
新建一个maven依赖项目。
pom.xml中引入纤程jar的坐标依赖。
<dependency>
<groupId>co.paralleluniverse</groupId>
<artifactId>quasar-core</artifactId>
<version>0.7.4</version>
<classifier>jdk8</classifier>
</dependency>纤程使用示例。
package com.example.demo.fiber;
import co.paralleluniverse.fibers.Fiber;
import co.paralleluniverse.fibers.futures.AsyncCompletionStage;
import co.paralleluniverse.strands.Strand;
import co.paralleluniverse.strands.SuspendableRunnable;
import com.example.demo.fiber.tool.WorkTools;
import java.util.concurrent.CountDownLatch;
/**
* 描述:纤程demo </br>
* 作者:王林冲 </br>
* 时间:2023/4/7 15:44
*/
public class Test {
public static void main(String[] args) throws InterruptedException {
fiberTest();
}
public static void fiberTest() throws InterruptedException {
new Fiber(() -> {
Strand.sleep(5000);
System.out.println("纤程开始执行了");
}).start();
System.out.println("主线程执行完毕");
}
}为了实现类似于线程池的功能,想在一个批量处理的过程中,开多个纤程处理,在统一获取结果,然后继续主线程执行,场景相当多。
自己实现个纤程池。
package com.example.demo.fiber.tool;
import co.paralleluniverse.fibers.Fiber;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
/**
* 描述:协程工作程池 </br>
* 作者:王林冲 </br>
* 时间:2023/4/7 17:33
*/
@Slf4j
public class FiberWorkPool {
/**
* 工作协程数组
*/
private List<Fiber> workThreads;
/**
* 协程任务倒计数门栓
*/
private CountDownLatch countDownLatch = new CountDownLatch(0);
/**
* 建立协程池,taskCount 为协程池中工做协程的个数
* @param taskCount
*/
public FiberWorkPool(int taskCount) {
workThreads = new ArrayList<>(taskCount);
countDownLatch = new CountDownLatch(taskCount);
}
/**
* 任务加入任务队列
* @param task
*/
public void execute(Fiber task) {
try {
workThreads.add(task); //阻塞接口的Fiber work插入
} catch (Exception e) {
log.error("========> Fiber work add failed ..., msg : {}", e.getMessage());
}
}
//销毁协程池,该方法保证全部任务都完成的状况下才销毁全部协程,不然等待任务完成再销毁
public void shutdown() throws InterruptedException {
start();
countDownLatch.await();
workThreads.clear(); //清空等待队列
log.debug("========> successfully closed FiberWorkPool ...");
}
/**
* 启动协程池里所有的协程
*/
public void start() {
if (workThreads.size() != 0) {
for (Fiber fiber : workThreads) {
fiber.start();
}
}
}
/**
* 获取倒计数门栓
*
* @return
*/
public CountDownLatch getCountDownLatch() {
return this.countDownLatch;
}
}纤程池使用demo:
package com.example.demo.fiber.tool;
import co.paralleluniverse.fibers.Fiber;
