去年4月,OpenAI发布的DALL-E 2用更高的分辨率、更真实的图像生成以及更准确地理解自然描述,横扫整个AIGC领域。
不过图像生成真正进入全民化还要数Stable Diffusion的开源,仅在消费级的GPU上即可运行,用户可以在自己的数据集上进行微调,也不用忍受各大绘画网站为了「安全」设立的各种过滤词表,真正实现了「绘画自由」。
而在视频生成领域,目前各家大厂还是只敢拿demo出来演示,普通用户还无法使用。
最近阿里达摩院在ModelScope上首发开源了「基于文本的视频生成」的模型参数,一起实现「视频自由」!

模型链接:https://modelscope.cn/models/damo/text-to-video-synthesis/files
体验链接:https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
只需要输入文本,即可返回符合文本描述的视频,并且该模型能够适用于「开放领域」的视频生成,能够基于文本描述进行推理,不过目前只支持英文输入。
比如说输入经典的「an astronaut riding a horse」,直接让宇航员动起来!
或者输入「a panda eating bamboo on a rock」,可以得到下面的视频。
也可以根据huggingface上提供的接口自行输入prompt,比如输入「a dog eating a cake」,就可以得到2秒钟的视频,不过由于计算资源不足,可能需要排队等待一会。
文本到视频生成扩散模型由「文本特征提取」、「文本特征到视频隐空间扩散模型」、「视频隐空间到视频视觉空间」三个子网络组成,整体模型参数约17亿。
多阶段文本到视频生成扩散模型采用Unet3D结构,通过从纯高斯噪声视频中迭代去噪的过程,实现视频生成的功能。
在实现上参考的相关论文主要有两篇。
高分辨率图像合成与潜扩散模型
通过将图像形成过程分解为自动编码器去噪的顺序应用,扩散模型实现了对图像数据和其他数据的最新合成结果,并且扩散模型的公式能够接受一个引导机制来控制图像生成过程,而不需要重新训练。

不过由于这些模型通常直接在像素空间中运行,因此对强大的扩散模型进行优化通常需要耗费数百 GPU 天的时间,并且由于顺序评估而导致推理成本高昂。
论文链接:https://arxiv.org/pdf/2112.10752.pdf
为了能够在有限的计算资源上进行扩散模型训练,同时保持其质量和灵活性,研究人员将其应用于强大的预训练自动编码器的潜空间。
与以往的工作相比,在这种表征上的训练扩散模型可以在降低复杂度和保持细节之间达到接近最佳的点,大大提高了视觉保真度。
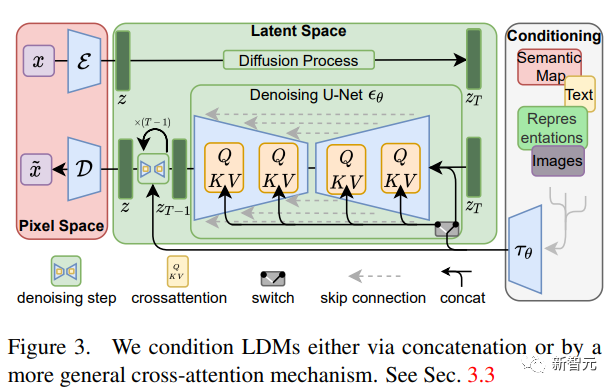
通过在模型结构中引入交叉注意层,可以将扩散模型转化为功能强大且灵活的生成器,用于一般条件输入(如文本或边界框) ,并使得以卷积方式进行高分辨率合成成为可能。

文中提出的潜扩散模型(LDM)在图像修复和各种任务(包括无条件图像生成、语义场景合成和超分辨率)的高度竞争性性能方面取得了新的进展,同时与基于像素的潜在扩散模型相比,显著降低了计算需求。
VideoFusion:用于高质量视频生成的分解扩散模型
扩散概率模型(DPM)通过逐渐向数据点添加噪声来构造正向扩散过程,并学习反向去噪过程以生成新样本,已被证明能够处理复杂的数据分布。
尽管最近在图像合成方面取得了成功,但是由于视频的数据空间维度更高,将DPM应用于视频生成仍然具有挑战性。

以往的方法通常采用标准的扩散过程,即用独立的噪声破坏同一视频片段中的帧,忽略了内容冗余和时间相关性。

论文链接:https://arxiv.org/pdf/2303.08320v2.pdf
这篇论文提出了一种分解扩散过程,通过将每帧噪声分解为一个在所有帧之间共享的基本噪声和一个沿着时间轴变化的残余噪声;去噪pipeline采用两个联合学习的网络来相应地匹配噪声分解。
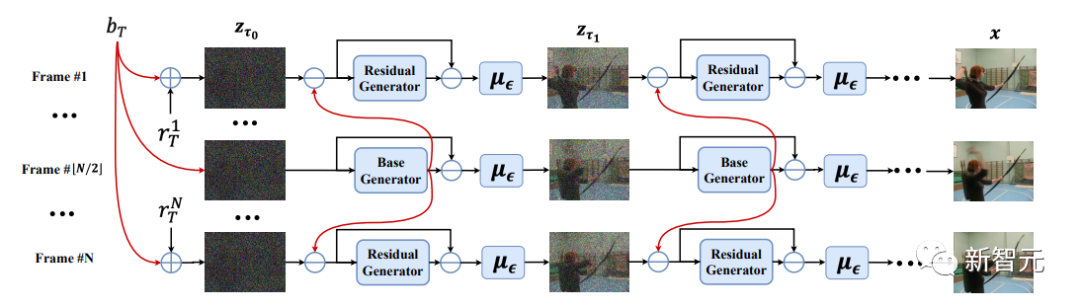
在不同数据集上的实验证实了文中的方法VideoFusion,在高质量视频生成方面优于基于GAN和基于扩散的替代方法。
实验中进一步表明,分解公式可以受益于预先训练的图像扩散模型和良好的支持文本条件下的视频生成。
在ModelScope框架下,通过调用简单的Pipeline即可使用当前模型,其中,输入需为字典格式,合法键值为'text',内容为一小段文本。
该模型暂仅支持在GPU上进行推理,模型需要硬件配置大约是 16GB 内存和 16GB GPU显存。
输入具体代码示例如下。
运行环境 (Python Package)
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/modelscope && cd modelscope && pip install -e .
pip install open_clip_torch代码范例 (Demo Code)
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
p = pipeline('text-to-video-synthesis', 'damo/text-to-video-synthesis')
test_text = {
'text': 'A panda eating bamboo on a rock.',
}
output_video_path = p(test_text,)[OutputKeys.OUTPUT_VIDEO]
print('output_video_path:', output_video_path)查看结果 (View Results)
上述代码会展示输出视频的保存路径,目前编码格式采用VLC播放器可以正常播放。
模型的限制与偏见
训练数据
训练数据包括 LAION5B、 ImageNet、 Webvid 等公共数据集。图像和视频滤波是经过美学评分、水印评分和重复数据删除等预训练后进行的。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
有这些railscast。http://railscasts.com/episodes/218-making-generators-in-rails-3有了这个,你就会知道如何创建样式表和脚手架生成器。http://railscasts.com/episodes/216-generators-in-rails-3通过这个,您可以了解如何添加一些文件来修改脚手架View。我想把两者结合起来。我想创建一个生成器,它也可以创建脚手架View。有点像RyanBates漂亮的生成器或web_app_themegem(https://github.com/pilu/web-app-theme)。我
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p