
⭐️前言⭐️
本篇文章就进入了自动化测试的章节了,如果作为一名测试开发人员,非常需要掌握自动化测试的能力,因为它不仅能减少人力的消耗,还能提升测试的效率。
🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁
🍉博主将持续更新学习记录收获,友友们有任何问题可以在评论区留言
🍉博客中涉及源码及博主日常练习代码均已上传GitHub

📍内容导读📍
自动化测试指软件测试的自动化,在预设状态下运行应用程序或者系统,预设条件包括正常和异常,最后评估运行结果。将人为驱动的测试行为转化为机器执行的过程,有效的减少人力的消耗,同时提高生活的质量。
通过自动化测试有效减少人力的投入,同时提高了测试的质量和效率
比如回归测试,版本越来越多,版本回归的压力也越来越大,仅仅通过人工测试来回归所有的版本肯定是不现实的,所以我们需要借助自动化测试。
自动化测试包括接口自动化测试、UI自动化测试、移动端自动化测试、web端自动化测试
用于进行web自动化测试的工具有很多,博主选择selenium作为我们web自动化测试的工具,有以下几点原因:
1)开源免费
2)支持很多浏览器;如Chrome、Firefox、IE浏览器等
3)支持多系统;如Linux、Windows、MacOS
4)支持多语言;Java、Python、CSharp、Ruby、JavaScript、Kotlin…
5)selenium包提供了很多可供测试使用的API
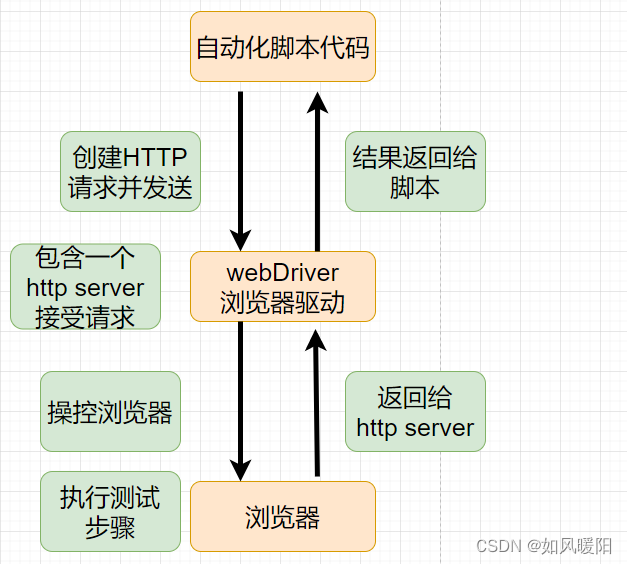
如果想要使用selenium实施web自动化测试,需要配置相应的浏览器的驱动,放在jdk的bin目录下,具体操作流程点击【链接】跳转,查看具体详情。
驱动使得计算机和设备工作起来。
人工测试的情况下,人能直接手动的打开浏览器,那么驱动就是人力;自动化来说,代码不能直接打开浏览器,需要借助驱动程序才能打开浏览器。
首先创建一个maven项目,在maven项目的pom.xml依赖中导入selenium的依赖。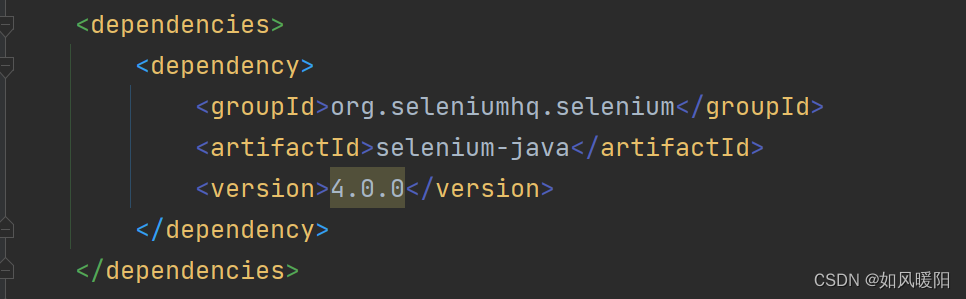
自动化脚本:
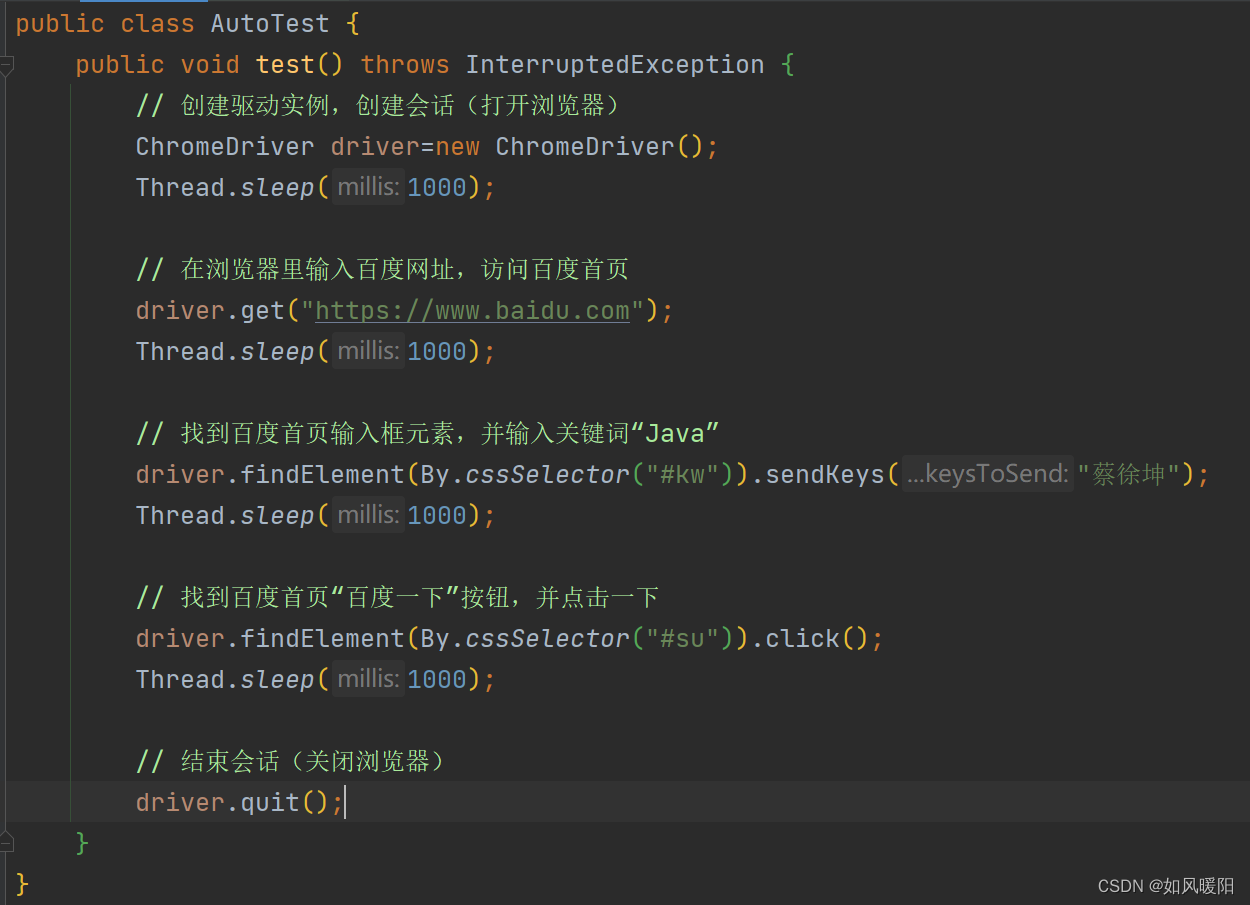
