索引生命周期管理 (Index Lifecycle management: ILM) 是在 Elasticsearch 6.7 版正式推出的一项功能,它是 Elasticsearch 的一部分,主要用来帮助管理索引。
如果你要处理时间序列数据,则不想将所有内容连续转储到单个索引中。 取而代之的是,你可以定期将数据滚动到新索引,以防止数据过大而又缓慢又昂贵。 随着索引的老化和查询频率的降低,你可能会将其转移到价格较低的硬件上,并减少分片和副本的数量。
要在索引的生命周期内自动移动索引,可以创建策略来定义随着索引的老化对索引执行的操作,这样可以确保所有索引具有相似的大小。
ILM 由一些策略(policies)组成,而这些策略可以触发一些 actions。这些 actions 可以为:
| Action | Description |
| rollover | 创建一个新的索引,基于数据的时间跨度,大小及文档的多少 |
| shrink | 减少 primary shards 的数目 |
| force merge | 合并 shard 的 segments |
| freeze | 针对鲜少使用的索引进行冻结以节省内存 |
| delete | 永久地删除一个索引 |
索引生命周期由五个阶段(phases)组成:hot,warm,cold,frozen 及 delete。每个阶段有一组可用的 actions。这些 actions 由上面的 actions 中的一些组成。把这些阶段和相应的 actions 一起组合起来就形成了一个策略(policy)。我们可以通过 API 的形式或者直接在 Kibana 中使用 UI 的形式来创建这些 policies。
ILM 策略实例:
在 hot 阶段,你可能 rollover 一个 alias 从而每两个星期就生成一个新的索引,避免太大的索引数据。在这个阶段你可以做导入数据,并允许繁重的搜索。
在 warm 阶段,你可能把索引变成 read-only,并把索引保留于这个阶段一个星期。在这个阶段,不可以导入数据,但是可以进行适度的搜索。
