
最近工作中遇到某些七七八八的问题,就是与事务和锁、并发都有着紧密联系相关的问题所在。主要情况是:通过调用方法获取编号,而这个编号是递增有序的,并且存在于数据库中,简单理解就是需要用到这种编号(以下称任务编号),需要从数据库获取出来,在+1最为本次需要的编号,然后在存回数据库中,提供下次使用。直观来看是没得问题的,但是,可能在某次并发的时候出现编号相同,着属实很令人头疼,在经过领导的指导下是完美的解决了,接下来复盘一下。
因为公司项目使用WQL作为持久层,但是我这次使用Mybatis-Plus,效果大差不差。新建springboot项目,基础创建不在赘述。主要创建一张简单的数据表,就一个id和number字段。之后用mp自动生成代码。
最外层加上Transactional注解,并且在对编码操作的方法也加了Transactional注解,为了防止并发问题,加了锁。此时模拟的问题是:在嵌套事务中,父事务延时提交导致获得到的数据出错。
直接在控制层中调用,这里会加上Transactional,并且一开始数据库数据为{“id”:“1”, “number”:“460”}
@GetMapping("/t1")
@Transactional(rollbackFor = Exception.class)
public void getTest1() {
String n = countNumService.getCount();
System.out.println(" t1 : " + n);
try {
Thread.sleep(6000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
@GetMapping("/t2")
@Transactional(rollbackFor = Exception.class)
public void getTest2() {
String n = countNumService.getCount();
System.out.println(" t2 : " + n);
// 忽略其他的增删操作
}
对数据库获取操作的方法,加上Transactional与synchronized。
@Override
@Transactional(rollbackFor = Exception.class)
public synchronized String getCount() {
// 获取
CountNum countNum = countNumMapper.selectById(1);
countNum.setNumber(countNum.getNumber() + 1);
// 修改
countNumMapper.updateById(countNum);
return countNum.getNumber().toString();
}
通过IDEA的插件RestServices(也可以用postman)测试,先请求/t1接口,这里会睡眠6s来模拟事务延时提交,在去请求/t2接口,可以看出得到的数据会是相同的。

只有两个线程都能形成两个相同的code,仔细分析一下,假设synchronized锁是锁住的,那为什么会出现这样的问题呢?当t1线程访问getCount()方法,此时他拿到synchronized的锁,在进行获取数据并且+1操作后进行update操作,此时synchronized的锁已经被释放了,但是父事务却没有提交,也就是没有写回到数据库中,接下来t2线程过来了,也拿到了这把锁,又从数据库获取了数据,此时获得的是脏数据,最后就会导致出现了相同的code。
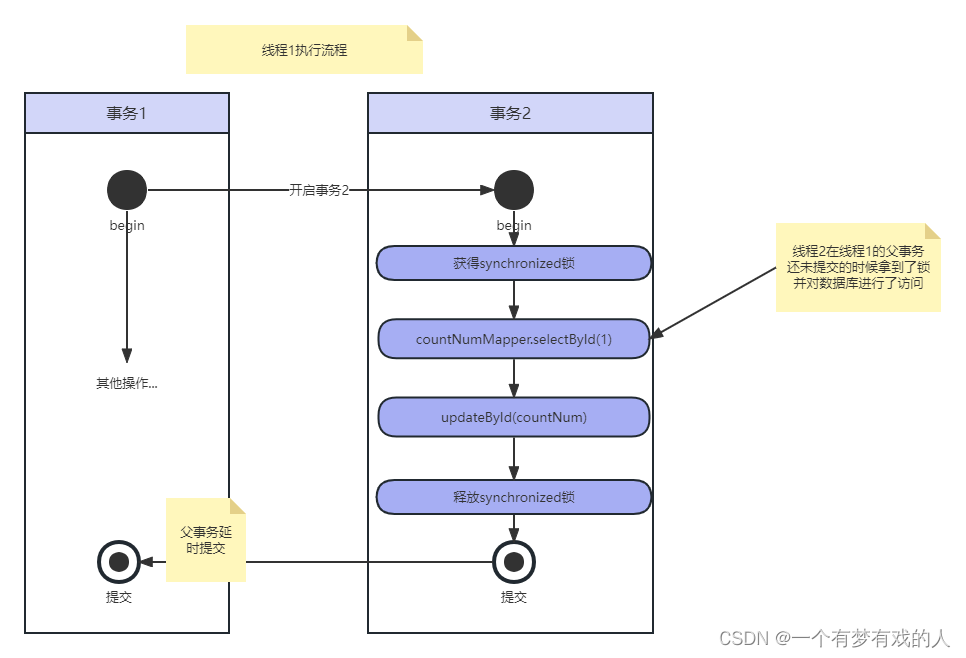
这里是因为事务的先后提交导致,可以使用Transactional注解的配置来解决,使用@Transactional(propagation = Propagation.REQUIRES_NEW),每次都会启动一个新的事务,是Spring事务传播机制的一种级别,表示当前方法必须在自己的事务中运行,如果当前已经存在一个事务,则会挂起该事务,创建一个新的事务用于执行当前方法。当当前方法执行完成后,新事务被提交,原事务恢复执行。
此次测试是使用apache-jmeter-5.4.3测试工具来测试20次请求的并发情况(接口每次会创建100次,一共会又20*100次),在以上代码的条件下编写新的接口。
以下是每次请求都会创建100个线程,getCount()除了使用propagation = Propagation.REQUIRES_NEW,其他不变。
@GetMapping("/t3")
@Transactional(rollbackFor = Exception.class)
public void getTest1() {
for (int i = 0; i <100 ; i++) {
new Thread(()->{
String taskCode = countNumService.getCount();
System.out.println("t1 " + Thread.currentThread().getName() + " code: " + taskCode);
}).start();
}
}
测试结果就会发现并发下出现了种种问题,会出现相同的code。
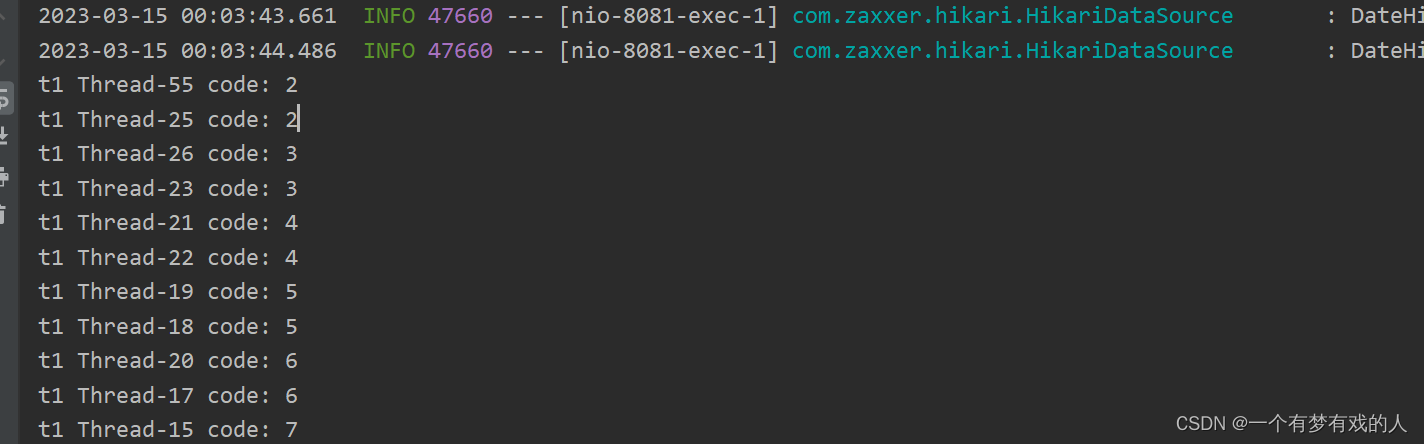
这是由于父子事务嵌套,子事务与锁一起使用,导致了synchronized锁的失效。当我把事务去掉的时候,则就不会出现并发的问题。

问题就是出在事务与synchronized锁的共同使用导致的,如果既要保证并发不出问题,又要保证在异常的时候需要回滚数据,在实际应用中,getCount()内部又其他对数据库的操作,因此需要事务来保证异常的回滚,也就是一定需要父子事务的嵌套,在这种情况下需要怎么做处理?
