【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事
【SQL开发实战技巧】系列(二):简单单表查询
【SQL开发实战技巧】系列(三):SQL排序的那些事
【SQL开发实战技巧】系列(四):从执行计划讨论UNION ALL与空字符串&UNION与OR的使用注意事项
【SQL开发实战技巧】系列(五):从执行计划看IN、EXISTS 和 INNER JOIN效率,我们要分场景不要死记网上结论
【SQL开发实战技巧】系列(六):从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率,记住内外关联条件不要乱放
【SQL开发实战技巧】系列(七):从有重复数据前提下如何比较出两个表中的差异数据及对应条数聊起
【SQL开发实战技巧】系列(八):聊聊如何插入数据时比约束更灵活的限制数据插入以及怎么一个insert语句同时插入多张表
【SQL开发实战技巧】系列(九):一个update误把其他列数据更新成空了?Merge改写update!给你五种删除重复数据的写法!
【SQL开发实战技巧】系列(十):从拆分字符串、替换字符串以及统计字符串出现次数说起
【SQL开发实战技巧】系列(十一):拿几个案例讲讲translate|regexp_replace|listagg|wmsys.wm_concat|substr|regexp_substr常用函数
【SQL开发实战技巧】系列(十二):三问(如何对字符串字母去重后按字母顺序排列字符串?如何识别哪些字符串中包含数字?如何将分隔数据转换为多值IN列表?)
【SQL开发实战技巧】系列(十三):讨论一下常用聚集函数&通过执行计划看sum()over()对员工工资进行累加
【SQL开发实战技巧】系列(十四):计算消费后的余额&计算银行流水累计和&计算各部门工资排名前三位的员工
【SQL开发实战技巧】系列(十五):查找最值所在行数据信息及快速计算总和百之max/min() keep() over()、fisrt_value、last_value、ratio_to_report
【SQL开发实战技巧】系列(十六):数据仓库中时间类型操作(初级)日、月、年、时、分、秒之差及时间间隔计算
【SQL开发实战技巧】系列(十七):数据仓库中时间类型操作(初级)确定两个日期之间的工作天数、计算—年中周内各日期出现次数、确定当前记录和下一条记录之间相差的天数
【SQL开发实战技巧】系列(十八):数据仓库中时间类型操作(进阶)INTERVAL、EXTRACT以及如何确定一年是否为闰年及周的计算
【SQL开发实战技巧】系列(十九):数据仓库中时间类型操作(进阶)如何一个SQL打印当月或一年的日历?如何确定某月内第一个和最后—个周内某天的日期?
【SQL开发实战技巧】系列(二十):数据仓库中时间类型操作(进阶)获取季度开始结束时间以及如何统计非连续性时间的数据
【SQL开发实战技巧】系列(二十一):数据仓库中时间类型操作(进阶)识别重叠的日期范围,按指定10分钟时间间隔汇总数据
【SQL开发实战技巧】系列(二十二):数仓报表场景☞ 从分析函数效率一定快吗聊一聊结果集分页和隔行抽样实现方式
【SQL开发实战技巧】系列(二十三):数仓报表场景☞ 如何对数据排列组合去重以及通过如何找到包含最大值和最小值的记录这个问题再次用执行计划给你证明分析函数性能不一定高
【SQL开发实战技巧】系列(二十四):数仓报表场景☞通过案例执行计划详解”行转列”,”列转行”是如何实现的
【SQL开发实战技巧】系列(二十五):数仓报表场景☞结果集中的重复数据只显示一次以及计算部门薪资差异高效的写法以及如何对数据进行快速分组
【SQL开发实战技巧】系列(二十六):数仓报表场景☞聊聊ROLLUP、UNION ALL是如何分别做分组合计的以及如何识别哪些行是做汇总的结果行
【SQL开发实战技巧】系列(二十七):数仓报表场景☞通过对移动范围进行聚集来详解分析函数开窗原理以及如何一个SQL打印九九乘法表
【SQL开发实战技巧】系列(二十八):数仓报表场景☞人员分布问题以及不同组(分区)同时聚集如何实现
【SQL开发实战技巧】系列(二十九):数仓报表场景☞简单的树形(分层)查询以及如何确定根节点、分支节点和叶子节点
【SQL开发实战技巧】系列(三十):数仓报表场景☞树形(分层)查询如何排序?以及如何在树形查询中正确的使用where条件
【SQL开发实战技巧】系列(三十一):数仓报表场景☞分层查询如何只查询树形结构某一个分支?如何剪掉一个分支?
【SQL开发实战技巧】系列(三十二):数仓报表场景☞对表中某个字段内的值去重
【SQL开发实战技巧】系列(三十三):数仓报表场景☞从不固定位置提取字符串的元素以及搜索满足字母在前数字在后等条件的数据
【SQL开发实战技巧】系列(三十四):数仓报表场景☞如何对数据分级并行转为列
【SQL开发实战技巧】系列(三十五):数仓报表场景☞根据条件返回不同列的数据以及Left /Full Join注意事项
【SQL开发实战技巧】系列(三十六):数仓报表场景☞整理垃圾数据:查找数据的连续性时间和重叠时间的关系,初始化开始结束时间
【SQL开发实战技巧】系列(三十七):数仓报表场景☞从表内始终只有近两年的数据,要求用两列分别显示其中一年的数据聊行转列隐含信息的重要性
【SQL开发实战技巧】系列(三十八):数仓报表场景☞拆分字符串进行连接
【SQL开发实战技巧】系列(三十九):Oracle12C常用新特性☞新增分页查询
【SQL开发实战技巧】系列(四十):Oracle12C常用新特性☞可以在同样的列(列组合)上创建多个索引以及可以对DDL操作进行日志记录
【SQL开发实战技巧】系列(四十一):Oracle12C常用新特性☞APPROX_COUNT_DISTINCT以及TEMP UNDO(临时undo记录可以存储在一个临时表中)
【SQL开发实战技巧】系列(四十二):Oracle12C常用新特性☞With FUNCTION新特性
【SQL开发实战技巧】系列(四十三):Oracle12C常用新特性☞转换函数的增强和不可见字段
文章目录
博主从上大二注册CSDN以来只把CSDN当作偶尔查问题的地方,21年开始也写过几篇博客,但仅限于两三个月偶尔发一篇玩玩。工作上博主刚工作时候是做的Oracle开发DBA后来同时搞了大数据,也拿到了Oracle和华为大数据的专家认证。
日常工作生活中,经常有同事、网友咨询SQL开发和调优的各种问题,于是我下定决心做个系列的SQL开发博客文章。
这一系列文章主要是分为两块:一小块是SQL基础,一大块是企业级实战案例讲解。
我不会去给大家讲具体语法和底层实现原理,因为我感觉语法大家可以看官方文档或看其他博主博客,很多书籍配以语法简单的查询案例讲解语法,而实战特别是实际开发工作的实战SQL级的难度特少,所以我的这一系列文章重点突出讲企业SQL查询实战案例!
做完这一系列博主考虑是否开一系列SQL调优案例,但是博主还想继续开一系列hadoop、zookeeper、kafka、hbase、flume、Hive、Spark、Flink的博客文章,等做完这一系列SQL开发再考虑后续咋个安排吧!!!
接下来,给大家先分享一个本人工作中的SQL开发优化案例来作为这一系列博客的开章!!!
有下面一个SQL亟待优化
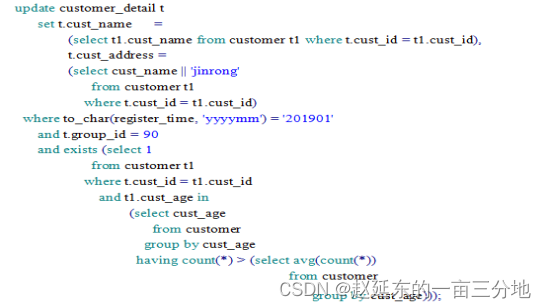
这个SQL执行计划如下
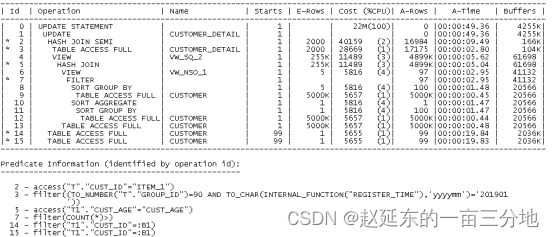
题目SQL的功能一句话概括来说是用客户表里在大于所有年龄段平均人数的年龄段范围的客户更新客户明细表中注册日期在2019年1月且客户组为90的相同客户的客户名称和客户地址。两个表均无索引,从原生SQL执行计划发现共执行了6次TABLE ACCESS FULL查询,其中CSTOMER_DETAIL表1次,CUSTOMER表5次,另外CUSTOMER表做了2次GROUP BY,在更新CUSTOMER_DETAIL表两列时,表CUSTOMER执行了2次全表扫描。
所以我们优化的切入点主要有两个:
1、减少全表扫描资源开销;
2、减少CUSTOMER表GROUP BY资源开销;
对于原生SQL,我们主要做了以下三部分优化:
1. exists (select 1
2. from customer t1
3. where t.cust_id = t1.cust_id
4. and t1.cust_age in
5. (select cust_age
6. from customer
7. group by cust_age
8. having count(*) > (select avg(count(*))
9. from customer
10. group by cust_age)));
1.exists (
2. with
3. v as (select CUST_AGE,count(*)c from zq.CUSTOMER group by CUST_AGE),
4. a as (select CUST_AGE from v where v.c > (select avg(v.c) from v)
5. ) select 1
6. from zq.customer t1
7. where t.cust_id = t1.cust_id
8. and t1.cust_age in (select CUST_AGE from a));