在 cold 阶段,你可能 freeze 索引,并减少 replica 的数量,并保留于这个阶段三个星期。在这个阶段,不可以导入数据,但是可以进行极其少量的搜索,
在 delete 阶段,只有一个动作可以选择。比如你可以删除超过 6 个星期的索引数据以节省成本。
索引在 Elasticsearch 中的生命周期:
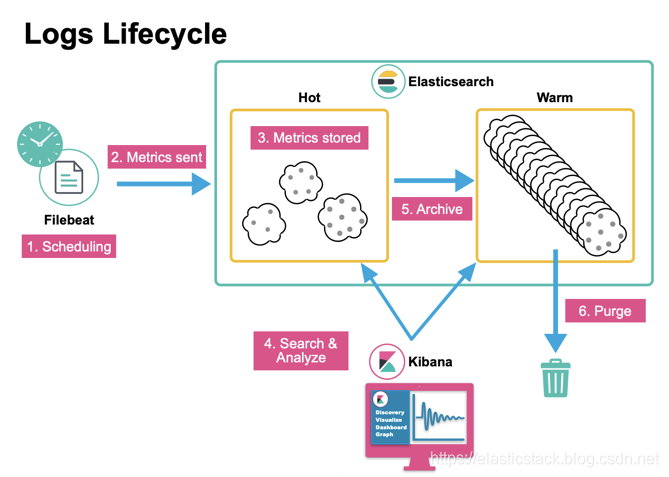
针对一个超大规模的集群:
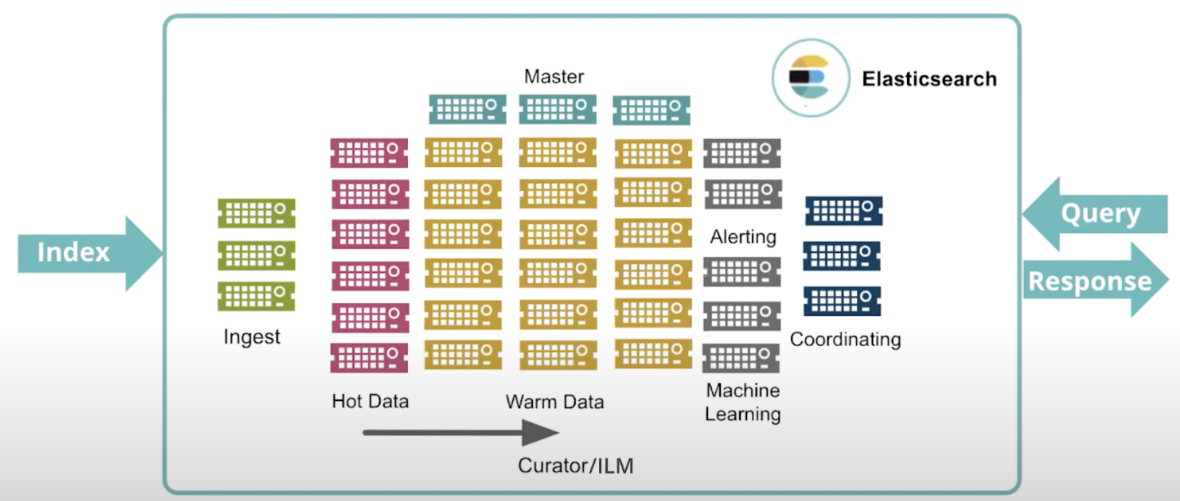
各节点职责:
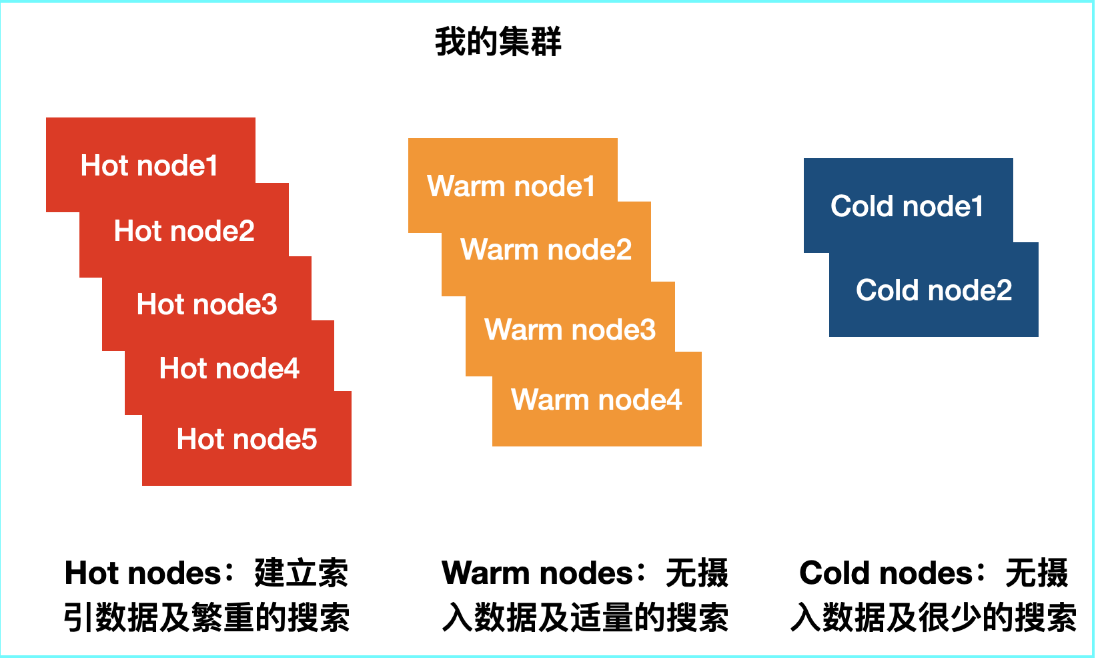
启动三个节点(10.49.196.10、10.49.196.11、10.49.196.12)的集群,其中两个为 hot 节点(存放 hot 阶段的数据),一个为 warm 节点(存放 warm 阶段的数据)。
在 10.49.196.10、10.49.196.11 上运行:
bin/elasticsearch -d -E node.attr.data=hot在 10.49.196.12 上运行:
bin/elasticsearch -d -E node.attr.data=warm查看 node 属性信息:
GET _cat/nodeattrs?v
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "10mb",
"max_age": "1d",
"max_docs": 5
}
}
},
"warm": {
"min_age": "5m",
"actions": {
"shrink": {
"number_of_shards": 1
},
"allocate": {
"number_of_replicas": 0,
"require": {
"data": "warm"
}
}
}
},
"delete": {
"min_age": "10m",
"actions": {
"delete": {}
}
}
}
}
}这里定义的 policy 意思为:
