数据会持久化到磁盘,查询数据是就会有I/O操作,相对于缓存操作,I/O操作的时间成本相当高昂。
I/O操作的基本单位是一个磁盘页面,比如16KB的页面大小。当数据量比较大时,单表数据就会分布在多个磁盘页面。
如果没有索引,就必须按顺序加载磁盘页面到缓存进行查找,判断数据是否存在。随着数据量的增长,磁盘I/O操作的次数也会越来越多。
因此,有必要通过一些辅助的数据结构来提交检索的速度。
从上面可以看出,想要快速读取到数据,可从以下几个方面着手
1. 如何尽量减少磁盘IO操作
2. 如何快速定位到数据所在的磁盘页面
3. 如何快速定位数据在磁盘页面内的位置
索引是存储引擎用于快速查找记录的一种数据结构。
举个类似的例子,当我们要阅读《高性能MySQL》的第五章时,一般会先查找目录,找到第五章对应的页码,然后翻到对应页码即可。
目录一般不会超过10页,整本书有将近700页。
如果没有目录,那么我们只能顺序或者使用二分的方法来查找第五章,需要翻页的次数就会更多。
索引的作用与书籍的目录相似,用于辅助快速查找目标数据。
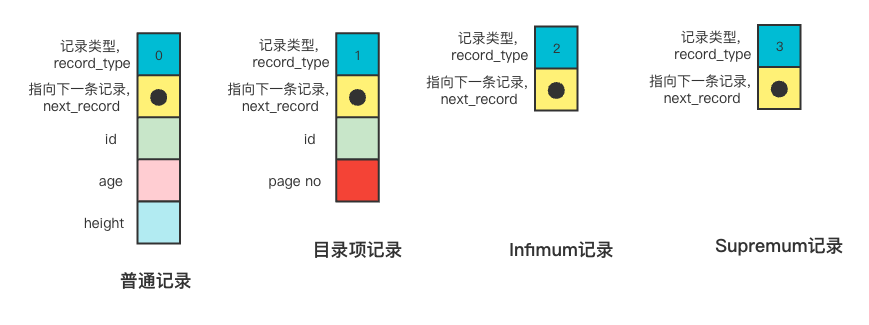
InnoDB支持四种记录格式,分别是REDUNDANT、COMPACT、DYNAMIC和COMPRESSED,MySQL5.7默认是DYNAMIC格式。
下图是DYNAMIC行格式的示意图

记录头信息的格式示意图如下
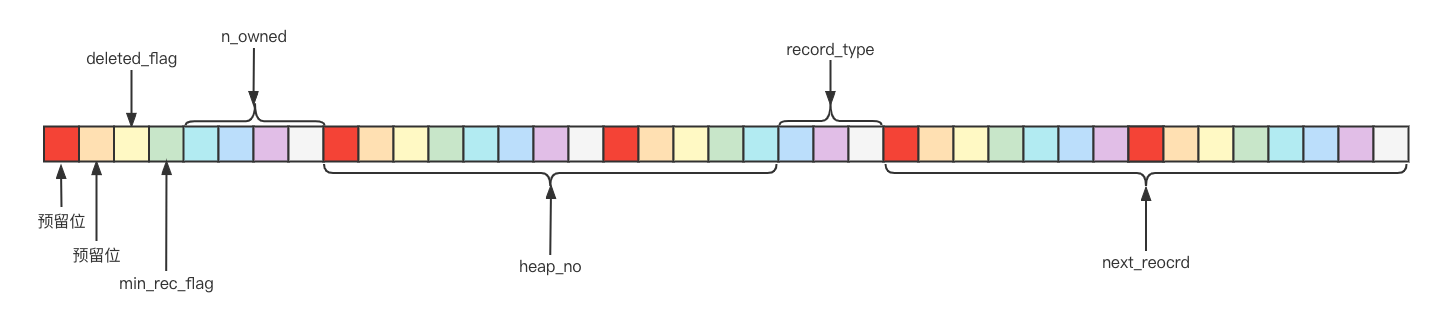
部分字段含义
deleted_flag:顾名思义,该记录是否被删除的标志
min_rec_flag:B+树每层非叶子结点中最小的记录项的标志
n_owned: 页面中分组的
heap_on: 表示当前记录在页面堆中的相对记录
