元数据是存放在inode(index node)表中。inode 表中有很多条记录组成,第一条记录对应的存放了一个
软连接 类似于windows里快捷方式,软连接,符号连接
查看inode号
[root@localhost data]# ls
123 1.txt 2.txt 3.txt 4.txt 5.txt data1 data2
[root@localhost data]# ls -i //方法1
35802872 123 35802838 1.txt 35802839 2.txt 35802840 3.txt 35802841 4.txt 35802842 5.txt 2420054 data1 35802875 data2
[root@localhost data]# stat /data/1.txt //方法2
文件:"/data/1.txt"
大小:0 块:0 IO 块:4096 普通空文件
设备:fd00h/64768d Inode:35802838 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
环境:unconfined_u:object_r:default_t:s0
最近访问:2022-10-12 18:52:31.654822781 +0800
最近更改:2022-10-12 18:52:31.654822781 +0800
最近改动:2022-10-12 18:52:31.654822781 +0800
创建时间:-
3个时间戳:
最近访问atime:最后一次差看文件
最近更改mtime:最近更改文件内容的时间,注意:更改完内容之后,ctime也会改变
最近改动ctime:最近更改文件元信息的时间,比如改变权限等直接指针:直接指向数据块
间接指针:不直接指向数据块,要经过中间数据块,最后指向数据块
图解:
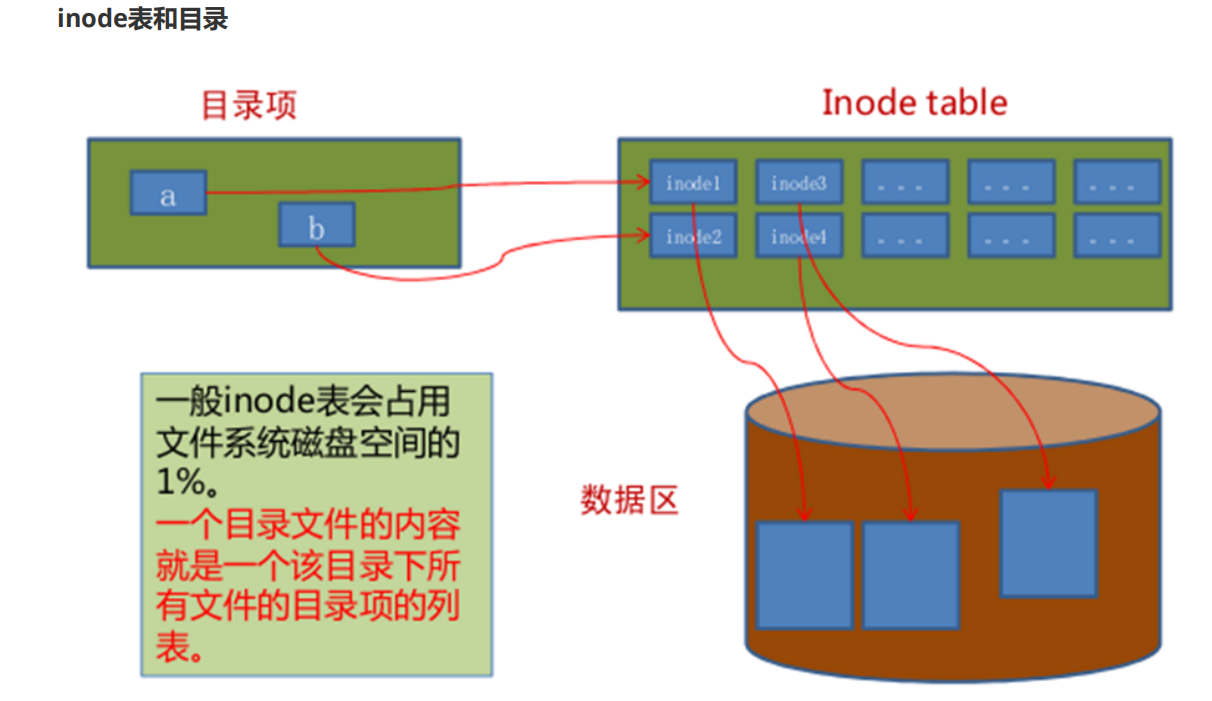
文件是存储在硬盘上的,硬盘的最小存储单位叫做“扇区”(sector),每个扇区存储512字节。
一般连续八个扇区组成一个"块”(block),一个块是4K大小,是文件存取的最小单位。操作系统读取硬盘的时候,是一次性连续读取多个扇区,即一个块一个块的读取的。
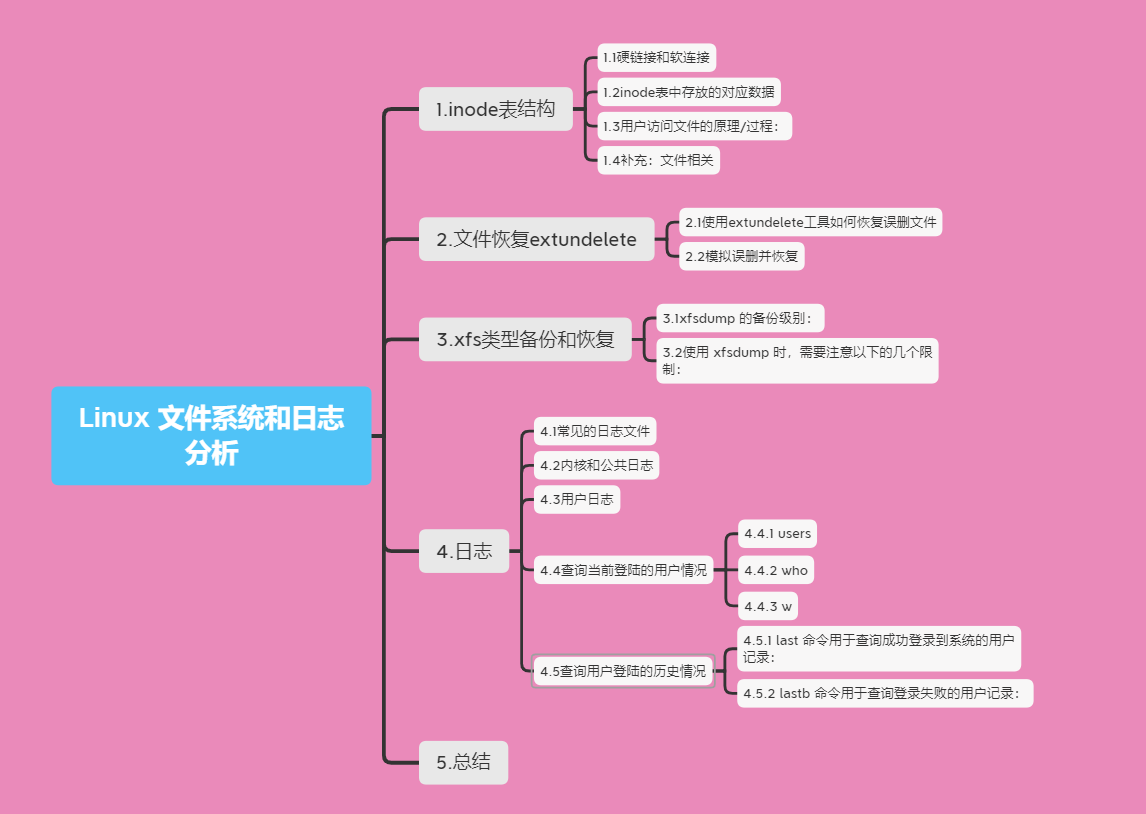
文件数据包括实际数据与元信息(类似文件属性)。文件数据存储在“块"中,存储文件元信息(比如文件的创建者、创建日期、文件大小、文件权限等)的区域就叫做inode表。 因此,一个文件必须占用一个inode,并且至少占用一个block。
inode不包含文件名。文件名是存放在目录文件夹当中的。Linux 系统中一切皆文件,因此目录也是一种文件。
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称,文件名和inode号码是一一对应关系,每个inode号码对应一个或多个文件名。
唯一 同一文件系统() 不同的文件
所以,当用户在Linux系统中试图访问一个文件时,系统会先根据文件名去查找它对应的inode号码:通过inode号码,获取inode信息;根据inode信息,看该用户是否具有访问这个文件的权限;如果有,就指向相对应的数据block,并读取数据。
tops:
硬盘上最小的存储单位为扇区(512字节)
owner info:所有者
size:大小

inode号与命令cp,rm,mv的关系:
cp 命令:
分配一个空闲的inode号,在inode表中生成新条目
在目录中创建一个目录项,将名称与inode编号关联
拷贝数据生成新的文件
rm 命令:
硬链接数递减,从而释放的inode号可以被重用
把数据块放在空闲列表中
删除目录项
数据实际上不会马上被删除,但当另一个文件使用数据块时将被覆盖
mv 命令:
#可以通过inode号来删除指定文件
[root@localhost data]# ls -i
35802872 123 35802838 1.txt 35802839 2.txt 35802840 3.txt 35802841 4.txt 35802842 5.txt 2420054 data1 35802875 data2
[root@localhost data]# find -inum 35802872 -delete //命令1
[root@localhost data]# find -inum 35802872 -exec rm {} /; //命令2
[root@localhost data]# ls
1.txt 2.txt 3.txt 4.txt 5.txt data1 data2
删除文件空间不释放,解决方法
[root@localhost opt]#lsof |grep delete //列出文件 过滤已删除
[root@localhost opt]#echo " " > /boot/bigfile //写空字符导给文件
删除一个文件,实际上并不清除 inode 节点和 block 的数据,只是在这个文件的父目录 里面的 block 中,删除这个文件的名字。
Linux 是通过 Link 的数量来控制文件删除的,只有 当一个文件不存在任何 Link 的时候,这个文件才会被删除。
在 Linux 系统运维工作中,经常会遇到因操作不慎、操作错误等导致文件数据丢失的情 况,尤其对于客户企业中一些新手。
当然,这里所指的是彻底删除,即已经不能通过“回收 站”找回的情况,比如使用“rm -rf”来删除数据。
针对 Linux 下的 EXT 文件系统,可用的恢复 工具有 debugfs、ext3grep、extundelete 等。
其中 extundelete 是一个开源的 Linux 数据 恢复工具,支持 ext3 文件系统。
这两个包在系统安装光盘的/Package 目录下就有,使用 rpm 或 yum 命令将其安装;
[root@localhost ~]#yum -y install e2fsprogs-devel e2fsprogs-libs
#安装依赖软件
[root@localhost ~]# tar -jxvf extundelete-0.2.4.tar.bz2 -C /opt
#解压软件
[root@localhost ~]# cd /opt/extundelete-0.2.4
#切换到目录下
[root@localhost extundelete-0.2.4]# ./configure //定义模块和路径
#编译安装
[root@localhost extundelete-0.2.4]#make //编译
[root@localhost extundelete-0.2.4]#make install //写入硬盘
[root@localhost extundelete-0.2.4]#cd /usr/local/bin/
[root@localhost bin]#ls
extundelete you-get
#验证恢复,目前使用版本只对ext3 有效,分区略
[root@localhost ~]# mkfs.ext3 /dev/sdb1
[root@localhost ~]# mkdir /test/
[root@localhost ~]# mount /dev/sdb1 /test/
[root@localhost ~]# cd /test/
[root@localhost test]# echo a>a
[root@localhost test]# echo a>b
[root@localhost test]# echo a>c
[root@localhost test]# echo a>d
查看文件系统/dev/sdb1 下存在哪些文件
具体的使用情况:
其中--inode 2 代表从 i 节点为 2 的文件开始查看,一般文件系统格式化挂载之后,i 节点是从 2 开始的,2 代表该文件系统最开始的目录。
[root@localhost test]# rm -rf a b //模拟误删除
[root@localhost test]# ls c d lost+foun
[root@localhost test]# cd
[root@localhost ~]# umount /test/
#解挂载
[root@localhost ~]#extundelete /dev/sdb1 --inode 2 //查看该分区下的存在哪些文件
# 命令 查看的分区 从2节点开始
[root@localhost ~]# extundelete /dev/sdb1 --restore-all //使用恢复
# 命令 需要恢复的分区设备 恢复选项,全都要
[root@localhost ~]# ls
anaconda-ks.cfg extundelete-0.2.4 extundelete-0.2.4.tar.bz2 RECOVERED_FILES
[root@localhost ~]# cd RECOVERED_FILES/ //进入恢复目录
[root@localhost RECOVERED_FILES]# ls //查看
a b //恢复成功
若系统中未安装 xfsdump与xfsrestore工具,可以通过yum install -y xfsdump命令安装。
xfsdump 按照inode 顺序备份一个 xfs 文件系统。
0 表示完全备份
1-9 表示增量 备份
xfsdump 的备份级别默认为 0
xfsdump 的命令格式为:
xfsdump -f 备份存放位置 要备份路径或设备文件。
选项:
| 选项 | 作用 |
| -f | 指定备份文件目录 |
| -L | 指定标签 session label |
| -M | 指定设备标签 media label |
| -s | 备份单个文件,-s 后面不能直接跟路径 |
不支持没有挂载的文件系统备份,所以只能备份已挂载的;
必须使用 root 的权限才能操作;
只能备份 XFS 文件系统;
备份下来的数据只能让 xfsrestore 解析;
| 日志文件说明 | |
|---|---|
| /var/log/messages内核和公共日志 | 它是核心系统日志文件,其中包含了系统启动时的引导信息,以及系统运行时的其他状态消息。I/O 错误、网络错误和其他系统错误都会记录到此文件中。其他信息,比如某个人的身份切换为 root,已及用户自定义安装软件的日志,也会在这里列出 |
| /var/log/cron 计划任务日志 | 记录与系统定时任务相关的曰志 |
| /var/log/dmesg 系统引导日志 | 记录了系统在开机时内核自检的信息,也可以使用dmesg命令直接查看内核自检信息 |
| /var/log/maillog 邮件日志 | 记录邮件信息的曰志 |
| 用户日志: | |
| /var/log/lastlog | 记录系统中所有用户最后一次的登录时间的曰志。这个文件也是二进制文件.不能直接用Vi 查看。而要使用lastlog命令查看 |
| /var/log/secure | 记录验证和授权方面的倍息,只要涉及账户和密码的程序都会记录,比如系统的登录、ssh的登录、su切换用户,sudo授权,甚至添加用户和修改用户密码都会记录在这个日志文件中 |
| /var/log/wtmp | 永久记录所有用户的登陆、注销信息,同时记录系统的启动、重启、关机事件。同样,这个文件也是二进制文件.不能直接用Vi查看,而要使用last命令查看 |
| /var/tun/ulmp |
事件产生的时间。
产生事件的服务器的主机名。
[root@localhost ~]# cat /var/log/secure //查看用户验证和授权的日志
Oct 10 10:17:07 localhost sshd[13030]: pam_unix(sshd:session): session closed for user root
Oct 10 10:17:19 localhost sshd[13444]: pam_unix(sshd:session): session closed for user root
Oct 10 10:17:19 localhost su: pam_unix(su:session): session closed for user suoluo
Oct 10 10:17:19 localhost su: pam_unix(su:session): session closed for user suoluo
Oct 10 11:46:41 localhost sshd[13828]: pam_unix(sshd:session): session closed for user root
Oct 10 11:46:47 localhost sshd[15915]: Accepted password for root from 192.168.61.1 port 55893 ssh2
Oct 10 11:46:47 localhost sshd[15915]: pam_unix(sshd:session): session opened for user root by (uid=0)
Oct 10 11:46:49 localhost sshd[13784]: pam_unix(sshd:session): session closed for user root
Oct 10 12:20:39 localhost sshd[16300]: Accepted password for root from 192.168.61.1 port 56474 ssh2
Oct 10 12:20:39 localhost sshd[16300]: pam_unix(sshd:session): session opened for user root by (uid=0)
Oct 10 12:20:41 localhost sshd[15915]: pam_unix(sshd:session): session closed for user root
日志的配置文件 位置在 /etc/rsyslog.conf
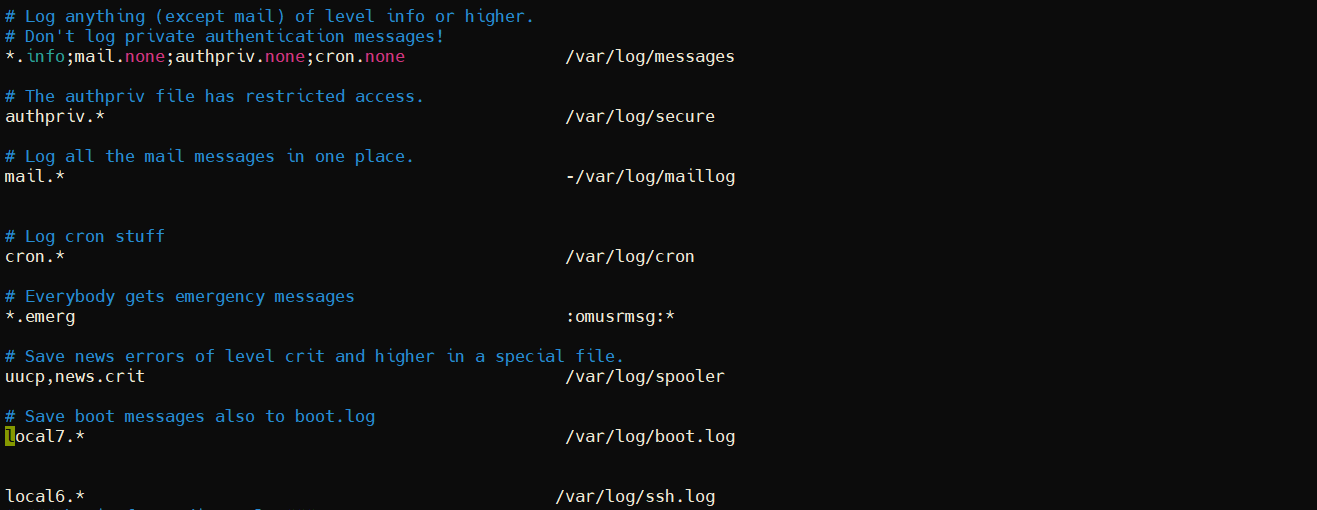
vim /etc/rsyslog.conf
#查看rsyslog.conf 配置文件
*.info;mail.none;authpriv.none;cron.none
#表示所有info等级以上的所有等级的信息都写到对应的日志文件里
mail.none
#表示某事件的信息不写到日志文件里(这里比如是邮件)
lastlog 等日志文件中,保存了系统用户登录、退出等相关的事件消息;
但是这些文件都是二进制的数据文件,不能直接使用 tail、less 等文本查看工具进行浏览;
users 命令只是简单地输出当前登录的用户名称,每个显示的用户名对应一个登录会话。 如果一个用户有不止一个登录会话,那他的用户名将显示与其相同的次数

以查看当前系统存在哪些不合法用户,从而对其进行审计和处理。who 的默认输出包括用

w 命令用于显示当前系统中的每个用户及其所运行的进程信息,比 users、who 命令的 输出内容要丰富一些。

最近的登录情况将显示在最前面。通过 last 命令可以及时掌握 Linux 主机的登录情况,若发现未经授权的用户登录过,则表示当前 主机可能已被入侵
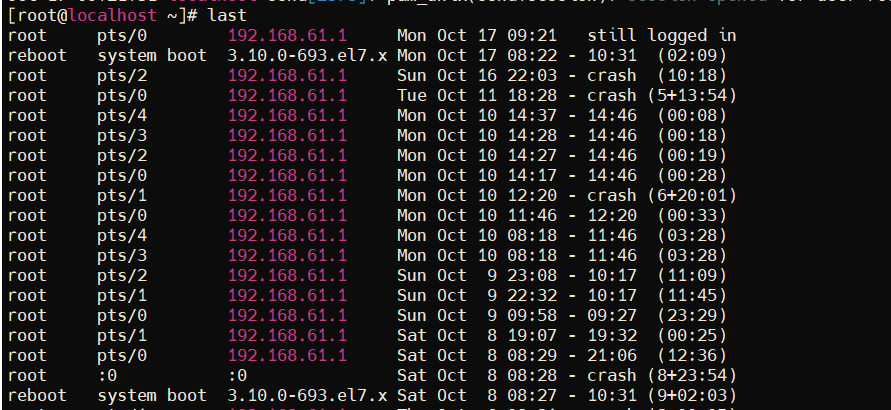
如登录的用户名错误、密码不正确等情况都 将记录在案。登录失败的情况属于安全事件,因为这表示可能有人在尝试猜解你的密码。除 了使用 lastb 命令查看以外,也可以直接从安全日志文件/var/log/secure 中获得相关信息。

日志文件是重要的系统信息文件,其中记录了许多重要的系统事件,包括用户的登录信息、系统的启动信息、系统的安全信息、邮件相关信息、各种服务相关信息等
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只