作者:vivo 互联网服务器团队
本文是《vivo营销自动化技术解密》的第5篇文章,重点分析介绍在营销自动化业务中实时营销场景的背景价值、实时营销引擎架构以及项目开发过程中如何利用动态队列做好业务流量隔离,动态发布,使用规则引擎来提升营销规则的配置效率等几种关键技术设计实践。
《vivo营销自动化技术解密》系列文章:
营销自动化的触达场景按照时效性划分主要有两大类:
1. 离线目标用户群发。
通过对业务离线数据的分析决策,制定合适的运营策略对目标用户进行群发触达。典型的场景有:新品推荐、活动预热、定期关怀、用户召回等。
2.实时个性化触达。
通过分析单个用户在一段指定时间内的行为轨迹,进行个性化的实时性营销触达。典型的场景有:支付提醒,满足活动条件触达等。
离线目标用户群发一般根据活动规则,T+n或者周期性对大数据离线用户数据进行批处理分析查询,获取满足条件的目标用户,从而进行营销触达。
需要关注的问题是:海量大数据的储存、查询性能和稳定性。而相比于离线目标用户群发,实时个性化触达对时效性的要求更高,一般来说触达效果也会更优,比如:
对24小时内收藏订单后,同时加入购物车的用户,push推送活动领券提醒;
对领取优惠券1小时内未使用的用户,推送使用提醒;
对活动期间成功下单总金额达到999元的用户,推送领取奖励提醒;
实时个性化触达需要关注问题包括:
1. 事件实时接入的高扩展性 。
需要快速支撑接入不同业务系统的各类行为事件和规则,需要进行统一的分发处理。
2.高性能高可靠统一分发处理。
3.复杂多源数据的处理。
包括数据的补全,各种规则指标的统计,目标用户的交并差计算。
4.高效可扩展的规则匹配。
对业务定义的各种复杂规则,需要有一套强扩展性的规则匹配工具。
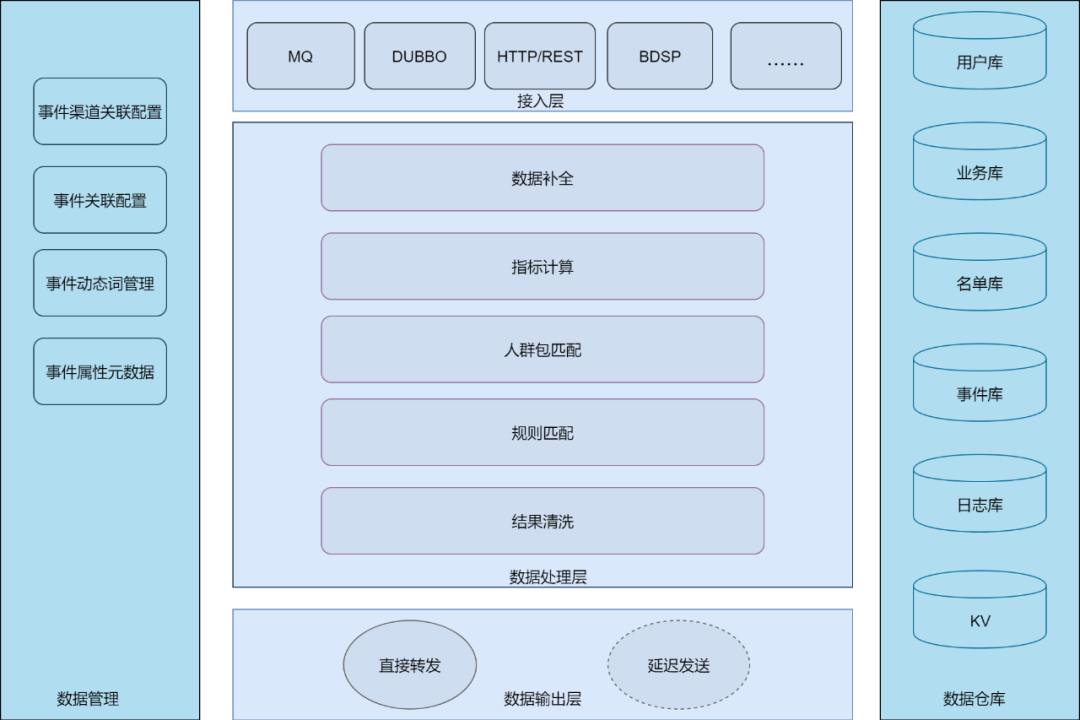
接入层
提供多种业务事件数据接入方式(比如支持异构外部系统的通用HTTP,内部的DUBBO、MQ等),最后转成MQ的方式统一分发。
由于事件数据源的不同,需要对宿主业务进行队列流量隔离管控,同时还需要评估后续队列的容量伸缩效率。
需要满足新增事件时,无需对系统进行重新部署,需要进行动态消息队列接入(下文会进行详细解析)。
数据处理层
实时引擎的核心部分。主要负责对事件数据进行加工处理,主要包括:
业务数据的统一标识补全,将多源数据进行打通关联。
对业务数据进行各种指标计算。常见的是基于时间窗口和会话窗口的流式计算,一般使用Flink来搭建。
目标用户匹配。常用的用户直接交并差集计算,能够更好的对目标用户进行实验。
业务规则匹配。基于业务逻辑对用户的数据进行匹配。
数据输出层
负责结果数据输出分发,主要目的是数据调配和触达发送策略。
数据管理
保存事件元数据的配置。
数据仓库
离线数据的储存,作用于流程中各种数据处理流程。
由于公司内部业务技术栈不尽相同,需要支持多种业务事件数据接入方式,比如通用HTTP接口,Java技术栈的DUBBO接口、和MQ消息队列的方式,为了系统内部可以进行统一管理,最后转成MQ的方式进行统一分发。
由于事件数据源的不同,需要对宿主业务进行MQ队列流量管控隔离。不同业务系统事件接入需求有以下不同的设计方案:
方案一:为每个接入的事件创建一条新队列,不同事件使用不同队列。

优点:最小粒度的流量控制,不同事件接入之间可以做到隔离,互不影响。
缺点:每次接入新事件都需要申请创建队列,随着事件接入数据增加,队列维护成本比较高。
方案二:同一接入方的事件使用同一队列,不同接入方使用不同队列(目前消息中心的方案)
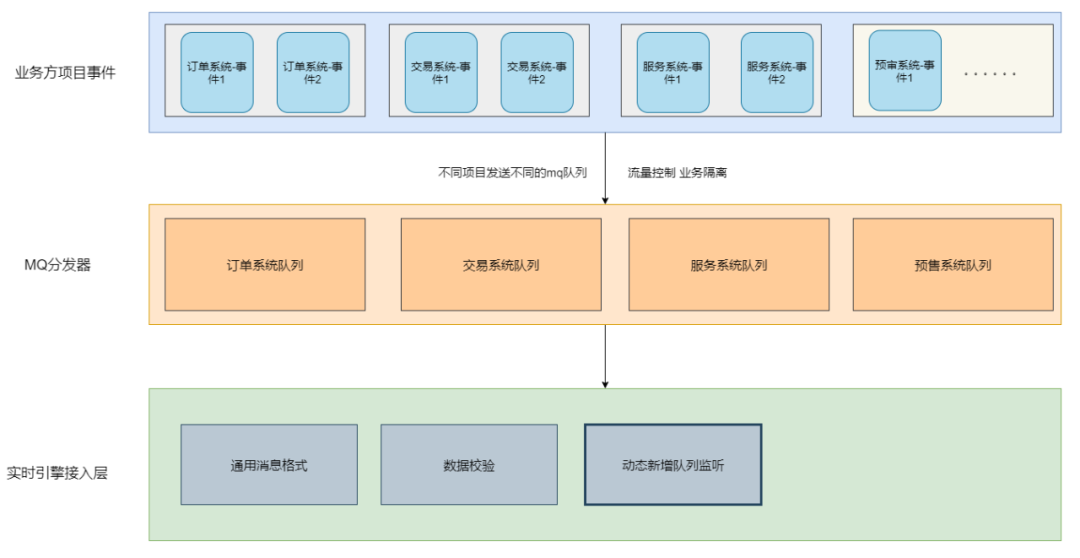
优点:按接入方来进行流量控制,接入方之间进行隔离,同一接入方只需在首次接入使用时创建队列,后续接入新事件无需创建。
缺点: 不同接入方接入时需要创建队列,同一接入方不隔离,有相互影响的风险。
方案三:不同接入方、事件均使用同一队列
优点:业务方使用友好,后续接入无需变更,耦合度小,方便切换MQ中间件。
缺点:最大粒度的流量控制,无法做到隔离,风险较高,需要经常进行队列扩容。
方案四:事先评估每个事件的优先级(如流量),高优先级的事件单独创建一条队列,低优先级的事件共用同一队列
优点:按事件的维度进行流量控制。
缺点:对接入方使用不够友好,不同业务接入时需要创建队列。
各方案对比如下:
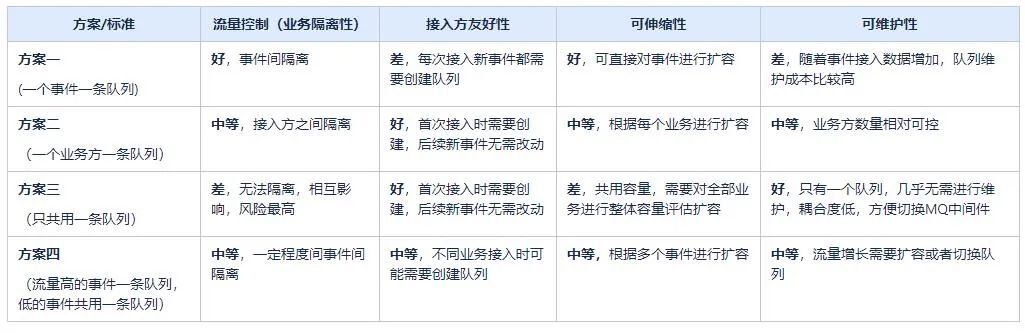
结论:按照当前项目优先级综合评估来看,业务隔离性>可伸缩性>可维护性>接入方友好性。
方案二比较适合 。(不同的项目可以根据自己的实际情况按优先级进行合适的选型)
背景:当需要做好业务间风险隔离时,就必须按业务或者事件的维度进行队列拆分。此时若进行新接入事件就可能需要重新创建新的队列。
初期方案:采用公司中间件vivo-rmq, 当接入方需要新增队列时,需要修改代码新增队列监听,重新发版,这样做的问题是重新发版成本较高,按照项目流程管理进行效率低。
优化方案一: 修改启动加载类加载指定目录下的配置文件,新增队列时修改配置文件上传。
优点:无需发版。
缺点:仍需要重启服务器,同时需要维护配置文件目录等信息。
优化方案二:保存队列配置信息到数据表中,启用定时任务在服务器运行时动态监听数据库配置,新增或者下线队列配置记录后,自动进行队列变更。
优点:无需发版和重启。
缺点:定时任务实时性稍差,必须确保队列监听成功后在通知业务方接入。
结论:采用方案二,新增事件无需对系统进行重新部署,使用运行时动态方式进行消息队列接入。
抽象公共分发模板:事件参数和有效性检测 → 分发到事件规则匹配器 EventMatcher → 输出到渠道发送流程
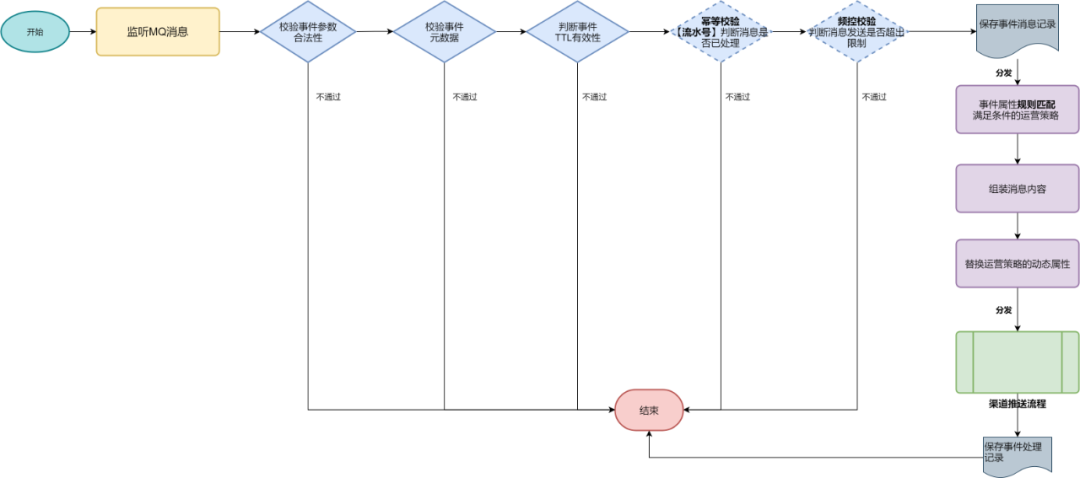
可靠平滑启停
1. MQ消费端分发主流程未处理完成,系统重启可能会造成事件消息丢失。
解决方案 :配置MQ消费端没有返回ack时,MQ服务端重新发送消息,此时业务消费必须保证幂等性。
2. MQ分发主流程处理完成已返回ack,但是在分发到业务线程池过程中 ,由于JVM重启而丢失。
解决方案 :这种场景时间极短,可以等待分发完成再进行ack。
3. MQ分发主流程分发到业务线程池处理过后, 但是线程池处理渠道发送过程仍可能因为JVM重启而丢失。
解决方案 :
利用JVM ShutdownHook钩子函数设置重启标记flag,MQ取数据时可以根据flag不再取出数据;
业务线程池不再接受新的任务, 同时利用线程池自身的Hook,等待处理线程池完成已有的任务。
指标补全
业务接入方可以提前将业务数据加载到统一大数据平台,并补充元数据配置,支持实时事件数据之外的数据补全。
指标统计
对规则配置数据进行,使用Flink CEP负责事件处理,支持时间窗口计算。
交并差运算
基于Presto计算查询引擎,对不同目标用户群进行交并差负责运算,得到处理后的结果数据。
传统方案
使用简单直接的硬编码的方式,根据不同的事件条件进行编码处理,适合迭代更新要求低的小型系统。
传统方案存在的问题
硬编码开发成本高,交付时间长,难以应对需求变化。
业务规则重复累赘,难以维护。
业务规则发生变化需要修改代码,重启服务后才能生效。
规则引擎
狭义上的规则引擎是业务规则管理系统,英文名为BRMS(即Business Rule Management System),指一整套的规则管理解决方案。
而广义上的规则引擎是指一个可以将业务决策从应用程序代码中分离出来的输入输出组件,接收业务数据输入,并根据业务规则输出决策。
规则引擎重点关注的是:规则配置的通用性和扩展性,以及规则匹配的性能。
规则引擎优点
业务规则与系统代码分离,实现业务规则的集中管理。
在不重启服务的情况下可随时对业务规则进行扩展和维护。
可以动态修改业务规则,从而快速响应需求变更。
规则引擎是相对独立的,只关心业务规则,使得业务分析人员也可以参与编辑、维护系统的业务规则。
减少了硬编码业务规则的成本和风险。
使用规则引擎提供的规则编辑工具,使复杂的业务规则实现变得的简单。
规则引擎的实现选型
目前开源规则引擎 Drools、Easy Rules、表达式引擎Aviator,还有动态语言Groovy、甚至直接使用SpEL进行封装都可以作为规则引擎的一种实现方案。
如果需要搭建一整套完整BRMS的功能,从规则配置工作台,图形化语言建模,规则库管理等一站式解决方案,可以直接选用Drools。这也是大家认为Drools使用起来比较“重”的原因,组件繁多逻辑复杂,学习成本高。
如果业务场景相对简单,只是希望解决规则迭代频繁的问题,提升配置管理的扩展性,可以选用Easy Rules或者利用表达式引擎Aviator为基础搭建。
规则引擎常用应用场景
风险控制系统:风险贷款、风险评估
反欺诈项目:银行贷款、征信验证
决策平台系统:财务计算
促销平台系统:满减、打折、加价购等营销场景
其他应用场景
本文重点分析介绍在营销自动化业务中实时营销引擎的设计,实时营销是通过分析单个用户在一段指定时间内的行为轨迹,产生动态的运营决策,可以对用户进行即时性的触达。
实时营销引擎架构设计主要分为事件接入、数据处理、指标计算、数据输出、元数据配置和数仓管理等模块。在项目开发过程我们利用队列隔离做好业务流量隔离,队列动态配置支持事件高效接入发布,统一分发处理提升流程的抽象化,平滑发布保障数据的可靠性,规则引擎来提升营销规则的配置效率。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只