目录
该方法对点集进行逐步上采样,同时根据法向量信息来检测边缘点,需要输入点云具有法线信息。在点云空洞填充和稀疏表面重建中具有较好的应用。
头文件
#include <CGAL/edge_aware_upsample_point_set.h> // 上采样
函数
OutputIterator CGAL::edge_aware_upsample_point_set ( const PointRange & points,
OutputIterator output,
const NamedParameters & np = parameters::default_values()
)
这种方法逐步向上采样点集,同时接近边缘奇点(通过法线变化检测),这从输入点集产生一个更密集的点集。这在基于点的渲染、孔填充和稀疏表面重建中有应用。点的法线需要作为输入。
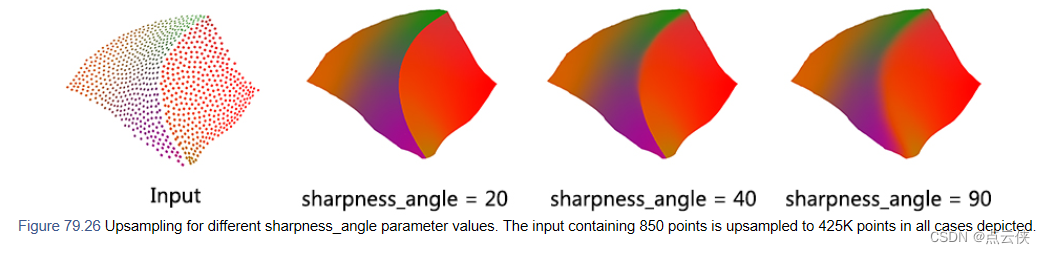
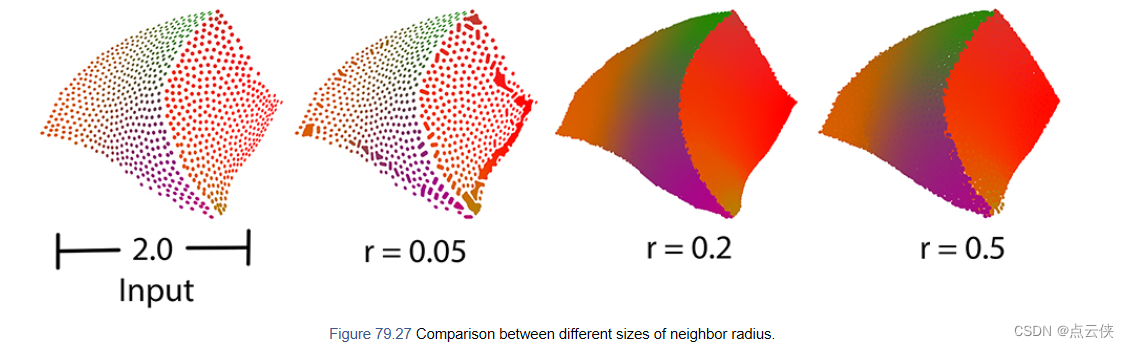
sharpness_angle(s_angle):控制输出结果的平滑度,值越大越平滑,取值范围[0,90]。edge_sensitivity(edge_s): 边缘的敏感性取值范围[0,1],边缘敏感度越大,在尖锐边缘处插入点的有限度越高neighbor_radius(n_radius) :邻域点的个数,如果提供,查询点的邻域是用一个固定的球面计算的半径,而不是固定数量的邻居。在这种情况下,参数k用于限制每个球邻域返回点的数量(避免高密度区域的点过多)number_of_output_points(n_out)) 上采样后的点数edge_sensitivity
此参数控制新点插入的位置。边缘敏感值越大,沿尖锐特征插入点的优先级越高。如下图所示,想要在尖锐的特征上插入更多的点时,高值是可取的,这些地方的局部梯度很高,如尖点、折痕和角等。相反,当edge_sensitivity设置为0时,点是均匀插入的。取值范围为[0,1]。

sharpness_angle
这个参数控制尖锐特征的平滑程度。
neighbor_radius
通常,采样点的邻域至少应该包括一个相邻采样点环。使用小的邻域可能无法插入新的点。使用大的邻域可以填补小的洞,但插入边缘的点可能是不规则的。如果该参数值设置为默认值或小于零,函数将使用邻域点的密度进行估计。
#include <vector>
#include <fstream>
#include <CGAL/Simple_cartesian.h>
#include <CGAL/IO/read_points.h>
#include <CGAL/IO/write_points.h>
#include <CGAL/edge_aware_upsample_point_set.h> // 上采样
// types
typedef CGAL::Simple_cartesian<double> Kernel;
// 用于存储点坐标和法向量的pair容器
typedef std::pair<Kernel::Point_3, Kernel::Vector_3> PointVectorPair;
int main(int argc, char* argv[])
{
const std::string input_filename = CGAL::data_file_path("cgal//before_upsample.xyz");
const char* output_filename("cgal//after_upsample.xyz");
// -----------------------读取包含点坐标和法向量的.xyz点云-------------------
std::vector<PointVectorPair> points;
if (!CGAL::IO::read_points(input_filename,std::back_inserter(points),
CGAL::parameters::point_map(CGAL::First_of_pair_property_map<PointVectorPair>())
.normal_map(CGAL::Second_of_pair_property_map<PointVectorPair>())))
{
std::cerr << "Error: cannot read file " << input_filename << std::endl;
return -1;
}
// ---------------------------------参数设置---------------------------------
