在Ubuntu20.04版本中,没有/etc/network/interfaces文件,而是使用/etc/netplan/01-network-manager-all.yaml文件配置网络
目录
出现问题:
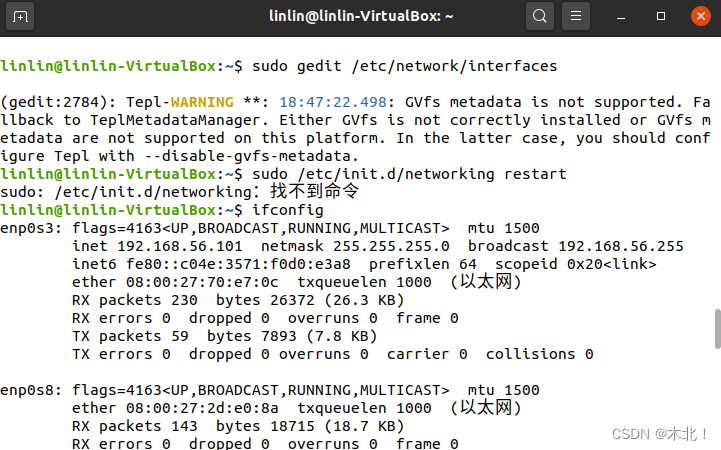
编辑/etc/network/interfaces文件信息,再执行下面命令使配置生效,结果找不到命令
linlin@master:~$ sudo /etc/init.d/networking restart
sudo: /etc/init.d/networking:找不到命令
原因说明:
/etc/network路径下原本并没有interfaces文件

/etc/netplan路径下有*.yaml文件

Ubuntu20.04的配置网络不是修改interfaces文件,而是需要修改*.yaml文件
