我已经