
先看下本篇主要内容:
本篇主要介绍源代码映射,源代码映射(Source maps)是以.map结尾的文件,例如example.min.js.map和styles.css.map。大多数构建工具都可以生成源代码映射文件,例如Vite、webpack、Rollup、Parcel、esbuild等,一些工具默认包含源代码映射,而其他工具则需要额外的配置才能生成它们。
使用源代码映射可以方便地在开发过程中进行调试,因为它们提供了一种将压缩、混淆和优化的代码还原为原始源代码的方法。这对于诊断和修复错误非常有帮助,特别是在生产环境中。源代码映射还可以帮助你确定哪些代码行负责执行特定的功能,以及从哪里调用了特定的函数。
尽管源代码映射非常有用,但是它们会增加文件大小并增加服务器的负载。因此,在生产环境中通常会禁用它们,而在开发过程中启用它们以便进行调试。如果你使用的构建工具不支持源代码映射,则有可能需要手动编写它们。
下面是正文~~~~
今天,我们要谈论源代码映射,这是现代 Web 开发中非常重要的工具,可以显著地简化调试过程。在本文中,我们将探讨源代码映射的基础知识,它们是如何生成的,以及它们如何提高调试体验。
回到过去的美好时光,我们使用纯HTML、CSS和JavaScript构建Web应用程序,并将相同的文件部署到Web上。
然而,随着我们现在构建更复杂的Web应用程序,开发工作流可能涉及使用各种工具。例如:
这些工具需要构建过程将我们的代码转换为标准的 HTML、JavaScript 和 CSS,以便浏览器能够理解。此外,为了优化性能,通常会压缩(例如使用 Terser 来缩小和混淆 JavaScript)和合并这些文件,减小它们的大小并使它们更适合于Web。
例如,使用构建工具,我们可以将以下TypeScript文件转换并压缩为一行JavaScript代码。
/* A TypeScript demo: example.ts */
document.querySelector('button')?.addEventListener('click', () => {
const num: number = Math.floor(Math.random() * 101);
const greet: string = 'Hello';
(document.querySelector('p') as HTMLParagraphElement).innerText = `${greet}, you are no. ${num}!`;
console.log(num);
});一个压缩版本将是:
/* A compressed JavaScript version of the TypeScript demo: example.min.js */
document.querySelector("button")?.addEventListener("click",(()=>{const e=Math.floor(101*Math.random());document.querySelector("p").innerText=`Hello, you are no. ${e}!`,console.log(e)}));然而,这种优化可能会使调试变得更具挑战性。将所有内容压缩到单行中并缩短变量名称的压缩代码可能会使问题的源头难以确定。这就是源映射的作用——它们将编译后的代码映射回原始代码。
源映射是以 .map 结尾的文件(例如, example.min.js.map 和 styles.css.map )。它们可以由大多数构建工具生成,例如 Vite、webpack、Rollup、Parcel、esbuild 等等。
