上一篇介绍了zookeeper的作用以及原理,这一篇我们介绍消息中间件kafka以及为什么要用kafka,什么业务场景下需要kafka,还有不同业务场景应该用哪一种消息中间件。最后还有kafka集群的搭建。注,kafka从2.8版本开始已经在逐步取消依赖zookeeper了,本文依赖zookeeper以及不依赖zookeeper改用Kraft模式都会介绍。
在说kafka是什么之前,我们应该先知道,消息中间件是什么。举个例子,大家网上买东西,现在很多时候都会放到驿站或者快递柜,而不是快递员直接送到你手上,然后你什么时候去取快递,那就是你的事了,那在这个过程中,中间的这个驿站或者快递柜,就是充当了快递中间件的角色,快递员就是生产者,而你,就是消费者了。那消息中间件,在我们系统架构的层面上去理解,就是消息先到消息中间件,然后消费者服务再去消息中间件消费消息这样的一个过程。而kafka是众多消息中间件里的其中一种。
kafka作为一个发布订阅消息系统,它有几个特性,分别是消息持久化,高吞吐,分布式,多客户端支持,实时等,适用于离线和在线的消息消费。kafka能支持百万级的消息写入和读取吞吐量,并且能在分布式环境中维护消息的顺序性和一致性。还支持数据备份和容错,可以保证数据的可靠性。在我们的系统有很多业务场景都可以用到kafka,例如:
在了解kafka原理之前,我们先把涉及到的相关基本概念先弄清楚。
基本概念差不多就这些,下面我们用图来表示一下他们之间的关系。
先宏观的说一下producer、kafka cluster、consumer三者的关系以及数据流的方向。
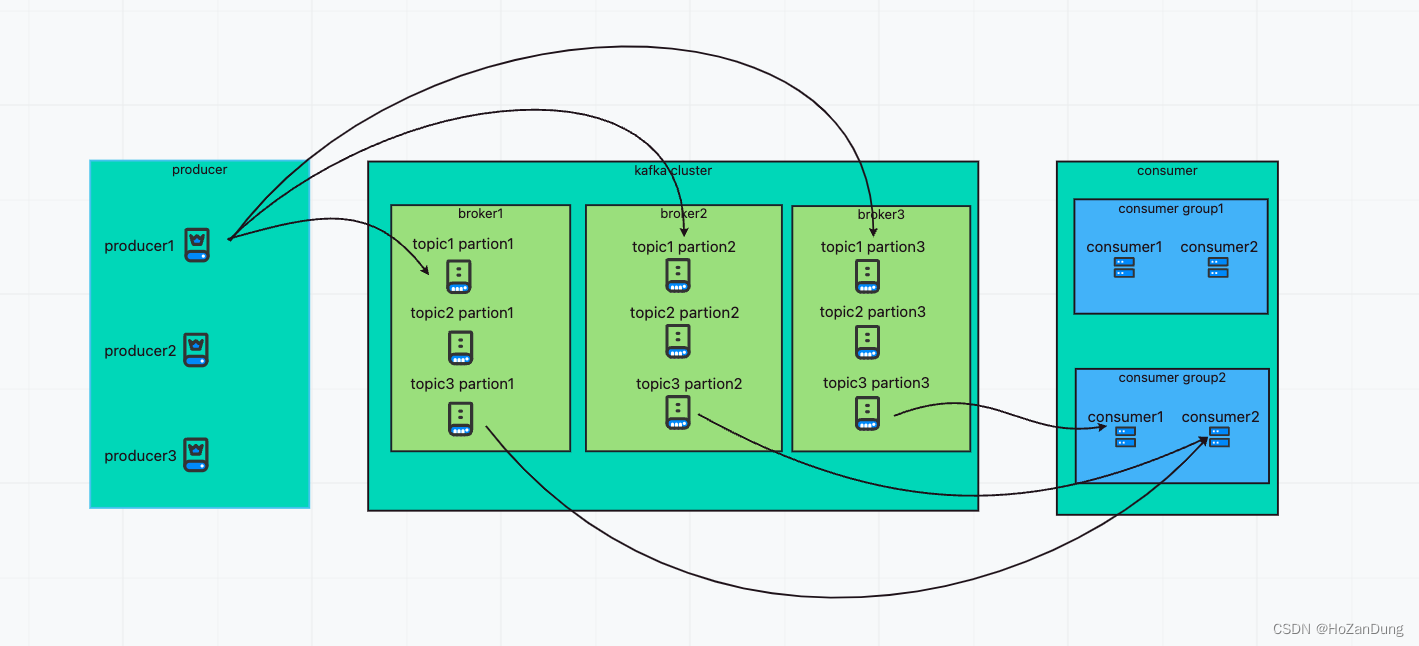
如上图表示:
然后说一下topic、partition、replication(leader)、replication(follower)之间的关系。

如上图表示:
接下来说一下broker是如何选出controller的,以及选出来的controller有什么作用。
controller可以做replication状态管理
维护的状态分为两类:
1.每台broker上的分区replication信息
2.每个分区的leader replication信息
kafka为replication定义了7种状态:
1.new replication,创建副本时的最初状态,当处于这个状态,replication只能成为follower replication。
2.online replication,replication启动后,就会变成该状态,处于这个状态,replication可变为follower或leader。
3.offline replication,replication所在的broker崩溃,会变为这个状态。
4.replication delete started,开始topic得删除操作后,topic下得所有分区replication都会变为这个状态。
5.replication deletion successful,若replication成功响应了删除replication请求,进入该状态。
6.replication deletion ineligible,replication删除失败,进入该状态。
7.non existent replication,replication删除成功,进入该状态。
replication状态流转过程:
1.topic新建时,该topic下得所有replication都是non existent replication状态。
2.controller加载zookeeper中该topic每个partition的所有replication信息到内存中,同时将该replication状态变为new replication。随后controller将该partition中的第一个replication作为leader然后所有replication被设置进入ISR(同步副本集),然后在zookeeper持久化这个信息。
3.当确定了partition的leader和ISR后,controller将这些信息以请求的方式发送给所有replication,同时将replication状态同步到集群的所有broker。最后controller将partition的所有replication状态设置为online。
4.当开始topic删除时,controller尝试停止所有replication,此时replication会停止向leader获取数据。如果停止的是leader本身,则controller会设置该partition的leader为no leader,之后replication进入offline状态。当所有replication都offline时,controller将replication状态变为deletion started表示topic删除任务开始,在这一步的过程中,controller向这些partition得broker发送请求,让他们删除本机上的replication数据。删除成功后,状态变为deletion successful。失败的会进入deletion ineligible,等待controller重试。后续会变为non existent状态,同时controller的上下文缓存会清除这个replication信息。
controller可以做partition状态管理
partiiton状态如下:
1.non existent,表示不存在或者已删除的分区。
2.new partition,partition被创建时,处于这种状态,此时kafka为该分区确认partition列表,但还没选出leader partition和ISR(同步副本集)。然后在zookeeper持久化这个信息。
3.online partition,一旦确认了leader,进入该状态,正常工作的partition都在这一个状态。
4.offline partition,在正常工作的过程中,所在broker宕机,则partition进入此状态。
partition状态流转过程:
1.新建一个topic时,controller负责创建partition对象,并设置partition为non existent,随后controller的上下文信息读取replication分配方案,最后将partition状态设置为new。
2.处于new状态的partition还没有leader和ISR,因此controller会初始化leader和ISR并设置partition状态为online,此时partition开始正常工作。
3.若用户发起topic删除或者关闭broker操作,controller会将收影响的partition设置为offline状态。如果是删除topic,controller会开启partition下所有replication的删除操作,并最终将partition设置为non existent。
所以controller的职责有几个
1.更新集群元数据信息 2.创建topic 3.删除topic 4.partition重分配 5.leader选举 6.topic扩展 7.broker加入集群 8.broker崩溃处理 9.受控关闭 10.controller leader选举
然后说一下partition和consumer之间的数量关系分别会导致什么结果。
1.consumer大于partition

同一个partition只能被同一个consumer group内的某一个consumer消费,多出来的consumer空闲。会造成资源浪费。
2.consumer小于等于partition
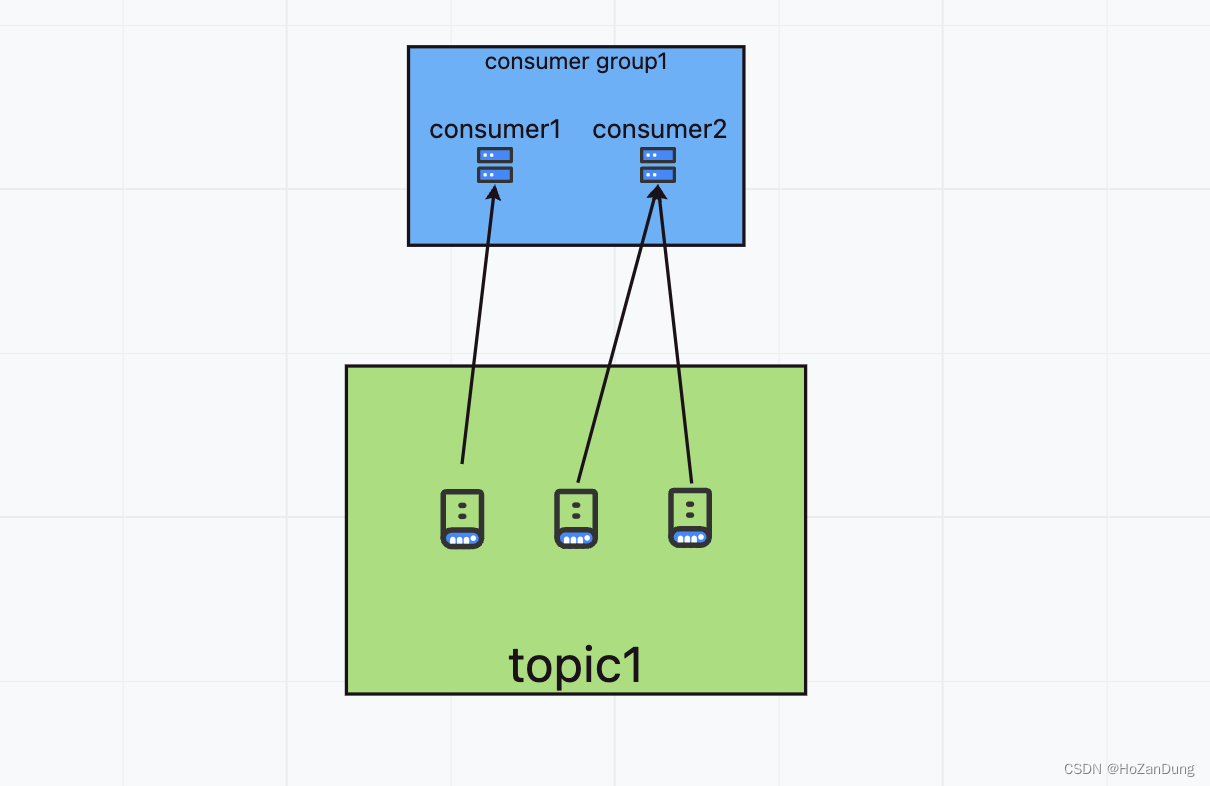
一个consumer对应多个partition,consumer2接收到的消息量是consumer1的两倍,会导致consumer group消费压力不均。多个consumer group相互隔离。
因此,consumer和partition一一对应的状态,是比较推荐的。
为什么要用zookeeper上面已经说过了,需要同步集群信息。那为什么要弃用zookeeper的原因也比较简单,一个中间件需要依赖另一个中间件。首先就比较奇怪。然后还有zookeeper有个特点,强一致性。如果zookeeper集群中的某个节点数据发生更变,那么会通知其他节点同时执行更新,那需要等超过半数都更新成功,那这写入性能就较差了。另外,zookeeper只适用于存储一些简单的配置或者集群的元数据,不是真正意义上的存储系统。如果写入数据量过大,zookeeper得性能和稳定性就会下降,可能导致watch延迟或者丢失。所以在kafka集群较大,partition也很多的时候,zookeeper的元数据就会很多,性能就很差,还有zookeeper也是分布式,也是走选举这种逻辑的,他的选举也不是特别快,而且发生选举的时候,整个集群是不对外提供服务的。
因此,kafka没有zookeeper之后,就把元数据存储到自己内部,利用之前的log存储机制来保存元数据。会有一个元数据topic,元数据会像普通message一样保存在log里面,另外还搞了个KRaft来实现controller quorum。
依赖zookeeper和不依赖zookeeper在下面的搭建过程中均有涉及。
这次我们还是用server02、server03、server04来搭建,因为上一篇已经搭建了zookeeper集群了,我们先搭建有zookeeper的版本,然后再搭建没有zookeeper的版本。其实也就是docker-compose配置的不同而已,因为是用docker-compose,down掉也比较容易。
第一步先去dns服务器配好我们的kafka域名解析,
kafka01.xdeas.com.cn、zookeeper01.com.cn
kafka02.xdeas.com.cn、zookeeper02.com.cn
kafka03.xdeas.com.cn、zookeeper02.com.cn
分别对应我们的server02、server03、server04。
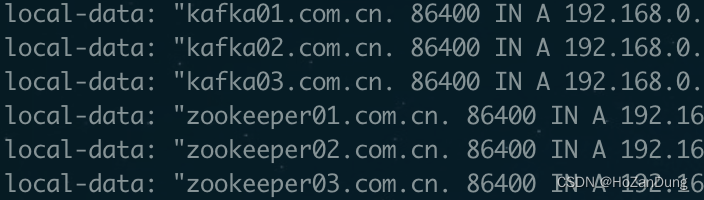
zookeeper版本:
我们还是先创建好需要的文件夹。

然后写我们的docker-compose.yaml文件
配置文件中有不一样的地方如图所示。然后跑一下 docker-compose up -d 就可以了。
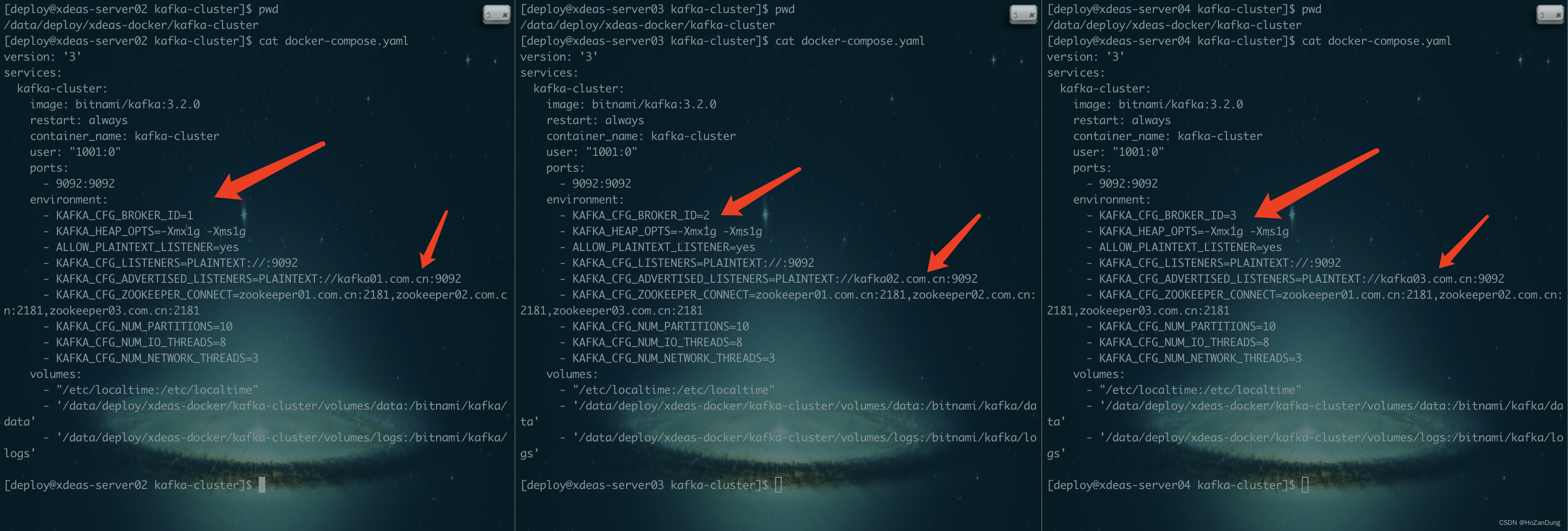
这里贴出三份配置文件
server02
version: '3'
services:
kafka-cluster:
image: bitnami/kafka:3.2.0
restart: always
container_name: kafka-cluster
user: "1001:0"