解决步骤:
1. 使用命令查看IP端口名称,当前IP地址,掩码,广播地址
ifconfig
2. 在终端输入命令,编写文件(#后面的文字是注释,需要去掉)
sudo gedit /etc/netplan/01-network-manager-all.yaml
# Let NetworkManager manage all devices on this system
network:#网络
version: 2#版本
renderer: NetworkManager#渲染器
ethernets:#以太网
enp0s3:
addresses: [192.168.1.10/24]
dhcp4: no
dhcp6: no
gateway4: 192.168.1.1#网关
nameservers:#域名服务器
addresses: [192.168.1.1,114.114.114.114]3. 输入命令,使刚才的配置生效
sudo netplan apply
4. 再次输入命令,查看修改后的IP地址(对比下面的红色标记),修改成功!
ifconfig

参考:
Ubuntu 20.4 没有/etc/network/interfaces,配置网络需用Netplan
网计划|YAML 中与后端无关的网络配置 (netplan.io)
问题说明:网络配置中修改了interfaces文件,结果端口信息都看不到了(本来有enp0s3端口)

解决方法:
1. 在/etc/network的路径进入终端输入命令,删除文件(建议)
rm interfaces
或者清空修改的interfaces文件:sudo gedit /etc/network/interfaces
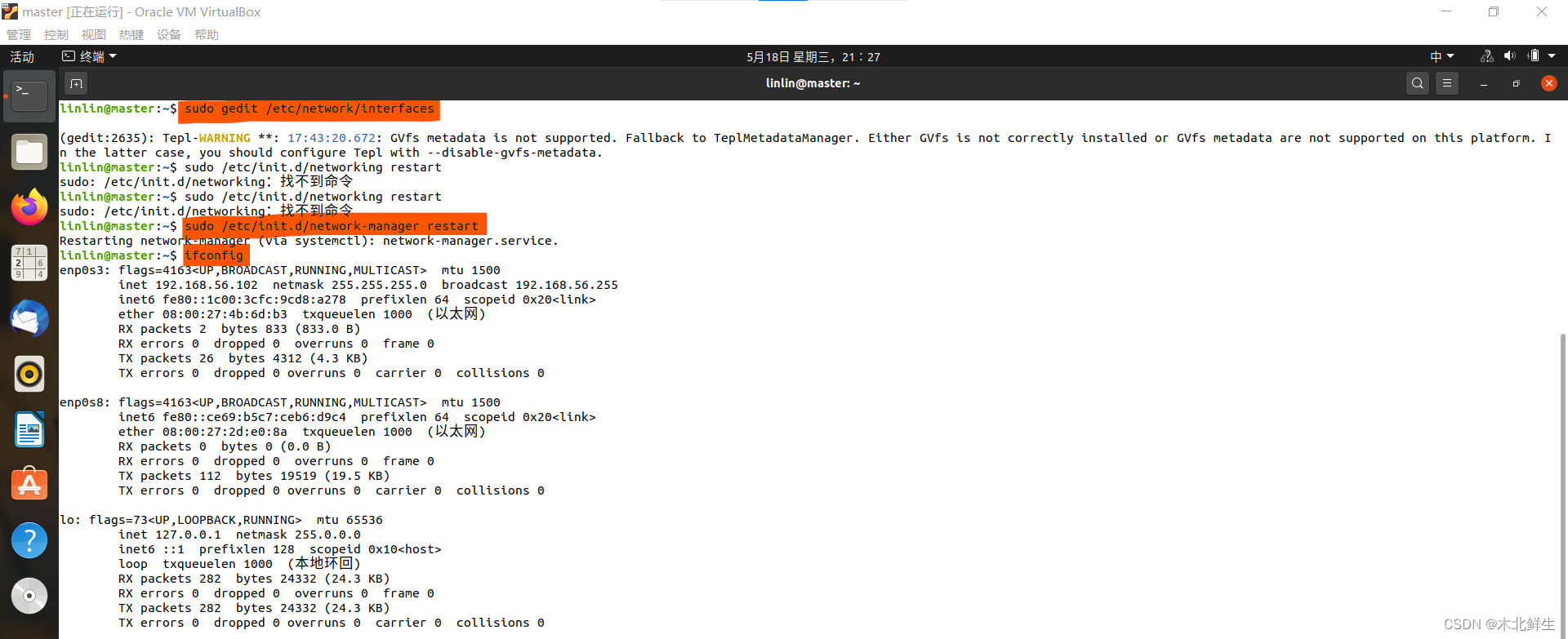
2. 输入下行的命令,使配置生效(sudo /etc/init.d/networking restart这条命令无效)
sudo /etc/init.d/network-manager restart
3. 再输入命令,就可以看到网卡回来了(下图中红色标记为输入的命令)
ifconfig
原因说明:
当使用网络地址转换时,为10.0.2.15,公网下可以上网
当使用仅主机网络时,为192.168.56.101,为私人网段,不能上网
修改IP地址为192.168.1.10,依然为私人网段,不能上网

解决方法:
虚拟机未启动的状态下,设置网卡一连接方式为网络地址转换(NAT),其它网卡取消勾选启用网络连接,点击ok
出现问题:编写masters文件,出现找不到文件,检查输入位置是否正确并重试
