文章目录
工厂的流水线如下:

官方文档 的流水线如下:
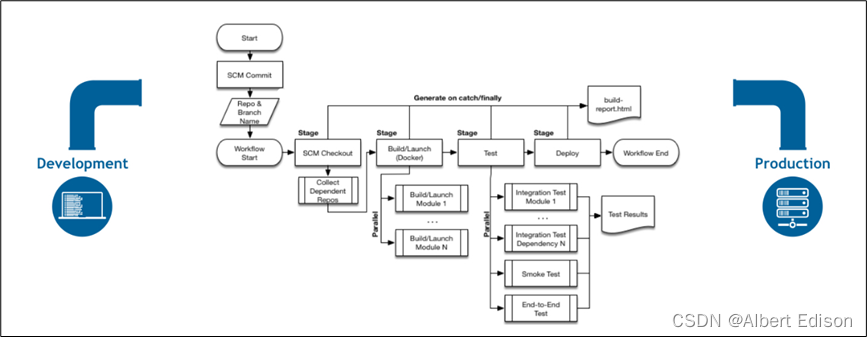
为什么叫做流水线?其实和工厂产品的生产线类似,pipeline 是从源码到发布到线上环境。
关于流水线,需要知道的几个点:
重要的功能插件,帮助 Jenkins 定义了一套工作流框架;
Pipeline 的实现方式是一套 Groovy DSL( 领域专用语言 ),所有的发布流程都可以表述为一段 Groovy 脚本;
将 WebUI 上需要定义的任务,以脚本代码的方式表述出来;
帮助jenkins实现持续集成 CI(Continue Integration)和持续部署 CD(Continue Deliver)的重要手段;
两种语法类型:
注意:为与 BlueOcean 脚本编辑器兼容,通常建议使用 Declarative Pipeline 的方式进行编写,从 jenkins 社区的动向来看,很明显这种语法结构也会是未来的趋势。
json 脚本
pipeline {
agent {label '172.21.51.68'}
environment {
PROJECT = 'myblog'
}
stages {
stage('Checkout') {
steps {
checkout scm
}
}
stage('Build') {
steps {
sh 'make'
}
}
stage('Test'){
steps {
sh 'make check'
junit 'reports/**/*.xml'
}
}
stage('Deploy') {
steps {
sh 'make publish'
}
}
}
post {
success {
echo 'Congratulations!'
}
failure {
echo 'Oh no!'
}
always {
echo 'I will always say Hello again!'
}
}
}
checkout 步骤为检出代码;scm 是一个特殊变量,指示 checkout 步骤克隆触发此 Pipeline 运行的特定修订
agent:指明使用哪个 agent 节点来执行任务,定义于 pipeline 顶层或者 stage 内部
any,可以使用任意可用的 agent 来执行
label,在提供了标签的 Jenkins 环境中可用的代理上执行流水线或阶段。例如:agent { label 'my-defined-label' },最常见的使用方式
none,当在 pipeline 块的顶部没有全局代理,该参数将会被分配到整个流水线的运行中并且每个 stage 部分都需要包含他自己的 agent 部分。比如:agent none
docker, 使用给定的容器执行流水线或阶段。 在指定的节点中,通过运行容器来执行任务
agent {
docker {
image 'maven:3-alpine'
label 'my-defined-label'
args '-v /tmp:/tmp'
}
}
options:允许从流水线内部配置特定于流水线的选项。
options { buildDiscarder(logRotator(numToKeepStr: '10')) }options { disableConcurrentBuilds() }options { timeout(time: 1, unit: 'HOURS') }options { retry(3) }environment:指令制定一个 键-值对序列,该序列将被定义为所有步骤的环境变量
stages:包含一系列一个或多个 stage 指令,stages 部分是流水线描述的大部分 “work” 的位置。 建议 stages 至少包含一个 stage 指令用于连续交付过程的每个离散部分,比如构建、测试和部署。
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}
steps:在给定的 stage 指令中执行的定义了一系列的一个或多个 steps。
post:定义一个或多个 steps ,这些阶段根据流水线或阶段的完成情况而运行 post 支持以下 post-condition 块中的其中之一: always、changed、 failure、 success、 unstable 和 aborted。
post 部分运行该步骤post 部分运行该步骤post 部分运行该步骤,通常 web UI 是红色post 部分运行该步骤,通常 web UI 是蓝色或绿色post 部分运行该步骤,通常由于测试失败,代码违规等造成。通常 web UI 是黄色post 部分运行该步骤,通常由于流水线被手动的aborted。通常 web UI 是灰色创建 pipeline 示意:新建任务 -> 流水线
jenkins/pipelines/p1.yaml
pipeline {
agent {label '172.21.51.68'}
environment {
PROJECT = 'myblog'
}
stages {
stage('printenv') {
steps {
echo 'Hello World'
sh 'printenv'
}
}
stage('check') {
steps {
checkout([$class: 'GitSCM', branches: [[name: '*/master']], doGenerateSubmoduleConfigurations: false, extensions: [], submoduleCfg: [], userRemoteConfigs: [[credentialsId: 'gitlab-user', url: 'http://gitlab.luffy.com/root/myblog.git']]])
}
}
stage('build-image') {
steps {
sh 'docker build . -t myblog:latest -f Dockerfile'
}
}
stage('send-msg') {
steps {
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=4778abd23dbdbaf66fc6f413e6ab9c0103a039b0054201344a22a5692cdcc54e' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "我就是我, 是不一样的烟火"
}
}'
"""
}
}
}
}
点击 “立即构建”,同样的,我们可以配置触发器,使用 webhook 的方式接收项目的 push 事件
Build when a change is pushed to GitLab.Secret tokengitlab,创建 webhook,发送 test push events 测试关于 Blue Ocean 我们需要知道的几点:
思考:
Jenkins Pipeline 提供了一套可扩展的工具,用于将 “简单到复杂” 的交付流程实现为 “持续交付即代码”。
Jenkins Pipeline 的定义通常被写入到一个文本文件(称为 Jenkinsfile )中,该文件可以被放入项目的源代码控制库中。
演示1:使用 Jenkinsfile 管理 pipeline
Jenkinsfile:jenkins/pipelines/p2.yaml
pipeline {
agent {label '172.21.51.68'}
environment {
PROJECT = 'myblog'
}
stages {
stage('printenv') {
steps {
echo 'Hello World'
sh 'printenv'
}
}
stage('check') {
steps {
checkout([$class: 'GitSCM', branches: [[name: '*/master']], doGenerateSubmoduleConfigurations: false, extensions: [], submoduleCfg: [], userRemoteConfigs: [[credentialsId: 'gitlab-user', url: 'http://gitlab.luffy.com/root/myblog.git']]])
}
}
stage('build-image') {
steps {
sh 'docker build . -t myblog:latest -f Dockerfile'
}
}
stage('send-msg') {
steps {
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=4778abd23dbdbaf66fc6f413e6ab9c0103a039b0054201344a22a5692cdcc54e' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "我就是我, 是不一样的烟火"
}
}'
"""
}
}
}
}
演示2:优化及丰富流水线内容
优化代码检出阶段
由于目前已经配置了使用 git 仓库地址,且使用 SCM 来检测项目,因此代码检出阶段完全没有必要再去指定一次
构建镜像的 tag 使用 git 的 commit id
增加 post 阶段的消息通知,丰富通知内容
配置 webhook,实现 myblog 代码推送后,触发 Jenkinsfile 任务执行
jenkins/pipelines/p3.yaml
pipeline {
agent { label '172.21.51.68'}
stages {
stage('printenv') {
steps {
echo 'Hello World'
sh 'printenv'
}
}
stage('check') {
steps {
checkout scm
}
}
stage('build-image') {
steps {
retry(2) { sh 'docker build . -t myblog:${GIT_COMMIT}'}
}
}
}
post {
success {
echo 'Congratulations!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=4778abd23dbdbaf66fc6f413e6ab9c0103a039b0054201344a22a5692cdcc54e' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😄👍构建成功👍😄\n 关键字:luffy\n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
failure {
echo 'Oh no!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=4778abd23dbdbaf66fc6f413e6ab9c0103a039b0054201344a22a5692cdcc54e' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😖❌构建失败❌😖\n 关键字:luffy\n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
always {
echo 'I will always say Hello again!'
