springboot版本:2.0.5.RELEASE
elasticsearch版本:7.9.1
引入依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.9.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.9.1</version>
</dependency>
application.properties 配置文件:
elasticsearch.schema=http
elasticsearch.address=192.168.80.130:9200,192.168.80.131:9200,192.168.80.132:9200
elasticsearch.connectTimeout=10000
elasticsearch.socketTimeout=60000
elasticsearch.connectionRequestTimeout=10000
elasticsearch.maxConnectNum=200
elasticsearch.maxConnectPerRoute=200
# 无密码可忽略
elasticsearch.userName=elastic
elasticsearch.password=123456
连接配置:
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PreDestroy;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Configuration
public class ElasticSearchConfig {
/**
* 协议
*/
@Value("${elasticsearch.schema:http}")
private String schema;
/**
* 集群地址,如果有多个用“,”隔开
*/
@Value("${elasticsearch.address}")
private String address;
/**
* 集群地址,如果有多个用“,”隔开
*/
@Value("${elasticsearch.userName}")
private String userName;
/**
* 集群地址,如果有多个用“,”隔开
*/
@Value("${elasticsearch.password}")
private String password;
/**
* 连接超时时间
*/
@Value("${elasticsearch.connectTimeout:5000}")
private int connectTimeout;
/**
* Socket 连接超时时间
*/
@Value("${elasticsearch.socketTimeout:10000}")
private int socketTimeout;
/**
* 获取连接的超时时间
*/
@Value("${elasticsearch.connectionRequestTimeout:5000}")
private int connectionRequestTimeout;
/**
* 最大连接数
*/
@Value("${elasticsearch.maxConnectNum:100}")
private int maxConnectNum;
/**
* 最大路由连接数
*/
@Value("${elasticsearch.maxConnectPerRoute:100}")
private int maxConnectPerRoute;
private RestHighLevelClient restHighLevelClient;
@Bean
public RestHighLevelClient restHighLevelClient() {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
UsernamePasswordCredentials elastic = new UsernamePasswordCredentials(userName, password);
credentialsProvider.setCredentials(AuthScope.ANY,elastic);
// 拆分地址
List<HttpHost> hostLists = new ArrayList<>();
String[] hostList = address.split(",");
for (String addr : hostList) {
String host = addr.split(":")[0];
String port = addr.split(":")[1];
hostLists.add(new HttpHost(host, Integer.parseInt(port), schema));
}
// 转换成 HttpHost 数组
HttpHost[] httpHost = hostLists.toArray(new HttpHost[]{});
// 构建连接对象
RestClientBuilder builder = RestClient.builder(httpHost);
// 异步连接延时配置
builder.setRequestConfigCallback(requestConfigBuilder -> {
requestConfigBuilder.setConnectTimeout(connectTimeout);
requestConfigBuilder.setSocketTimeout(socketTimeout);
requestConfigBuilder.setConnectionRequestTimeout(connectionRequestTimeout);
return requestConfigBuilder;