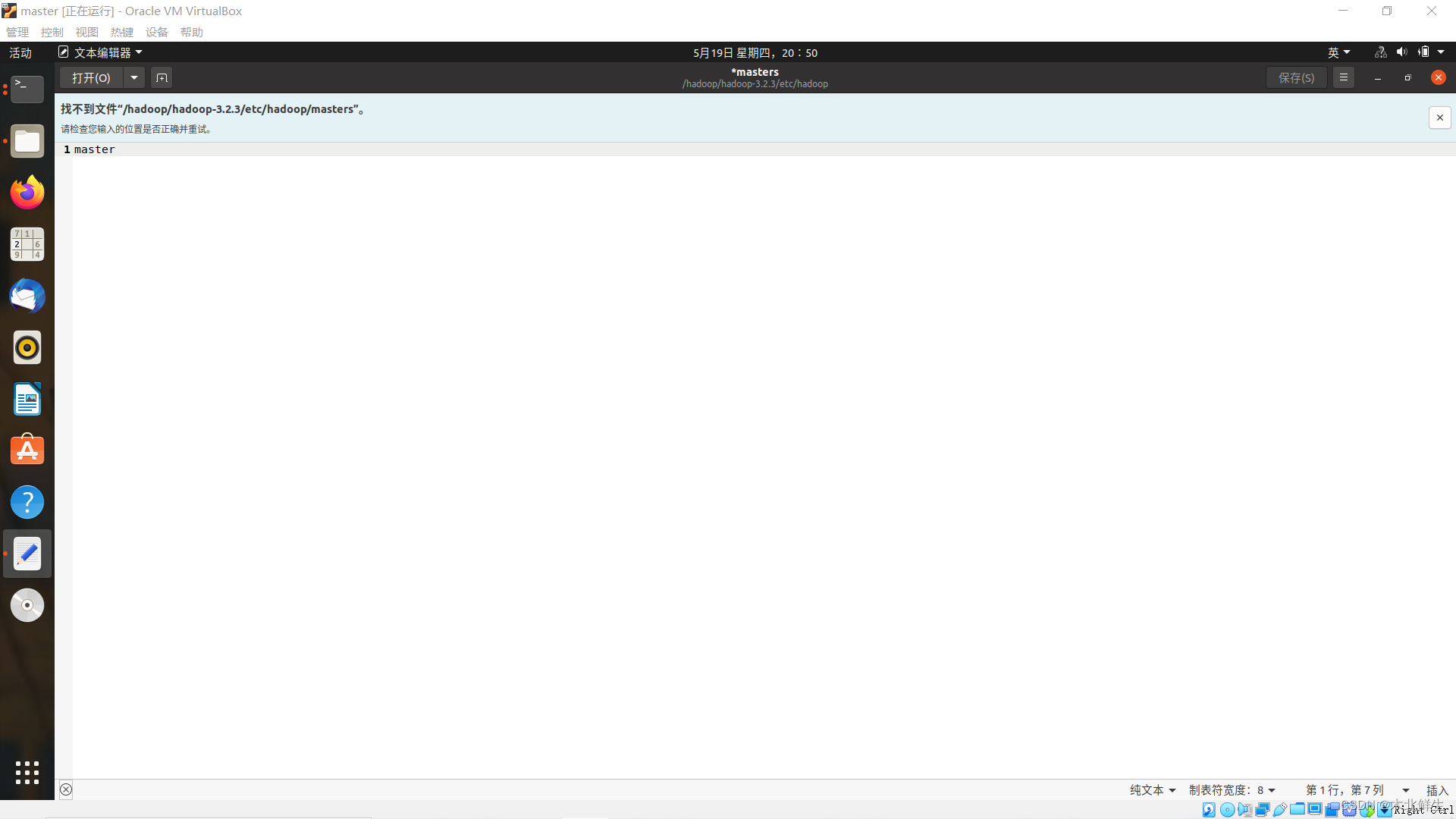
原因说明:混淆了绝对路径和相对路径,在主目录/home/linlin下打开终端,如下图
第一条绝对路径正确,根目录/下/etc/hosts文件确实存在
第二条绝对路径错误,根目录/下不存在/hadoop.../masters文件
第一条相对路径正确,主目录/home/linlin存在/hadoop.../masters文件
第一条相对路径正确,主目录/home/linlin存在/hadoop.../masters文件,省略了./

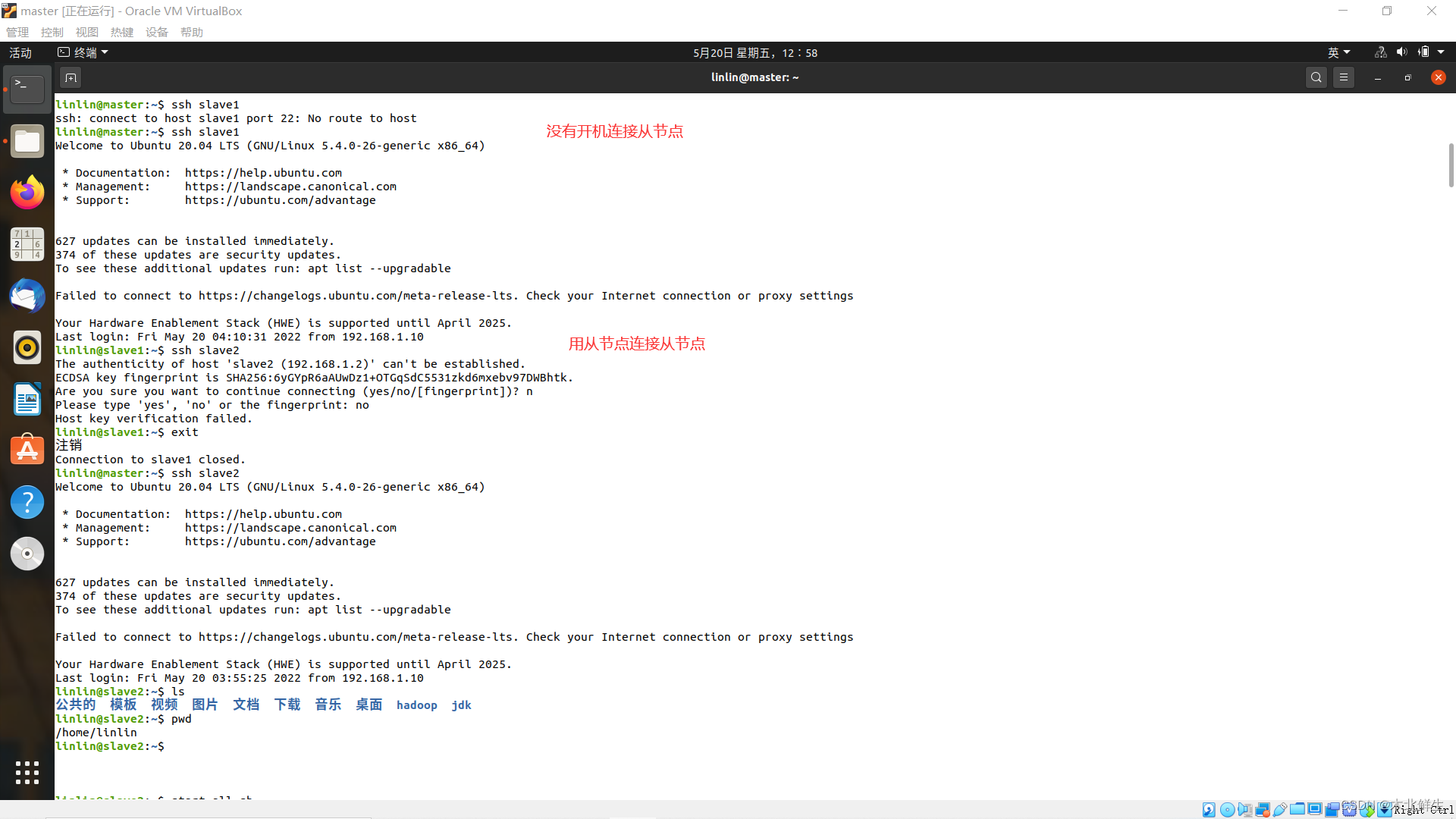
master节点进程正常启动,但是不能连接slave节点
hdfs页面Live Node节点数为0,yarn页面node数为0