import com.google.common.collect.Lists;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.concurrent.*;
/**
* 描述:协程池应用demo </br>
* 作者:王林冲 </br>
* 时间:2023/4/10 17:17
*/
@Component
public class FiberWorkPoolAppDemo {
public void fiber() throws InterruptedException {
//开启5个协程,50个任务列队。
FiberWorkPool fiberWorkPool = new FiberWorkPool(50);
for (int i = 0; i < 50; i++) {
fiberWorkPool.execute(new Fiber(() -> {
Fiber.sleep(50);
//System.out.println("========= " + Fiber.currentFiber().getName() + " ============");
fiberWorkPool.getCountDownLatch().countDown();
}));
}
//等待协程任务完毕后再结束主线程
fiberWorkPool.shutdown();
}
public void thread() throws ExecutionException, InterruptedException {
List<Future<Void>> futures = Lists.newArrayList();
ExecutorService executorService = Executors.newFixedThreadPool(50);
for (int i = 0; i < 50; i++) {
futures.add(executorService.submit(new Callable<Void>() {
@Override
public Void call() throws Exception {
Thread.sleep(50);
return null;
}
}));
}
for (Future<Void> future : futures) {
future.get();
}
executorService.shutdownNow();
}
}测试controller:
package com.example.demo.fiber.tool;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.ExecutionException;
/**
* 描述:协程controller </br>
* 作者:王林冲 </br>
* 时间:2023/4/10 17:20
*/
@RestController
@RequestMapping("/fiber")
public class FiberTestController {
@Autowired
private FiberWorkPoolAppDemo fiberWorkPoolAppDemo;
/**
* 协程测试
* @throws InterruptedException
* @throws ExecutionException
*/
@GetMapping("/fiberTest")
public void fiberTest () throws InterruptedException, ExecutionException {
Long start = System.currentTimeMillis();
fiberWorkPoolAppDemo.fiber();
System.out.println("=======> "+ (System.currentTimeMillis() - start) + "=======毫秒");
}
/**
* 线程测试
* @throws InterruptedException
* @throws ExecutionException
*/
@GetMapping("/threadTest")
public void threadTest () throws InterruptedException, ExecutionException {
Long start = System.currentTimeMillis();
fiberWorkPoolAppDemo.thread();
System.out.println("=======> "+ (System.currentTimeMillis() - start) + "=======毫秒");
}
}jmeter压测参数。
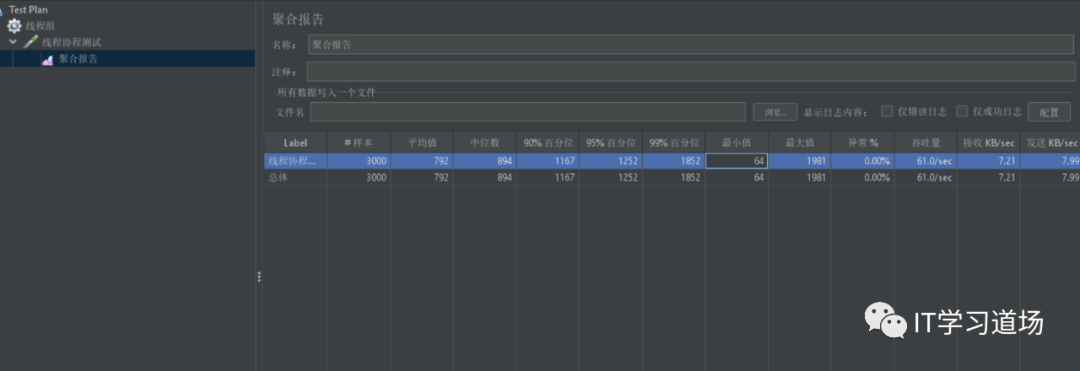
线程池压测。
纤程池压测。
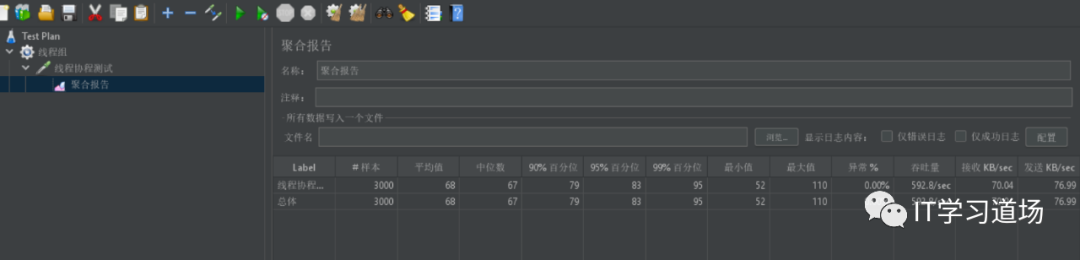
差距一目了然,当你的线程池,异步出现性能问题时,请考虑纤程,让你的代码性能数量级的提升,线程池之所以慢,是因为大量的线程频繁的上下文切换,和线程此中任务争夺线程while循环,耗cpu那是相当多,纤程就避免了这个问题。所以性能刚杠杠的。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候