在 Pandas DataFrame 中插入 NaN 单元非常容易:
In [98]: df
Out[98]:
neg neu pos avg
250 0.508475 0.527027 0.641292 0.558931
500 NaN NaN NaN NaN
1000 0.650000 0.571429 0.653983 0.625137
2000 NaN NaN NaN NaN
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN
[12 rows x 4 columns]
In [99]: df.interpolate(method='nearest', axis=0)
Out[99]:
neg neu pos avg
250 0.508475 0.527027 0.641292 0.558931
500 0.508475 0.527027 0.641292 0.558931
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN
[12 rows x 4 columns]
我还希望它使用给定的方法推断插值范围之外的 NaN 值。我怎样才能最好地做到这一点?
最佳答案
DataFrameDataFrame 可以外推,但是,pandas 中没有简单的方法调用,需要另一个库(例如 scipy.optimize)。
一般来说,外推需要确定assumptions about the data被外推。一种方法是通过 curve fitting一些通用的参数化数据方程,以找到最能描述现有数据的参数值,然后用于计算超出该数据范围的值。这种方法的困难和局限性问题是,选择参数化方程时必须对趋势进行一些假设。这可以通过使用不同的方程式进行反复试验来得出所需的结果,或者有时可以从数据源中推断出来。问题中提供的数据确实不够大,无法获得拟合良好的曲线;然而,这足以说明。
以下是使用 3rd 阶多项式外推 DataFrame 的示例
f(x) = a x3 + b x2 + c x + d (Eq. 1)
此通用函数 (func()) 曲线拟合到每一列以获得唯一的列特定参数(即 a、b、 c,d)。然后,这些参数化方程用于为所有具有 NaN 的索引推断每列中的数据。
import pandas as pd
from cStringIO import StringIO
from scipy.optimize import curve_fit
df = pd.read_table(StringIO('''
neg neu pos avg
0 NaN NaN NaN NaN
250 0.508475 0.527027 0.641292 0.558931
500 NaN NaN NaN NaN
1000 0.650000 0.571429 0.653983 0.625137
2000 NaN NaN NaN NaN
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN'''), sep='\s+')
# Do the original interpolation
df.interpolate(method='nearest', xis=0, inplace=True)
# Display result
print ('Interpolated data:')
print (df)
print ()
# Function to curve fit to the data
def func(x, a, b, c, d):
return a * (x ** 3) + b * (x ** 2) + c * x + d
# Initial parameter guess, just to kick off the optimization
guess = (0.5, 0.5, 0.5, 0.5)
# Create copy of data to remove NaNs for curve fitting
fit_df = df.dropna()
# Place to store function parameters for each column
col_params = {}
# Curve fit each column
for col in fit_df.columns:
# Get x & y
x = fit_df.index.astype(float).values
y = fit_df[col].values
# Curve fit column and get curve parameters
params = curve_fit(func, x, y, guess)
# Store optimized parameters
col_params[col] = params[0]
# Extrapolate each column
for col in df.columns:
# Get the index values for NaNs in the column
x = df[pd.isnull(df[col])].index.astype(float).values
# Extrapolate those points with the fitted function
df[col][x] = func(x, *col_params[col])
# Display result
print ('Extrapolated data:')
print (df)
print ()
print ('Data was extrapolated with these column functions:')
for col in col_params:
print ('f_{}(x) = {:0.3e} x^3 + {:0.3e} x^2 + {:0.4f} x + {:0.4f}'.format(col, *col_params[col]))
Interpolated data:
neg neu pos avg
0 NaN NaN NaN NaN
250 0.508475 0.527027 0.641292 0.558931
500 0.508475 0.527027 0.641292 0.558931
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN
Extrapolated data:
neg neu pos avg
0 0.411206 0.486983 0.631233 0.509807
250 0.508475 0.527027 0.641292 0.558931
500 0.508475 0.527027 0.641292 0.558931
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 0.621036 0.969232 0.708464 0.766245
6000 1.197762 2.799529 0.991552 1.662954
8000 3.281869 7.191776 1.702860 4.058855
10000 7.767992 15.272849 3.041316 8.694096
20000 97.540944 150.451269 26.103320 91.365599
30000 381.559069 546.881749 94.683310 341.042883
50000 1979.646859 2686.936912 467.861511 1711.489069
Data was extrapolated with these column functions:
f_neg(x) = 1.864e-11 x^3 + -1.471e-07 x^2 + 0.0003 x + 0.4112
f_neu(x) = 2.348e-11 x^3 + -1.023e-07 x^2 + 0.0002 x + 0.4870
f_avg(x) = 1.542e-11 x^3 + -9.016e-08 x^2 + 0.0002 x + 0.5098
f_pos(x) = 4.144e-12 x^3 + -2.107e-08 x^2 + 0.0000 x + 0.6312
avg 列 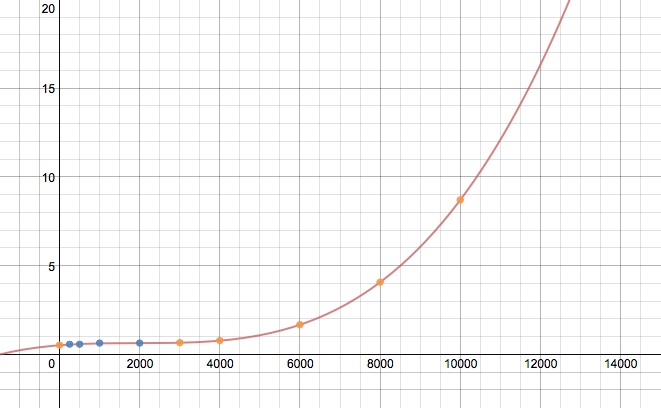
如果没有更大的数据集或不知道数据的来源,这个结果可能是完全错误的,但应该举例说明推断 DataFrame 的过程。 func() 中假定的等式可能需要播放 以获得正确的外推。此外,也没有尝试使代码高效。
更新:
如果您的索引是非数字的,例如 DatetimeIndex,see this answer了解如何推断它们。
关于python - 推断 Pandas DataFrame 中的值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/22491628/
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只