一些工具默认包含源代码映射,而其他一些工具可能需要额外的配置才能生成它们。
/* Example configuration: vite.config.js */
/* https://vitejs.dev/config/ */
export default defineConfig({
build: {
sourcemap: true, // enable production source maps
},
css: {
devSourcemap: true // enable CSS source maps during development
}
})这些源映射文件包含有关编译代码如何映射到原始代码的基本信息,使开发人员能够轻松调试。这是一个源映射的示例。
{
"mappings": "AAAAA,SAASC,cAAc,WAAWC, ...",
"sources": ["src/script.ts"],
"sourcesContent": ["document.querySelector('button')..."],
"names": ["document","querySelector", ...],
"version": 3,
"file": "example.min.js.map"
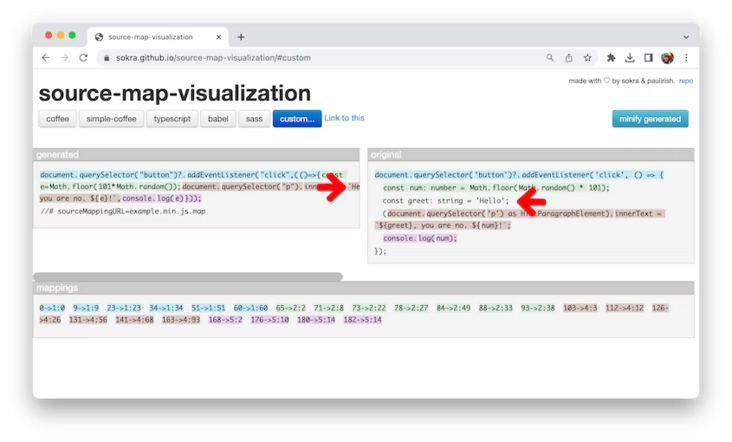
}源映射的最关键方面是 mappings 字段。它使用 VLQ 基于 64 编码的字符串将编译文件中的行和位置映射到相应的原始文件。可以使用源映射可视化工具(如 source-map-visualization 和 Source Map Visualization)来可视化此映射。
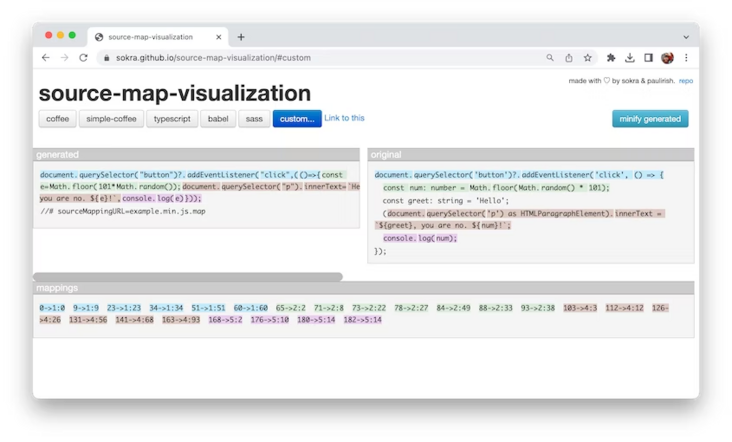
左侧生成的列显示压缩内容,右侧原始列显示原始来源。可视化工具会为原始列中的每一行和生成列中对应的代码进行着色编码。
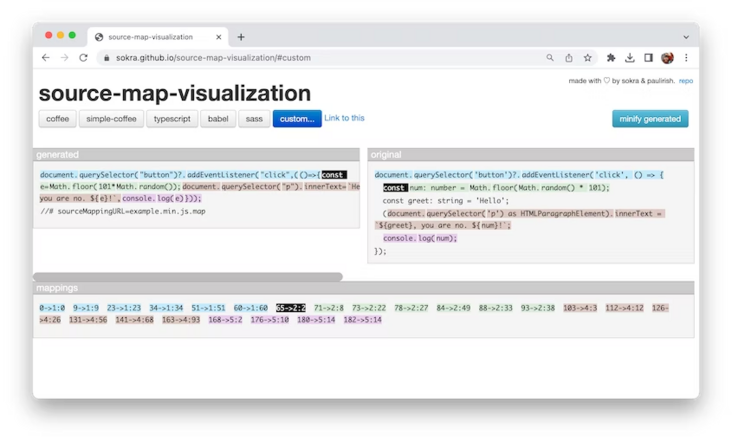
映射部分显示了代码的解码映射。例如,条目 65-> 2:2 的意思是:
浏览器开发者工具应用这些源映射,帮助我们更快地定位调试问题,直接在浏览器中进行。
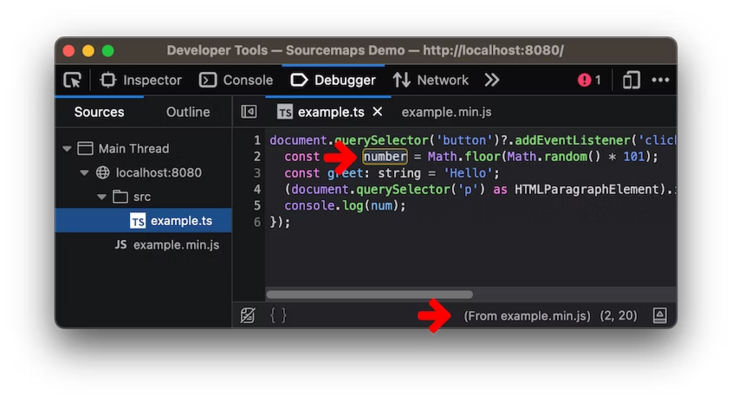
该图显示了浏览器开发者工具如何应用源映射,并显示文件之间的映射关系。
源映射支持扩展。扩展是以 x_ 命名约定开头的自定义字段。一个例子是由 Chrome DevTools 提出的 x_google_ignoreList 扩展字段。请参阅 x_google_ignoreList 以了解这些扩展如何帮助您专注于我们的代码。
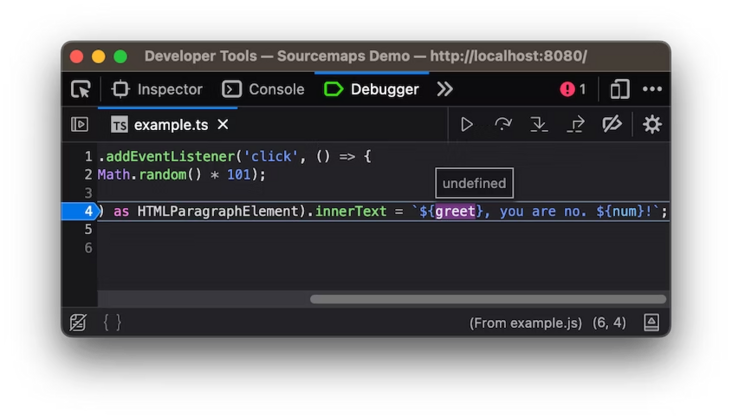
在我们的示例中,变量 greet 在构建过程中被优化掉了。该值直接嵌入到最终的字符串输出中。
在这种情况下,当我们调试代码时,开发人员工具可能无法推断和显示实际值。这不仅是浏览器开发人员工具的挑战,也使代码监视和分析更加困难。
当然,这是一个可以解决的问题。其中一种方法是像其他编程语言一样,在源映射中包含范围信息,以便进行调试。
然而,这需要整个生态系统共同努力改进源映射规范和实现。目前正在积极讨论如何通过源映射来提高调试性能。
我们期待着改进源代码映射,使调试变得更加简单!
本文转载自微信公众号「大迁世界」,可以通过以下二维码关注。转载本文请联系大迁世界公众号。

类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象