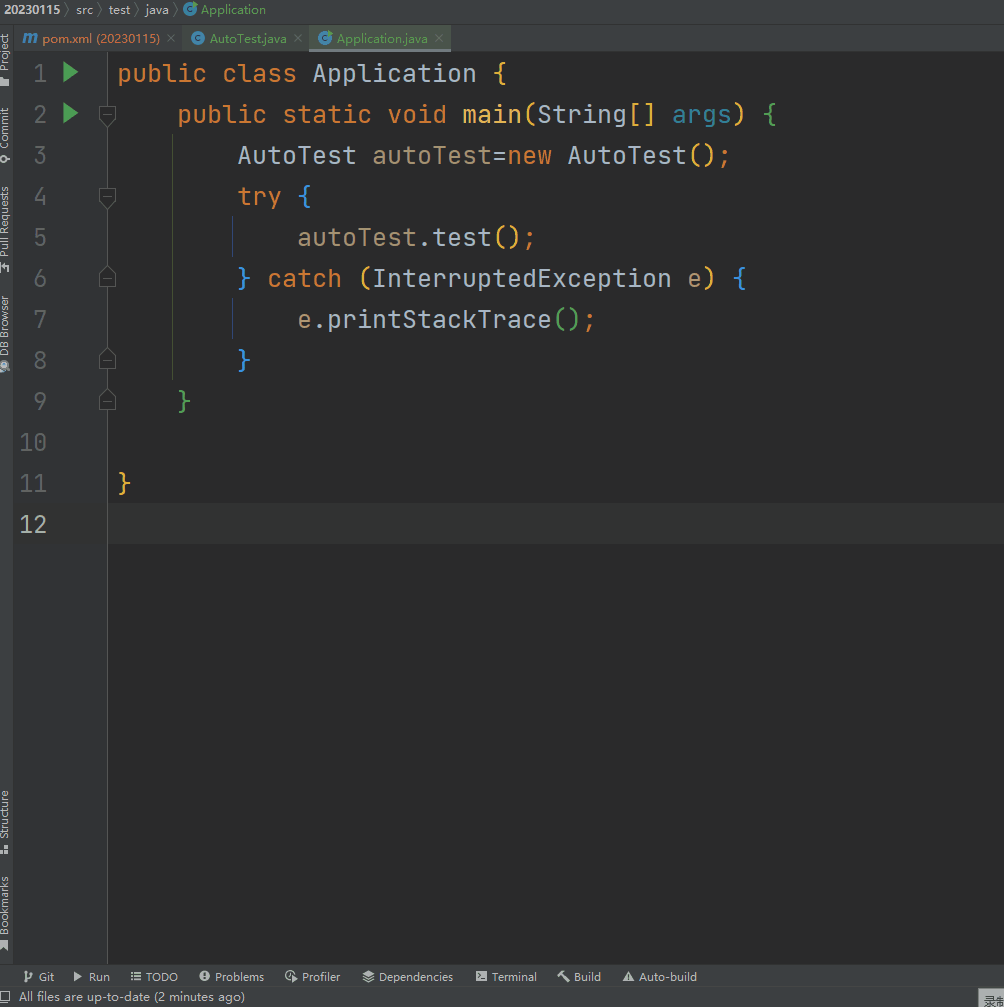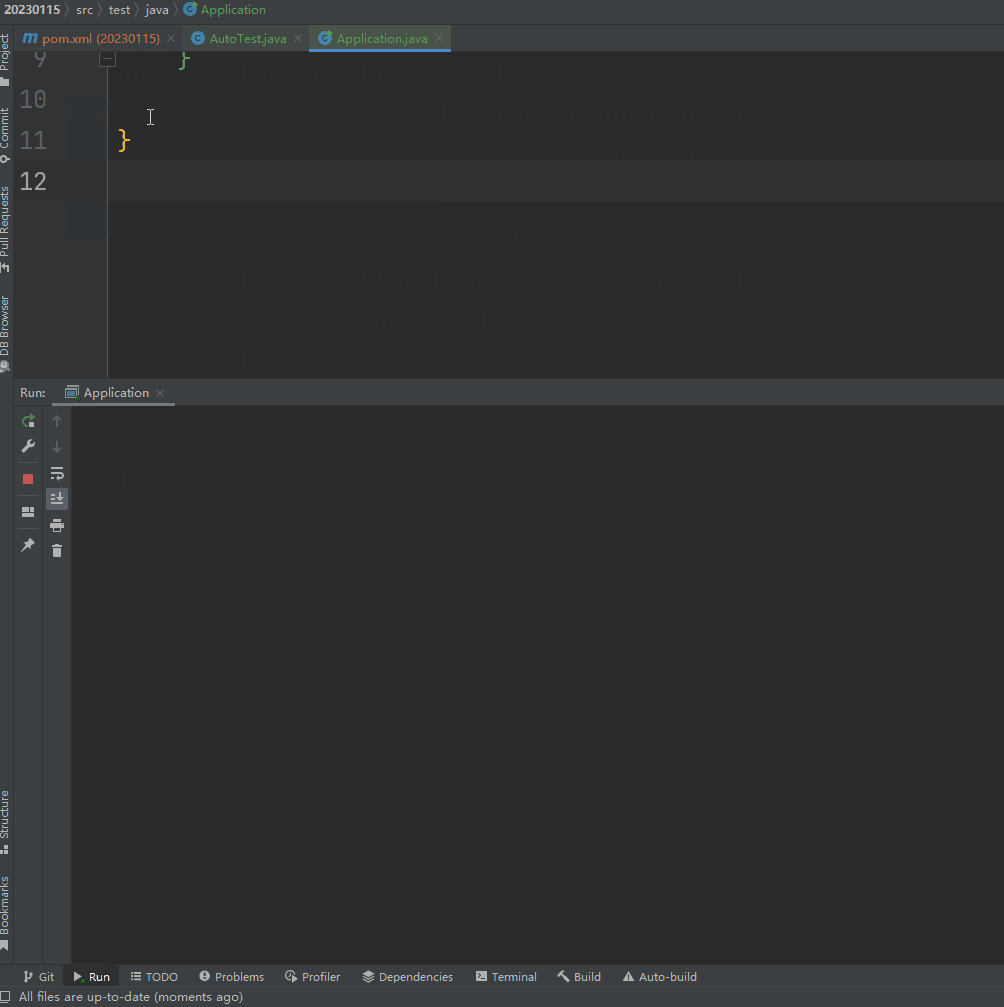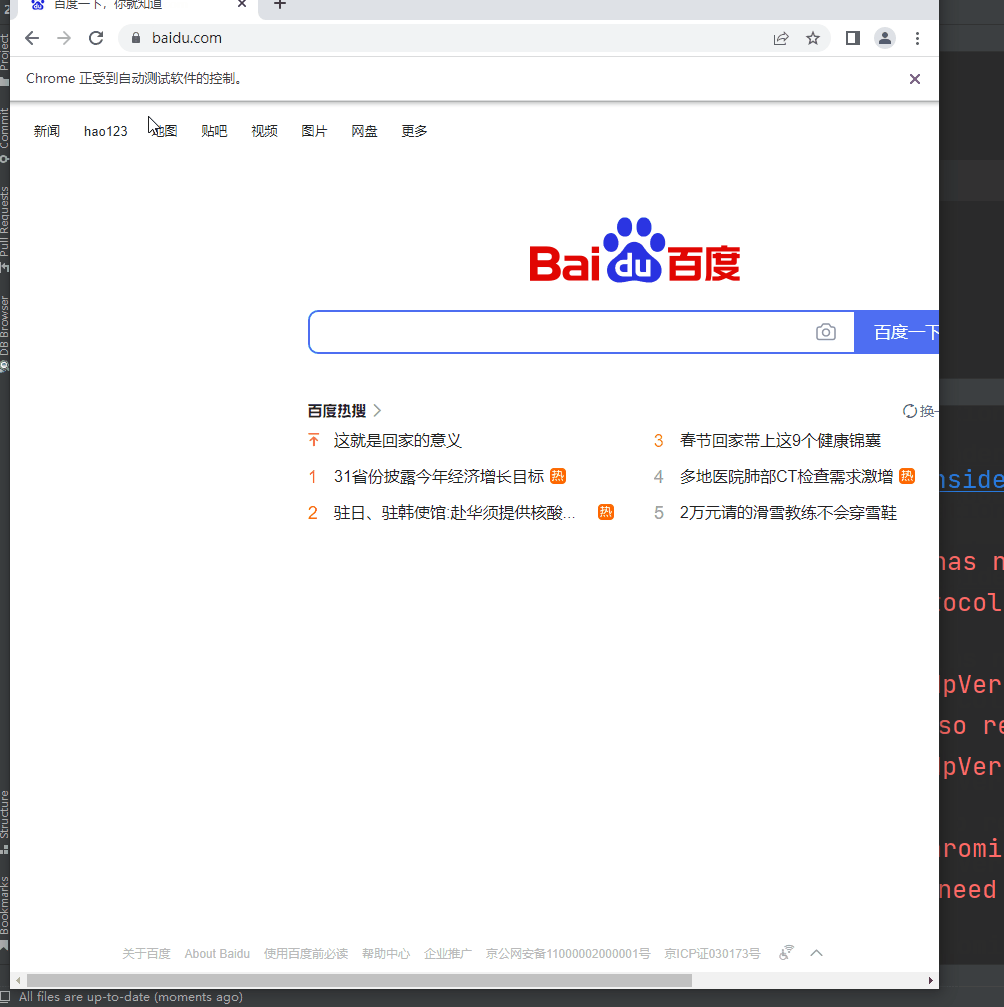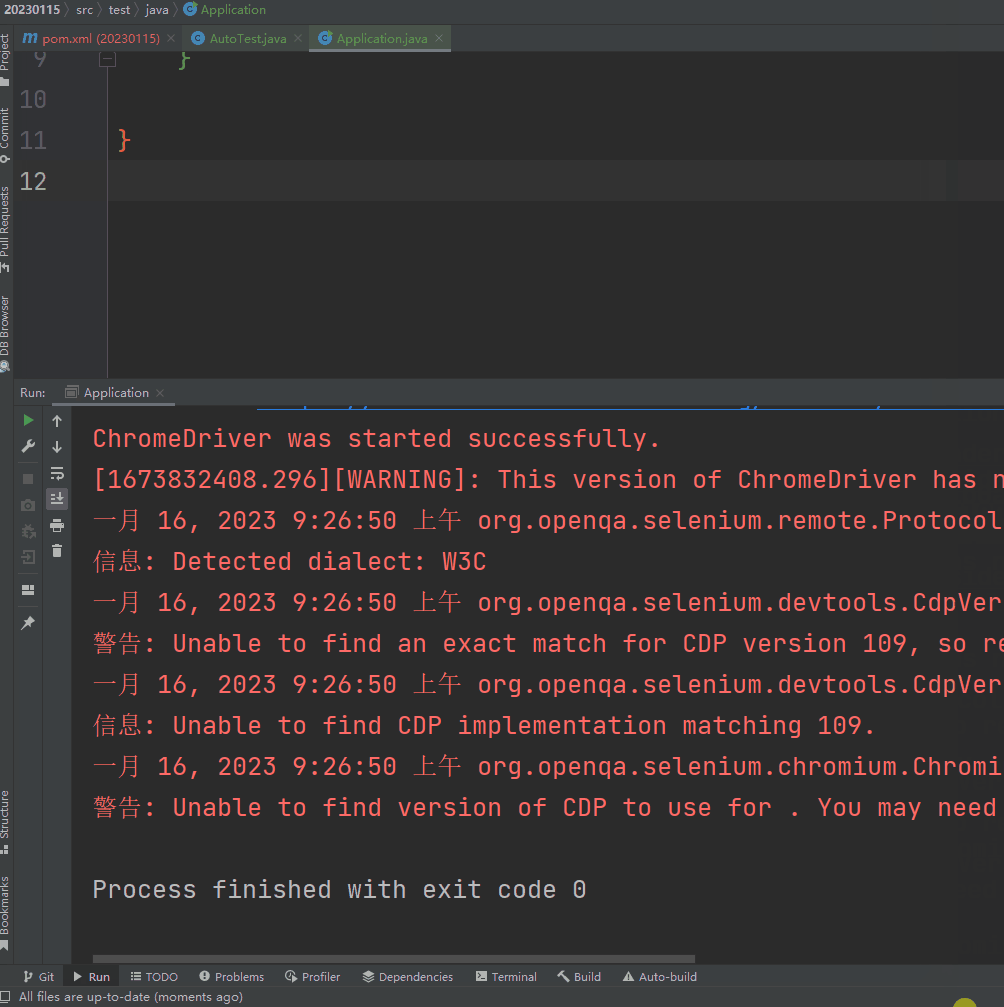
运行该脚本,人工不需要进行操作,就会自动打开谷歌浏览器,并输入蔡徐坤进行搜索,效果如下所示:
selenium常用方法介绍:
1.查找页面元素
findElement()
参数:By类(提供通过什么方式来查找元素)
返回值:webElement
findElements()
参数:By类(提供通过什么方式来查找元素)
返回值:List< WebElement >
当元素可以在页面找到的情况下,程序正常退出。
当元素在页面找不到的情况下,程序执行报错。
2.元素的定位By类
selector:选中页面中指定的标签元素
有基础选择器和复合选择器
xpath:
语法
层级:/ 子级 // 跳级
属性:@
函数:contains()...
自动化中要求元素的定位必须唯一,但是手动在页面复制
selector或者xpath元素,不一定是唯一的,需要我们进行手动修改到唯一。
页面查找元素方式:
打开开发者模式——>选择标签——>选中页面元素——>查看控制台选中部分代码——>右键——copy——选择selector或者xpath——>ctrl+f打开搜索框
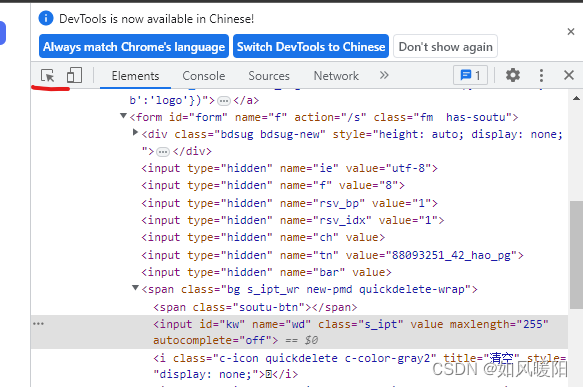
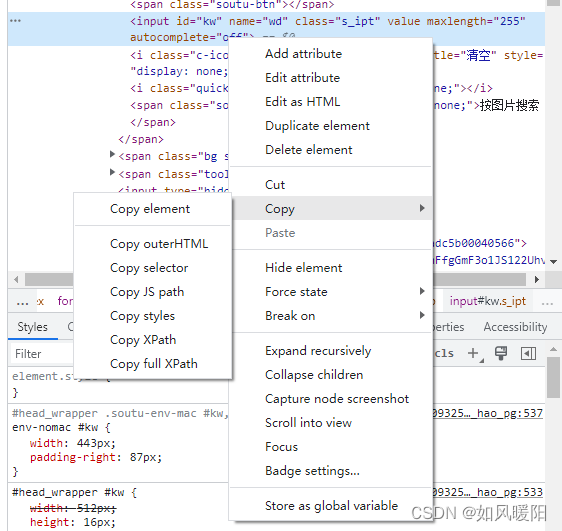
仅适用于文本字段和内容可编辑的元素
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
driver.findElement(By.cssSelector("#su")).click();
通过回车键实现提交,仅适用于表单元素()
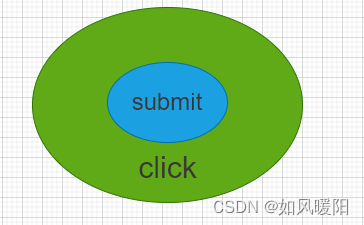
【selenium官方不推荐使用submit,更推荐使用click】
用于频繁测试输入是否可以重复输入
driver.findElement(By.cssSelector("#kw")).clear();
获取文本——getText()
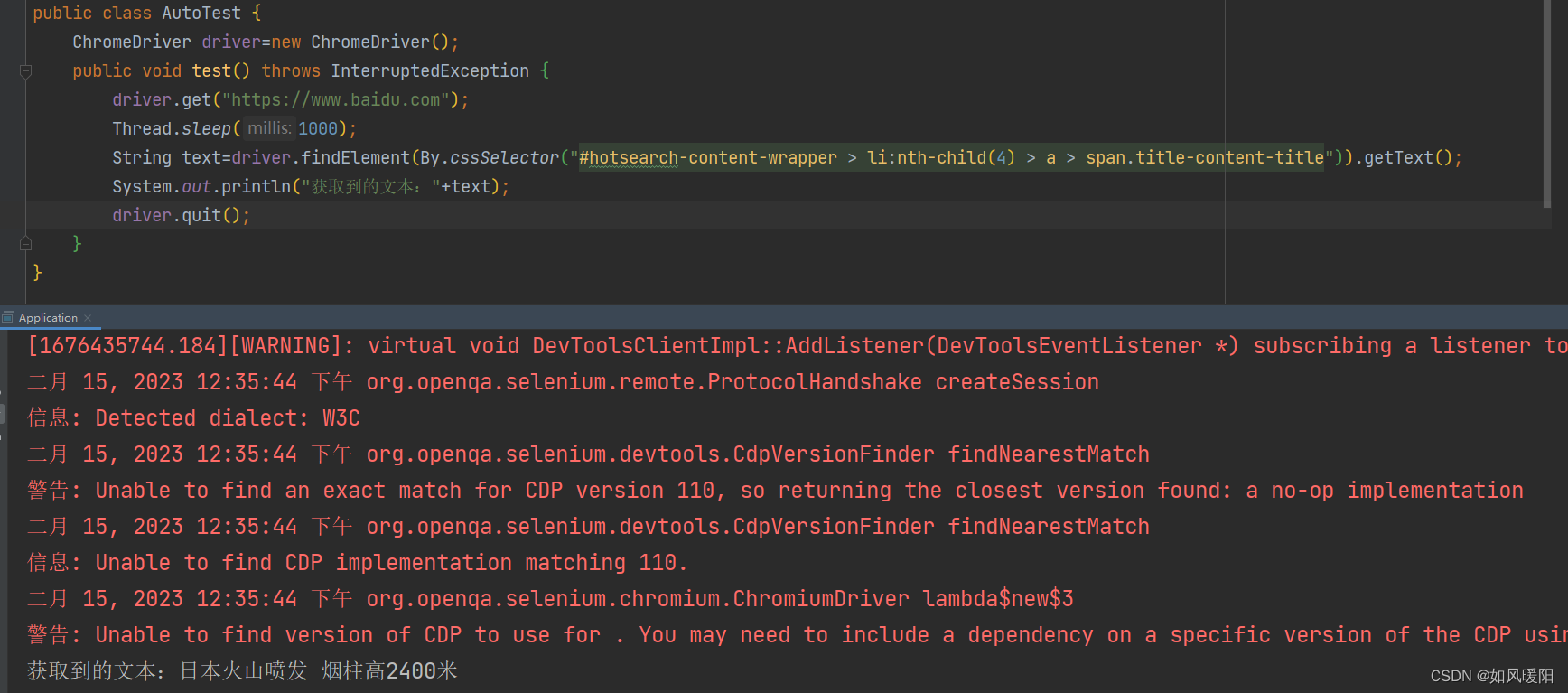
获取属性——getAttribute()
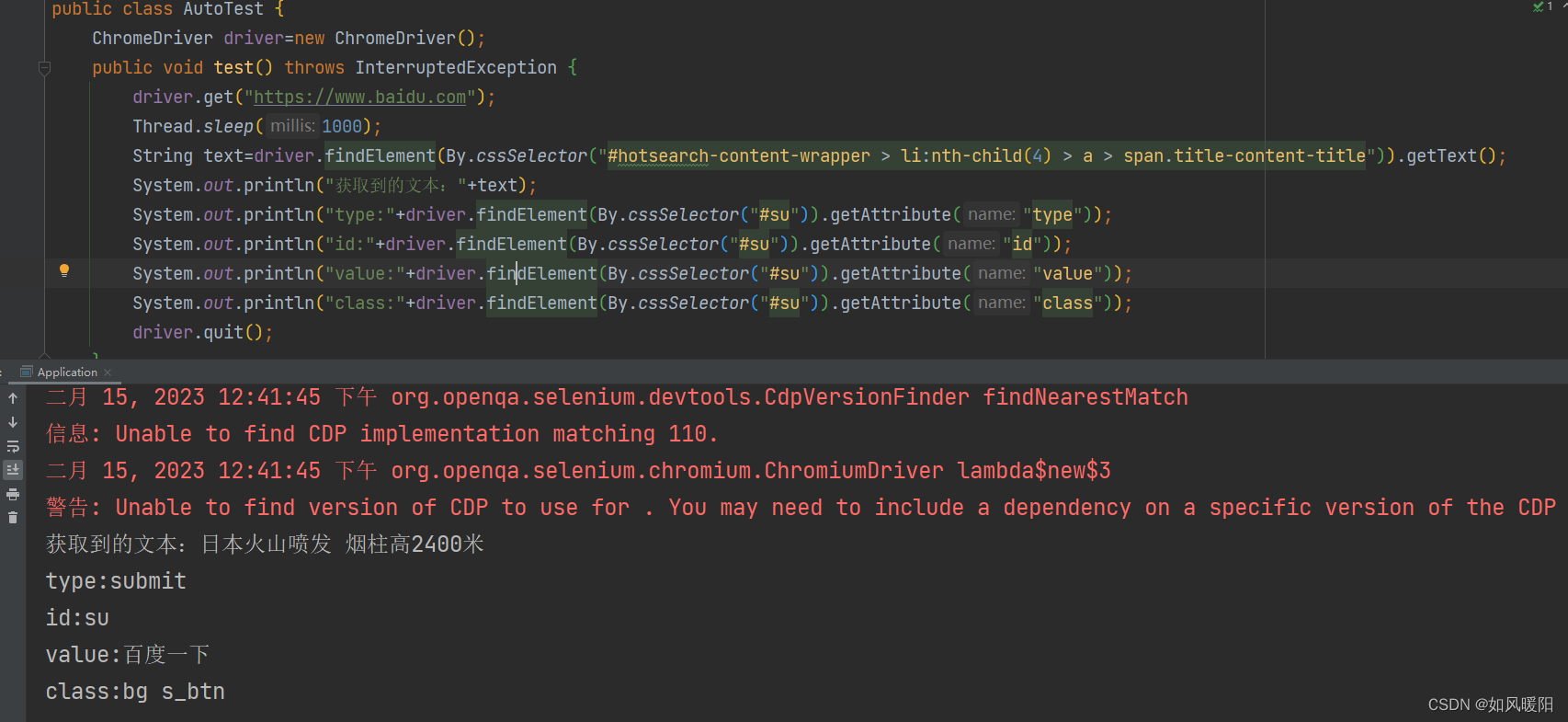
获取页面的标题和URL
getTitle() getCurrentUrl()
public void windowControl() throws InterruptedException {
Thread.sleep(1000);
driver.manage().window().maximize();
Thread.sleep(3000);
driver.manage().window().minimize();
Thread.sleep(3000);
driver.manage().window().fullscreen();
Thread.sleep(3000);
driver.manage().window().setSize(new Dimension(1024,888));
Thread.sleep(2000);
driver.quit();
}
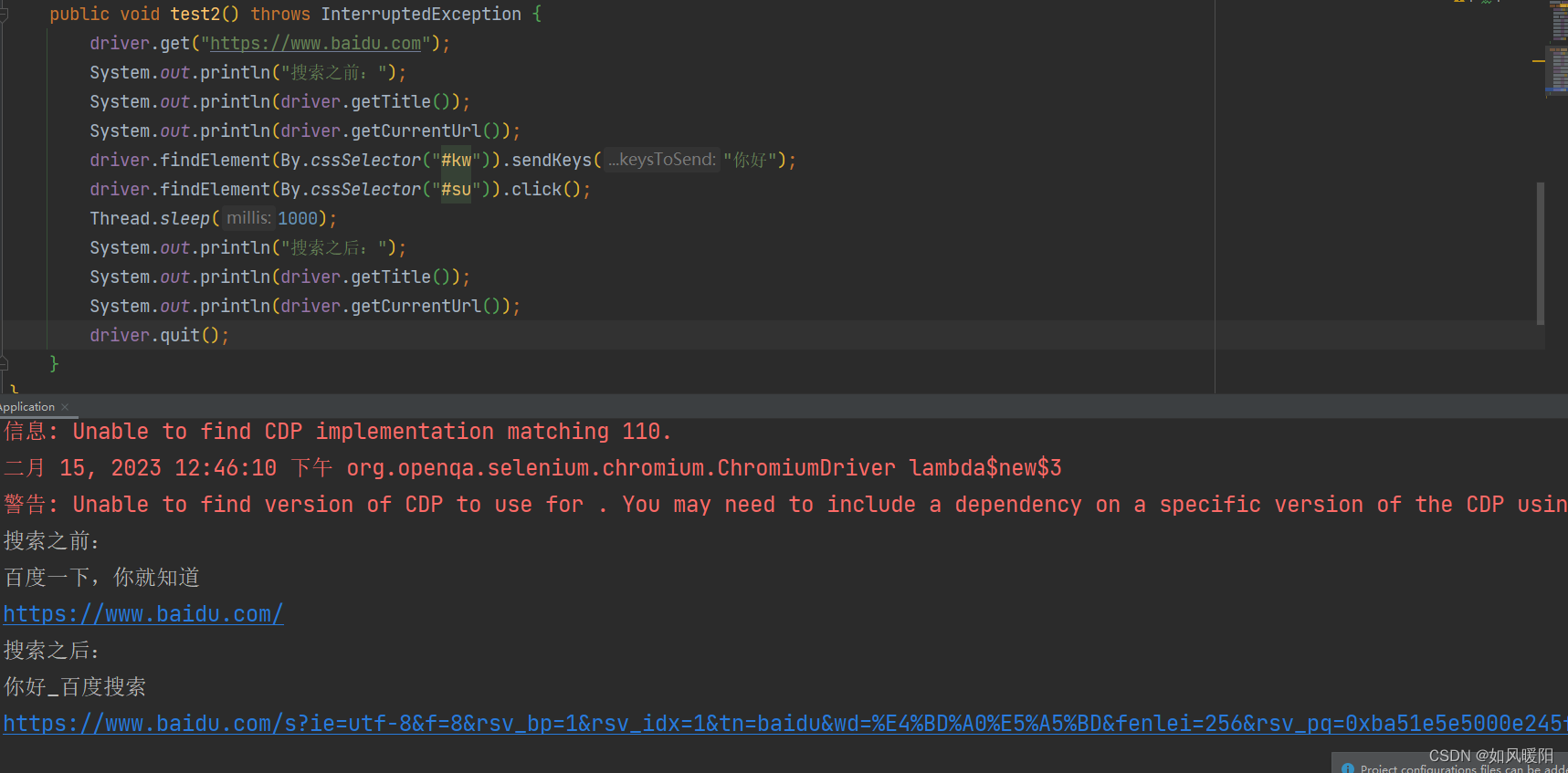
打开百度首页,点击图片超链接进入到百度图片首页,获取百度图片页面的“百度一下”,结果如下所示报错,找不到所选择的页面元素。
这是因为当打开多个页面窗口后,浏览器无法识别对哪个窗口的元素进行选择,所以才会导致这样的报错,解决办法如下:
通过句柄的选择,选择到单个页面
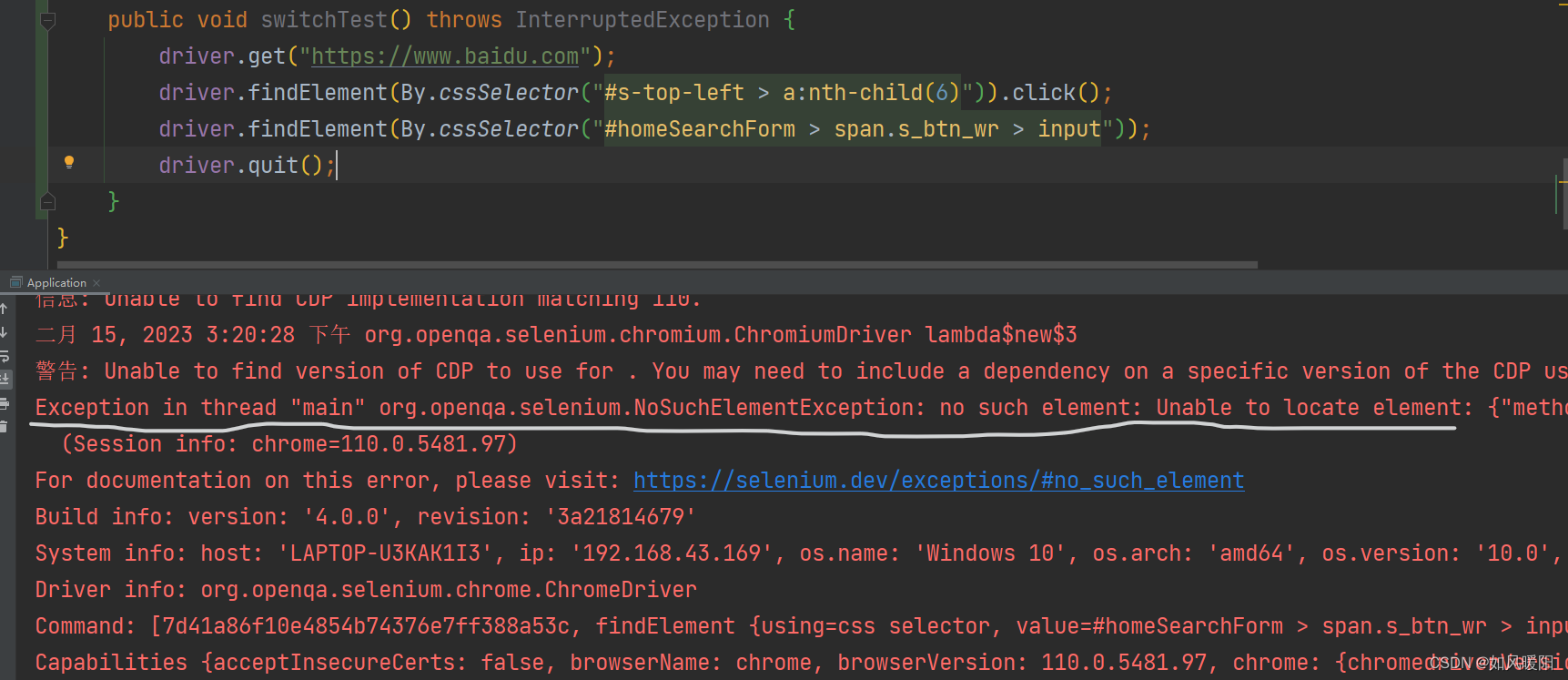
public void switchTest() throws InterruptedException {
driver.get("https://www.baidu.com");
driver.findElement(By.cssSelector("#s-top-left > a:nth-child(6)")).click();
// 获取当前页面的句柄
String curHandle=driver.getWindowHandle();
System.out.println("当前页面的句柄:"+curHandle);
// 先获取所有标签的句柄
Set<String> handles=driver.getWindowHandles();
for(String handle:handles) {
if(handle!=curHandle) {
driver.switchTo().window(handle);
}
}
driver.findElement(By.cssSelector("#homeSearchForm > span.s_btn_wr > input"));
driver.quit();
}
当程序报错时我们可能无法抓取到具体的错误原因,这个时候可以通过在代码中实现屏幕抓取的方式,将出现错误时的页面截图,来进一步查看错误的原因。
如下操作示例:
在百度首页输入框输入”迪丽热巴“,点击搜素,并选择下图的元素
按照逻辑该实现过程并不应该出错,但是却抛出了异常。
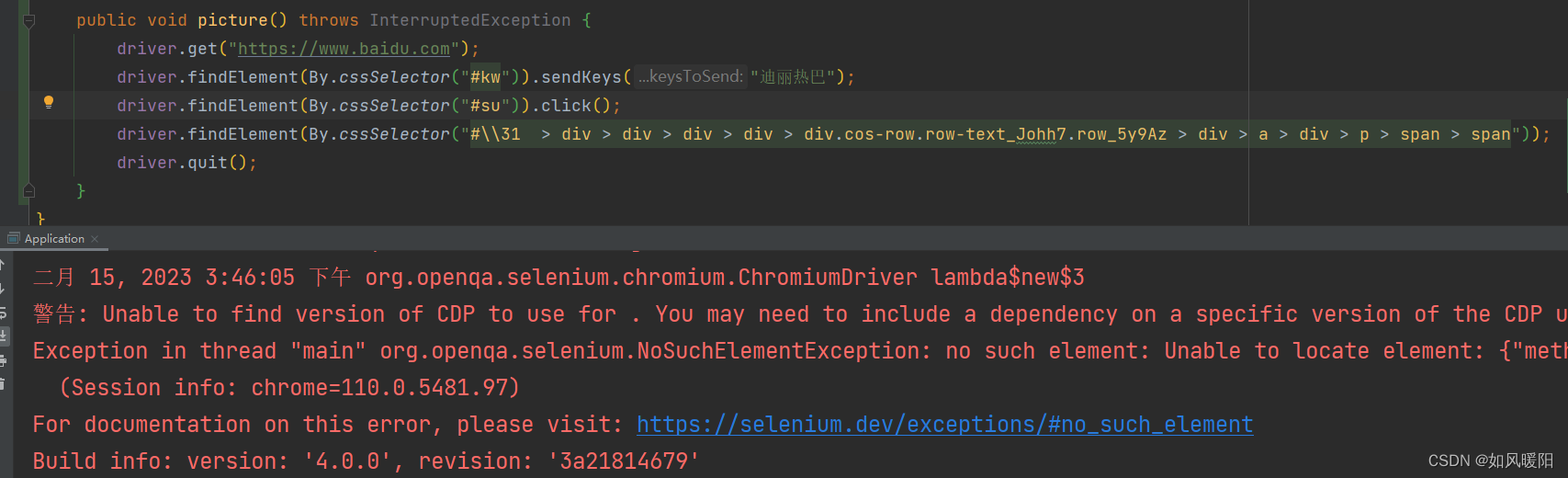
我们通过截图操作来查看报错的原因:
先配置截图所需的xml文件
<!-- 保存屏幕截图文件需要用到的包 -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
代码调整:
public void picture() throws InterruptedException, IOException {
driver.get("https://www.baidu.com");
driver.findElement(By.cssSelector("#kw")).sendKeys("迪丽热巴");
driver.findElement(By.cssSelector("#su")).click();
// 屏幕截图(保存现场)
File srcFile=driver.getScreenshotAs(OutputType.FILE);
// 把屏幕截好的文件放到指定的路径下
String fileName="my.png";
FileUtils.copyFile(srcFile,new File(fileName));
driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span"));
driver.quit();
}
截取到的图片:
由此可见是因为页面没有加载出来而导致的错误,所以让页面加载出来后就不会报错了
代码调整:执行click操作后让线程休眠等待一会页面的加载
public void picture() throws InterruptedException, IOException {
driver.get("https://www.baidu.com");
driver.findElement(By.cssSelector("#kw")).sendKeys("迪丽热巴");
driver.findElement(By.cssSelector("#su")).click();
Thread.sleep(3000);
// 屏幕截图(保存现场)
File srcFile=driver.getScreenshotAs(OutputType.FILE);
// 把屏幕截好的文件放到指定的路径下
String fileName="my.png";
FileUtils.copyFile(srcFile,new File(fileName));
driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span"));
driver.quit();
}
注意:
当文件名相同时,程序多次执行生成的图片文件会被同名覆盖,所以可以给图片命名加上UUID或者时间戳来防止被覆盖。
由于程序执行的速度要比浏览器渲染的速度快得多,所以就需要在程序中设置等待,来防止6.2中屏幕截图示例,由于页面没有加载出来而导致的错误。
此处主要介绍三种等待方式:强制等待、隐式等待、显示等待
该方式通过调用Thread.sleep()来使程序阻塞进行,但是该方式有点太耗时,所以在自动化测试中并不是非常常用
隐式等待会作用于driver的整个生命周期,会一直轮询判断元素是否存在,如果不存在,就在等待设置好的时间里不断的进行轮询,直到元素能够被找到(如果超过时间还未找到就报错)
public void implicitlyWait() {
// 添加隐式等待
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(5));
driver.get("https://www.baidu.com");
driver.findElement(By.cssSelector("#kw")).sendKeys("迪丽热巴");
driver.findElement(By.cssSelector("#su")).click();
driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span"));
driver.quit();
}
当等待的条件满足后(一般用来判断需要等待的元素是否加载出来),就继续下一步操作。等不到就一直等,如果在规定的时间之内都没找到,那么就跳出Exception。