});
// 异步连接数配置
builder.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.setMaxConnTotal(maxConnectNum);
httpClientBuilder.setMaxConnPerRoute(maxConnectPerRoute);
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
return httpClientBuilder;
});
restHighLevelClient = new RestHighLevelClient(builder);
return restHighLevelClient;
}
@PreDestroy
public void clientClose() {
try {
this.restHighLevelClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
可以模糊匹配索引名称
@Test
public void tset() throws IOException {
GetIndexRequest getIndexRequest = new GetIndexRequest("log*");
// 获取es前缀过滤下所有索引
GetIndexResponse getIndexResponse = restHighLevelClient.indices().get(getIndexRequest, RequestOptions.DEFAULT);
// 将es查出的索引转换为list
List<String> elasticsearchList = new ArrayList<>(getIndexResponse.getMappings().keySet());
elasticsearchList.forEach(System.out::println);
}
es 的 trem query 做的是精确匹配查询,关于这里早 serviceName 字段后面加的 .keyword 说明如下:
es5.0 及以后的版本取消了 String 类型,将原先的 String 类型拆分为 text 和 keyword 两种类型。它们的区别在于 text 会对字段进行分词处理而 keyword 则不会。
当没有为索引字段预先指定 mapping 的话,es 就会使用 Dynamic Mapping ,通过推断你传入的文档中字段的值对字段进行动态映射。例如传入的文档中字段 total 的值为12,那么 total 将被映射为 long 类型;字段 addr 的值为"192.168.0.1",那么 addr 将被映射为 ip 类型。然而对于不满足 ip 和 long 格式的普通字符串来说,情况有些不同:ES 会将它们映射为 text 类型,但为了保留对这些字段做精确查询以及聚合的能力,又同时对它们做了 keyword 类型的映射,作为该字段的 fields 属性写到 _mapping 中。例如,我这里使用的字段 “serviceName”,用来存储服务名称字符串类型,会对它做如下的 Dynamic Mapping:
"serviceName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
在之后的查询中使用 serviceName 是将 serviceName 作为 text 类型查询,而使用 serviceName.keyword 则是将 serviceName 作为 keyword 类型查询。前者会对查询内容做分词处理之后再匹配,而后者则是直接对查询结果做精确匹配。
es 的 trem query 做的是精确匹配而不是分词查询,因此对 text 类型的字段做 term 查询将是查不到结果的(除非字段本身经过分词器处理后不变,未被转换或分词)。此时,必须使用 serviceName.keyword 来对 serviceName 字段以 keyword 类型进行精确匹配。
GET logdata-log-center-2021.05.06/_search
{
"query": {
"terms": {
"serviceName.keyword": [
"log-center-user-portal",
"log-center-collect-manage"
]
}
}
}
Java API
@Test
public void test() throws IOException {
//构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// termQuery只能匹配一个值,第一个入参为字段名称,第二个参数为传入的值,相当于sql中的=
// searchSourceBuilder.query(QueryBuilders.termQuery("serviceName.keyword", "log-center-user-portal-web"));
//termsQuery可以一次性匹配多个值,相当于sql中的in
searchSourceBuilder.query(QueryBuilders.termsQuery("serviceName.keyword", "log-center-user-portal-web", "log-center-collect-manage"));
//构建查询请求对象,入参为索引
SearchRequest searchRequest = new SearchRequest("log-web-up-log-center-2021.10.30");
//向搜索请求对象中配置搜索源
searchRequest.source(searchSourceBuilder);
