注意力机制(Attention Mechanism)是一种人工智能技术,它可以让神经网络在处理序列数据时,专注于关键信息的部分,同时忽略不重要的部分。在自然语言处理、计算机视觉、语音识别等领域,注意力机制已经得到了广泛的应用。
注意力机制的主要思想是,在对序列数据进行处理时,通过给不同位置的输入信号分配不同的权重,使得模型更加关注重要的输入。例如,在处理一句话时,注意力机制可以根据每个单词的重要性来调整模型对每个单词的注意力。这种技术可以提高模型的性能,尤其是在处理长序列数据时。
在深度学习模型中,注意力机制通常是通过添加额外的网络层实现的,这些层可以学习到如何计算权重,并将这些权重应用于输入信号。常见的注意力机制包括自注意力机制(self-attention)、多头注意力机制(multi-head attention)等。
总之,注意力机制是一种非常有用的技术,它可以帮助神经网络更好地处理序列数据,提高模型的性能。
文章目录
多头注意力(Multi-Head Attention)是注意力机制的一种扩展形式,可以在处理序列数据时更有效地提取信息。
在标准的注意力机制中,我们计算一个加权的上下文向量来表示输入序列的信息。而在多头注意力中,我们使用多组注意力权重,每组权重可以学习到不同的语义信息,并且每组权重都会产生一个上下文向量。最后,这些上下文向量会被拼接起来,再通过一个线性变换得到最终的输出。
多头注意力是Transformer模型中的一个重要组成部分,被广泛用于各种自然语言处理任务,如机器翻译、文本分类等。
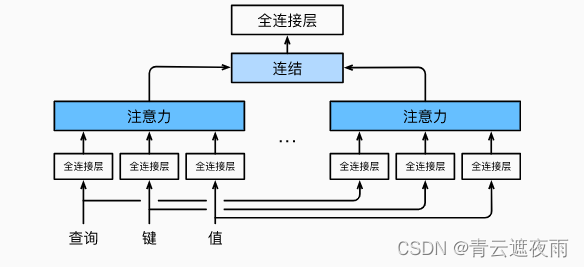
在实现多头注意力之前,让我们用数学语言将这个模型形式化地描述出来。 给定查询
q
∈
R
d
q
q\in R^{d_q}
q∈Rdq、 键
k
∈
R
d
k
k\in R^{d_k}
k∈Rdk和值
v
∈
R
d
v
v\in R^{d_v}
v∈Rdv, 每个注意力头的计算方法为:
h
i
=
f
(
W
i
(
q
)
q
,
W
i
(
k
)
k
,
W
i
(
v
)
v
)
∈
R
p
v
h_i=f(W_i^{(q)}q,W_i^{(k)}k,W_i^{(v)}v)\in R^{pv}
hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv
其中,可学习的参数包括
W
i
(
q
)
W_i^{(q)}
Wi(q)、
W
i
(
k
)
W_i^{(k)}
Wi(k)和
W
i
(
v
)
W_i^{(v)}
Wi(v), 以及代表注意力汇聚的函数
f
f
f。
f
f
f可以是加性注意力和缩放点积注意力。 多头注意力的输出需要经过另一个线性转换, 它对应着
h
h
h个头连结后的结果,因此其可学习参数是
W
o
W_o
Wo:

在实现过程中通常选择缩放点积注意力作为每一个注意力头。 为了避免计算代价和参数代价的大幅增长, 我们设定 p q = p k = p v = p p / h p_q=p_k=p_v=p_p/h pq=pk=pv=pp/h。 值得注意的是,如果将查询、键和值的线性变换的输出数量设置为 p q h = p k h = p v h = p p p_qh=p_kh=p_vh=p_p pqh=pkh=pvh=pp, 则可以并行计算 h h h个头。 在下面的实现中,是通过参数 p o p_o ponum_hiddens指定的。
#@save
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
为了能够使多个头并行计算, 上面的MultiHeadAttention类将使用下面定义的两个转置函数。 具体来说,transpose_output函数反转了transpose_qkv函数的操作。
#@save
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
代码解释:
这段代码实现了多头注意力机制,其中 MultiHeadAttention 类实现了多头注意力的前向传播, transpose_qkv 函数将输入的 queries, keys, values 通过线性变换并按照 num_heads 进行分组,最终输出变换后的 queries, keys, values,在前向传播中使用这些变换后的 queries, keys, values 来计算注意力权重。在 transpose_qkv 函数的实现中,首先将 queries, keys, values 转换成形状为 (batch_size, queries/keys/values_num, num_hiddens) 的张量,然后根据 num_heads 将最后一维进行分组,变换成形状为 (batch_size, num_heads, queries/keys/values_num, num_hiddens/num_heads) 的张量,最后将第一维和第二维进行交换,输出形状为 (batch_size*num_heads, queries/keys/values_num, num_hiddens/num_heads) 的张量。transpose_output 函数实现了对 MultiHeadAttention 的输出进行逆转换的操作。