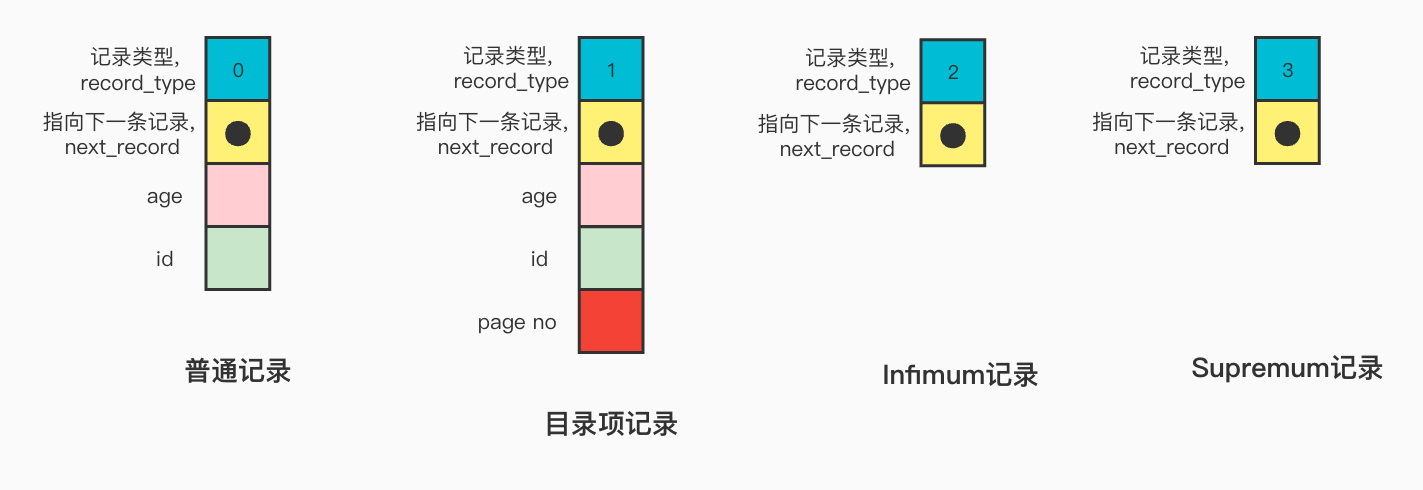
record_type: 表示当前记录的类型,0表示普通记录,1表示B+树非叶子结点的目录项记录,2表示Infimum记录,3表示Supremum记录。
next_record: 指向下一条记录,表示下一条记录的相对位置
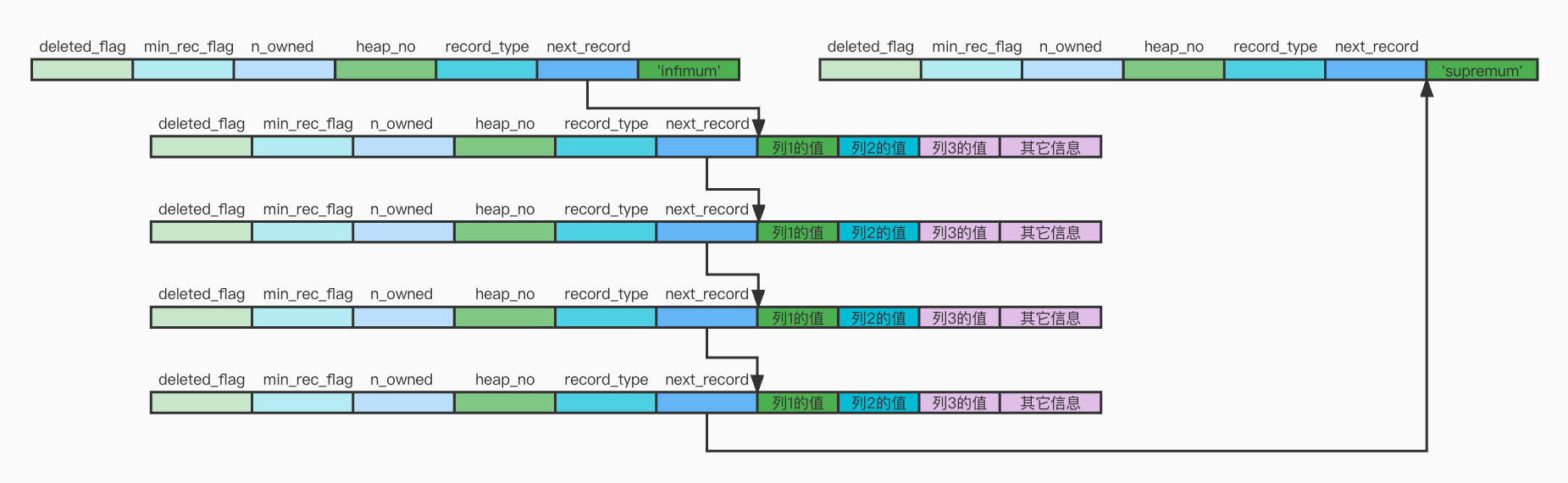
所有页面都有两条虚拟记录,即Infimum和Supremum。
Infimum代表页面中的最小的记录,而Supremum则代表页面中最大的记录。
页内的记录串联成一个单向链表。
如果表有主键,会根据主键排序;
没主键有唯一非空索引,会根据该索引排序;
两者都没有,InnoDB会自动生成一个row_id列并根据该列进行排序。
页是InnoDB管理存储空间的基本单位,一个页的大小一般是16K。
数据页面的结构如下图
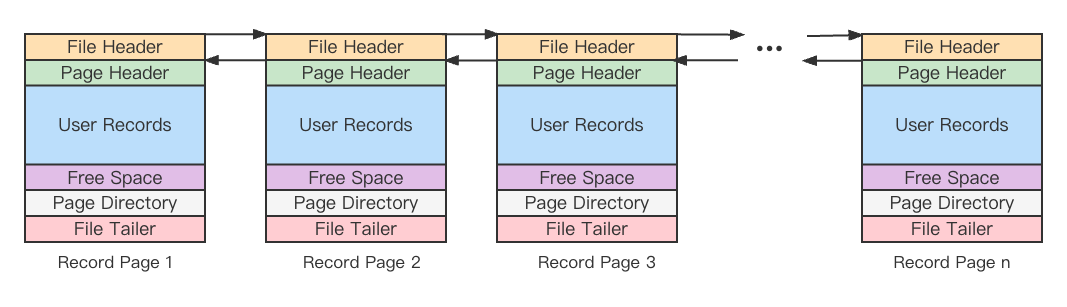
File Header:页面通用信息,如当前页号、上一页/下一页页号
Page Header:页面的各种状态信息,如分组数量,记录数
User Records:记录的有序链表
Free Space:页面中尚未使用的空间
Page Directory:对User Records数据进行分组,减少遍历链表的次数,加速查找
File Tailer:校验页面数据是否完整
页面内的数据是有序的单向链表。
假设单行数据128B,而单个磁盘页面大小可以是16KB,因此一个磁盘页面最多可以存放128条数据。这样挨个查找太慢。
可以利用有序链表的特性,对有序数据进行分组,记录每组的最大值,形成一个有序分组列表。先二分查找有序分组列表,再查找分组内的数据。