ports:
- 9092:9092
environment:
- KAFKA_CFG_BROKER_ID=1
- KAFKA_HEAP_OPTS=-Xmx1g -Xms1g
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka01.com.cn:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper01.com.cn:2181,zookeeper02.com.cn:2181,zookeeper03.com.cn:2181
- KAFKA_CFG_NUM_PARTITIONS=10
- KAFKA_CFG_NUM_IO_THREADS=8
- KAFKA_CFG_NUM_NETWORK_THREADS=3
volumes:
- "/etc/localtime:/etc/localtime"
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/data:/bitnami/kafka/data'
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/logs:/bitnami/kafka/logs'server03
version: '3'
services:
kafka-cluster:
image: bitnami/kafka:3.2.0
restart: always
container_name: kafka-cluster
user: "1001:0"
ports:
- 9092:9092
environment:
- KAFKA_CFG_BROKER_ID=2
- KAFKA_HEAP_OPTS=-Xmx1g -Xms1g
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka02.com.cn:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper01.com.cn:2181,zookeeper02.com.cn:2181,zookeeper03.com.cn:2181
- KAFKA_CFG_NUM_PARTITIONS=10
- KAFKA_CFG_NUM_IO_THREADS=8
- KAFKA_CFG_NUM_NETWORK_THREADS=3
volumes:
- "/etc/localtime:/etc/localtime"
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/data:/bitnami/kafka/data'
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/logs:/bitnami/kafka/logs'server04
version: '3'
services:
kafka-cluster:
image: bitnami/kafka:3.2.0
restart: always
container_name: kafka-cluster
user: "1001:0"
ports:
- 9092:9092
environment:
- KAFKA_CFG_BROKER_ID=3
- KAFKA_HEAP_OPTS=-Xmx1g -Xms1g