索引创建 1 天后、索引大小达到 10MB 或 索引文档数达到 5(符合任何一个即可),该索引将滚动更新,系统将创建一个新索引。该新索引将重新启动策略,而当前的索引(刚刚滚动更新的索引)将在滚动更新后等待 5 分钟进入温阶段。
索引进入温阶段后,ILM 会将索引收缩到 1 个分片 0 个副本,通过分配操作将索引移动到温节点。完成该操作后,索引将再等待 5 分钟 (时间都是从滚动跟新算起,10 - 5 = 5)后进入删除阶段。
删除阶段具有用于删除索引的删除操作。在删除阶段,您将始终需要有一个 min_age 条件,以允许索引在给定时段内待在热、温或冷阶段。
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias",
"index.routing.allocation.require.data": "hot",
"index": {
"number_of_shards": 2,
"number_of_replicas": 1
}
},
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"name": {
"type": "keyword"
},
"poems": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"about": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"success": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}所有以 test- 开头的 index 都需要遵循这个规律。这里定义了 rollover 的 alias 为 “test-alias”。需要注意的是 "index.routing.allocation.require.data": "hot",这定义了我们需要 indexing 的 node 的 data 属性是 hot。
PUT test-000001
{
"aliases": {
"test-alias": {
"is_write_index": true
}
}
}这里定义了一个叫做 test-alias 的 alias,它指向 test-00001 索引。注意这里的 is_write_index 为 true。如果有 rollover 发生时,这个alias会自动指向最新 rollover 的 index。
使用 elasticsearch-head 查看该索引:

POST test-alias/_bulk
{"index":{"_id":"1"}}
{"age": 30,"name": "李白1","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"}
{"index":{"_id":"2"}}
{"age": 30,"name": "李白2","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"}
{"index":{"_id":"3"}}
{"age": 30,"name": "李白3","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"}
{"index":{"_id":"4"}}
{"age": 30,"name": "李白4","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"}
{"index":{"_id":"5"}}
{"age": 30,"name": "李白5","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"}
{"index":{"_id":"6"}}
{"age": 30,"name": "李白6","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"}
已经有超过 5 个文档了,将会 rollover;rollover 扫描间隔默认时 10 分钟,可以通过修改 indices.lifecycle.poll_interval 参数来改变默认的间隔时间。