这里就会涉及的行记录的n_owned和页面的Page Directory了,InnoDB分组规则如下
1. Infimum记录所在的分组只能有一条记录
2. Supremum记录所在的分组拥有的记录数量为1~8条
3. 其它分组拥有的记录数量为4~8条
4. 分组指向组内ID最大的行。
下图是简化的行记录和Page Directory。
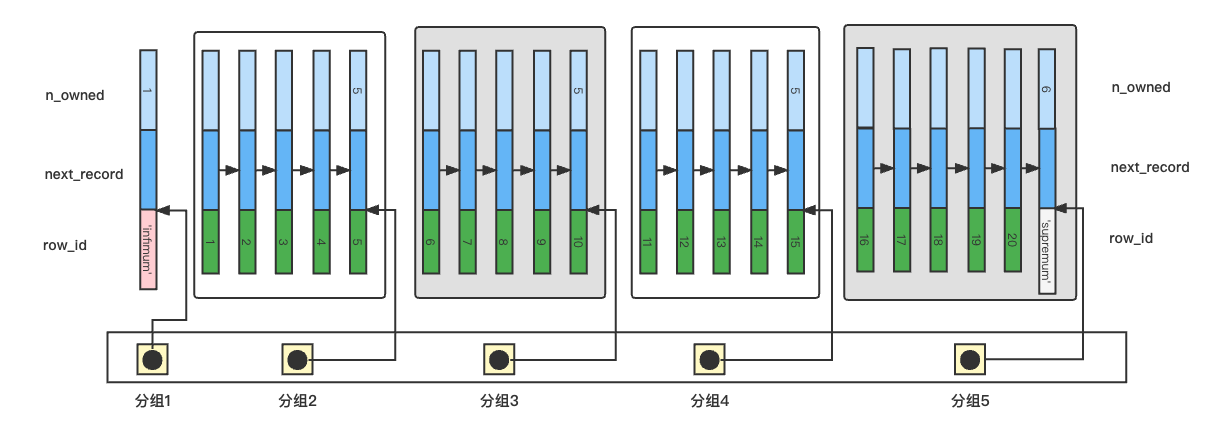
在上图中查找ID=17的记录
1. 利用分组进行二分查找,
(1 + 5) / 2 = 3,分组3的最大ID为10,因此继续在右半区间查找
(3 + 5) / 2 = 4,分组最大的ID为15,17位于右半区间,又应为5 - 4 = 1,因此,17位于分组5
2. 组内顺序查找
在分组内遍历单向链表,查找到ID=17的记录
在B树详解,这边随笔中介绍了B树的查找、插入、删除操作,可以深入理解B数的数据结构
CREATE TABLE `t_student` ( `id` int NOT NULL AUTO_INCREMENT COMMENT '主键ID' , `age` int NOT NULL DEFAULT '0' COMMENT '年龄' , `height` int NOT NULL DEFAULT '0' COMMENT '身高' , PRIMARY KEY (`id`), KEY `age` (`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE =utf8mb4_0900_ai_ci ROW_FORMAT=COMPACT;
为了方便画图表示,下面是简化的聚簇索引各种记录格式
聚簇索引结构举例
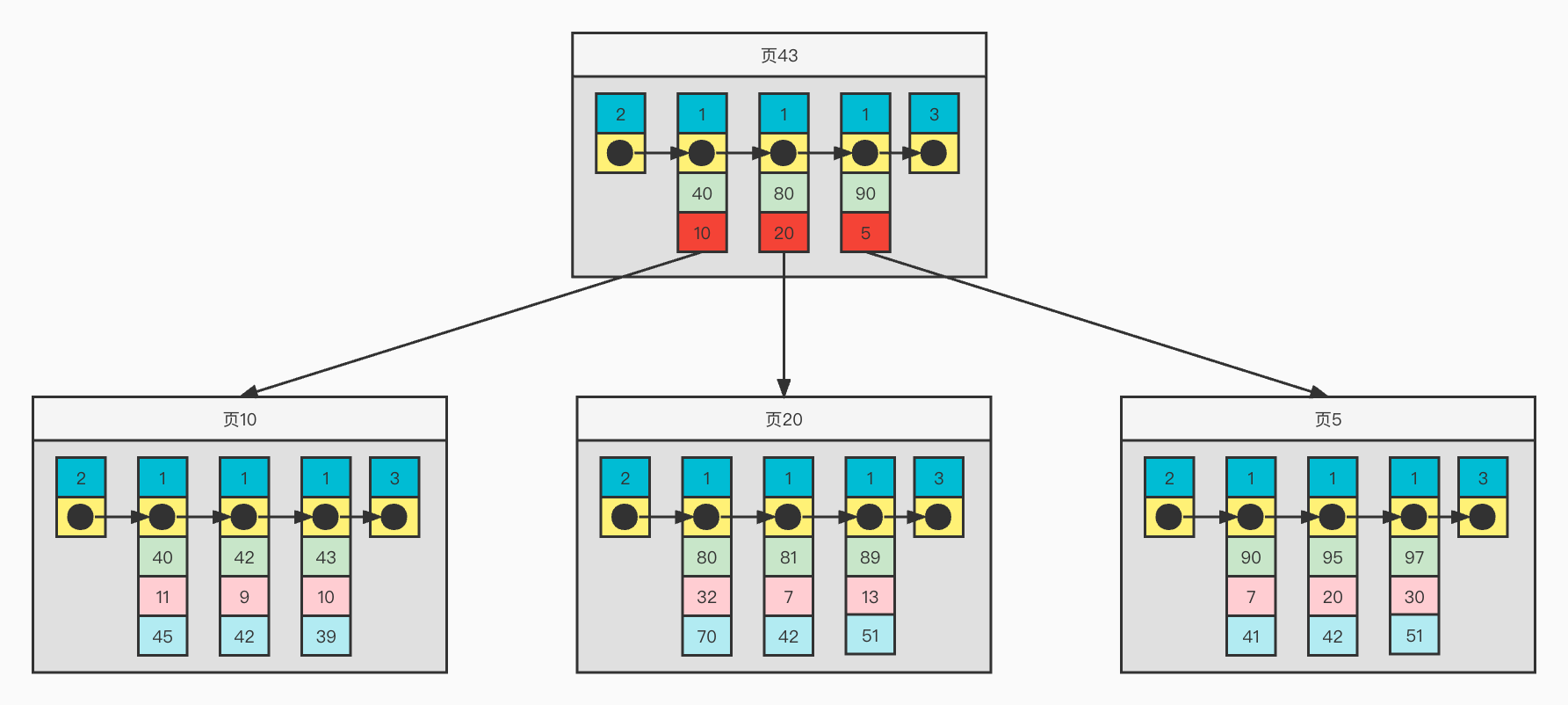