public void webDriverWait() {
driver.get("https://www.baidu.com");
driver.findElement(By.cssSelector("#kw")).sendKeys("迪丽热巴");
driver.findElement(By.cssSelector("#su")).click();
// 添加显示等待
new WebDriverWait(driver,Duration.ofSeconds(5))
.until(driver->driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span")));
driver.quit();
}
总结:
如果是只需等待页面中的一个元素加载就用显示等待,等待整个网页加载就用隐式等待。
隐式等待可以跟强制等待搭配使用(有时候隐式等待可能不生效),但注意隐式等待不能和显式等待一起用。
selenium可以执行js脚本,完成js操作,如下所示:
public void scriptTest() throws InterruptedException {
driver.get("https://image.baidu.com/");
Thread.sleep(1000);
// 执行js命令:让页面置顶/置底 (如果想滑到最下面,值设置的大一些即可)
driver.executeScript("document.documentElement.scrollTop=500");
Thread.sleep(1000);
// 值为0就是顶部
driver.executeScript("document.documentElement.scrollTop=0");
Thread.sleep(1000);
driver.quit();
}
如下图所示:浏览器的导航栏会有前进、后退、刷新这样三个操作。

public void navigateTest() {
driver.navigate().to("https://www.baidu.com");
// 想要回退到访问百度网址之前的状态
driver.navigate().back();
// 前进,又进入到了百度首页
driver.navigate().forward();
// 刷新百度首页
driver.navigate().refresh();
driver.quit();
}
