近些日子在很多线上比赛中都遇到了smc文件加密技术,比较出名的有Hgame杭电的比赛,于是我准备实现一下这项技术,但是在网上看了很多文章,发现没有讲的特别详细的,或者是无法根据他们的方法进行实现这项技术,因此本篇文章就是分享我在学习以及尝试smc文件加密技术时所遇到的麻烦以及心得。
该篇文章将会从我学习这项技术的视角,讲述我屡次失败的经历,一点点深入。
SMC(Software-Based Memory Encryption)是一种局部代码加密技术,它可以将一个可执行文件的指定区段进行加密,使得黑客无法直接分析区段内的代码,从而增加恶意代码分析难度和降低恶意攻击成功的可能性。
SMC的基本原理是在编译可执行文件时,将需要加密的代码区段(例如函数、代码块等)单独编译成一个section(段),并将其标记为可读、可写、不可执行(readable, writable, non-executable),然后通过某种方式在程序运行时将这个section解密为可执行代码,并将其标记为可读、可执行、不可写(readable, executable, non-writable)。这样,攻击者就无法在内存中找到加密的代码,从而无法直接执行或修改加密的代码。
SMC技术可以通过多种方式实现,例如修改PE文件的Section Header、使用API Hook实现代码加密和解密、使用VMProtect等第三方加密工具等。加密时一般采用异或等简单的加密算法,解密时通过相同的算法对密文进行解密。SMC技术虽然可以提高恶意代码的抗分析能力,但也会增加代码运行的开销和降低代码运行速度。
具体来说,SMC实现的主要步骤包括:
读取PE文件并找到需要加密的代码段。
将代码段的内容进行异或加密,并更新到内存中的代码段。
重定向代码段的内存地址,使得加密后的代码能够正确执行。
执行加密后的代码段。
SMC的优点在于:
SMC采用的是软件实现方式,因此不需要硬件支持,可以在任何平台上运行。
SMC对于程序的执行速度影响较小,因为代码解密和执行过程都是在内存中进行的。
SMC可以对代码进行多次加密,增加破解的难度。
SMC可以根据需要对不同的代码段进行不同的加密方式,从而提高安全性。
然而,SMC的缺点也显而易见,主要包括:
SMC的实现比较复杂,需要涉及到PE文件结构、内存管理等方面的知识。
SMC需要在运行时动态地解密代码,因此会对程序的性能产生一定的影响。
SMC只能对静态的代码进行加密,对于动态生成的代码无法进行保护。
SMC对于一些高级的破解技术(如内存分析)可能无法完全保护程序。
综上所述,SMC是一种局部代码加密技术,可以提高程序的安全性,但也存在一些局限性。在实际应用中,需要根据具体的情况选择最合适的保护方案,综合考虑安全性、性能和可维护性等因素。
[流程图]
+---------------------+
| 读取PE文件 |
| 找到代码段 |
+---------------------+
|
|
v
+---------------------------------+
| 对代码段进行异或加密 |
| 并更新到内存中的代码段 |
+---------------------------------+
|
|
v
+---------------------------------+
| 重定向代码段的内存地址, |
| 使得加密后的代码能够正确执行 |
+---------------------------------+
|
|
v
+---------------------+
| 执行加密后的代码段 |
+---------------------+[小结一下]
前面说的非常的高端,其实通俗的讲就是程序可以自己对自己底层的字节码进行操作,就是所谓的自解密技术。其在ctf比赛中常见的就是可以将一段关键代码进行某种加密,然后程序运行的时候就直接解密回来,这样就可以干扰解题者的静态分析,在免杀方面也是非常好用的技术。可以利用该技术隐藏关键代码。
说实话,实现这项技术我是踩了非常多的坑的,接下来将会一一分享。
用伪代码解释一下该技术:
proc main:
............
IF .运行条件满足
CALL DecryptProc (Address of MyProc)//对某个函数代码解密
........
CALL MyProc //调用这个函数
........
CALL EncryptProc (Address of MyProc)//再对代码进行加密,防止程序被Dump
......