从上图可以看出,
1)页面内记录按照主键增长的顺序构成一个单项链表
2)对于普通记录,则是一个按照主键有序的双向链表
为了方便画图表示,下面是简化的二级索引各种记录格式
二级索引结构举例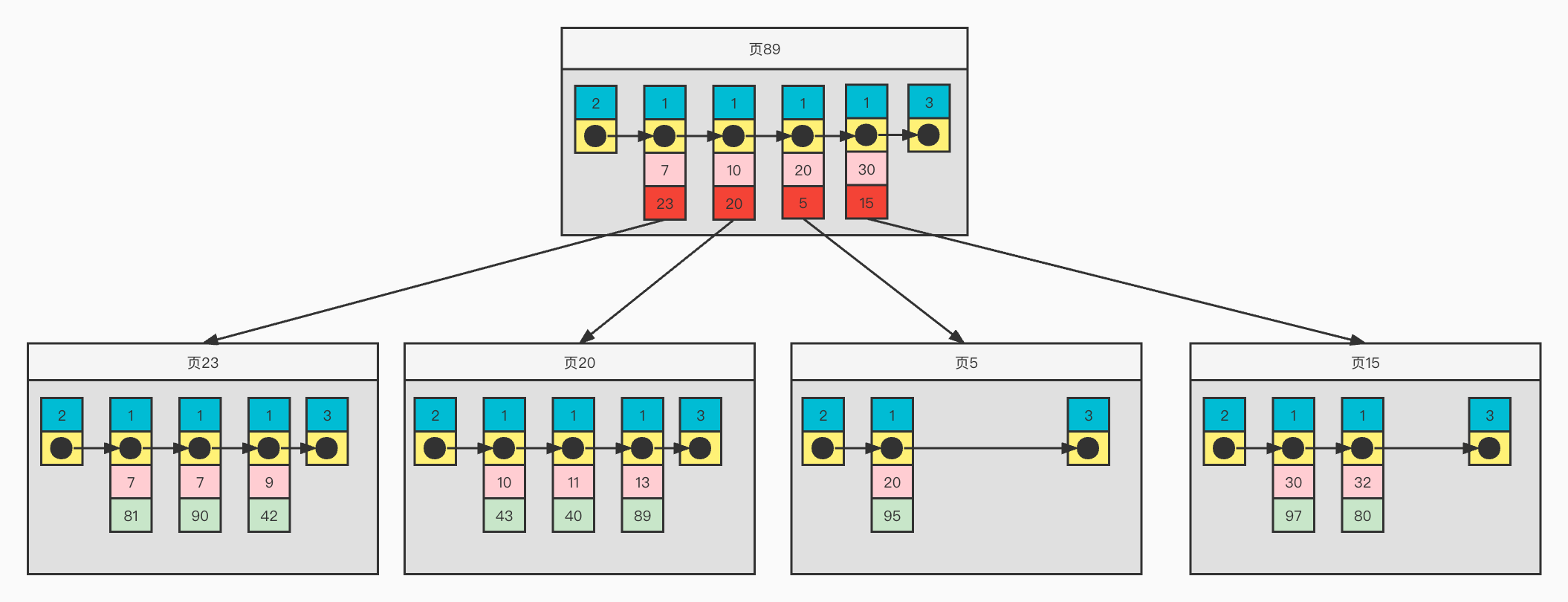
1)页面内记录按照二级索引age增长的顺序构成一个单项链表
2)对于普通记录,则是一个按照age有序的双向链表
3)普通记录并没没有包含完整的信息,而是<age,主键>的组合,需要取其它信息如height还需要进行回表
回表: 数据库根据索引(非主键)找到了指定的记录所在行后,还需要根据索引上保存的主键 ID 再次到数据块里获取数据。
1. 尽量使用占用空间少的索引
索引字段占用空间小,意味着单个页面可以存放更多的目录项目记录,使得B+数更加扁平,从而减少IO次数
2. 选择频繁作为查询条件的字段作为索引
频繁作为查询条件的字段作为索引,减少查询的时间,避免全表查询。
3. 选择区分度高的字段作为索引
例如性别只有男1女2两种情况,如果建立索引,目录项只有两条记录,意义不大。还增加了维护索引的成本。
4. 最左匹配原则
多个字段构成联合索引时,这几个字段的顺序十分重要。
假设有联合索引<a,b,c>
目录项记录是先按a排序,如果a相等再按b排序,如果a和b都相等,再按c排序。
如果查询条件只有(b,c),则改索引并不会生效。如果只有(a),那索引只是部分生效。
《MySQL是怎么运行的》
我发现自己需要这个。假设cart是一个包含用户列表的模型。defindex_of_itemcart.users.each_with_indexdo|u,i|ifu==current_userreturniendend获取此类关联索引的更简单方法是什么? 