首先先来了解事务Transactional与锁synchronized一同使用会带来什么问题。
事务Transactional与锁synchronized他们是两种不一样的机制,两种机制要是一起使用,可能会出现一些问题。
首先,synchronized锁是用来实现线程同步,防止多个线程同时访问共享资源导致的并发问题。而Transactional是Spring框架中用于管理事务的机制,用于保证多个操作的四个特性(原子性、一致性、隔离性和持久性)。
可以将子事务中的锁移到父事务中,优化一下细粒度,就只对获取任务编码的这条语句进行上锁。
@GetMapping("/t4")
@Transactional(rollbackFor = Exception.class)
public void getTest4() {
for (int i = 0; i <100 ; i++) {
new Thread(()->{
synchronized(CountNumController.class) {
String taskCode = countNumService.getCount();
System.out.println("t4 " + Thread.currentThread().getName() + " code: " + taskCode);
}
}).start();
}
}
这样就能保证并发不出问题,也能保证将父子事务都存在。

👍创作不易,如有错误请指正,感谢观看!记得点赞哦!👍
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
我目前正在上一门数据库类(class),其中一个实验室问题让我困惑于如何实现上述内容,事实上,如果可能的话。我试过搜索docs但是定义的交易方式比较模糊。这是我第一次尝试在没有Rails的情况下进行任何数据库操作,所以我有点迷茫。我已经成功地创建了一个到我的postgresql数据库的连接并且可以执行语句,我需要做的最后一件事是根据一个简单的条件回滚一个事务。请允许我向您展示代码:require'pg'@conn=PG::Connection.open(:dbname=>'db_15_11_labs')@conn.prepare('insert','INSERTINTOhouse(ho
如何使用Rails中的事务block一次性更新/保存模型的多个实例?我想更新数百条记录的值;每条记录的值都不同。这不是一个属性的批量更新情况。Model.update_all(attr:value)在这里不合适。MyModel.transactiondothings_to_update.eachdo|thing|thing.score=rand(100)+rand(100)thing.saveendendsave似乎发布了它自己的事务,而不是将更新分批处理到周围的事务中。我希望所有更新都在一次大交易中进行。我怎样才能做到这一点? 最佳答案
给定以下代码:defcreate@something=Something.new(params[:something])thing=@something.thing#anothermodel#modificationofattributesonboth'something'and'thing'omitted#doIneedtowrapitinsideatransactionblock?@something.savething.saveendcreate方法是隐式包装在ActiveRecord事务中,还是需要将其包装到事务block中?如果我确实需要包装它,这是最好的方法吗?
据我了解,如果我们在此交易中有任何代码,并且当它发生任何错误时(保存!,...)在该block中,整个代码将恢复,这里的问题是是否有任何超时(racktimeout=12)发生在这个block中。defcreateActiveRecord::Base.transactiondo//timeouthappensendend当Rack::Timeout发生时,我们如何使用事务回滚代码? 最佳答案 当发生Rack超时时,任何正在进行的事务都将被回滚,但是已经提交的事务当然会保持提交状态。您不必为此担心。一旦启动数据库事务,它最终将被提交或
我有一个跨越多个页面的表单。现在的设置方式并不理想,因为它会在提交时保存(到数据库)每个页面。因此,如果用户未在所有页面上完成表单,则数据库中将保存不完整的用户注册信息。如果用户没有完全填写表格,我想“回滚”保存。那么有没有一种方法可以设置一个事务,该事务在用户填写第一个表单时开始,在用户完成最后一页时结束? 最佳答案 您正在寻找的是acts_as_state_machinegem.如果您不熟悉状态机,请查看here. 关于ruby-on-rails-是否可以让数据库事务跨越Rails中
从来源(database_cleaner,active_record)来看,它们应该同样快。但是有人声称使用database_cleaner的事务策略会降低Controller和模型规范的速度(forexample)。我手头没有用于基准测试的大型测试套件。任何人有任何见解或比较两者? 最佳答案 我花了一点时间在广泛使用ActiveRecord固定装置的中型代码库上比较两者。当我将其切换为使用DatabaseCleaner而不是use_transactional_fixtures时,模型规范开始花费大约两倍的时间。在进行了与您相同的比