// 执行搜索,向ES发起http请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (RestStatus.OK.equals(response.status())) {
long total = response.getHits().getTotalHits().value; //检索到符合条件的总数
SearchHit[] hits = response.getHits().getHits();
//未指定size,默认查询的是10条
for (SearchHit hit : hits) {
String index = hit.getIndex();//索引名称
String id = hit.getId(); //文档id
JSONObject jsonObject = JSON.parseObject(hit.getSourceAsString(), JSONObject.class); //文档内容
System.out.println(jsonObject);
}
}
}
es的 wildcard query 做的是模糊匹配查询,类似 sql 中的 like,而 value 值前后的 “*” 号类似与 sql 中的 ”%“ 。
GET logdata-log-center-2021.05.06/_search
{
"query": {
"wildcard": {
"serviceName.keyword": {
"value": "*user-portal*"
}
}
}
}
Java API
searchSourceBuilder.query(QueryBuilders.wildcardQuery("serviceName.keyword", "*" + "user-portal" + "*"));
es 的 range query 做的是范围查询,相当于 sql 中的 between … and …
GET log-web-up-log-center-2021.10.30/_search
{
"query": {
"range": {
"timestamp": {
"gte": "2021-10-30 15:00:00",
"lte": "2021-10-30 16:00:00",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS"
}
}
}
}
Java API
searchSourceBuilder.query(QueryBuilders.rangeQuery("timestamp")
.gte("2021-10-30 15:00:00") //起始值
.lte("2021-10-30 16:00:00") //结束值
.format("yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS"));//可以指定多个格式化标准,使用||隔开
es的 match query 做的是全文检索,会对关键字进行分词后匹配词条。
GET log-web-up-log-center-2021.10.30/_search
{
"query": {
"match": {
"orgName": {
"query": "有限公司"
}
}
}
}
query:搜索的关键字,对于英文关键字如果有多个单词则中间要用半角逗号分隔,而对于中文关键字中间可以用逗号分隔也可以不用。
Java API
//全文检索,支持分词匹配
searchSourceBuilder.query(QueryBuilders.matchQuery("orgName", "有限公司");
上面的 MatchQuery 有一个短板,假如用户输入了某关键字,我们在检索的时候不知道具体是哪一个字段,这时我们用什么都不合适,而 MultiMatchQuery 的出现解决了这个问题,他可以通过 fields 属性来设置多个域联合查找,具体用法如下
GET log-web-up-log-center-2021.10.30/_search
{
"query": {
"multi_match": {
"query": "user-portal",
"fields": ["serviceName", "systemName"]
}
}
}
Java API
//全文检索,支持分词匹配,支持多字段检索
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("user-portal", "serviceName", "systemName", "description"));
es的 exists query 做的是检索某个字段存在的数据,即不为 null 的数据。其中指定的 field 可以是一个具体的字段,也可以是一个 json 结构。
GET logdata-log-center-2021.05.06/_search
{
"query": {
"exists": {
"field": "networkLogDetailInfo"
}
}
}
Java API
//查询networkLogDetailInfo不为null的数据
searchSourceBuilder.query(QueryBuilders.existsQuery("networkLogDetailInfo"));
es的 bool query 做的是将多个查询组合起来去检索数据,主要的组合参数有 must、should、mustNot 等。
GET logdata-log-center-2021.05.06/_search
{
"query": {
"bool": {
"must": [
{
"exists": {
"field": "networkLogDetailInfo"
}
},
{
"range": {
"timestamp": {
"gte": "2021-05-05 00:00:00",
"lte": "2021-05-07 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS"