弹窗有三种类型:警告弹窗、确认弹窗、提示弹窗
处理弹窗的步骤:
1、将driver对象作用到弹窗上(切换到弹窗)driver.switchTo().alert()
2、选择确认/取消或者在提示弹窗输入文本
accept()、dismiss()、sendKeys()
public void alertTest() throws InterruptedException {
driver.get("file:///D:/%E4%BB%A3%E7%A0%81%E4%BB%93%E5%BA%93/selenium-html/Prompt.html");
Thread.sleep(1000);
// 打开弹窗
driver.findElement(By.cssSelector("body > input[type=button]")).click();
Thread.sleep(1000);
// 切换到弹窗进行弹窗的处理
Alert alert=driver.switchTo().alert();
Thread.sleep(1000);
// 弹窗输入文本
alert.sendKeys("这是输入的文本");
Thread.sleep(1000);
// 1.点击确认
alert.accept();
// 2.点击取消
// alert.dismiss();
Thread.sleep(1000);
driver.quit();
}
选择框的选择方式有:
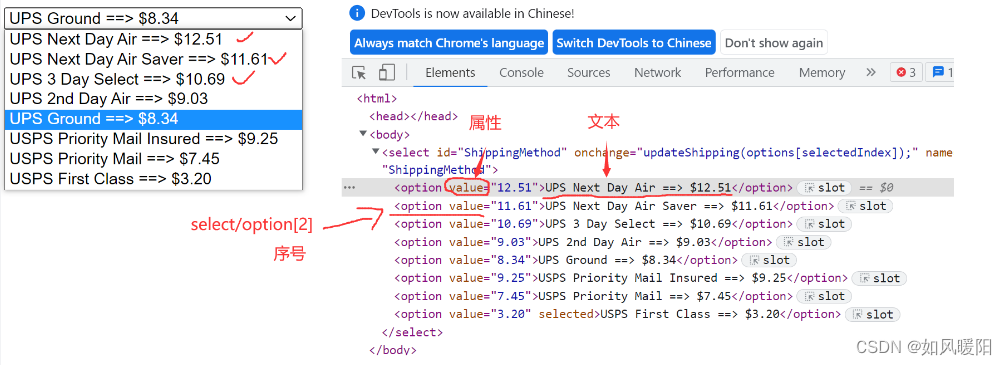
public void selectTest() throws InterruptedException {
driver.get("file:///D:/%E4%BB%A3%E7%A0%81%E4%BB%93%E5%BA%93/selenium-html/select.html");
Thread.sleep(2000);
WebElement ele=driver.findElement(By.cssSelector("#ShippingMethod"));
// 先创建选择框对象
Select select=new Select(ele);
Thread.sleep(2000);
// 根据文本来选择
//select.selectByVisibleText("UPS Next Day Air ==> $12.51");