出现问题:配置好所有节点后,启动hadoop,发现其中slave服务器缺少datanode进程
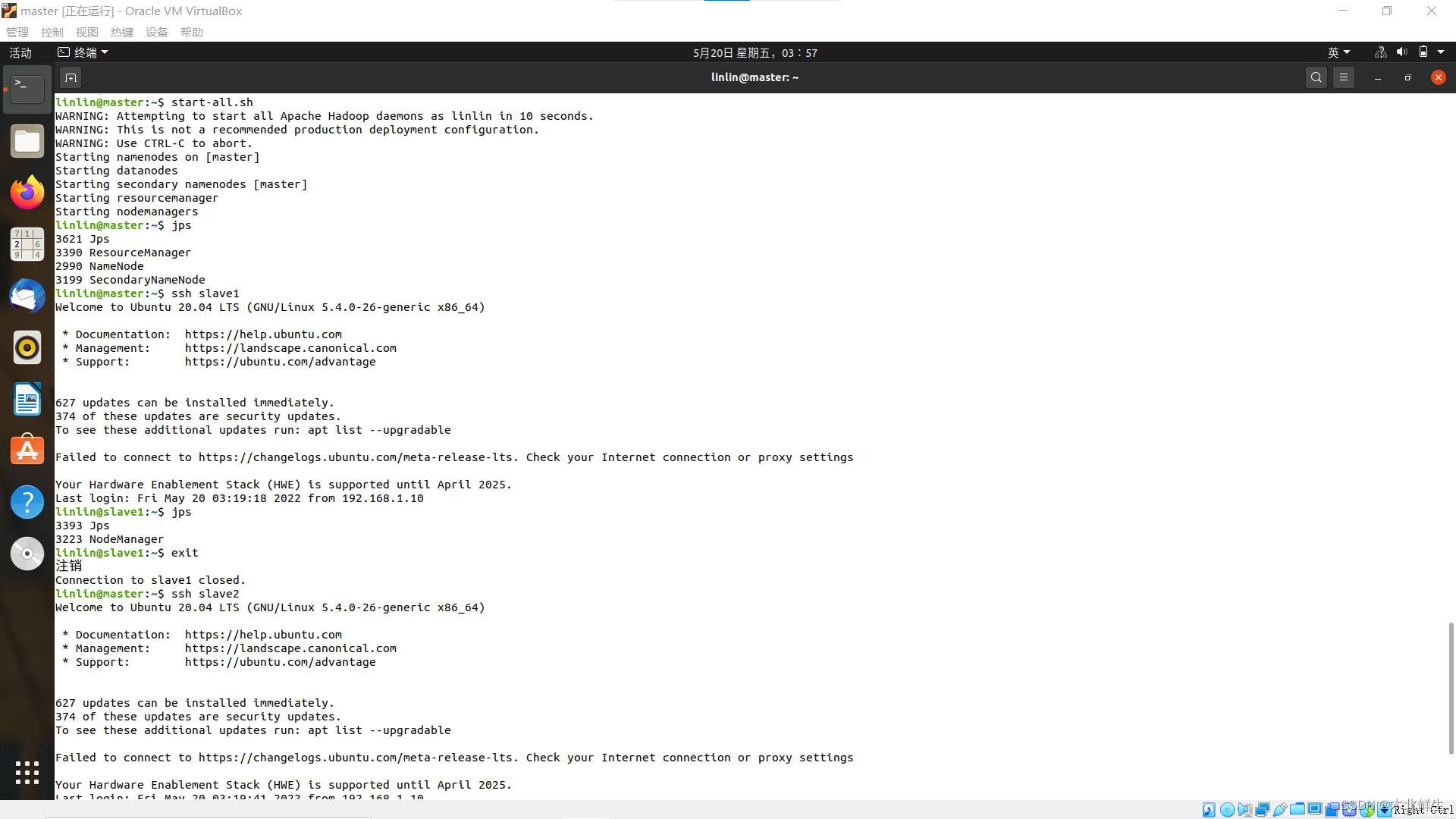
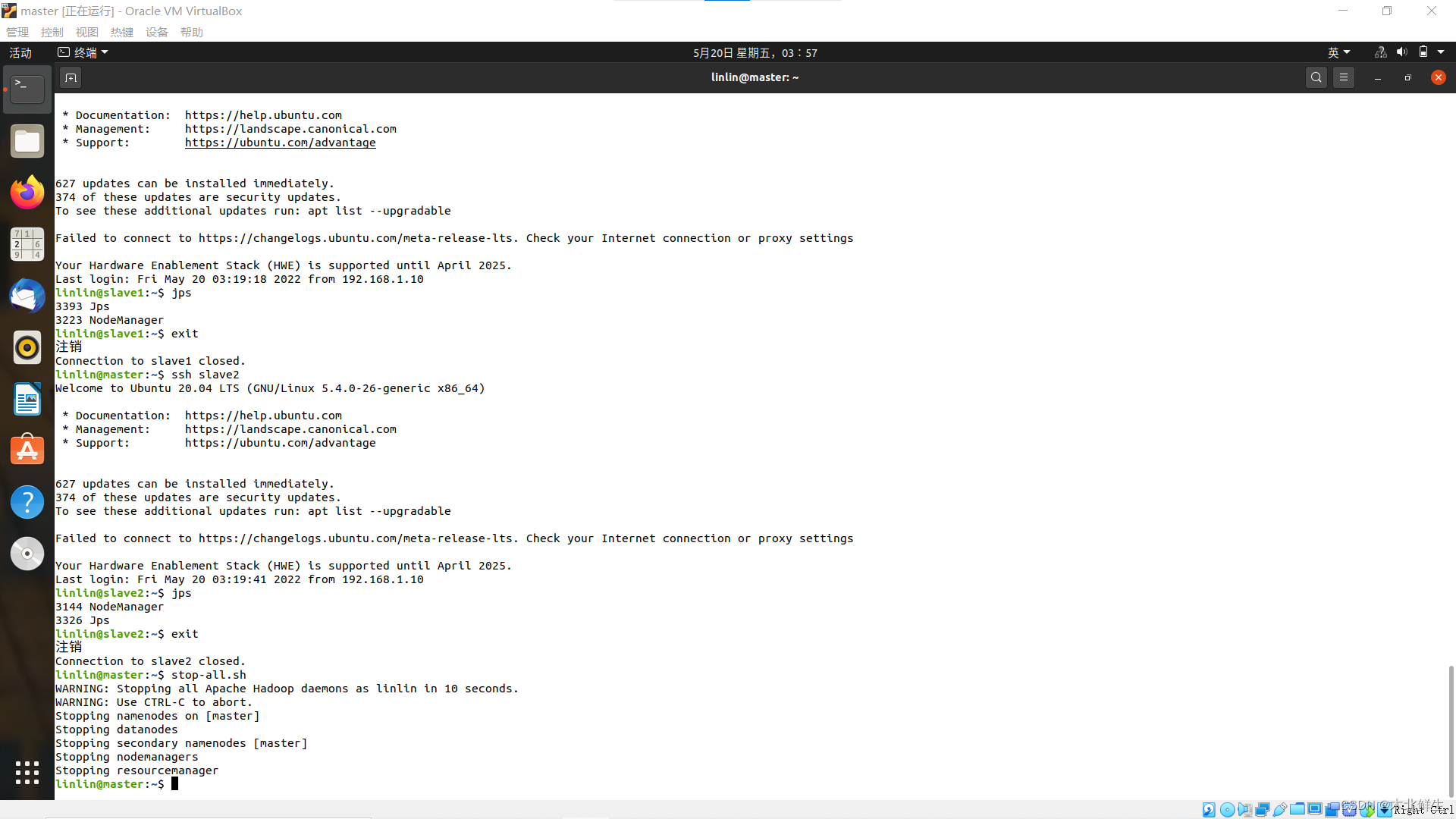
查看web页面,hdfs页面LiveNode节点数为0,yarn页面正常可以查看node信息


原因说明:
之前配置hadoop时,创建和产生的临时文件:
file:///home/linlin/hadoop/hadoop-3.2.3/dataNode_1_dir
file:///home/linlin/hadoop/hadoop-3.2.3/logs
file:///home/linlin/hadoop/hadoop-3.2.3/hadoop_data/hdfs/datanode