最佳答案 indexArray上的方法与您的index_of_item方法相同,例如cart.users.index(current_user)返回数组中第一个对象的索引==给obj。如果未找到匹配项,则返回nil。 关于ruby-on-
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
假设我有一个可枚举对象enum,现在我想获取第三个项目。我知道一种通用方法是转换成数组,然后使用索引访问,如:enum.to_a[2]但这种方式会创建一个临时数组,效率可能很低。现在我使用:enum.each_with_index{|v,i|breakvifi==2}但这非常丑陋和多余。执行此操作最有效的方法是什么? 最佳答案 你可以使用take剥离前三个元素,然后剥离last从take给你的数组中获取第三个元素:third=enum.take(3).last如果您根本不想生成任何数组,那么也许:#Ifenumisn'tanEnum
在我的场景中,Logstash收到的系统日志行的“时间戳”是UTC,我们在Elasticsearch输出中使用事件“时间戳”:output{elasticsearch{embedded=>falsehost=>localhostport=>9200protocol=>httpcluster=>'elasticsearch'index=>"syslog-%{+YYYY.MM.dd}"}}我的问题是,在UTC午夜,Logstash在外时区(GMT-4=>America/Montreal)结束前将日志发送到不同的索引,并且索引在20小时(晚上8点)之后没有日志,因为“时间戳”是UTC。我们已
