稀疏矩阵几乎产生于所有的大型科学工程计算领域,记录样本特征值的稠密矩阵中很多记录值都是0,由于0不携带信息,因此耗费空间存储0元素是很浪费资源的行为。而且很多计算只对非零元素进行操作,将特征矩阵构建成稀疏矩阵,可以很容易的索引到非零元素,所以基于稀疏矩阵的数据运算,可是实现更低的资源占用和更快的计算速度。
在单细胞领域,稀疏矩阵对于处理 scRNA-seq 表达谱数据是非常必要的,构建分析对象的时候它们消耗更低的内存。本文重点介绍 R语言 稀疏矩阵对象格式, 稀疏矩阵与稠密矩阵的相互转换。
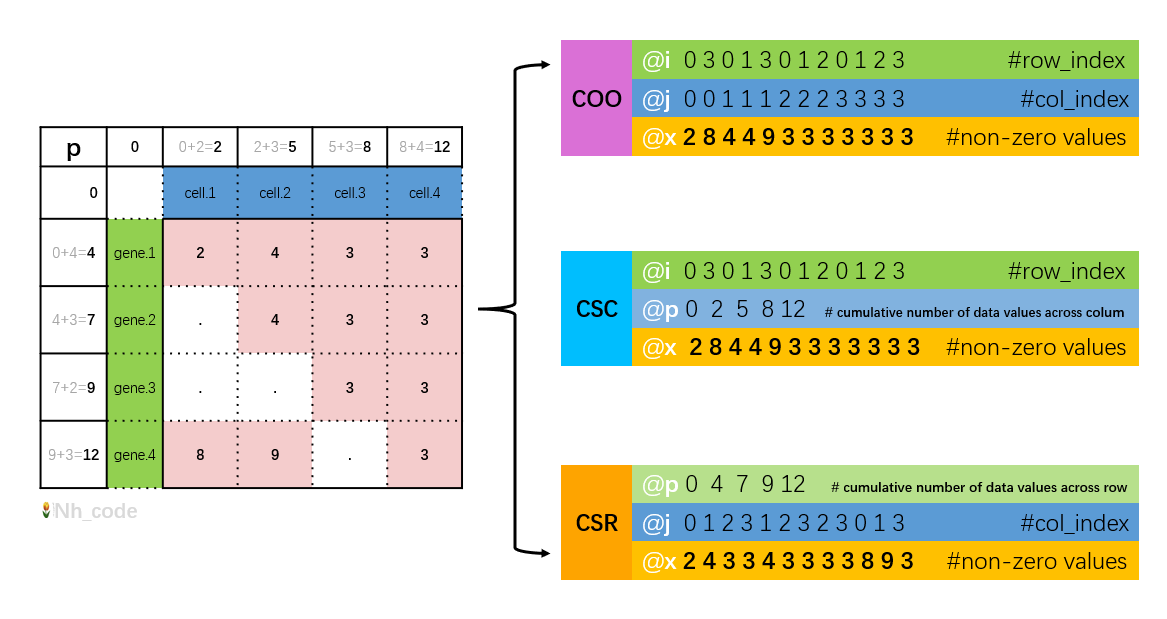
首先,稀疏矩阵的一般格式主要有三种:
(i,j,x)的形式记录非零条目
i## 非零元素的行号【0-based索引值】j## 非零元素的列号【0-based索引值】x## 按列向量方向排列的非零元素 值(从左到右)(i,p,x)的形式记录非零条目
i## 非零元素的行号【0-based索引值】p## 从0开始, 记录值是对每列非零元素的个数的累加(从左到右)x## 按列向量方向排列的非零元素 值 (从左到右)p## 从0开始, 记录值是对每行非零元素的个数的累加(从上到下)j## 非零元素的列号【0-based索引值】x## 按行向量方向排列的非零元素 值 (从上到下)Matrix 包为扩展基本矩阵数据类型的密集和稀疏矩阵提供了一组 S4 类和应用于这些类对象的各种函数和运算符方法。>Matrix package - RDocumentation
install.packages("Matrix") ; library(Matrix)
构建一个测试用稠密矩阵:
library(dplyr)
counts <- data.frame(cell.1=c(2,0,0,8), cell.2=c(4,4,0,9),cell.3=c(3,3,3,0),cell.4=c(3,3,3,3),row.names = paste0("gene.",seq(4))) %>% as.matrix()
> counts
cell.1 cell.2 cell.3 cell.4
gene.1 2 4 3 3
gene.2 0 4 3 3
gene.3 0 0 3 3
gene.4 8 9 0 3
> print( paste0("矩阵非零元素个数 ", sum( colSums(counts != 0)) ," 个") )
[1] "矩阵非零元素个数 12 个"
> is(counts, 'sparseMatrix') #判断为非 稀疏矩阵 对象
[1] FALSE
as( )方法转换 稠密矩阵
⇒
\Rightarrow
⇒ 稀疏矩阵sparse.gbm.T <- as(counts, "dgTMatrix") ### convert to coo_matrix
sparse.gbm.C <- as(counts, "dgCMatrix") ### convert to csc_matrix
sparse.gbm.R <- as(counts, "dgRMatrix") ### convert to csr_matrix
创建列压缩的稀疏矩阵(csc_matrix)还可以用方法sparse.gbm <- Matrix::Matrix(counts, sparse = T),但是该方法在大型矩阵中较为低效。
三种稀疏矩阵对象在R语言中的结构str(sparse.gbm.*)
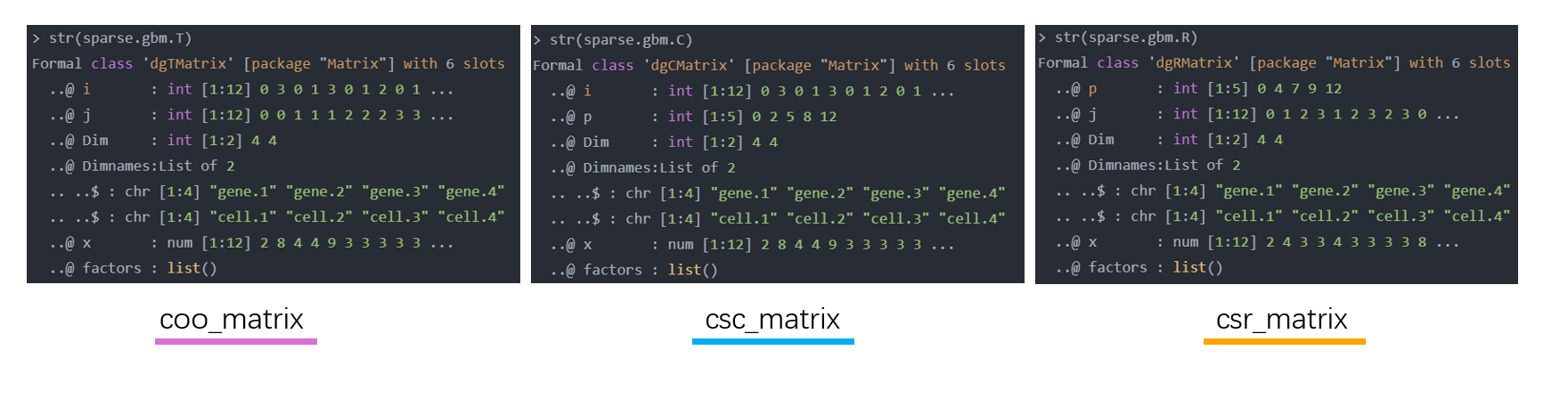
关于压缩格式的稀疏矩阵对象中数据结构的 sparse.gbm.C@p向量,该向量不是非零元素的行/列索引编号,它的值是对 数据压缩方向上 每个向量内非零元素个数的累加(如创建列压缩稀疏矩阵时,压缩方向为按列 向左到右 移动)。p向量的记录方式相比i/j记录非零元素索引号,有助于进一步减少稀疏矩阵对象存储大小。

对于任意矩阵,都可以计算p
列向量的p c(0, cumsum(colSums(counts != 0)))
行向量的p c(0, cumsum(rowSums(counts != 0)))
通过p可以解析出 压缩方向的 真是索引编号(i/j)
#通过 p向量 解析出 列压缩稀疏矩阵的 向量j [记录了每个非零元素的列编号]
> rep(1:sparse.gbm.C@Dim[2], diff(sparse.gbm@p))
[1] 1 1 2 2 2 3 3 3 4 4 4 4
> sparse.gbm.C@i
[1] 0 3 0 1 3 0 1 2 0 1 2 3
> sparse.gbm.C@x
[1] 2 8 4 4 9 3 3 3 3 3 3 3
> sparse.gbm.C@j
Error: no slot of name "j" for this object of class "dgCMatrix"
#列压缩的稀疏矩阵用p向量记录了元素的列索引编号j,所以没有向量j
as( )方法转换 稀疏矩阵
⇒
\Rightarrow
⇒ 稠密矩阵 >as.matrix(sparse.gbm.T)
cell.1 cell.2 cell.3 cell.4
gene.1 2 4 3 3
gene.2 0 4 3 3
gene.3 0 0 3 3
gene.4 8 9 0 3
sparse.gbm.C.new <- Matrix::sparseMatrix(
i = sparse.gbm.C@i + 1 , # +1 转换 0-based编号 为R语言 1-based 编号方式
p = sparse.gbm.C@p ,
x = sparse.gbm.C@x,
dims = sparse.gbm.C@Dim #矩阵的维度
)
注
意
:
\color{red}{注意:}
注意:由于dgCMatrix对象的行/列索引值 i / j 是【0-based】的,而R中数据对象(如data.frame,vector)的索引值都是 【1-based】 的,所以在通过Matrix::sparseMatrix重构稀疏矩阵的时候,i/j的索引值要加1转换为【1-based】
除了按S4的方法从对象中取三元组信息,通过Matrix::summary()方法可以快速获取稀疏矩阵S4对象的(i,j,x)三元组,并用于重构 sparse_matrix。
> as.data.frame(summary(sparse.gbm.C))
i j x
1 1 1 2
2 4 1 8
3 1 2 4
4 2 2 4
5 4 2 9
6 1 3 3
7 2 3 3
8 3 3 3
9 1 4 3
10 2 4 3
11 3 4 3
12 4 4 3
log2标准化: log2(sparse.gbm.C + 1 )
对行 求 和: Matrix::rowSums(sparse.gbm)
对行求均值: Matrix::rowMeans(sparse.gbm)
对列 求 和: Matrix::colSums(sparse.gbm)
对行求均值: Matrix::colMeans(sparse.gbm)
readMM( "matrix.mtx")writeMM(sparse.gbm.C, "matrix.mtx");system("gzip --keep matrix.mtx")参考资料
Working with a sparse matrix in R - Kamil Slowikowski (slowkow.com)
Instructions for using Python SciPy sparse matrix | Develop Paper
R convert matrix or data frame to sparseMatrix - Stack Overflow
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
我在Rails工作并有以下类(class):classPlayer当我运行时bundleexecrailsconsole然后尝试:a=Player.new("me",5.0,"UCLA")我回来了:=>#我不知道为什么Player对象不会在这里初始化。关于可能导致此问题的操作/解释的任何建议?谢谢,马里奥格 最佳答案 havenoideawhythePlayerobjectwouldn'tbeinitializedhere它没有初始化很简单,因为你还没有初始化它!您已经覆盖了ActiveRecord::Base初始化方法,但您没有调
我有一个服务模型/表及其注册表。在表单中,我几乎拥有服务的所有字段,但我想在验证服务对象之前自动设置其中一些值。示例:--服务Controller#创建Action:defcreate@service=Service.new@service_form=ServiceFormObject.new(@service)@service_form.validate(params[:service_form_object])and@service_form.saverespond_with(@service_form,location:admin_services_path)end在验证@ser
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build