file:///home/linlin/hadoop/hadoop-3.2.3/hadoop_data/hdfs/namenode
这些路径下的/dfs/namesecondary/current/VERSION文件或者/current/VERSION文件与进程的节点存储目录有关。正常的集群应该是:master上只有namenode临时文件,slave上只有datanode临时文件。两个目录的临时文件信息应该通过什么关联,对比文件发现:
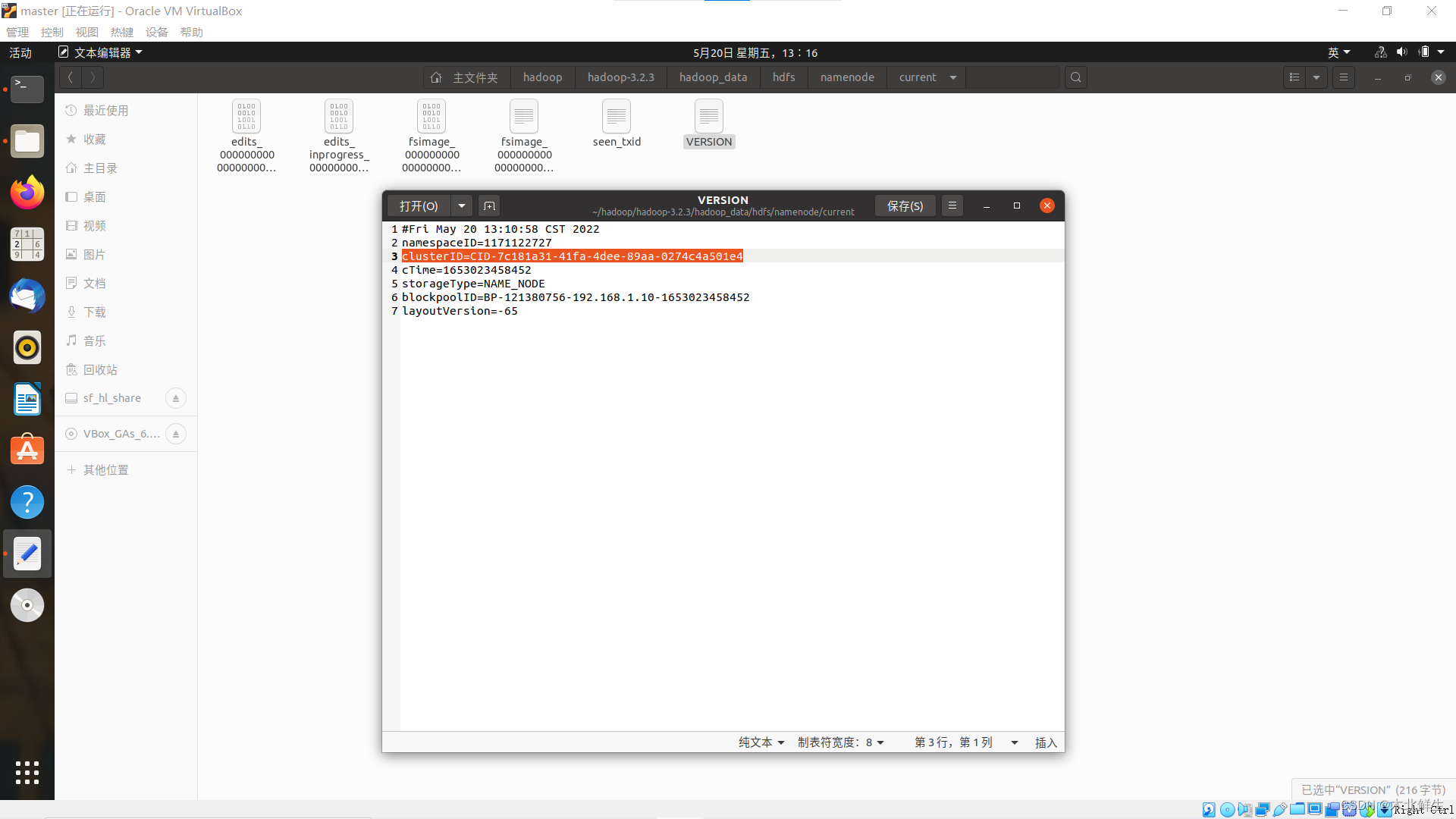
格式化namenode文件前后namenode文件中clusterID发生变化,所以与clusterID有关,与layoutVersion这一项无关。
解决方法一:
格式化namenode
将master服务器的namenode路径下的临时文件/current/VERSION的clusterID与slave服务器的datenode路径下临时文件/current/VERSION的clusterID改为一致
启动hadoop
解决方法二:
删除dataNode_1_dir和logs文件夹,删除节点存储目录的current文件夹
格式化namenode
启动hadoop
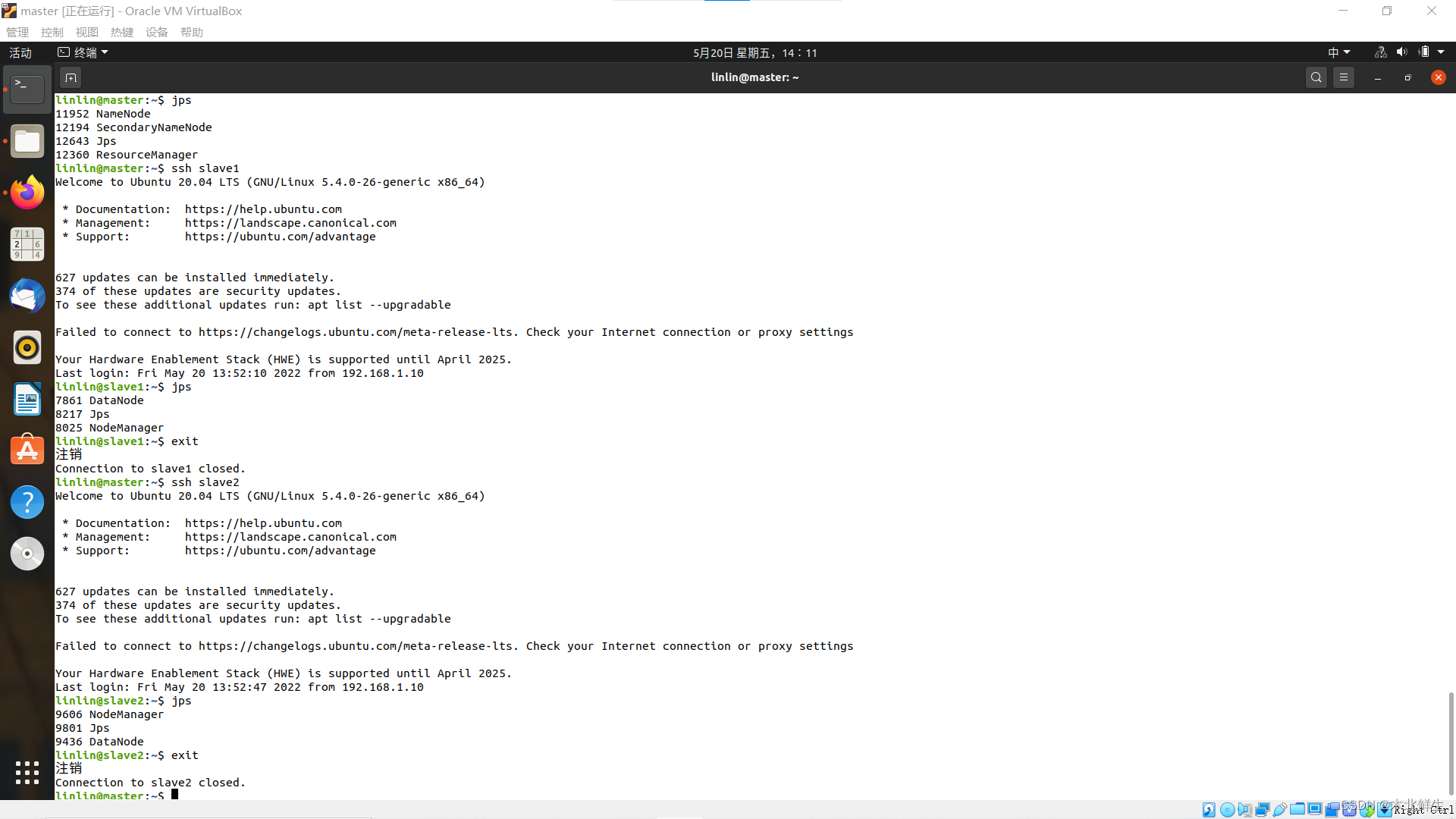
正常的hadoop进程
参考:
启动hadoop发现slave中jps没有datanode进程
服务器处于非启动状态,不能ssh连接;
服务器处于启动状态,从节点之间也可以ssh连接。
从节点启动hadoop进程,根据配置会缺少进程。




我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www