// 根据属性值来选择
// select.selectByValue("12.51");
// 根据序号来选择
select.selectByIndex(1);
Thread.sleep(2000);
driver.quit();
}
通过sendKeys("文件路径+文件")
public void fileUploadTest() throws InterruptedException {
driver.get("file:///D:/%E4%BB%A3%E7%A0%81%E4%BB%93%E5%BA%93/selenium-html/upload.html");
Thread.sleep(2000);
driver.findElement(By.cssSelector("body > div > div > input[type=file]")).sendKeys("D:\\代码仓库\\selenium-html\\upload.html");
Thread.sleep(2000);
driver.quit();
}
实际在工作中,测试人员将自动会部署在机器上自动去执行,并不会每次都监视自动化执行的过程,而是直接查看自动化执行的结果。
所以衍生出了无头模式的自动化测试,需要在创建浏览器对象之前就完成参数的设置。
public class ParamsTest {
void paramsTest() {
// 百度搜索迪丽热巴
// 先创建选项对象,然后再设置浏览器参数
ChromeOptions options=new ChromeOptions();
options.addArguments("-headless");
ChromeDriver driver=new ChromeDriver(options);
driver.get("https://www.baidu.com");
driver.findElement(By.cssSelector("#kw")).sendKeys("迪丽热巴");
driver.findElement(By.cssSelector("#su")).click();
driver.quit();
}
}
⭐️最后的话⭐️
总结不易,希望uu们不要吝啬你们的👍哟(^U^)ノ~YO!!如有问题,欢迎评论区批评指正😁

我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po