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka03.com.cn:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper01.com.cn:2181,zookeeper02.com.cn:2181,zookeeper03.com.cn:2181
- KAFKA_CFG_NUM_PARTITIONS=10
- KAFKA_CFG_NUM_IO_THREADS=8
- KAFKA_CFG_NUM_NETWORK_THREADS=3
volumes:
- "/etc/localtime:/etc/localtime"
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/data:/bitnami/kafka/data'
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/logs:/bitnami/kafka/logs'搭建成功之后,我们上去zookeeper查看broker信息。
通过 docker exec -ti zookeeper /bin/bash zkCli.sh -server 进入zk客户端
然后 ls /brokers/ids 看见如下图[1,2,3]就行了,注意这个[/brokers/ids]路径,如果你kafka启动的docker-compose文件里面zookeeper路径是zookeeper.com.cn:2181/kafka,你ls的路径就是/kafka/brokers/ids。

Kraft版本:
接下来我们搭建不依赖zookeeper的版本,由于我懒得搭两个kafka了,所以我们先docker-compose down掉之前的kafka。然后进入volumes文件夹把data文件夹里面的内容删掉。然后把上一份docker-compose.yaml文件改名改成zookeeper_version.yaml备份一下然后cp一份docker-compose出来就行了。我们直接改docker-compose.yaml文件的内容。

Kraft版本的docker-compose内容,最后的那个cluster id,必须一致。必填
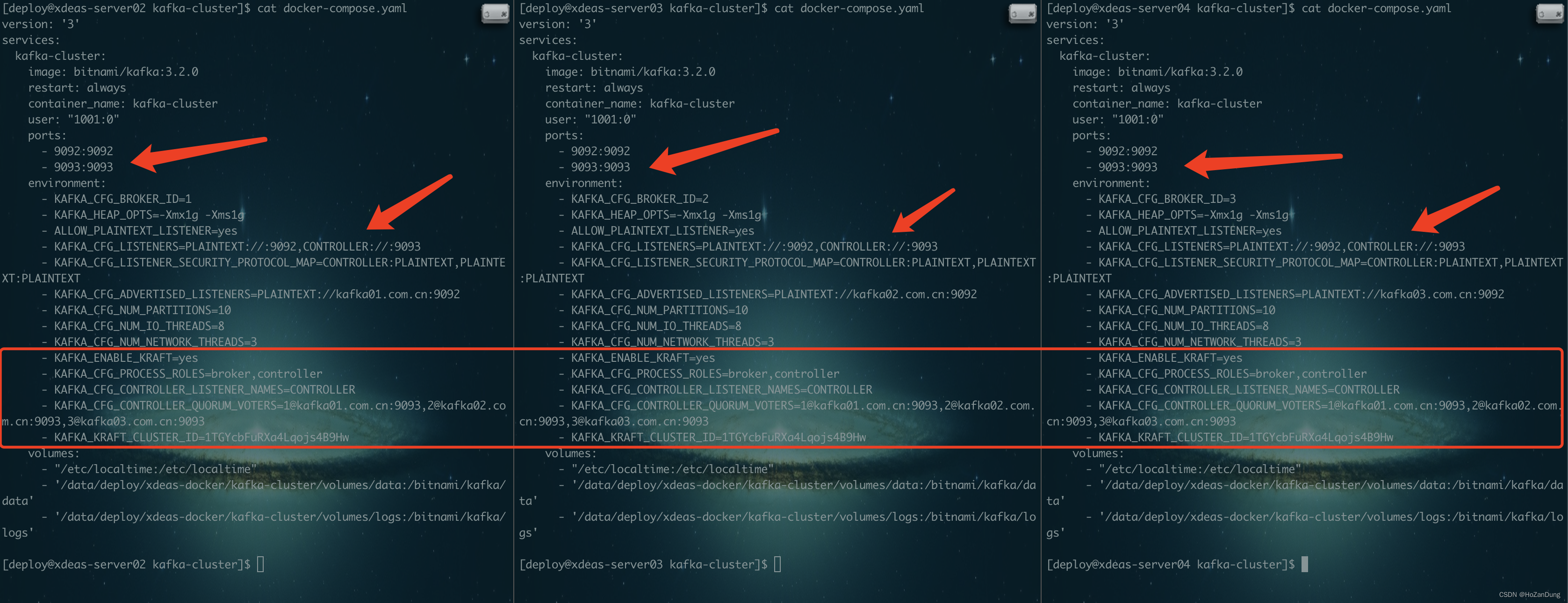
改动已经在图中用箭头以及红框指出。这里贴出三份配置文件。
server02
version: '3'
services:
kafka-cluster:
image: bitnami/kafka:3.2.0
restart: always
container_name: kafka-cluster
user: "1001:0"
ports:
- 9092:9092
- 9093:9093
environment:
- KAFKA_CFG_BROKER_ID=1
- KAFKA_HEAP_OPTS=-Xmx1g -Xms1g
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka01.com.cn:9092
- KAFKA_CFG_NUM_PARTITIONS=10
- KAFKA_CFG_NUM_IO_THREADS=8
- KAFKA_CFG_NUM_NETWORK_THREADS=3
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01.com.cn:9093,2@kafka02.com.cn:9093,3@kafka03.com.cn:9093
- KAFKA_KRAFT_CLUSTER_ID=1TGYcbFuRXa4Lqojs4B9Hw
volumes:
- "/etc/localtime:/etc/localtime"
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/data:/bitnami/kafka/data'
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/logs:/bitnami/kafka/logs'server03
version: '3'
services:
kafka-cluster:
image: bitnami/kafka:3.2.0
restart: always
container_name: kafka-cluster
user: "1001:0"
ports:
- 9092:9092
- 9093:9093
environment:
- KAFKA_CFG_BROKER_ID=2
- KAFKA_HEAP_OPTS=-Xmx1g -Xms1g
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka02.com.cn:9092
- KAFKA_CFG_NUM_PARTITIONS=10
- KAFKA_CFG_NUM_IO_THREADS=8
- KAFKA_CFG_NUM_NETWORK_THREADS=3
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01.com.cn:9093,2@kafka02.com.cn:9093,3@kafka03.com.cn:9093
- KAFKA_KRAFT_CLUSTER_ID=1TGYcbFuRXa4Lqojs4B9Hw
volumes:
- "/etc/localtime:/etc/localtime"
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/data:/bitnami/kafka/data'
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/logs:/bitnami/kafka/logs'server04
version: '3'
services:
kafka-cluster:
image: bitnami/kafka:3.2.0
restart: always
container_name: kafka-cluster
user: "1001:0"
ports:
- 9092:9092
- 9093:9093
environment:
- KAFKA_CFG_BROKER_ID=3
- KAFKA_HEAP_OPTS=-Xmx1g -Xms1g
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka03.com.cn:9092
- KAFKA_CFG_NUM_PARTITIONS=10
- KAFKA_CFG_NUM_IO_THREADS=8
- KAFKA_CFG_NUM_NETWORK_THREADS=3
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@kafka01.com.cn:9093,2@kafka02.com.cn:9093,3@kafka03.com.cn:9093
- KAFKA_KRAFT_CLUSTER_ID=1TGYcbFuRXa4Lqojs4B9Hw
volumes:
- "/etc/localtime:/etc/localtime"
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/data:/bitnami/kafka/data'
- '/data/deploy/xdeas-docker/kafka-cluster/volumes/logs:/bitnami/kafka/logs'docker-compose up -d

至此,zookeeper版本和Kraft版本都已搭建成功。请勿直接复制,各配置请根据个人情况稍作修改。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我使用irb。下面是我写的代码。“斧头”..“bc”我期待"ax""ay""az""ba"bb""bc"但结果只是“斧头”..“bc”我该如何纠正?谢谢。 最佳答案 >puts("ax".."bc").to_aaxayazbabbbc 关于ruby-从结束值创建一系列字符串,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7617092/
我有一个Ruby数组[1,4]。我想在中间插入另一个数组[2,3],这样它就变成了[1,2,3,4]。我可以使用[1,4].insert(1,[2,3]).flatten实现这一点,但是有更好的方法吗? 最佳答案 您可以通过以下方式进行。[1,4].insert(1,*[2,3])insert()方法处理多个参数。因此,您可以使用splat运算符*将数组转换为参数。 关于ruby-如何在数组中间插入一个数组?,我们在StackOverflow上找到一个类似的问题:
使用RubyonRails,我使用给定的增量(例如每30分钟)用时间填充“选择”。目前我正在YAML文件中写出所有的可能性,但我觉得有一种更巧妙的方法。我想我想提供一个开始时间、一个结束时间、一个增量,并且目前只提供一个名为“关闭”的选项(想想“business_hours”)。所以,我的选择可能会显示:'Closed'5:00am5:30am6:00am...[allthewayto]...11:30pm谁能想出更好的方法,或者只是将它们全部“拼写”出来的最佳方法? 最佳答案 此答案基于@emh的答案。defcreate_hour
我正在尝试使用docker运行一个Rails应用程序。通过github的sshurl安装的gem很少,如下所示:Gemfilegem'swagger-docs',:git=>'git@github.com:xyz/swagger-docs.git',:branch=>'my_branch'我在docker中添加了keys,它能够克隆所需的repo并从git安装gem。DockerfileRUNmkdir-p/root/.sshCOPY./id_rsa/root/.ssh/id_rsaRUNchmod700/root/.ssh/id_rsaRUNssh-keygen-f/root/.ss
在rails开发环境中,cache_classes是关闭的,所以你可以修改app/下的代码,不用重启服务器就可以看到变化。不过,在所有环境中,中间件只会创建一次。所以如果我有这样的中间件:classMyMiddlewaredefinitialize(app)@app=appenddefcall(env)env['model']=MyModel.firstendend我在config/environments/development.rb中执行此操作:config.cache_classes=false#thedefaultfordevelopmentconfig.middleware.