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
我一直在努力学习如何处理由数组组成的数组。假设我有这个数组:my_array=[['ORANGE',1],['APPLE',2],['PEACH',3]我将如何找到包含'apple'的my_array索引并删除该索引(删除子数组['APPLE',2]因为'apple'包含在该索引的数组中)?谢谢-我非常感谢这里的帮助。 最佳答案 您可以使用Array.select过滤掉项目:>>a=[['ORANGE',1],['APPLE',2],['PEACH',3]]=>[["ORANGE",1],["APPLE",2],["PEACH",3
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但
假设我有这个:[{:id=>34,:votes_count=>3},{:id=>2,:votes_count=>0},]如何根据id获取索引?我想要做的是在搜索id:34时返回0,在搜索id:21/。什么是最有效的方法? 最佳答案 你可以将一个block传递给#index:array.index{|h|h[:id]==34}#=>0 关于ruby-根据子哈希值获取数组索引,我们在StackOverflow上找到一个类似的问题: https://stackove
我正在用ruby遍历一个数组。有没有一种简单的方法可以在不返回for循环的情况下获取迭代次数或数组索引? 最佳答案 啊,知道了。each_with_index哇!编辑:糟糕! 关于ruby-如何使用每个迭代器获取数组索引或迭代次数?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/706115/