这么做的原因是因为多头注意力机制可以将输入张量进行 num_heads 个独立的注意力计算,将计算结果在最后一维拼接起来作为输出,这样可以提高模型的并行性,加快计算速度。同时,通过变换形状将 num_heads 独立处理,也可以增强模型对不同位置和特征的表征能力。
具体来说,这段代码实现的是一个MultiHeadAttention类,其中定义了一个forward方法。这个方法接收一个查询序列queries,一个键序列keys,一个值序列values和一个有效长度序列valid_lens作为输入,然后输出一个加权聚合的结果。
MultiHeadAttention类的初始化方法中,我们定义了几个线性层,以及注意力计算函数,然后用这些组件来定义一个多头注意力层。该层包括将输入queries、keys和values通过三个线性层进行变换,以便将它们的形状变为(batch_size * num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads),其中num_heads表示注意力头的数量。然后,我们通过调用transpose_qkv函数对这些变换后的输入进行一次变换,以便在注意力计算函数中实现多头并行计算。最后,我们通过调用transpose_output函数将输出重构成(batch_size,查询的个数,num_hiddens),并通过一个线性层对其进行变换,输出最终结果。
transpose_qkv函数将输入的queries、keys和values通过reshape和permute操作进行变换,以便多头并行计算。具体来说,它将输入变换为(batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads)的形状,然后将第2和第3个轴进行交换。最后,它将输出变换为(batch_size * num_heads, 查询或者“键-值”对的个数, num_hiddens/num_heads)的形状。
transpose_output函数将多头并行计算得到的输出通过reshape和permute操作逆转回原来的形状,具体来说,它将输出变换为(batch_size,查询的个数,num_heads, num_hiddens/num_heads)的形状,然后将第2和第3个轴进行交换,最终将输出变换为(batch_size,查询的个数,num_hiddens)的形状。
这里似乎所有的单头都是同一些参数,这样不会导致每个单头的输出都是一样的吗?
这里的确有点难懂, 这里其实是把所有注意力头里面的参数拼起来, 变成了一个大的全连接层

作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我正在使用Ruby-Tk为OSX开发一个桌面应用程序,我想为该应用程序提供一个AppleEvents接口(interface)。这意味着应用程序将定义它将响应的AppleScript命令的字典(对应于发送到应用程序的Apple事件),并且用户/其他应用程序可以使用AppleScript命令编写Ruby-Tk应用程序的脚本。其他脚本语言支持此类功能——Python通过位于http://appscript.svn.sourceforge.net/viewvc/appscript/py-aemreceive/的py-aemreceive库和Tcl通过位于http://tclae.source
Method#unbind返回对该方法的UnboundMethod引用,稍后可以使用UnboundMethod#bind将其绑定(bind)到另一个对象.classFooattr_reader:bazdefinitialize(baz)@baz=bazendendclassBardefinitialize(baz)@baz=bazendendf=Foo.new(:test1)g=Foo.new(:test2)h=Bar.new(:test3)f.method(:baz).unbind.bind(g).call#=>:test2f.method(:baz).unbind.bind(h).
显示等待需要用到两个类:WebDriverWait和expected_conditions两个类WebDriverWait:指定轮询间隔、超时时间等expected_conditions:指定了很多条件函数(也可以自定义条件函数)具体可以参考官网:selenium.webdriver.support.expected_conditions—Selenium4.5documentationfromseleniumimportwebdriverfromselenium.webdriver.common.byimportByfromselenium.webdriver.support.uiimpor
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。社区在12个月前审查了是否重新打开此问题,并将其关闭:原始关闭原因未解决最近学习了Ruby编程语言,总的来说是一门很好的语言。但是我很惊讶地发现它并不像我预期的那么简单。更准确地说,“最小惊喜规则”在我看来并不是很受尊重(当然这是相当主观的)。例如:x=trueandfalseputsx#displaystrue!和著名的:puts"zeroistrue
我收到错误AWS::S3::Errors::InvalidRequest不支持您提供的授权机制。请使用AWS4-HMAC-SHA256.当我尝试将文件上传到新法兰克福地区的S3存储桶时。所有适用于USStandard区域。脚本:backup_file='/media/db-backup_for_dev/2014-10-23_02-00-07/slave_dump.sql.gz's3=AWS::S3.new(access_key_id:AMAZONS3['access_key_id'],secret_access_key:AMAZONS3['secret_access_key'])s3_
【摘 要】近年来,基于自注意力机制的神经网络在计算机视觉任务中得到广泛的应用。随着智能交通系统的广泛应用,面对复杂多变的交通场景,车牌识别任务的难度不断提高,准确识别的需求更加迫切。因此提出一个基于自注意力的免矫正的车牌识别方法T-LPR。首先对图像进行切片和序列化,并使用3D卷积对切片序列进行特征提取,从而得到图像的嵌入向量序列。然后将嵌入向量序列输入基于TransformerEncoder的编码器中,学习各个嵌入向量之间的关系并输出最终的编码结果。最后使用分类器进行分类。在多个公共数据集上的实验结果表明,所提方法对各类困难场景下的车牌识别都非常有效。【关键词】车牌识别 ; 图像嵌入向量 ;
这个问题在这里已经有了答案:"CAUTION:provisionalheadersareshown"inChromedebugger(36个答案)关闭8年前。这是我的Angularjs片段代码:$http({method:'POST',withCredential:true,url:$scope.config.app_ws+'auth/signup',data:{user:$scope.auth}}).success(function(status,response){console.log(response);}).error(function(status,response){al
Qt中的信息输出机制介绍QDebug在Qt中使用qDebug输出不同类型的信息浮点数:使用%!f(MISSING)格式化符号输出浮点数布尔值:使用%!(MISSING)和%!(MISSING)格式化符号输出布尔值对象:使用qPrintable()函数输出对象的信息qInfoqWarningqCritical自定义信息输出格式不同输出方式的区别和底层逻辑总结介绍在Qt中,信息输出机制用于在程序运行时输出各种信息,包括调试信息、提示信息、警告信息和错误信息等。Qt提供了多种信息输出机制,主要包括以下几种:qDebug:最常用的信息输出机制,用于输出各种调试信息,例如变量的值、函数的返回值和对象的状
我正在使用log4javascript来记录和跟踪我的JavaScript代码中的问题。我以前见过类似的日志记录辅助工具,但我很难理解应该如何使用这些日志级别中的每一个才能更有用和更有成效。大多数时候,我最终会记录调试、信息或跟踪,但并没有真正意识到它们各自的效率如何。随着代码变得越来越大,它变得越来越困难,我觉得日志麻烦多于帮助。有人可以给我一些指南/帮助,以便我可以很好地使用日志记录机制。以下是log4javascript支持的不同日志级别:log4javascript.Level.ALLlog4javascript.Level.TRACElog4javascript.Level.