const double s_angle = 25; // 平滑度,值越大越平滑,取值范围[0,90]
const double edge_s = 0; // 边缘的敏感性取值范围[0,1]
const double n_radius = 0.25; // 邻域点搜索半径
const std::size_t n_out = points.size() * 10; // 上采样后的点数
// ----------------------------------上采样----------------------------------
CGAL::edge_aware_upsample_point_set<CGAL::Parallel_if_available_tag>(points,std::back_inserter(points),
CGAL::parameters::point_map(CGAL::First_of_pair_property_map<PointVectorPair>()).
normal_map(CGAL::Second_of_pair_property_map<PointVectorPair>()).
sharpness_angle(s_angle). // 控制输出结果的平滑度,值越大越平滑,取值范围[0,90]。
edge_sensitivity(edge_s). // 边缘的敏感性取值范围[0,1],边缘敏感度越大,在尖锐边缘处插入点的有限度越高
neighbor_radius(n_radius). // 邻域点的个数,如果提供,查询点的邻域是用一个固定的球面计算的半径
// 而不是固定数量的邻居。在这种情况下,参数k用于限制每个球邻域返回点的数量(避免高密度区域的点过多)
number_of_output_points(n_out)); // 上采样后的点数
std::cout << "上采样完毕!!!" << std::endl;
// ----------------------------------保存结果--------------------------------
if (!CGAL::IO::write_points(output_filename, points,
CGAL::parameters::point_map(CGAL::First_of_pair_property_map<PointVectorPair>())
.normal_map(CGAL::Second_of_pair_property_map<PointVectorPair>())
.stream_precision(6)))
{
std::cerr << "保存失败!!!" << std::endl;
return -1;
}
return 0;
}
1、原始点云

2、上采样
如果我有一个数组:a=[1,2,3]如何随机选择数组的子集,使每个子集的元素都是唯一的?也就是说,对于a,可能的子集是:[][1][2][3][1,2][2,3][1,2,3]我无法生成所有可能的子集,因为a的实际大小非常大,所以有很多很多子集。目前,我正在使用“随机游走”的想法——对于a的每个元素,我都会“抛硬币”,如果硬币正面朝上则将其包括在内——但我不确定这是否真的对空间进行了均匀采样。感觉它偏向于中间,但这可能只是我的想法在进行模式匹配,因为会有更多中等大小的可能性。我使用的方法是否正确,或者我应该如何随机抽样?(我知道这更像是一个与语言无关的“数学”问题,但我觉得这不是真正的
2023年4月20 日,DatabendCloud经历了近两年的打磨终于发布了!🎉此次发布会由北京数变科技有限公司【DatabendLabs】联合阿里云共同举办。DatabendCloud借助于云原生数仓Databend实现了云简单易用的大数据分析场景。以下内容来自Databend联合创始人-王吟、DatabendCloud平台负责人-李亚舟以及阿里云智能资深产品运营专家-蔡亮伟,在本次发布会上的分享总结。🙋本次发布会分为三个部分:第一部分:王吟,李亚舟分享:「 云上数据变革,DatabendCloud发布」第二部分:蔡亮伟分享:「阿里云对象存储OSS, 构建企业级数据湖底座」第三部分:在阿里
做音频处理(虽然它也可以是图像处理)我有一个一维数字数组。(它们恰好是代表音频样本的16位有符号整数,这个问题同样适用于float或不同大小的整数。)为了匹配不同频率的音频(例如,将44.1kHz样本与22kHz样本混合),我需要拉伸(stretch)或压缩值数组以满足特定长度。将数组减半很简单:每隔一个样本丢弃一次。[231,8143,16341,2000,-9352,...]=>[231,16341,-9352,...]将数组宽度加倍稍微不那么简单:将每个条目加倍(或可选地在相邻的“真实”样本之间执行一些插值)。[231,8143,16341,2000,-9352,...]=>[2
我有一大组(>2000)时间序列数据,我想在浏览器中使用d3显示这些数据。D3非常适合向用户显示数据的一个子集(~100点),但我还想要一个“上下文”View(likethis)来显示整个数据集并允许用户选择作为子区域进行查看细节。但是,当尝试在d3中显示那么多点时,性能很糟糕。我觉得一个好的解决方案是选择一个数据样本,然后使用某种插值(样条、多项式等,这是我知道怎么做的部分)来绘制一条与实际数据。但是,我不清楚应该如何选择子集。数据(如下所示)具有相当平坦的区域,在这些区域需要较少的样本才能进行适当的插值,而其他区域的绝对导数非常高,需要更频繁的采样。更复杂的是,数据存在间隙(生成数
我从事音频识别演示已有一段时间了,api需要我传递采样率为8000或16000的.wav文件,所以我必须对其进行下采样。我尝试了以下两种算法。虽然他们都没有像我希望的那样解决问题,但结果存在一些差异,我希望这会使它更清楚。这是我的第一次尝试,当sampleRate%outputSampleRate=0时效果很好,但是当outputSampleRate=8000或1600时,结果音频文件是silent(表示输出数组的每个元素的值为0):functioninterleave(inputL){varcompression=sampleRate/outputSampleRate;varleng
我正在使用zapp在谷歌云上托管的服务上记录错误消息,我看到虽然成功记录了错误,但存储在谷歌云日志“消息”字段中的文本是堆栈跟踪,并且不是我记录的错误消息。示例代码:varlog*zap.Loggeriferr:=doStuff();err!=nil{log.Error(,zap.Error(err))}除了谷歌云日志记录和堆栈驱动程序将使用调用结构化日志的message字段中的zap.Error捕获的堆栈跟踪外,这工作得很好。我定义的消息出现在msg字段中,但前者似乎是主要显示在日志记录控制台中并被stackdriver用于索引错误的消息。这意味着当通过控制台浏览日志和错误时,我只能
简介:阿里云研究院,甄选了2021-2022年度的10份重磅报告,分别从数字经济、行业转型、数字县域等领域,尝试解读、并推动各行各业的转型升级,展望中国数字经济的未来,迎接数字经济发展的春天。导语我们正处在复杂的历史节点中,气候变化加剧、地缘政治动荡、局部战争冲突持续不断,尤其无情的新冠疫情长时间席卷全球,在很多国家尚未得到有效控制,全球感染人数超过5亿,几乎所有的国家和地区都受到深度影响。在全球经济一片萧条之中,数字经济展现出独特的魅力,数字化转型也成为各行各业的共识。疫情在某种程度上加速了全球产业数字化转型的步伐,数据成为了主要生产要素,也是数字时代的核心基础资源。基于数据资源,传统产业的
我有一个简单的样本混合器,在分析时我注意到大约40-50%的时间花在了重新采样上(44.1=>48kHz,他们必须做一些比lerp更复杂的事情)。当我在48kHz模式下打开播放设备(在我的例子中是DSound)时,这一步就没有了。问题是:有没有办法查询音频驱动程序的默认(native)采样率以避免重采样?我尝试搜索网络/文档但一无所获,我认为这可能是一个简单的API调用。谢谢。 最佳答案 如果您仍然好奇,我也有同样的问题,但找不到答案。有人为我指出了正确的方向,我能够获得一个用于获取播放属性的工作代码示例(Win>=Vista)。您
是否可以在windowsazurecloud上运行symfony(1.4)?我想知道的两件事是如何执行symfony任务以及symfony将缓存文件保存在哪里(blob存储?)。感谢您的回答。 最佳答案 PHP是Microsoft最近非常重视的东西,所以是的,Symfony可以在Azure之上运行,尽管文档很少,因为大多数人坚持使用Linux服务器。关于任务,WindowsAzure上有一个运行命令行任务的工具,虽然我自己还没有尝试过。http://azurephptools.codeplex.com/
我需要调整图像大小并对其重新采样,这样它们就不会变成锯齿状(我认为这称为锯齿)。我找到了一些纯VB6代码的代码(抱歉,链接丢失了),但它有点慢(2-5秒),而且我正在实时显示图片,所以我需要更快的东西。我似乎记得看过一些使用GDI+库执行此操作的示例。VB6中的示例将是理想的,但我可能可以使用其他语言的WindowsAPI调用的简单示例。 最佳答案 WIA2.0的缩放过滤器似乎做得不错。Windows®ImageAcquisitionAutomationLibraryv2.0Tool:Imageacquisitionandmanip