PUT _cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "30s"
}
}rollover 后会生成新的索引:

rollover 后,索引 test-000001 等待 5 分钟左右后将会进入 warm 阶段。
rollover 后的情况:
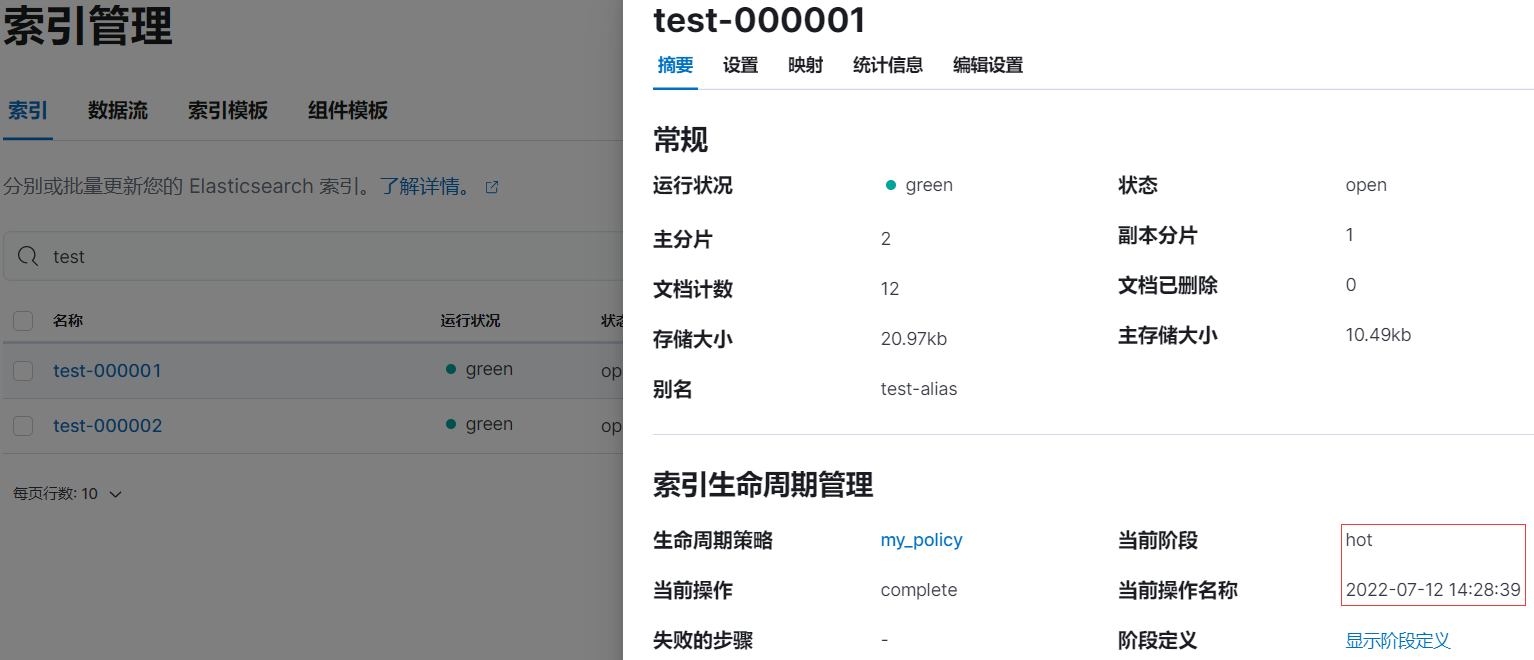
rollover 后等待 5 分钟左右后,索引 test-000001 已被重命名为 shrink-so7u-test-000001:
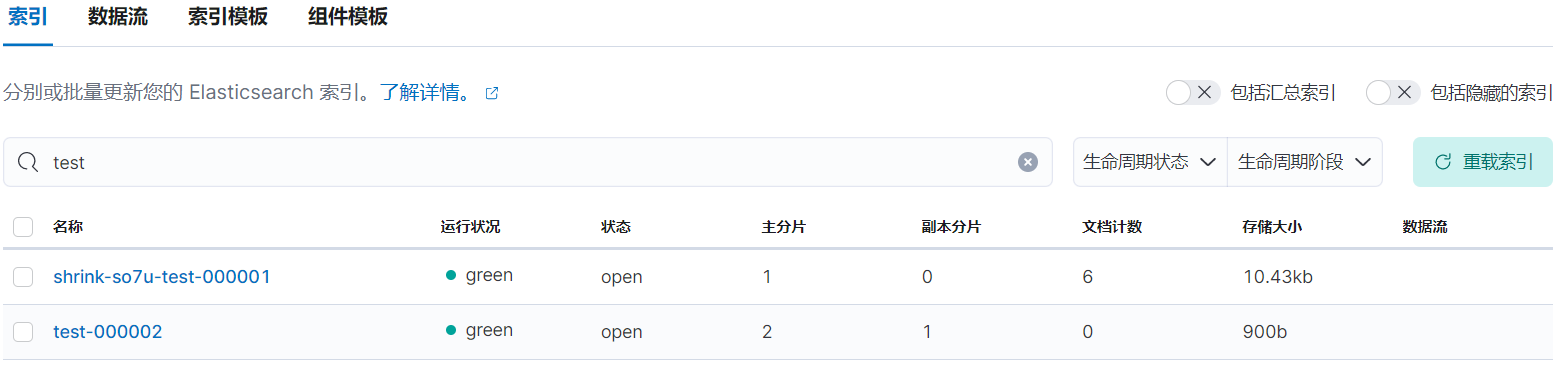
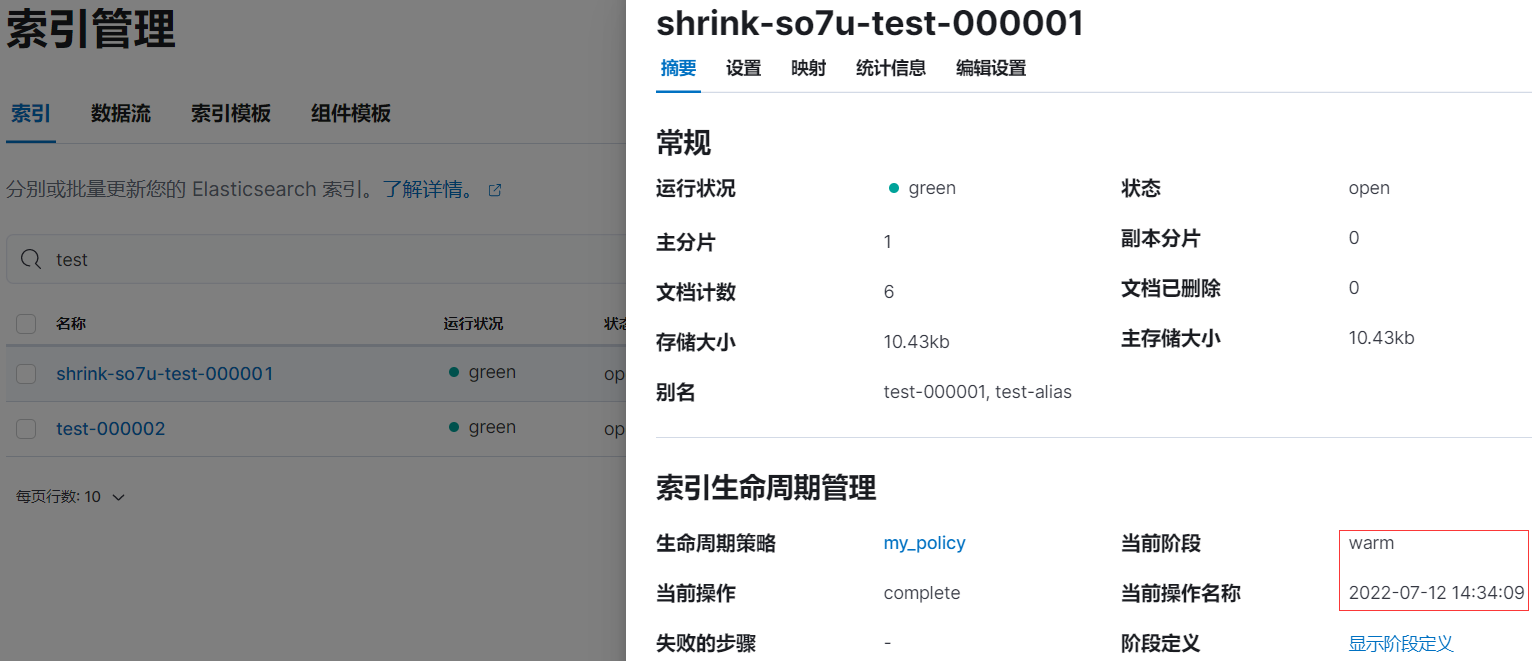
在 warm 阶段再等待 5 分钟(10m - 5m)左右后, shrink-so7u-test-000001 进入 delete 阶段,索引将被删除。
参考:
1、https://elasticstack.blog.csdn.net/article/details/102728987
2、https://elasticstack.blog.csdn.net/article/details/102856967
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生
我发现自己需要这个。假设cart是一个包含用户列表的模型。defindex_of_itemcart.users.each_with_indexdo|u,i|ifu==current_userreturniendend获取此类关联索引的更简单方法是什么? 最佳答案 indexArray上的方法与您的index_of_item方法相同,例如cart.users.index(current_user)返回数组中第一个对象的索引==给obj。如果未找到匹配项,则返回nil。 关于ruby-on-
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration