 切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
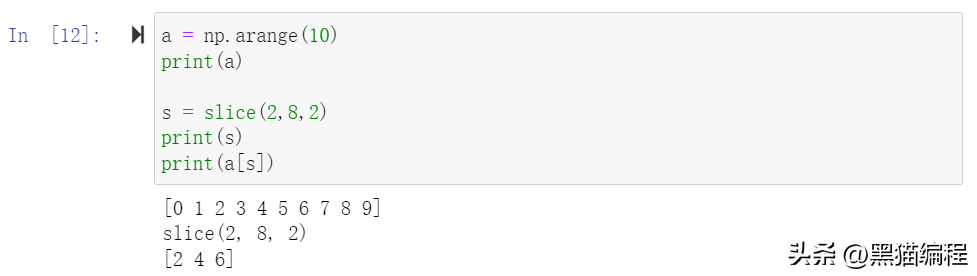
切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。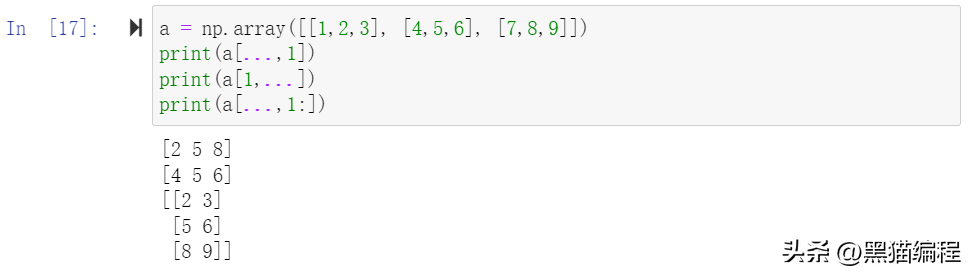

a = np.array([[0,1,2], [3,4,5], [6,7,8], [9,10,11]])
print(a)
print('-' * 20)
rows = np.array([[0,0], [3,3]])
cols = np.array([[0,2], [0,2]])
b = a[rows, cols]
print(b)
print('-' * 20)
rows = np.array([[0,1], [2,3]])
cols = np.array([[0,2], [0,2]])
c = a[rows, cols]
print(c)
print('-' * 20)
rows = np.array([[0,1,2], [1,2,3], [1,2,3]])
cols = np.array([[0,1,2], [0,1,2], [0,1,2]])
d = a[rows, cols]
print(d)[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
--------------------
[[ 0 2]
[ 9 11]]
--------------------
[[ 0 5]
[ 6 11]]
--------------------
[[ 0 4 8]
[ 3 7 11]
[ 3 7 11]]a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(a)
print('-' * 20)
b = a[1:3, 1:3]
print(b)
print('-' * 20)
c = a[1:3, [0,2]]
print(c)
print('-' * 20)
d = a[..., 1:]
print(d)[[1 2 3]
[4 5 6]
[7 8 9]]
--------------------
[[5 6]
[8 9]]
--------------------
[[4 6]
[7 9]]
--------------------
[[2 3]
[5 6]
[8 9]]a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(a)
print('-' * 20)
print(a[a > 5])[[1 2 3]
[4 5 6]
[7 8 9]]
--------------------
[6 7 8 9]a = np.array([np.nan, 1, 2, np.nan, 3, 4, 5])
print(a)
print('-' * 20)
print(a[~np.isnan(a)])[nan 1. 2. nan 3. 4. 5.]
--------------------
[1. 2. 3. 4. 5.]a = np.array([1, 3+4j, 5, 6+7j])
print(a)
print('-' * 20)
print(a[np.iscomplex(a)])[1.+0.j 3.+4.j 5.+0.j 6.+7.j]
--------------------
[3.+4.j 6.+7.j]a = np.arange(2, 10)
print(a)
print('-' * 20)
b = a[[0,6]]
print(b)[2 3 4 5 6 7 8 9]
--------------------
[2 8]a = np.arange(32).reshape(8, 4)
print(a)
print('-' * 20)
print(a[[4, 2, 1, 7]])[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
--------------------
[[16 17 18 19]
[ 8 9 10 11]
[ 4 5 6 7]
[28 29 30 31]]a = np.arange(32).reshape(8, 4)
print(a[[-4, -2, -1, -7]])[[16 17 18 19]
[24 25 26 27]
[28 29 30 31]
[ 4 5 6 7]]A×B={(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
B×A={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)}a = np.arange(32).reshape(8, 4)
print(a[np.ix_([1,5,7,2], [0,3,1,2])])[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]a = np.arange(1, 5)
b = np.arange(1, 5)
c = a * b
print(c)[ 1 4 9 16]a = np.array([
[0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]
])
b = np.array([0, 1, 2])
print(a + b)[[ 0 1 2]
[10 11 12]
[20 21 22]
[30 31 32]]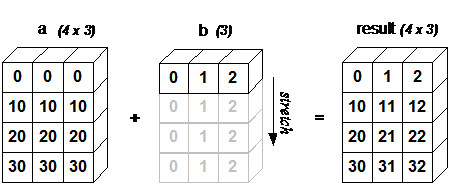 tile扩展数组
tile扩展数组a = np.array([1, 2])
b = np.tile(a, (6, 1))
print(b)
print('-' * 20)
c = np.tile(a, (2, 3))
print(c)[[1 2]
[1 2]
[1 2]
[1 2]
[1 2]
[1 2]]
--------------------
[[1 2 1 2 1 2]
[1 2 1 2 1 2]]a = np.array([
[0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]
])
b = np.array([0, 1, 2])
bb = np.tile(b, (4, 1))
print(a + bb)[[ 0 1 2]
[10 11 12]
[20 21 22]
[30 31 32]]假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co