}
}
}
],
"must_not": [
{
"exists": {
"field": "serviceLogDetailInfo"
}
}
]
}
}
}
Java API
@Test
public void test() throws IOException {
//构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建bool类型查询器
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//使用must连接,相当于and,构建第一个查询条件existsQuery必须包含此字段
boolQueryBuilder.must(QueryBuilders.existsQuery("networkLogDetailInfo"));
//使用must连接第二个条件,rangeQuery范围查找,相当于between...and...
boolQueryBuilder.must(QueryBuilders.rangeQuery("timestamp")
.from("2021-05-05 00:00:00") //起始值
.to("2021-05-07 00:00:00") //结束值
.includeLower(true) //是否等于起始值
.includeUpper(false) //是否等于结束值
.format("yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS")); //格式化时间
//使用mustNot连接第三个条件
boolQueryBuilder.mustNot(QueryBuilders.existsQuery("serviceLogDetailInfo"));
searchSourceBuilder.query(boolQueryBuilder);
//构建查询请求对象,入参为索引
SearchRequest searchRequest = new SearchRequest("logdata-log-center-2021.05.06");
//向搜索请求对象中配置搜索源
searchRequest.source(searchSourceBuilder);
// 执行搜索,向ES发起http请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (RestStatus.OK.equals(response.status())) {
long total = response.getHits().getTotalHits().value; //检索到符合条件的总数
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
String index = hit.getIndex();//索引名称
String id = hit.getId(); //文档id
JSONObject jsonObject = JSON.parseObject(hit.getSourceAsString(), JSONObject.class); //文档内容
System.out.println(jsonObject);
}
}
}
es 使用 sort 进行排序,可以多个字段联合排序。
GET logdata-log-center-2021.05.06/_search
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "serviceLogDetailInfo"
}
}
]
}
},
"sort": [
{
"serviceName.keyword": {
"order": "asc"
},
"timestamp": {
"order": "desc"
}
}
]
}
先按照第一个字段排序,第一个字段相同时按照第二个字段排序。
Java API
//升序
searchSourceBuilder.sort("serviceName.keyword", SortOrder.ASC);
//降序
searchSourceBuilder.sort("timestamp", SortOrder.DESC);
检索数据,有时只需要其中的几个字段,es 也支持对结果集进行字段筛选过滤。字段可以使用 “*” 进行模糊匹配。
GET logdata-log-center-2021.05.06/_search
{
"_source": {
"includes": ["messageId", "system*", "service*", "timestamp"],
"excludes": []
}
}
Java API
//筛选字段,第一个参数为需要的字段,第二个参数为不需要的字段
searchSourceBuilder.fetchSource(new String[] {"messageId", "system*", "service*", "timestamp"}, new String[] {});
es 的分页方式有三种:from+ size、scroll、search_after, 默认采用的分页方式是 from+ size 的形式。
GET logdata-log-center-2021.05.06/_search
{
"from": 0,
"size": 2,
"query": {
"exists": {
"field": "networkLogDetailInfo"
}
},
"_source": {
"includes": ["messageId", "system*", "service*", "timestamp"],
"excludes": []
}
}
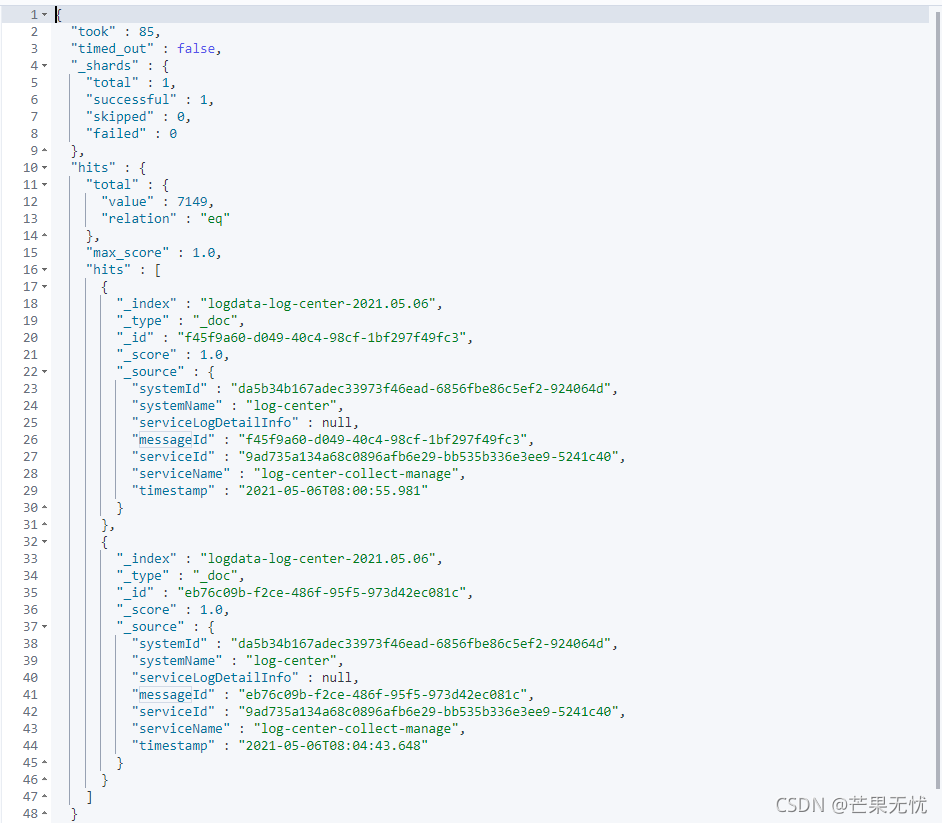