}
}
}
演示3:使用 k8s 部署服务
新建 deploy 目录,将 k8s 所需的文件放到 deploy 目录中
将镜像地址改成模板,在 pipeline 中使用新构建的镜像进行替换
执行 kubectl apply -f deploy 应用更改,需要配置 kubectl 认证
$ scp -r k8s-master:/root/.kube /root
jenkins/pipelines/p4.yaml
pipeline {
agent { label '172.21.51.68'}
environment {
IMAGE_REPO = "172.21.51.143:5000/myblog"
}
stages {
stage('printenv') {
steps {
echo 'Hello World'
sh 'printenv'
}
}
stage('check') {
steps {
checkout scm
}
}
stage('build-image') {
steps {
retry(2) { sh 'docker build . -t ${IMAGE_REPO}:${GIT_COMMIT}'}
}
}
stage('push-image') {
steps {
retry(2) { sh 'docker push ${IMAGE_REPO}:${GIT_COMMIT}'}
}
}
stage('deploy') {
steps {
sh "sed -i 's#{{IMAGE_URL}}#${IMAGE_REPO}:${GIT_COMMIT}#g' manifests/*"
timeout(time: 1, unit: 'MINUTES') {
sh "kubectl apply -f manifests/"
}
}
}
}
post {
success {
echo 'Congratulations!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=4778abd23dbdbaf66fc6f413e6ab9c0103a039b0054201344a22a5692cdcc54e' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😄👍构建成功👍😄\n 关键字:myblog\n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
failure {
echo 'Oh no!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=4778abd23dbdbaf66fc6f413e6ab9c0103a039b0054201344a22a5692cdcc54e' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😖❌构建失败❌😖\n 关键字:luffy\n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
always {
echo 'I will always say Hello again!'
}
}
}
演示4:使用凭据管理敏感信息
上述 Jenkinsfile 中存在的问题是敏感信息使用明文,暴漏在代码中,如何管理流水线中的敏感信息(包含账号密码),之前我们在对接 gitlab 的时候,需要账号密码,已经使用过凭据来管理这类敏感信息,同样的,我们可以使用凭据来存储钉钉的 token 信息,那么,创建好凭据后,如何在 Jenkinsfile 中获取已有凭据的内容?
Jenkins 的声明式流水线语法有一个 credentials() 辅助方法(在 environment 指令中使用),它支持 secret 文本,带密码的用户名,以及 secret 文件凭据。
下面的流水线代码片段展示了如何创建一个使用带密码的用户名凭据的环境变量的流水线。
在该示例中,带密码的用户名凭据被分配了环境变量,用来使你的组织或团队以一个公用账户访问 Bitbucket 仓库;这些凭据已在 Jenkins 中配置了凭据 ID jenkins-bitbucket-common-creds。
当在 environment 指令中设置凭据环境变量时:
environment {
BITBUCKET_COMMON_CREDS = credentials('jenkins-bitbucket-common-creds')
}
这实际设置了下面的三个环境变量:
BITBUCKET_COMMON_CREDS - 包含一个以冒号分隔的用户名和密码,格式为 username:password。BITBUCKET_COMMON_CREDS_USR - 附加的一个仅包含用户名部分的变量。BITBUCKET_COMMON_CREDS_PSW - 附加的一个仅包含密码部分的变量。pipeline {
agent {
// 此处定义 agent 的细节
}
environment {
//顶层流水线块中使用的 environment 指令将适用于流水线中的所有步骤。
BITBUCKET_COMMON_CREDS = credentials('jenkins-bitbucket-common-creds')
}
stages {
stage('Example stage 1') {
//在一个 stage 中定义的 environment 指令只会将给定的环境变量应用于 stage 中的步骤。
environment {
BITBUCKET_COMMON_CREDS = credentials('another-credential-id')
}
steps {
//
}
}
stage('Example stage 2') {
steps {
//
}
}
}
}
因此对 Jenkinsfile 做改造:jenkins/pipelines/p5.yaml
pipeline {
agent { label '172.21.51.68'}
environment {
IMAGE_REPO = "172.21.51.143:5000/myblog"
DINGTALK_CREDS = credentials('dingTalk')
}
stages {
stage('printenv') {
steps {
echo 'Hello World'
sh 'printenv'
}
}
stage('check') {
steps {
checkout scm
}
}
stage('build-image') {
steps {
retry(2) { sh 'docker build . -t ${IMAGE_REPO}:${GIT_COMMIT}'}
}
}
stage('push-image') {
steps {
retry(2) { sh 'docker push ${IMAGE_REPO}:${GIT_COMMIT}'}
}
}
stage('deploy') {
steps {
sh "sed -i 's#{{IMAGE_URL}}#${IMAGE_REPO}:${GIT_COMMIT}#g' manifests/*"
timeout(time: 1, unit: 'MINUTES') {
sh "kubectl apply -f manifests/"
}
}
}
}
post {
success {
echo 'Congratulations!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=${DINGTALK_CREDS_PSW}' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😄👍构建成功👍😄\n 关键字:luffy\n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
failure {
echo 'Oh no!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=${DINGTALK_CREDS_PSW}' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text",
"text": {
"content": "😖❌构建失败❌😖\n 关键字:luffy\n 项目名称: ${JOB_BASE_NAME}\n Commit Id: ${GIT_COMMIT}\n 构建地址:${RUN_DISPLAY_URL}"
}
}'
"""
}
always {
echo 'I will always say Hello again!'
}
}
}
上面我们已经通过 Jenkinsfile 完成了最简单的项目的构建和部署,那么我们来思考目前的方式:
目前都是在项目的单一分支下进行操作,企业内一般会使用 feature、develop、release、master 等多个分支来管理整个代码提交流程,如何根据不同的分支来做构建?
构建视图中如何区分不同的分支?
如何不配置 webhook 的方式实现构建?
如何根据不同的分支选择发布到不同的环境(开发、测试、生产)?
我们简化一下流程,假如使用 develop 分支作为开发分支,master 分支作为集成测试分支,看一下如何使用多分支流水线来管理。
演示1:多分支流水线的使用
(1)提交develop分支:
$ git checkout -b develop
$ git push --set-upstream origin develop
(2)禁用 pipeline 项目
(3)Jenkins 端创建多分支流水线项目
develop|master|v.*保存后,会自动检索项目中所有存在 Jenkinsfile 文件的分支和标签,若匹配我们设置的过滤正则表达式,则会添加到多分支的构建视图中。所有添加到视图中的分支和标签,会默认执行一次构建任务。
演示2:美化消息通知内容
jenkins/pipelines/p6.yaml
pipeline {
agent { label '172.21.51.68'}
environment {
IMAGE_REPO = "172.21.51.143:5000/myblog"
DINGTALK_CREDS = credentials('dingTalk')
TAB_STR = "\n \n "
}
stages {
stage('printenv') {
steps {
script{
sh "git log --oneline -n 1 > gitlog.file"
env.GIT_LOG = readFile("gitlog.file").trim()
}
sh 'printenv'
}
}
stage('checkout') {
steps {
checkout scm
script{
env.BUILD_TASKS = env.STAGE_NAME + "√..." + env.TAB_STR
}
}
}
stage('build-image') {
steps {
retry(2) { sh 'docker build . -t ${IMAGE_REPO}:${GIT_COMMIT}'}
script{
env.BUILD_TASKS += env.STAGE_NAME + "√..." + env.TAB_STR
}
}
}
stage('push-image') {
steps {
retry(2) { sh 'docker push ${IMAGE_REPO}:${GIT_COMMIT}'}
script{
env.BUILD_TASKS += env.STAGE_NAME + "√..." + env.TAB_STR
}
}
}
stage('deploy') {
steps {
sh "sed -i 's#{{IMAGE_URL}}#${IMAGE_REPO}:${GIT_COMMIT}#g' manifests/*"
timeout(time: 1, unit: 'MINUTES') {
sh "kubectl apply -f manifests/"
}
script{
env.BUILD_TASKS += env.STAGE_NAME + "√..." + env.TAB_STR
}
}
}
}
post {
success {
echo 'Congratulations!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=${DINGTALK_CREDS_PSW}' \
-H 'Content-Type: application/json' \
-d '{
"msgtype": "markdown",
"markdown": {
"title":"myblog",
"text": "😄👍 构建成功 👍😄 \n**项目名称**:luffy \n**Git log**: ${GIT_LOG} \n**构建分支**: ${GIT_BRANCH} \n**构建地址**:${RUN_DISPLAY_URL} \n**构建任务**:${BUILD_TASKS}"
}
}'
"""
}
failure {
echo 'Oh no!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=${DINGTALK_CREDS_PSW}' \
-H 'Content-Type: application/json' \
-d '{
"msgtype": "markdown",
"markdown": {
"title":"myblog",
"text": "😖❌ 构建失败 ❌😖 \n**项目名称**:luffy \n**Git log**: ${GIT_LOG} \n**构建分支**: ${GIT_BRANCH} \n**构建地址**:${RUN_DISPLAY_URL} \n**构建任务**:${BUILD_TASKS}"
}
}'
"""
}
always {
echo 'I will always say Hello again!'
}
}
}
演示3:通知 gitlab 构建状态
Jenkins 端做了构建,可以通过 gitlab 通过的 api 将构建状态通知过去,作为开发人员发起 Merge Request 或者合并 Merge Request 的依据之一。
注意一定要指定 gitLabConnection('gitlab'),不然没法认证到 Gitlab 端
jenkins/pipelines/p7.yaml
pipeline {
agent { label '172.21.51.68'}
options {
buildDiscarder(logRotator(numToKeepStr: '10'))
disableConcurrentBuilds()
timeout(time: 20, unit: 'MINUTES')
gitLabConnection('gitlab')
}
environment {
IMAGE_REPO = "172.21.51.143:5000/demo/myblog"
DINGTALK_CREDS = credentials('dingTalk')
TAB_STR = "\n \n "
}
stages {
stage('printenv') {
steps {
script{
sh "git log --oneline -n 1 > gitlog.file"
env.GIT_LOG = readFile("gitlog.file").trim()
}
sh 'printenv'
}
}
stage('checkout') {
steps {
checkout scm
updateGitlabCommitStatus(name: env.STAGE_NAME, state: 'success')
script{
env.BUILD_TASKS = env.STAGE_NAME + "√..." + env.TAB_STR
}
}
}
stage('build-image') {
steps {
retry(2) { sh 'docker build . -t ${IMAGE_REPO}:${GIT_COMMIT}'}
updateGitlabCommitStatus(name: env.STAGE_NAME, state: 'success')
script{
env.BUILD_TASKS += env.STAGE_NAME + "√..." + env.TAB_STR
}
}
}
stage('push-image') {
steps {
retry(2) { sh 'docker push ${IMAGE_REPO}:${GIT_COMMIT}'}
updateGitlabCommitStatus(name: env.STAGE_NAME, state: 'success')
script{
env.BUILD_TASKS += env.STAGE_NAME + "√..." + env.TAB_STR
}
}
}
stage('deploy') {
steps {
sh "sed -i 's#{{IMAGE_URL}}#${IMAGE_REPO}:${GIT_COMMIT}#g' manifests/*"
timeout(time: 1, unit: 'MINUTES') {
sh "kubectl apply -f manifests/"
}
updateGitlabCommitStatus(name: env.STAGE_NAME, state: 'success')
script{
env.BUILD_TASKS += env.STAGE_NAME + "√..." + env.TAB_STR
}
}
}
}
post {
success {
echo 'Congratulations!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=${DINGTALK_CREDS_PSW}' \
-H 'Content-Type: application/json' \
-d '{
"msgtype": "markdown",
"markdown": {
"title":"myblog",
"text": "😄👍 构建成功 👍😄 \n**项目名称**:luffy \n**Git log**: ${GIT_LOG} \n**构建分支**: ${BRANCH_NAME} \n**构建地址**:${RUN_DISPLAY_URL} \n**构建任务**:${BUILD_TASKS}"
}
}'
"""
}
failure {
echo 'Oh no!'
sh """
curl 'https://oapi.dingtalk.com/robot/send?access_token=${DINGTALK_CREDS_PSW}' \
-H 'Content-Type: application/json' \
-d '{
"msgtype": "markdown",
"markdown": {
"title":"myblog",
"text": "😖❌ 构建失败 ❌😖 \n**项目名称**:luffy \n**Git log**: ${GIT_LOG} \n**构建分支**: ${BRANCH_NAME} \n**构建地址**:${RUN_DISPLAY_URL} \n**构建任务**:${BUILD_TASKS}"
}
}'
"""
}
always {
echo 'I will always say Hello again!'
}
}
}
我们可以访问 gitlab,然后找到 commit 记录,查看同步状态:
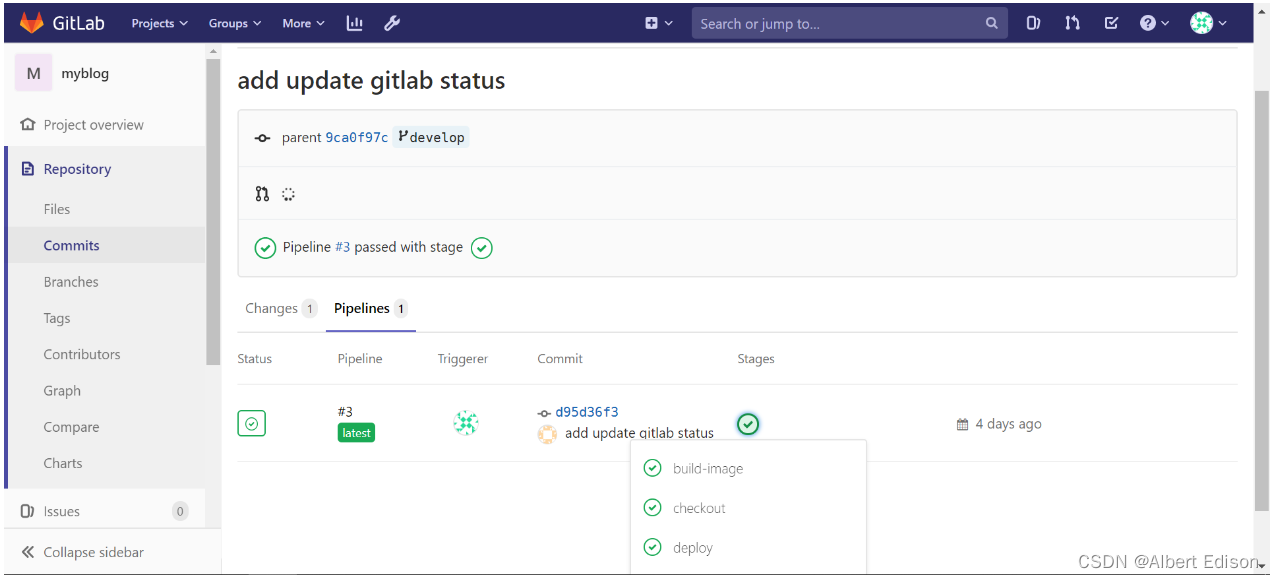
提交 merge request,也可以查看到相关的任务状态,可以作为项目 owner 合并代码的依据之一:
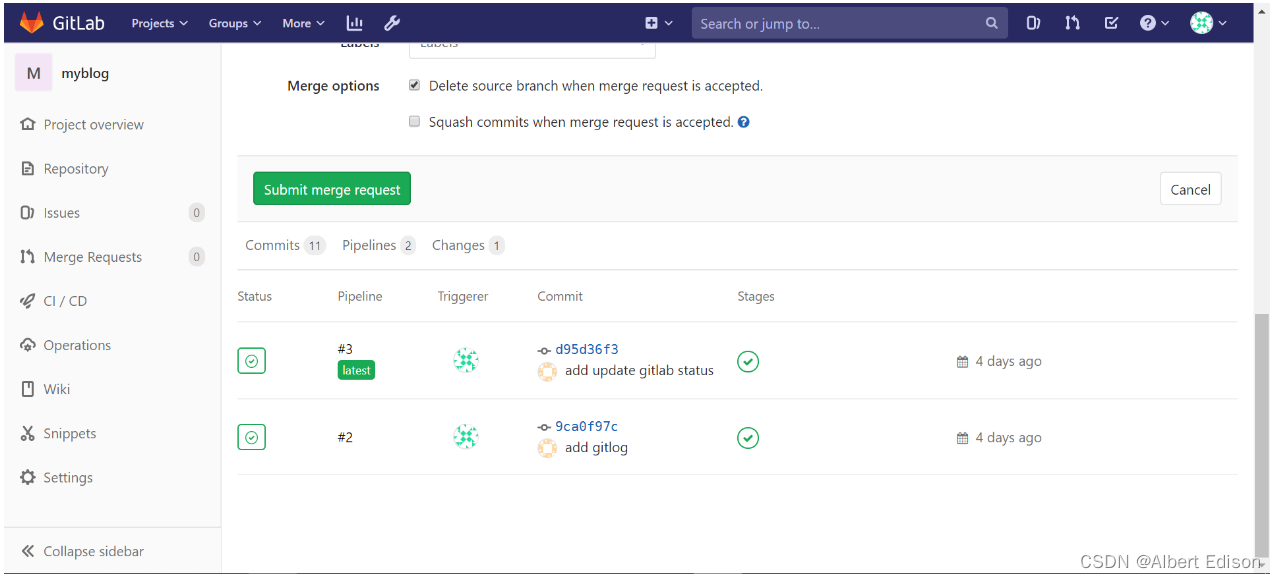
优势:
思考:
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。