end mainOK,非常明确,首先我是使用了Dev-C++ 6.7.5编译器,使用的MinGW GCC 9.2.0 32bit Debug的编译规则。
【----帮助网安学习,以下所有学习资料免费领!加vx:yj009991,备注 “博客园” 获取!】
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC漏洞分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
我们回忆一下该项技术,加入我们需要加密的是函数fun,那么我们首先需要使用指针找到fun的地址,一开始我使用的是int类型的指针,代码如下:
void fun()
{
char flag[]="flag{this_is_test}";
printf("%s",flag);
}
int main ()
{
int *a=(int *)fun;
for(int i = 0 ; i < 10 ; i++ )
{
printf("%x ",*(a++));
}
}输出结果为:
83e58955 45c738ec 616c66e5 e945c767 6968747b 73ed45c7 c773695f 745ff145 c7667365 7d74f545然后我们把编译出来的文件放到ida里面观察。
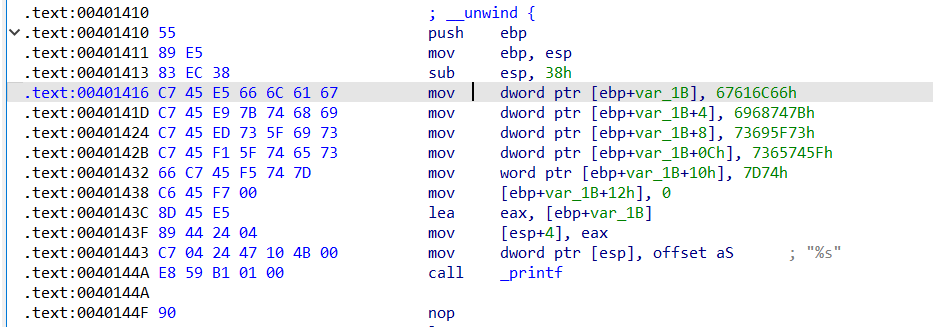
可以发现输出的内容确实是fun的字节码,但是由于int在c语言中占用了四个字节,因此是由四个16进制的机器码根据小端序排列输出的,那么为了解决这种连续字节码的问题我们需要找到一个只占用一个字节的指针,首先我想到了char类型,于是我马上更改代码,使用char类型的指针,得到了如下的输出结果。
55 ffffff89 ffffffe5 ffffff83 ffffffec 38 ffffffc7 45 ffffffe5 66显然,这里是忽略的char的符号位的问题,有符号char型如果最高位是1,意思是超过了0x7f,当%X格式化输出的时候,则会将这个类型的值拓展到int型的32位,所以才会出现0xff,被扩展为ffffffff。
一筹莫展之际,我想起了在c语言中还有一种数据类型是只占一个字节的,那就是byte类型的数据,将代码改成byte类型之后可以发现输出变得正常了。
输出为:
55 89 e5 83 ec 38 c7 45 e5 66这个就是正确的字节码的形式了。
那么我们需要定位到程序段进行加密了,由于本次只是实验,我们采取简单的异或加密方式,异或加密的特点就是加密函数也可以是解密函数,极大的方便了我们此次实验。我们可以先在ida中看到我们需要加密的程序段的位置。
在ida中我们可以发现我们需要解密的fun函数占用的地址段是0x00401410-00401451,那我们只需要将这一段内存中的机器码进行异或加密理论上就可以实现smc文件加密技术了。
实现代码如下:
void fun()
{
char flag[]="flag{this_is_test}";
printf("%s",flag);
}
int main ()
{
byte *a=(byte *)fun;
byte *b = a ;
for( ; a!=(b+0x401451-0x401410+1) ; a++ )
{
*a=*a^3;
}
fun();
}这段代码直接运行的话会出现内存错误,这是因为代码运行的时候对原本未被加密的fun函数进行了异或处理,导致本来应该是解密的操作变成了加密操作,然后机器无法识别该段内存就出现了内存错误,因此在运行代码前我们需要将文件中的fun函数部分进行加密操作。我这里使用idapython对字节码进行操作,然后将文件dump出来,完成对文件的加密。
idapython脚本为:
for i in range(0x401410,0x401451):
patch_byte(i,get_wide_byte(i)^3)运行后把代码dump下来,再运行。
发现出现内存错误告警,猜测可能是dev-c++的编译器开启了随机基地址和数据保护,因此选择更换编译器,并关闭随机基地址选项。这里使用的是visual studio 2019,32位的debug模式进行编译。
但是遗憾的是仍然无法运行,思考了一会儿之后发现可能是该段内存没有被设置成可读、可执行、可写入,导致程序无法识别这段内存了,因此我们改变方法使用程序段的概念,通过对整个程序段进行加密解密,来实现smc技术。
使用的代码是:
#include<Windows.h>
#include<string>
#include<string.h>
using namespace std;
#include <iostream>
#pragma code_seg(".hello")
void Fun1()
{
char flag[]="flag{this_is_test}";
printf("%s",flag);
}
#pragma code_seg()
#pragma comment(linker, "/SECTION:.hello,ERW")
void Fun1end()
{
}
void xxor(char* soure, int dLen) //异或
{
for (int i = 0; i < dLen;i++)
{
soure[i] = soure[i] ^3;
}
}
void SMC(char* pBuf) //SMC解密/加密函数
{
const char* szSecName = ".hello";
short nSec;
PIMAGE_DOS_HEADER pDosHeader;
PIMAGE_NT_HEADERS pNtHeader;
PIMAGE_SECTION_HEADER pSec;
pDosHeader = (PIMAGE_DOS_HEADER)pBuf;
pNtHeader = (PIMAGE_NT_HEADERS)&pBuf[pDosHeader->e_lfanew];
nSec = pNtHeader->FileHeader.NumberOfSections;
pSec = (PIMAGE_SECTION_HEADER)&pBuf[sizeof(IMAGE_NT_HEADERS) + pDosHeader->e_lfanew];
for (int i = 0; i < nSec; i++)
{
if (strcmp((char*)&pSec->Name, szSecName) == 0)
{
int pack_size;
char* packStart;
pack_size = pSec->SizeOfRawData;
packStart = &pBuf[pSec->VirtualAddress];
xxor(packStart, pack_size);
return;
}
pSec++;
}
}
void UnPack() //解密/加密函数
{
char* hMod;
hMod = (char*)GetModuleHandle(0); //获得当前的exe模块地址
SMC(hMod);
}
int main()
{
//UnPack();
UnPack(); //
Fun1();
return 0;
}如此操作后,做一个简单的验证看看能不能成功,就是进行两次调用unpack函数来看看程序能否正常运行,发现程序成功的输出了flag那么使用程序段的方式是正确的!!