通过查询结果可以发现,我们设置了分页参数之后, hits.total 返回的是数据总数7149,而按照分页规则,我们设置的size=2,因此 hits.hits 里面只有两条数据。
Java API
@Test
public void test() throws IOException {
//构建查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//查询条件
searchSourceBuilder.query(QueryBuilders.existsQuery("networkLogDetailInfo"));
int page = 1; // 页码
int size = 2; // 每页显示的条数
int index = (page - 1) * size;
searchSourceBuilder.from(index); //设置查询起始位置
searchSourceBuilder.size(size); //结果集返回的数据条数
//筛选字段,第一个参数为需要的字段,第二个参数为不需要的字段
searchSourceBuilder.fetchSource(new String[] {"messageId", "system*", "service*", "timestamp"}, new String[] {});
//构建查询请求对象,入参为索引
SearchRequest searchRequest = new SearchRequest("logdata-log-center-2021.05.06");
//向搜索请求对象中配置搜索源
searchRequest.source(searchSourceBuilder);
// 执行搜索,向ES发起http请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (RestStatus.OK.equals(response.status())) {
long total = response.getHits().getTotalHits().value; //检索到符合条件的总数
SearchHit[] hits = response.getHits().getHits();
//未指定size,默认查询的是10条
for (SearchHit hit : hits) {
String index = hit.getIndex();//索引名称
String id = hit.getId(); //文档id
JSONObject jsonObject = JSON.parseObject(hit.getSourceAsString(), JSONObject.class); //文档内容
System.out.println(jsonObject);
}
}
}
一种可满足深度分页的方式,es 提供了 scroll 的方式进行分页读取。原理上是对某次查询生成一个游标 scroll_id , 后续的查询只需要根据这个游标去取数据,每次只能拿到下一页的数据,直到结果集中返回的 hits 字段为空,就表示遍历结束。这里scroll=1m是scroll_id的有效期,表示1分钟,过期后会被es自动清理,每次查询会更新此值。
GET logdata-log-center-2021.05.06/_search?scroll=1m
{
"size": 2,
"query": {
"exists": {
"field": "networkLogDetailInfo"
}
},
"_source": {
"includes": ["messageId", "system*", "service*", "timestamp"],
"excludes": []
}
}
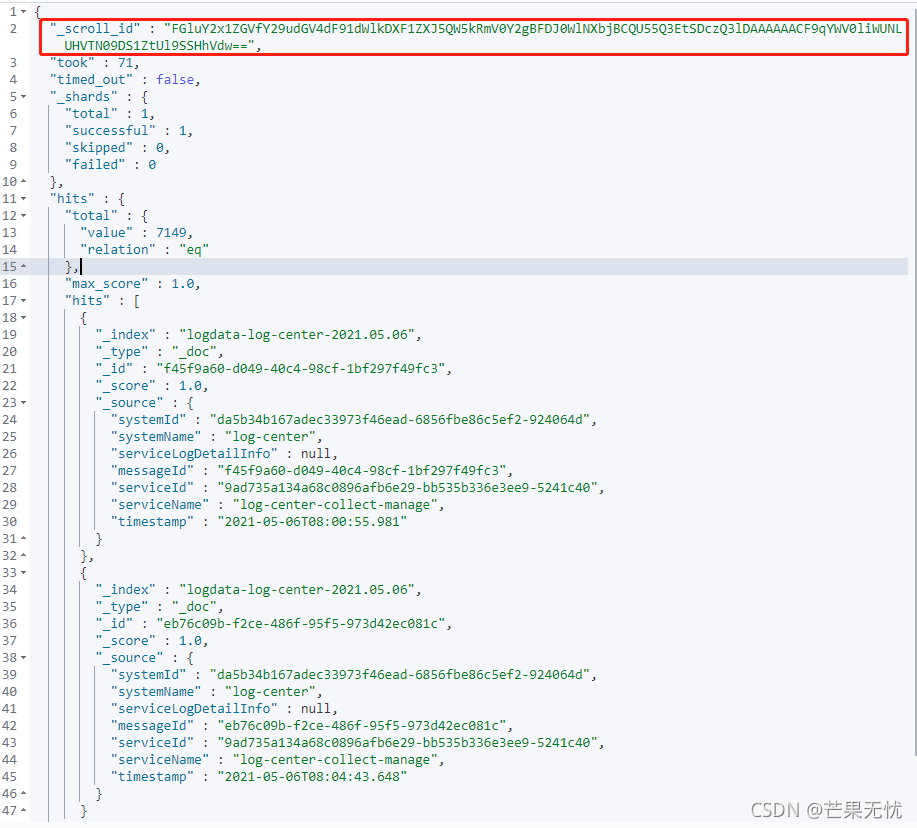
后续的查询中查询条件不需要指定,只需要携带 scroll_id 即可它会按照首次查询条件进行分页展示,下一次查询(两种方式):
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFFp0bGhXbjBCQU55Q3EtSDcxaWF4AAAAAACF-OYWV0liWUNLUHVTN09DS1ZtUl9SSHhVdw=="
}
GET /_search/scroll?scroll=1m&scroll_id=FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFFp0bGhXbjBCQU55Q3EtSDcxaWF4AAAAAACF-OYWV0liWUNLUHVTN09DS1ZtUl9SSHhVdw==
Java API
public void testScroll(String scrollId) throws IOException {
//查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//每页显示2条
searchSourceBuilder.size(2);
//查询条件
searchSourceBuilder.query(QueryBuilders.existsQuery("networkLogDetailInfo"));
//筛选字段,第一个参数为需要的字段,第二个参数为不需要的字段
searchSourceBuilder.fetchSource(new String[] {"messageId", "system*", "service*", "timestamp"}, new String[] {});
SearchRequest request = new SearchRequest("logdata-log-center-2021.05.06");
request.source(searchSourceBuilder);
Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1L));