这个过滤条件是对年龄进行限制,过滤出客户表中,客户年龄段的总人数大于所有年龄段的平均数,这样的记录。
优化时,拆成3步走:
三个步骤一共扫描了2000W+100+100条记录,而原表通过两次全表扫描2000W+2000W。
这里我们使用WITH AS短语,在真正进行查询前预先构造了两个临时表,第一增加了SQL的易读性,结构更加清晰,第二保存在内存中,可以被多次使用,达到了“少读”的目标。观察WITH CLAUSE方法的执行计划,其中“SYS_TEMP_XXXX”便是在运行过程中构造的中间统计结果临时表。
另外,考虑到GROUP BY反复用到CUST_AGE,我们在CUST_AGE字段加了索引。
1.set t.cust_name =
- (select t1.cust_name from customer t1 where t.cust_id = t1.cust_id),
- t.cust_address =
- (select cust_name || 'jinrong'
- from customer t1
- where t.cust_id = t1.cust_id)
1.set (t.cust_name, t.cust_address) =
2. (select t1.cust_name,t1.cust_name || 'jinrong' from zq.customer t1 where t.cust_id = t1.cust_id )
原SQL进行了两次全表扫描,优化后的SQL减少一次全表扫描,提高了查询效率。cusomer和customer_detail两个表的cust_id字段经常出现在where子句中,且为两表连接的字段,所以我们建立customer.cust_id和customer_detail.cust_id两个普通索引,但观察整个执行计划,customer_detail.cust_id上的索引并未被使用。是因为where没有对cust_id进行过滤,筛选出符合条件的customer_detail表后(下面简称为A表),对A表中的每一行记录去匹配customer表,这里A表是全表扫描,customer_detail表使用了索引。所以,我们仅在customer表的cust_id列建立索引。
但并不是所有表连接操作,都只有一个索引生效,需要具体问题具体分析。
1.where to_char(register_time, 'yyyymm') = '201901' and t.group_id = 90
1.where register_time > = to_date('20190101','yyyymmdd') and register_time < to_date('20190201','yyyymmdd') and t.group_id = '90';
通过第一步对表结构的分析,group_id字段是VARCHAR(2)类型的,当比较字符型和数值型的值时,oracle会把字符型的值隐式转换为数值型,因此优化为t.group_id = ‘90’。
在group_id和register_time上建立复合索引会提高速度。但是索引列上施加函数,会造成不使用索引,因此我们改用to date函数:
2.where register_time > = to_date('20190101','yyyymmdd') and register_time < to_date('20190201','yyyymmdd') and t.group_id = '90';
另外,复合索引的字段顺序,会影响查询速度,创建复合索引做SQL优化的一般原则是,如果两个字段在WHERE子句中使用频率相同,则将最具选择性的字段排在最前面,以下是分析结果:
register_time有2000W不重复值,可唯一标识每条记录;Group_id有100个不重复值。当建立(rigister_time,group_id)索引时,首先通过索引找到20190101和20190130两个叶子节点,再范围扫描170W条数据;当建立(Group_id,Register_time)索引时,首先通过索引找到group_id为90的叶子节点,再通过索引找到201901和201930两个起始点,随后范围扫描20W条数据。
因此,建立(Grouop_id ,Register_time)复合索引的性能更优。
对原生SQL做以上三方面优化后,我们将执行时长从原来的40s+压缩到最快0.915s,随机执行5次(1.51s,2.02s,1.15s,1.05s,1.44s),平均1.43s,下面是优化后的SQL执行计划:
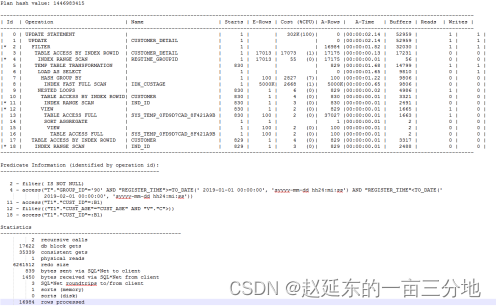
通过上面SQL优化案例我们认识到,日常SQL开发过程中应该在代码满足简单易读、易维护的前提下注意SQL的写法对资源消耗比重,扫描的数据块,重复计算量的控制。
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类