这段代码实现了一个简单的SMC自修改代码技术,主要包括以下几个部分:
使用 #pragma code_seg 指令将 Fun1() 函数代码段定义为一个名为 ".hello" 的新代码段,使其与其他代码段隔离开来,方便后面的加密和解密。
使用 #pragma comment(linker, "/SECTION:.hello,ERW") 指令将 ".hello" 代码段设置为可读、可执行、可写入的,以便后面的加密和解密操作。
定义 Fun1end() 函数作为 Fun1() 函数的结束点,以便后面的加密操作。
定义 xxor() 函数用于将指定的字符串进行异或加密/解密。
定义 SMC() 函数,该函数用于解密指定代码段的内容。具体操作是遍历 PE 文件的各个段,找到指定代码段并对其进行解密。
定义 UnPack() 函数,该函数用于对当前进程的代码段进行解密操作。具体操作是获取当前模块的句柄,读取模块的 PE 文件并对指定代码段进行解密。
在 main() 函数中调用 UnPack() 函数进行解密操作,然后调用 Fun1() 函数进行计算。
需要注意的是,这段代码只是一个简单的示例,实际应用中可能需要更加复杂的加密和解密方法,以及更多的安全措施来保护代码的安全性。同时,SMC自修改代码技术也存在一定的风险和挑战,需要仔细评估和规划,谨慎使用。
代码写好之后,仍然需要我们自己手动先加密程序,在别的文章中所使用的方法和工具我找了很久都没有找到,因此决定自己使用ida+idapython来实现对程序的加密,最后dump出程序,然后程序运行时会自己进行解密。
ida中的hello程序段
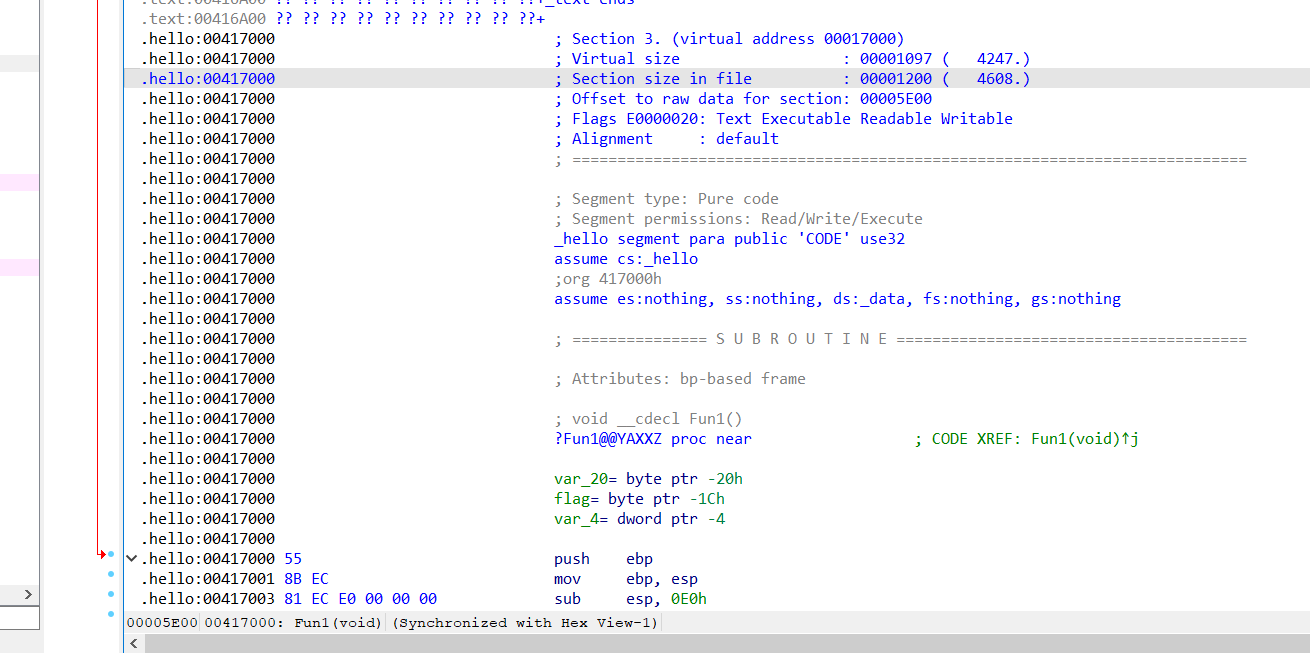
我们需要的是将所有hello程序段的内容进行加密。
idapython脚本:
for i in range(0x417000,0x4170A4):
patch_byte(i,get_wide_byte(i)^3)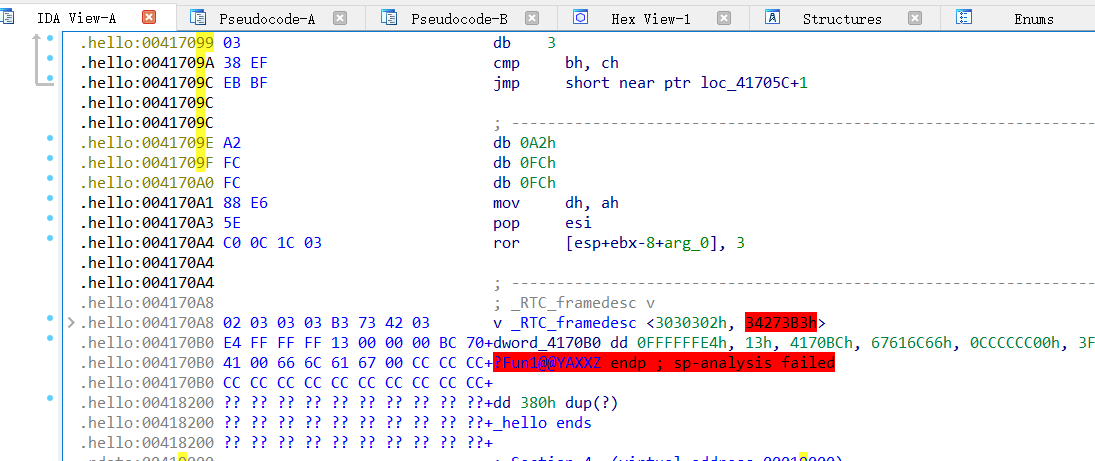
虽然dump出来的程序能输出我们程序中的值,但是仍然出现了堆栈不平衡的问题,因此在终端运行程序时仍然会爆出内存错误的告警,研究到此时我已经心态崩了,找了很多大牛的博客都没有详细提到怎么实现加密程序,那这样的话只能自己手撸了,这里使用python语言,代码为:
import pefile
def encrypt_section(pe_file, section_name, xor_key):
"""
加密PE文件中指定的区段
"""
# 找到对应的section
for section in pe_file.sections:
if section.Name.decode().strip('\x00') == section_name:
print(f"[*] Found {section_name} section at 0x{section.PointerToRawData:08x}")
data = section.get_data()
encrypted_data = bytes([data[i] ^ xor_key for i in range(len(data))])
pe_file.set_bytes_at_offset(section.PointerToRawData, encrypted_data)
print(f"[*] Encrypted {len(data)} bytes at 0x{section.PointerToRawData:08x}")
return
print(f"[!] {section_name} section not found!")
if __name__ == "__main__":
filename = "test1.exe"#加密文件的名字,需要在同一根目录下
section_name = ".hello"#加密的代码区段名字
xor_key = 0x03#异或的值
print(f"[*] Loading {filename}")
pe_file = pefile.PE(filename)
# 加密
print("[*] Encrypting section")
encrypt_section(pe_file, section_name, xor_key)
# 保存文件
new_filename = filename[:-4] + "_encrypted.exe"
print(f"[*] Saving as {new_filename}")
pe_file.write(new_filename)
pe_file.close()
这段代码实现了对PE文件中指定的代码区段进行异或加密的功能,具体解释如下:
导入pefile模块:该模块提供了解析PE文件格式的功能;
定义encrypt_section函数:该函数接收三个参数,分别是PE文件对象pe_file、待加密区段名称section_name和异或值xor_key。函数首先遍历PE文件中的所有区段,查找名字为section_name的区段;
对指定的代码区段进行加密:如果找到了名字为section_name的代码区段,该函数调用PE文件对象的set_bytes_at_offset方法,将指定区段中的每个字节和异或值异或,得到加密后的数据,并将加密后的数据写回指定区段。注意,set_bytes_at_offset方法需要传入一个字节串作为参数,因此需要将加密后的数据转换为字节串;
main函数:该函数首先指定待加密的PE文件名filename、待加密的区段名称section_name和异或值xor_key。然后,它创建一个PE文件对象pe_file,读入PE文件;接着调用encrypt_section函数,对指定区段进行加密;最后,将加密后的文件写入新的文件中,并关闭PE文件对象。
这段代码的执行过程如下:
调用main函数,读取PE文件test1.exe;
找到名字为.hello的区段,对其中的每个字节和异或值0x03进行异或,得到加密后的数据;
将加密后的数据写回.hello区段,并将加密后的文件保存为test1_encrypted.exe。
脚本完成后,满怀激动的运行它!
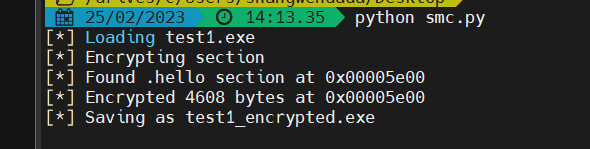
成功了!!

终端也成功的运行出了加密后的程序,我们再到ida中观察它。
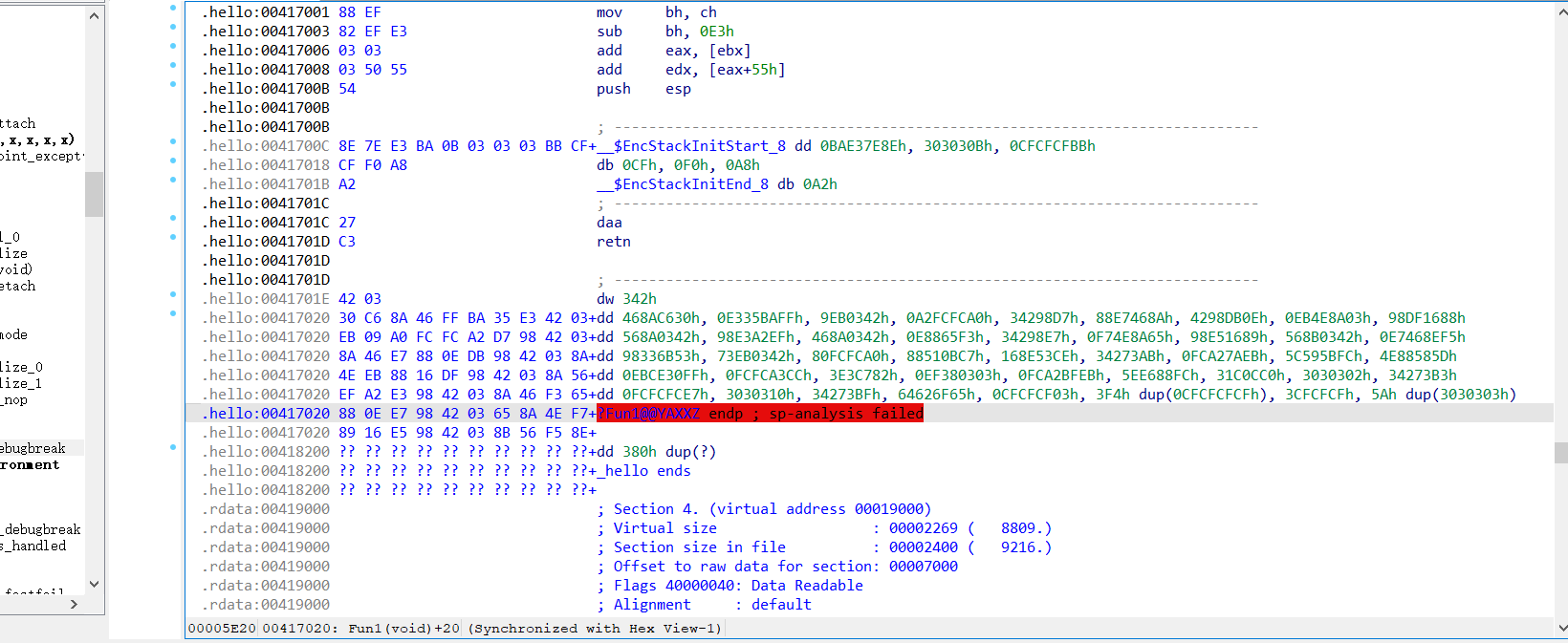
成功的无法静态分析。那么至此我们就成功的实现了该项技术!