request.scroll(scroll);//滚动翻页
SearchResponse response;
if (!StringUtils.isBlank(scrollId)) {
//Scroll查询
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(scroll);
response = restHighLevelClient.scroll(scrollRequest, RequestOptions.DEFAULT);
} else {
//首次查询使用普通查询
response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
}
//更新scrollId
scrollId = response.getScrollId();
System.out.println(scrollId);
if (RestStatus.OK.equals(response.status())) {
//设置查询总量
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit : hits) {
String index = hit.getIndex();
String id = hit.getId();
JSONObject jsonObject = JSON.parseObject(hit.getSourceAsString(), JSONObject.class);
System.out.println(jsonObject);
}
}
}
search_after 是 ES5.0 及之后版本提供的新特性,search_after查询时需要指定sort排序字段,可以指定多个排序字段,后续查询有点类似 scroll ,但是和 scroll 又不一样,它提供一个活动的游标,通过上一次查询的最后一条数据的来进行下一次查询。 这里需要说明一下,使用search_after查询需要将from设置为0或-1,当然你也可以不写
第一次查询:
POST logdata-log-center-2021.05.06/_search
{
"size": 2,
"query": {
"exists": {
"field": "networkLogDetailInfo"
}
},
"_source": {
"includes": ["messageId", "system*", "service*", "timestamp"],
"excludes": []
},
"sort": [
{
"timestamp": {
"order": "desc"
}
}
]
}
查询结果:可以看到每一条数据都有一个sort部分,而下一页的查询需要本次查询结果最后一条的sort值作为游标,实现分页查询

第二次查询:
POST logdata-log-center-2021.05.06/_search
{
"search_after": [
1620374316433
],
"size": 2,
"query": {
"exists": {
"field": "networkLogDetailInfo"
}
},
"_source": {
"includes": ["messageId", "system*", "service*", "timestamp"],
"excludes": []
},
"sort": [
{
"timestamp": {
"order": "desc"
}
}
]
}
Java API
public void testSearchAfter(Object[] values) throws IOException {
//查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(2);
searchSourceBuilder.from(0); //searchAfter需要将from设置为0或-1,当然也可以不写
//查询条件
searchSourceBuilder.query(QueryBuilders.existsQuery("networkLogDetailInfo"));
//筛选字段,第一个参数为需要的字段,第二个参数为不需要的字段
searchSourceBuilder.fetchSource(new String[] {"messageId", "system*", "service*", "timestamp"}, new String[] {});
//以时间戳排序
searchSourceBuilder.sort("timestamp", SortOrder.DESC);
if (values != null)
searchSourceBuilder.searchAfter(values);
SearchRequest request = new SearchRequest("logdata-log-center-2021.05.06");
request.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
if (RestStatus.OK.equals(response.status())) {
//设置查询总量
SearchHit[] hits = response.getHits().getHits();
for(int i = 0; i < hits.length; i++) {
String index = hits[i].getIndex();
String id = hits[i].getId();
JSONObject jsonObject = JSON.parseObject(hits[i].getSourceAsString(), JSONObject.class);
System.out.println(jsonObject);
if (i == hits.length-1) {
//最后一条数据的sortValue作为下一次查询的游标值
values = hits[i].getSortValues();
System.out.println(Arrays.toString(values));
}
}
}
}
es 的 aggs 对数据进行聚合查询统计,查询方式如下:
## 统计各系统一个月的日志采集数量
POST log*/_search
{
"size": 0,
"query": {
"range": {
"timestamp": {
"gte": "2021-10-24 00:00:00",
"lte": "2021-11-24 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
},
"aggs": {
"allLog": {
"terms": {
"field": "systemName.keyword",
"size": 10
}
}
}
}
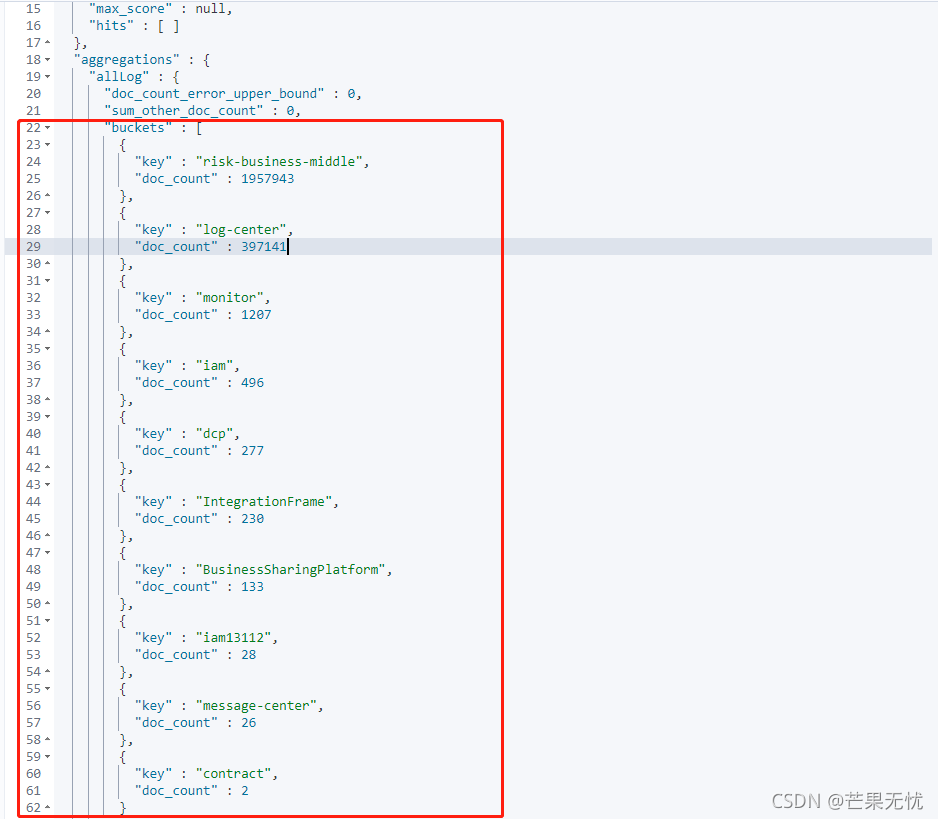
Java API
@Test
public void test() throws IOException {
//按照systemName字段聚合统计各个系统的日志数量
TermsAggregationBuilder bySystemName = AggregationBuilders.terms("allLog").field("systemName.keyword");
RangeQueryBuilder timestamp = QueryBuilders.rangeQuery("timestamp")
.gte("2021-10-24 00:00:00")
.lte("2021-11-24 00:00:00")
.format("yyyy-MM-dd HH:mm:ss");
//查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//配置聚合条件
searchSourceBuilder.aggregation(bySystemName);
//配置查询条件
searchSourceBuilder.query(timestamp);
//设置查询结果不返回,只返回聚合结果
searchSourceBuilder.size(0);
//创建查询请求对象,将查询条件配置到其中
SearchRequest request = new SearchRequest("log*");
request.source(searchSourceBuilder);
// 执行搜索,向ES发起http请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
if (aggregations != null) {
Terms terms = aggregations.get("allLog");
//解析桶
for (Terms.Bucket bucket : terms.getBuckets()) {
System.out.print("系统名称:" + bucket.getKeyAsString());
System.out.println("\t总日志数量:" + bucket.getDocCount());
}
}
}
多层嵌套聚合
## 统计各个系统的总日志数量,按系统统计各种类型日志数量
POST log*/_search
{
"size": 0,
"query": {
"range": {
"timestamp": {
"gte": "2021-10-24 00:00:00",
"lte": "2021-11-24 00:00:00",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
},
"aggs": {
"allLog": {
"terms": {
"field": "systemName.keyword",
"size": 10
},
"aggs": {
"errorLogNum": {
"filter": {
"terms": {
"level.keyword": [
"ERROR",
"FATAL"
]
}
}
},
"dbLogNum": {
"filter": {
"exists": {
"field": "dataLogDetailInfo"
}
}
},
"interfaceLogNum": {
"filter": {
"exists": {
"field": "networkLogDetailInfo"
}
}
},
"serviceLogNum": {
"filter": {
"exists": {
"field": "serviceLogDetailInfo"
}
}
},
"webLogNum": {
"filter": {
"exists": {
"field": "browserModel"
}
}
}
}
}
}
}
Java API
@Test
public void test() throws IOException {
//错误日志聚合条件
FilterAggregationBuilder errorLogNum = AggregationBuilders.filter("errorLogNum", QueryBuilders.termsQuery("level.keyword", "ERROR", "FATAL"));
//数据库日志聚合条件
FilterAggregationBuilder dataLogNum = AggregationBuilders.filter("dbLogNum", QueryBuilders.existsQuery("dataLogDetailInfo"));
//接口日志聚合条件
FilterAggregationBuilder networkLogNum = AggregationBuilders.filter("interfaceLogNum", QueryBuilders.existsQuery("networkLogDetailInfo"));
//应用日志聚合条件
FilterAggregationBuilder serviceLogNum = AggregationBuilders.filter("serviceLogNum", QueryBuilders.existsQuery("serviceLogDetailInfo"));
//前端日志聚合条件
FilterAggregationBuilder webUpLogNum = AggregationBuilders.filter("webLogNum", QueryBuilders.existsQuery("browserModel"));
//最外层聚合条件,第一次聚合的条件
TermsAggregationBuilder bySystemName = AggregationBuilders.terms("allLog").field("systemName.keyword").size(10);
//内部多个条件的子聚合,在系统聚合后的结果上二次聚合
bySystemName.subAggregation(errorLogNum)
.subAggregation(dataLogNum).
subAggregation(networkLogNum).
subAggregation(serviceLogNum).
subAggregation(webUpLogNum);
RangeQueryBuilder timestamp = QueryBuilders.rangeQuery("timestamp")
.gte("2021-10-24 00:00:00")
.lte("2021-11-24 00:00:00")
.format("yyyy-MM-dd HH:mm:ss");
//查询源构建器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//配置聚合条件
searchSourceBuilder.aggregation(bySystemName);
//配置查询条件
searchSourceBuilder.query(timestamp);
//设置查询结果不返回,只返回聚合结果
searchSourceBuilder.size(0);
//创建查询请求对象,将查询条件配置到其中
SearchRequest request = new SearchRequest("log*");
request.source(searchSourceBuilder);
// 执行搜索,向ES发起http请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
if (aggregations != null) {
Terms terms = aggregations.get("allLog");
for (Terms.Bucket bucket : terms.getBuckets()) {
ParsedFilter dbFilter = bucket.getAggregations().get("dbLogNum");
ParsedFilter serviceFilter = bucket.getAggregations().get("serviceLogNum");
ParsedFilter webFilter = bucket.getAggregations().get("webLogNum");
ParsedFilter interfaceFilter = bucket.getAggregations().get("interfaceLogNum");
ParsedFilter errorFilter = bucket.getAggregations().get("errorLogNum");
System.out.print("系统名称:" + bucket.getKeyAsString());
System.out.print("\t总日志:" + bucket.getDocCount());
System.out.print("\t数据库日志:" + dbFilter.getDocCount());
System.out.print("\t服务执行日志:" + serviceFilter.getDocCount());
System.out.print("\t前端操作日志:" + webFilter.getDocCount());
System.out.print("\t接口日志:" + interfaceFilter.getDocCount());
System.out.println("\t错误日志:" + errorFilter.getDocCount());
}
}
}
聚合查询还提供了许多查询规则,按时间date聚合、count聚合、avg聚合、sum聚合、min聚合、max聚合等等,这里就不一一列举了。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我目前正在尝试了解RoR。我将两个字符串传递到我的Controller中。一个是随机的十六进制字符串,另一个是电子邮件。该项目用于对数据库进行简单的电子邮件验证。我遇到的问题是当我输入如下内容来测试我的页面时:http://signup.testsite.local/confirm/da2fdbb49cf32c6848b0aba0f80fb78c/bob.villa@gmailcom我在:email的参数散列中得到的全部是'bob'。我在gmail和com之间留下了.,因为那样会导致匹配根本不起作用。我的路由匹配如下:match"confirm/:code/:email"=>"conf