SMC 技术在 CTF 比赛中有很多应用,主要是用来对抗反调试和反编译等工具的逆向分析。下面是几个常见的应用场景:
局部代码加密:CTF 比赛中有很多加密的二进制程序,利用 SMC 技术可以对程序的关键代码进行加密,增加分析难度,提高程序的安全性。
加密字符串和常量:CTF 比赛中有很多加密的字符串和常量,这些字符串和常量通常用来存储关键信息,如密钥、密码等。利用 SMC 技术可以对这些字符串和常量进行加密,增加分析难度,提高程序的安全性。
防止调试:CTF 比赛中有很多程序会使用调试器进行逆向分析,利用 SMC 技术可以对程序进行调试器检测和防御,防止调试器的使用。
防止反编译:CTF 比赛中有很多程序会被反编译,利用 SMC 技术可以对程序进行反编译检测和防御,防止程序被反编译。
总之,SMC 技术在 CTF 比赛中是一个非常有用的技术,可以用来保护程序的安全性,增加分析难度,提高程序的安全性。
点开文件可以看到一个可疑函数对文件地址进行操作,怀疑是smc文件加密技术。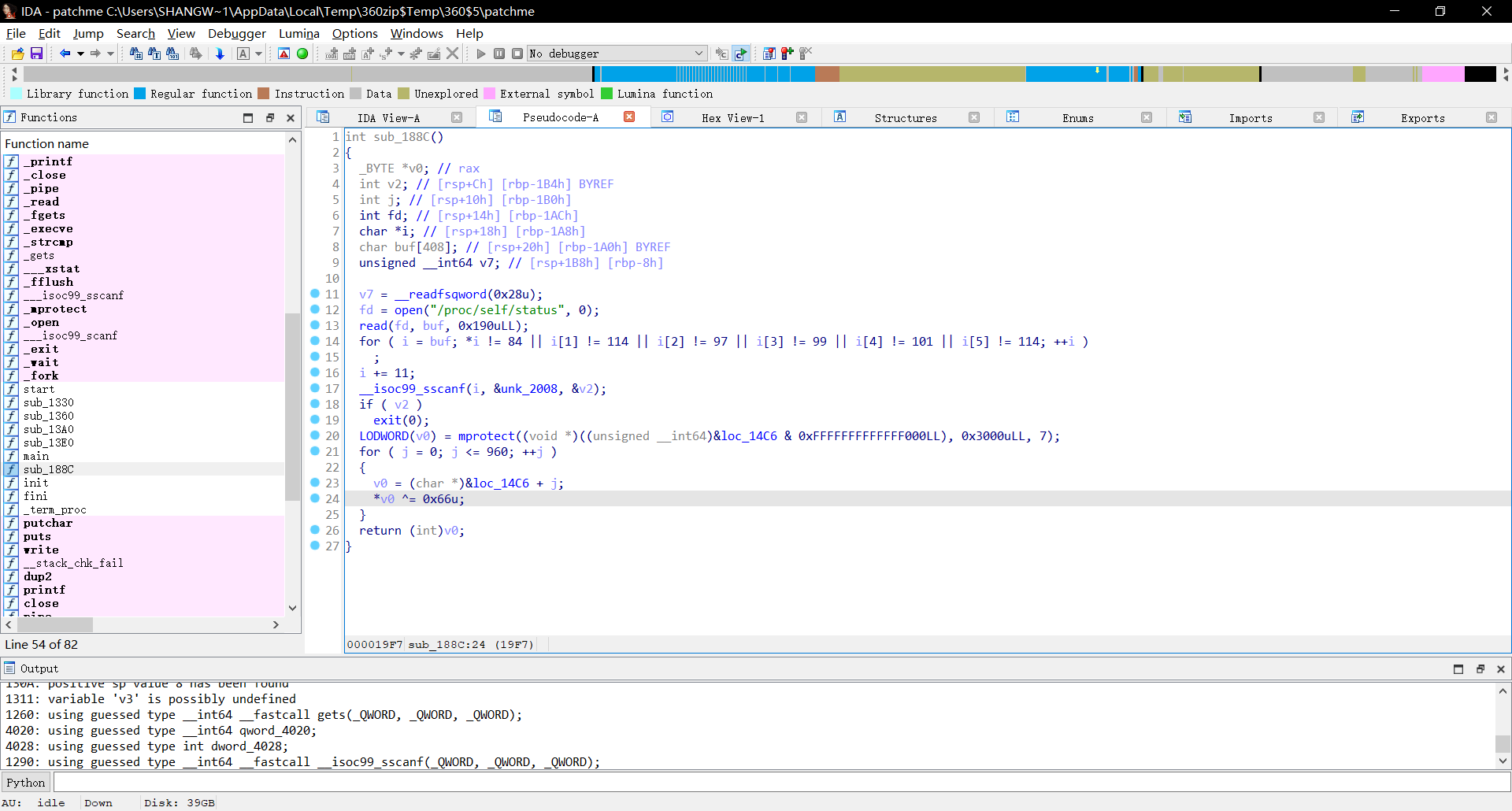
跟踪过去看一看。
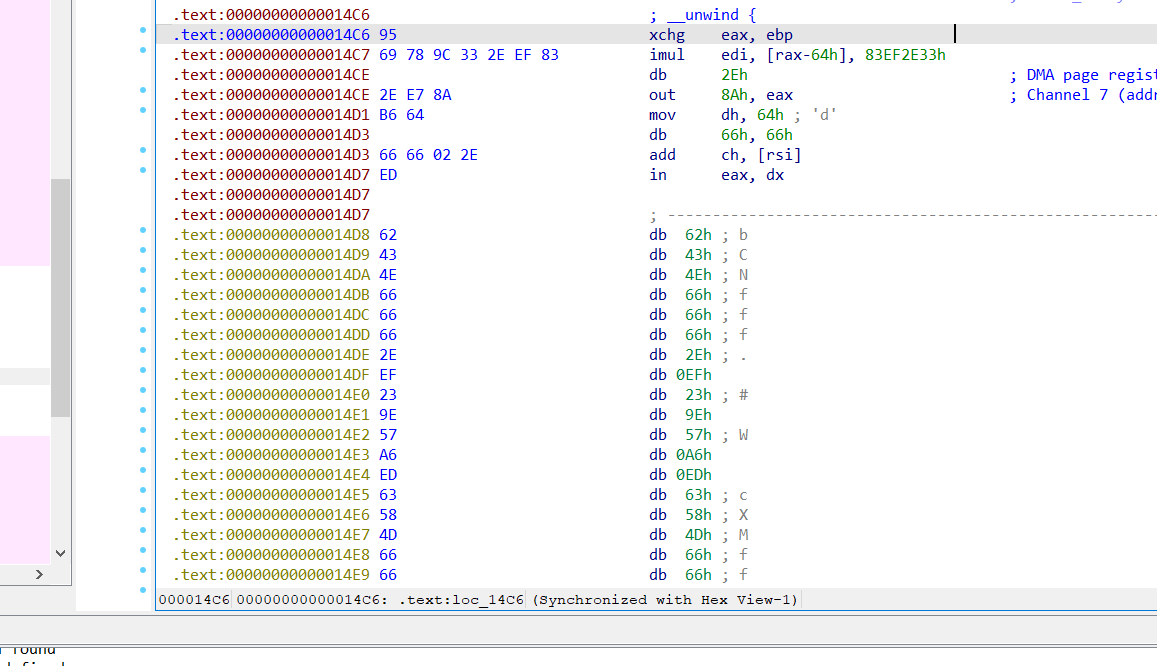
发现地址爆红,出现大量没有被解析的数据段那么实锤此处就是smc文件加密,那么我们将其异或回去,使用idc或者idapython
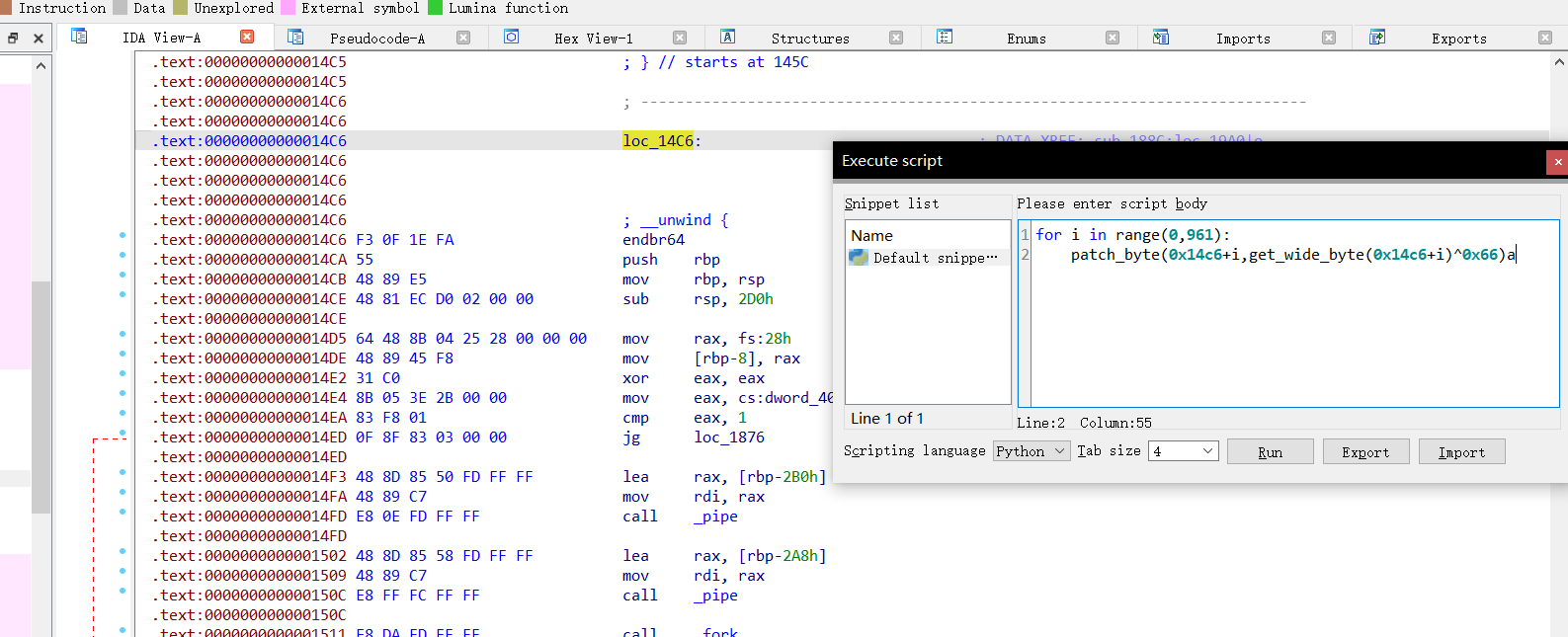
运行idapython脚本之后发现本来ida无法识别的汇编代码变得可以识别了,那么我们声明所有的未声明函数。
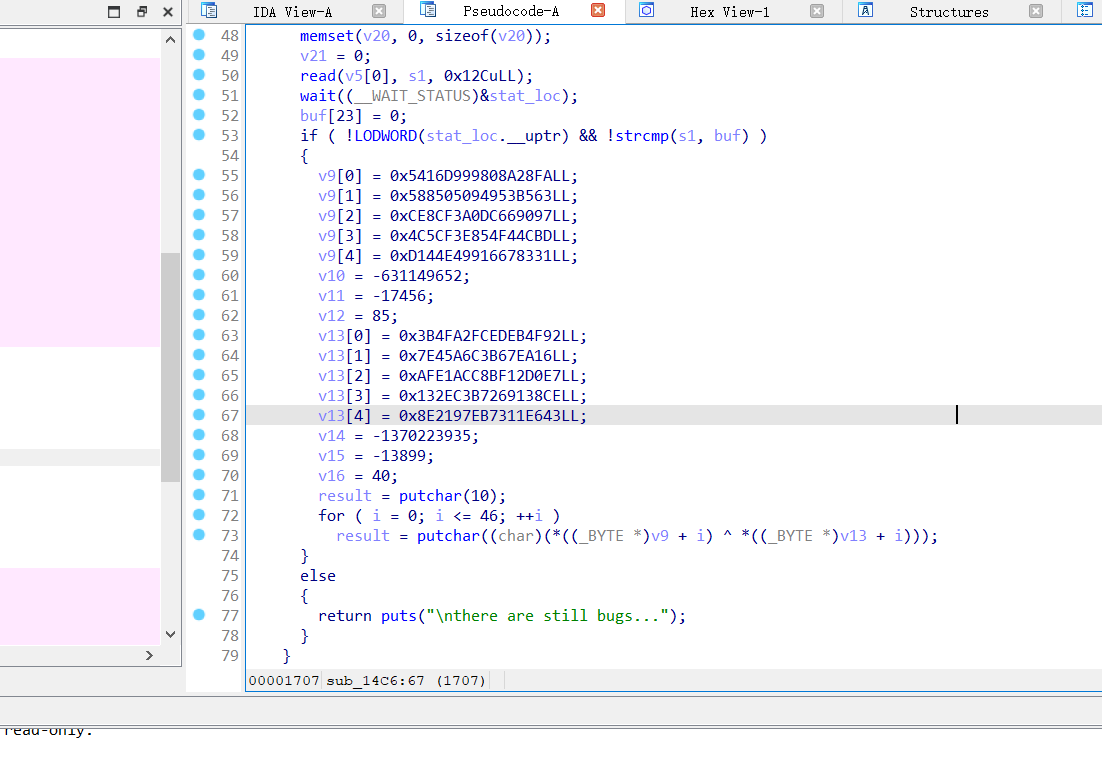
就可以在下面找到输出flag的方法了。
EXP
#include<iostream>
#include<algorithm>
#include<cstdio>
#include<cmath>
#include<map>
#include<vector>
#include<queue>
#include<stack>
#include<set>
#include<string>
#include<cstring>
#include<list>
#include<stdlib.h>
using namespace std;
typedef int status;
typedef int selemtype;
int ida_chars[] =
{
0xFA, 0x28, 0x8A, 0x80, 0x99, 0xD9, 0x16, 0x54,
0x63, 0xB5, 0x53, 0x49, 0x09, 0x05, 0x85, 0x58,
0x97, 0x90, 0x66, 0xDC, 0xA0, 0xF3, 0x8C, 0xCE,
0xBD, 0x4C, 0xF4, 0x54, 0xE8, 0xF3, 0x5C, 0x4C,
0x31, 0x83, 0x67, 0x16, 0x99, 0xE4, 0x44, 0xD1,
0xAC, 0x6B, 0x61, 0xDA, 0xD0, 0xBB, 0x55
};
int c[]={
0x92, 0x4F, 0xEB, 0xED, 0xFC, 0xA2, 0x4F, 0x3B,
0x16, 0xEA, 0x67, 0x3B, 0x6C, 0x5A, 0xE4, 0x07,
0xE7, 0xD0, 0x12, 0xBF, 0xC8, 0xAC, 0xE1, 0xAF,
0xCE, 0x38, 0x91, 0x26, 0xB7, 0xC3, 0x2E, 0x13,
0x43, 0xE6, 0x11, 0x73, 0xEB, 0x97, 0x21, 0x8E,
0xC1, 0x0A, 0x54, 0xAE, 0xB5, 0xC9,0x28
};
int main ()
{
for(int i = 0 ; i <= 46 ; i ++ )
{
printf("%c",ida_chars[i]^c[i]);
}
}
更多靶场实验练习、网安学习资料,请点击这里>>
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr