文章目录
2.6.2、可编程空信号Programmable Empty
此文仅仅对xilinx FIFO IP的参数做了详细解读,关于IP核的定制与使用方法请移步:从底层结构开始学习FPGA----FIFO IP的定制与测试
FIFO 的全称是 First In First Out,即先进先出,指的是对数据的存储具有先进先出特性的一个缓存器。FIFO与RAM 和 ROM 的区别是没有外部读写地址线,采取顺序写入数据,顺序读出数据的方式,使用起来简单方便,由此带来的缺点就是不能像 RAM 和 ROM 那样可以由地址线决定读取或写入某个指定的地址。
FIFO常被用于数据的缓存,或者高速异步数据的交互也即所谓的跨时钟域信号传递,比如 DDR 的数据读写。又或者不同位宽数据的转换,比如写入16位宽的数据,再读取8位宽的数据。
根据读、写操作是否使用同一个时钟可以把FIFO分为两类:
异步FIFO由于使用的异步时钟,所以其内部被划分为了两个时钟域--读时钟域和写时钟域。而同步FIFO的话,则只有一个时钟信号,所以其IP核内部只有一个时钟域。
xilinx 的vivado提供了免费的IP----FIFO Generate供我们使用,如下:
FIFO IP核提供了两种对外接口:
Native接口:即原始的默认接口,包括读使能、写使能,输入、输出,空、满等一系列的信号

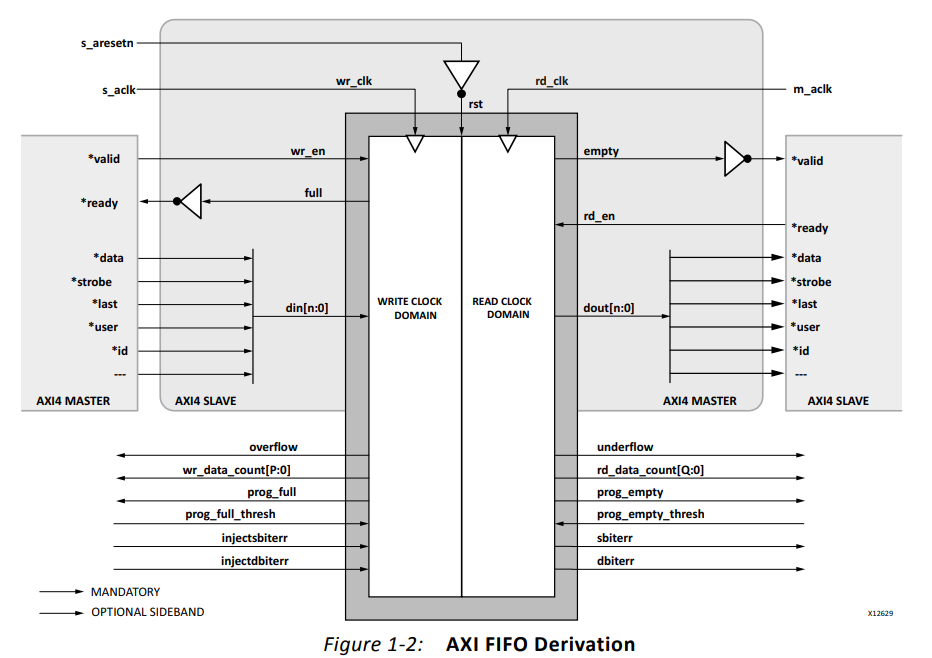
AXI4接口: AXI4接口其实是Native接口的再封装,可以实现AXI4,AXI3,AXI4-Lite和AXI4-Streaming。下图可以看到,AXI4接口的FIFO除了数据的写入、读取是采用的经典AXI4握手协议外,像空、满等信号就是直接对外输出的。关于AXI4接口,我们这里不展开说,后面有机会再更新。
FPGA内部资源丰富,所以FIFO IP核的实现也可以采用不同的资源形式:
虽然可以使用不同的资源来实现FIFO给我们提供了很大的灵活性,但是缺点也是存在的----由于实现方式的不同,不同类型组成的FIFO可以实现的功能也不一致。
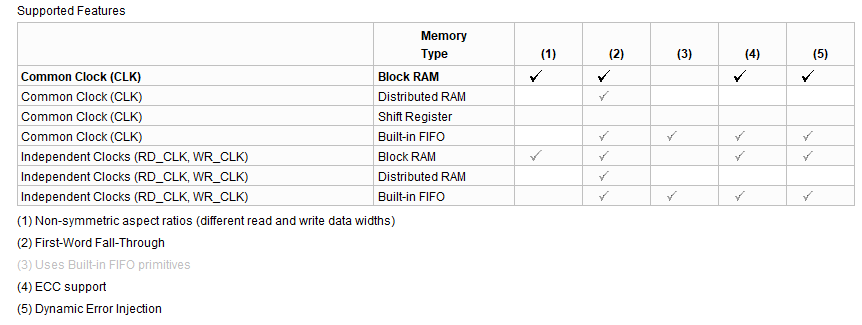
比如下表(来自FIFO IP核定制界面)中的Built-in FIF资源组成的异步FIFO,可以实2、3、4、5,但是无法实现功能1----不同的读、写数据位宽。
FIFO IP核的性能我们一般直接量化为其可以运行的最高频率,根据实现资源的不同和使用FPGA器件的不同,其性能差异很大。
限于篇幅,我们这里不举例了,有兴趣可以请查阅《pg057-fifo-generator》第2章的Performance。基本的规律就是,Virtex-7器件的FIFO>Kintex-7器件的FIFO>Artix-7器件的FIFO。
要实现FIFO的正确写操作就需要了解与写入操作有关的信号和写入的时序。以下是与写操作相关的信号。
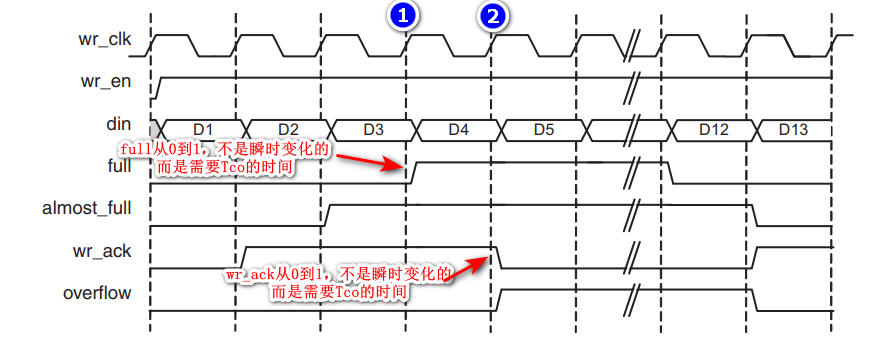
在了解写时序之前,有必要说明的一点是:数据的改变不是瞬时的,而是需要一定的时间,这个时间就是Tco。比如下图中:
了解了这两点后,我们再来看下写操作的时序图: (绿色表示写入成功,红色表示写入失败)
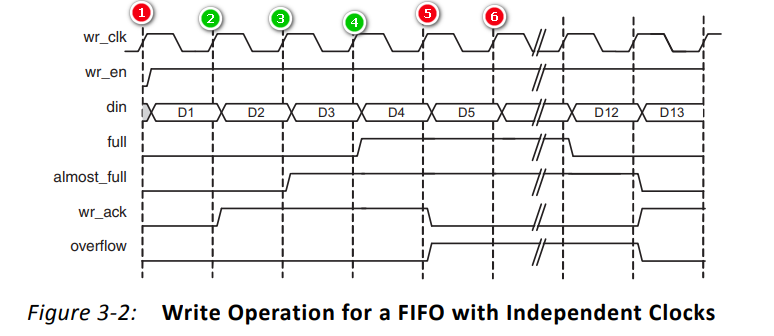
- ①:写使能wr_en为0,输入din无数据
- ②:写使能wr_en为1,输入din为D1;wr_ack被拉高,表示写入数据D1成功
- ③:写使能wr_en为1,输入din为D2;wr_ack为1,表示写入数据D2成功;almost_full拉高,表示FIFO几乎满(还可以写一个数据)
- ④:写使能wr_en为1,输入din为D3;wr_ack为1,表示写入数据D3成功;almost_full为1,表示FIFO几乎满;full拉高,表示FIFO已满,不能在写数据了
- ⑤:写使能wr_en为1,输入din为D4;wr_ack被拉低,表示写入数据D4不成功;almost_full为1,表示FIFO几乎满;full为1,表示FIFO已满;overflow被拉高,表示出现了写满(在FIFO满状态下进行写操作)操作
- ⑥:写使能wr_en为1,输入din为D5;wr_ack为0,表示写入数据D5不成功;almost_full为1,表示FIFO几乎满;full为1,表示FIFO已满;overflow为1,表示出现了写满(在FIFO满状态下进行写操作)操作
- 后续:对FIFO进行读操作后,重复进行写操作
要实现FIFO的正确读操作就需要了解与读取操作有关的信号和读取的时序。以下是与读操作相关的信号。
读操作比较特殊,分为了两种模式:标准模式(Standard)和前显模式(First-Word Fall-Through,FWFT)。
标准模式是默认模式,发出一次读指令,在一定的延迟后才会读到第一个数据。而前显模式则是在发出读取指令之前,就会把下一个会被读出的数据放到输出总线上。
前显模式看着好像很好,数据的输出没什么延迟,但是我建议你不要使用前显模式,因为前显模式的特殊性,导致其很多地方都会很奇怪,很违反直觉。比如前显模式的实际深度会比设定的要多,数据计数的准确性也会变差。
(1)标准模式(绿色表示读取成功,红色表示读取失败)
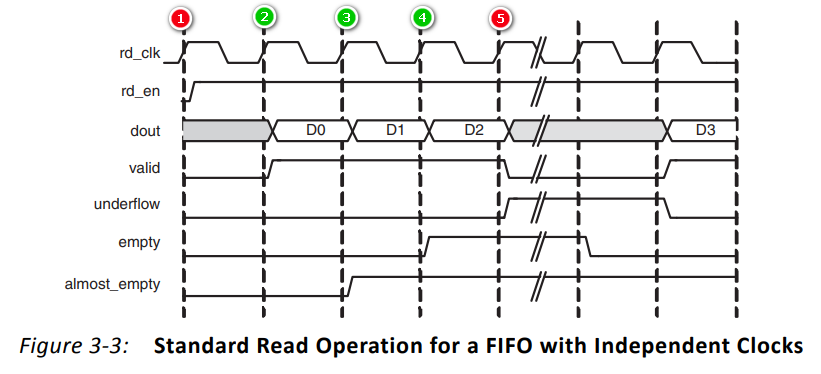
- ①:读使能rd_en为0,输出dout无数据
- ②:读使能rd_en为1,输出dout数据D0;valid被拉高,表示dout的数据是有效数据
- ③:读使能rd_en为1,输出dout数据D1;valid为1,表示dout的数据是有效数据;almost_empty被拉高,表示FIFO几乎空,仅剩一个数据
- ④:读使能rd_en为1,输出dout数据D2;valid为1,表示dout的数据是有效数据;almost_empty为1,表示FIFO几乎空;empty被拉高,表示FIFO空,所有数据都被读完了
- ⑤:读使能rd_en为1,输出dout无数据;valid被拉低,表示dout的数据是无效数据;almost_empty为1,表示FIFO几乎空;empty为1,表示FIFO空;underflow被拉高,表示在空状态下对FIFO进行了读取操作
- 后续:对FIFO进行写操作后,重复进行读操作
(2)前显模式 (绿色表示读取成功,红色表示读取失败)
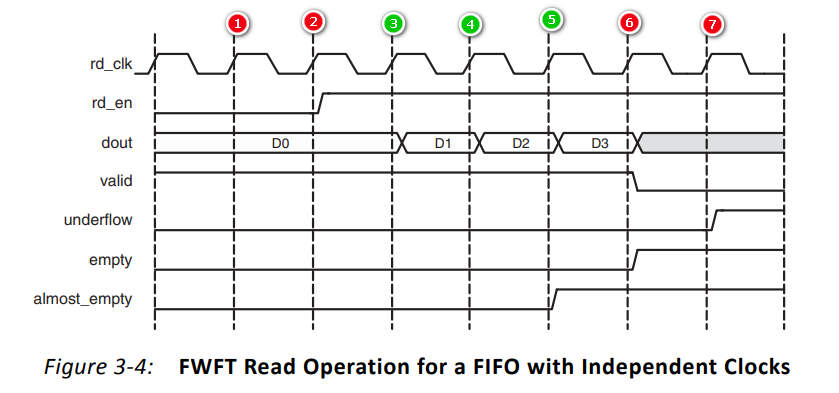
- ①:读使能rd_en为0,输出dout数据D0;valid为1,表示dout的数据是有效数据
- ②:读使能rd_en为0,输出dout数据D0;valid为1,表示dout的数据是有效数据
- ③:读使能rd_en为1,输出dout数据D1;valid为1,表示dout的数据是有效数据
- ④:读使能rd_en为1,输出dout数据D2;valid为1,表示dout的数据是有效数据
- ⑤:读使能rd_en为1,输出dout数据D3;valid为1,表示dout的数据是有效数据;almost_empty被拉高,表示FIFO几乎空,只有最后一个数据了
- ⑥:读使能rd_en为1,输出dout无数据;valid被拉低,表示dout的数据是无效数据;almost_empty为1,表示FIFO几乎空;empty被拉高,表示FIFO空,一个数据都没有了
- ⑦:读使能rd_en为1,输出dout无数据;valid为0,表示dout的数据是无效数据;almost_empty为1,表示FIFO几乎空;empty位1,表示FIFO空;underflow被拉高,表示在FIFO空状态下进行了读操作
- 后续:对FIFO进行写操作后,重复进行读操作
需要注意的是,不同于标准模式,前显模式的空信号会落后最后一个数据一个时钟周期(在标准模式,周期④读取了最后一个数据,同时空信号也被拉高;而在前显模式,周期⑤读取了最后一个数据,但是空信号却在周期⑥被拉高,落后了一个时钟周期)。
正由于前显模式的空信号时序的特殊性,使得其实际深度会比设计深度多2。
最后需要注意的是,前显模式的empty信号会在写入第一个数据的后两个时钟周期才会被拉低。
在读、写操作章节我们了解了几乎空、几乎满、空、满这四个指示FIFO中数据量的信号,但是在实际的应用中,有时候我们也需要在一些特定的时候获取FIFO的信息。比如我设计了一个深度为100的FIFO,希望能在FIFO中的数据量达到10个后就开始输出到后级,而在其数据量不满10时,希望不要对FIFO进行读取操作。这个时候FIFO的可编程空(满)信号就派上用场了。
当FIFO中的数据量到达可编程的阈值时,仍可以对FIFO继续读写,这些信号仅仅是作为一个指示信号来指示用户在某些特定条件下对FIFO进行操作。
注意:prog_full的置位会有1个时钟周期的延迟,而prog_full的释放则延迟更长,具体取决于读写时钟关系。
可编程满信号Programmable Full 提供了4类设置模式供我们使用:
下图是仅仅设定了单个可编程空阈值的时序图:

- ①:在FIFO数据量为6时,实际数据量达到阈值7,可编程满信号prog_full被拉高;其后FIFO数据一直大于等于阈值7,所以prog_full持续为1
- ②:FIFO数据小于阈值7,可编程满信号prog_full被拉低
- 注意:wr_data_count计数量有一个周期的延迟,当其为6时,FIFO中的实际数据量为7,所以为6时prog_full就会被拉高。后续此条不赘述
下图是同时设定了可编程空置位阈值和失效阈值的时序图:
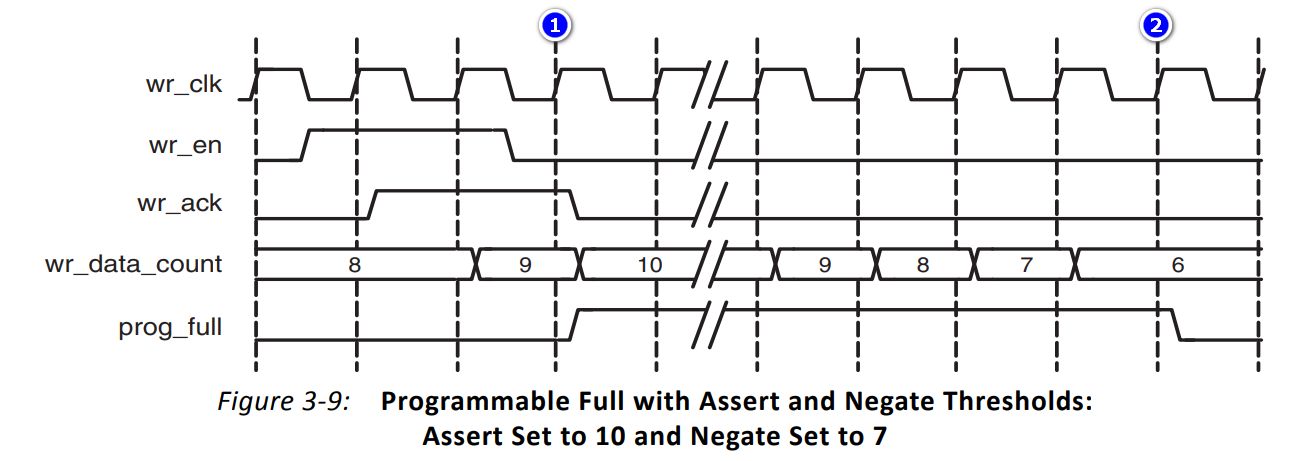
- ①:在FIFO数据量为9时,达到置位阈值10,可编程满信号prog_full被拉高;
- ②:FIFO数据小于失效阈值7,可编程满信号prog_full被拉低
- 注意:满置位值一定要大于满失效值。
可编程空信号Programmable Empty的使用方法基本与可编程满信号一致,所以不详细介绍了,只看两张时序图:
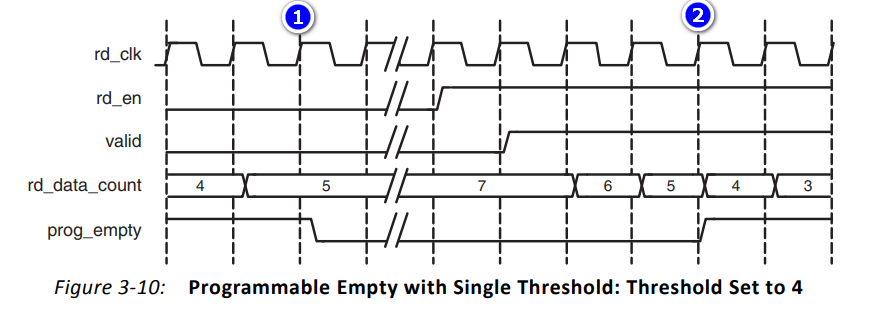
- ①:在周期①之前,FIFO数据量为4,等于可编程空的阈值4,所以prog_empty一直为高。到周期①FIFO中数量从4变为5,不在满足可编程空条件,prog_empty被拉低
- ②:当前FIFO中数据量为5,且进行了一次读操作,所以触及可编程空的阈值4,prog_empty被拉高
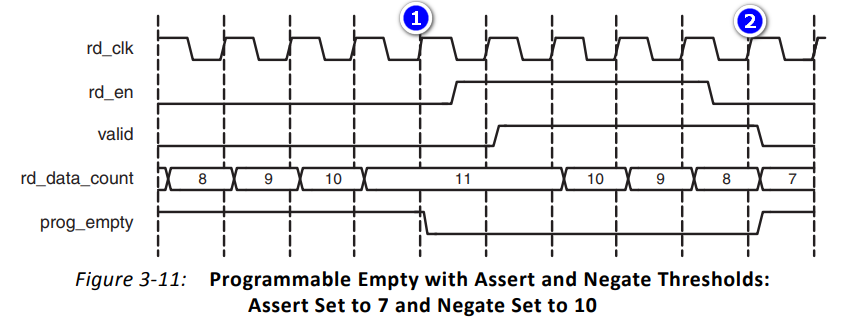
- ①:在周期①之前,FIFO数据量大于置位阈值7,所以prog_empty一直为高。到周期①FIFO数据量变为11,满足失效阈值10,所以prog_empty被拉低
- ②:当前FIFO中数据量为8,且进行了一次读操作,所以触及可编程空的置位阈值7,prog_empty被拉高
- 注意:空置位值一定要小于空失效值。
在某些应用场景下,我们可能希望可以实时追踪FIFO中的数据个数。需要注意的是:
尽管异步时钟域下的数据计数是不准确的,但却不会对FIFO功能造成影响。因为读计数和写计数都是一种保守的计数,这样做的目的是为了防止出现读空和写满,从而引发读写错误。
关于异步FIFO这部分的设计原理可以参考:关于异步FIFO设计,这7点你必须要搞清楚
转换读写位宽也是FIFO具备的一个重要的功能,我们可以一次写入16bit的数据,而一次只读出4bit的数据。读、写数据的位宽可以不同,但是必须满足比例关系:1:8, 1:4, 1:2, 1:1, 2:1, 4:1, 8:1。
在非对称的读写位宽情况下,一个必须要搞清楚的事就是数据的排序问题。
(1)写位宽 > 读位宽
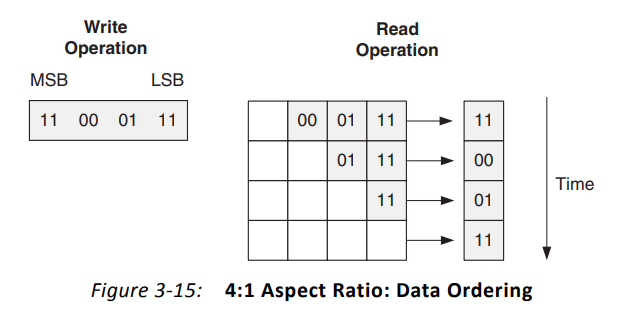
如果写入位宽8,读取位宽2,当我写入的数据是00011011,那么第一个读出来的数据是11还是00?
下图展示了写入8bit,读取2bit的数据排序情况,结果是读取是从高为MSB到低位LSB的,写入11000111,分4次读出了11--00--01--11。
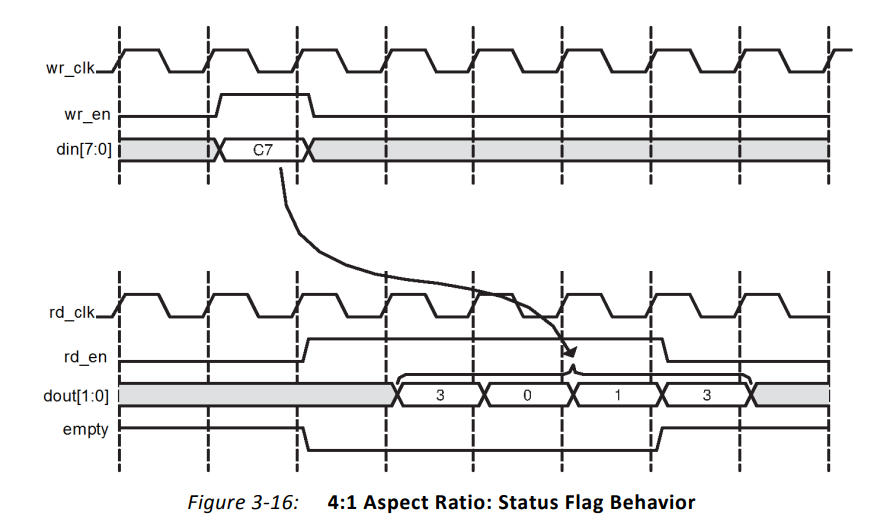
而空信号的行为也是与整个FIFO的数据量挂钩的。如下,写入8bit数据后,empty即失效,表示当前FIFO不空。当分4次,一次读取2bit,共读出8bit数据后,FIFO又恢复了空状态。
(2)写位宽 < 读位宽
同样的,如果写入位宽2,读取位宽8,当我分四次写入的数据分别是01 00 11 10,那么第一个读出来的数据是01001110还是10110001?
下图展示了写入2bit,读取8bit的数据排序情况,结果是第一次写入的数据01会在读取的最高位MSB,而第4次写入的数据10则会在读取的最低位LSB。
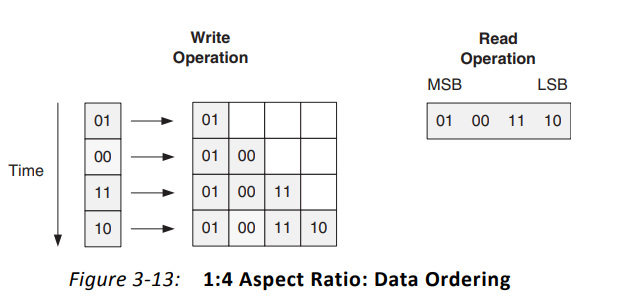
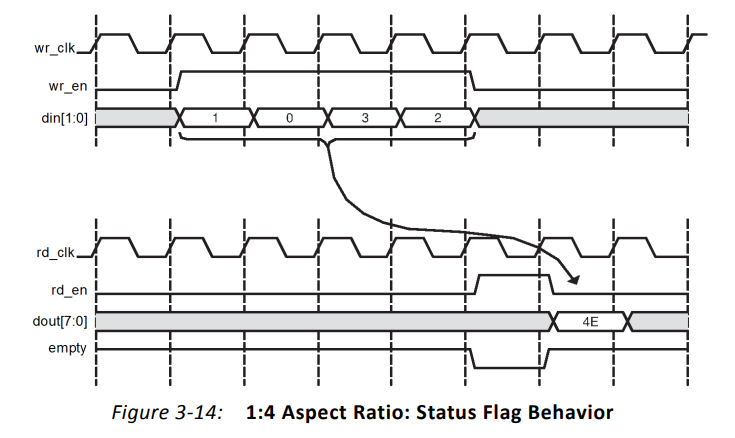
而空信号的行为也是与整个FIFO的数据量挂钩的。如下,分4次共写入8bit数据后,empty即失效,表示当前FIFO不空。当一次读取8bit数据后,FIFO又恢复了空状态。
在FPGA配置IP核后,在对FIFO进行操作前,必须对其复位。所以千万不要在上电后马上使用FIFO,而应该现将其复位,并在复位完成数个周期后才开始使用FIFO。在复位时时钟信号必须正常工作。
shift register FIFO和built-in FIFO的复位信号是不可选的,即一定存在的。对于shift register FIFO和7系列的built-in FIFO,Xilinx只提供了异步复位;而对于UltraScale,复位是同步复位信号,但提供了w_rst_busy和rd_rst_busy输出信号表示FIFO是否已经复位完毕。
Block RAM FIFO 和 Distributed RAM FIFO的复位信号是可选的。对于共用时钟的FIFO,选择同步复位和异步复位的区别主要在于是否复位信号是否和共用时钟同步;当选择异步复位时,可以Enable Safety Circuit,顾名思义就是让电路更安全,即通过复位完成信号wr_rst_busy和rd_rst_busy来表示是否FIFO已经复位完成。
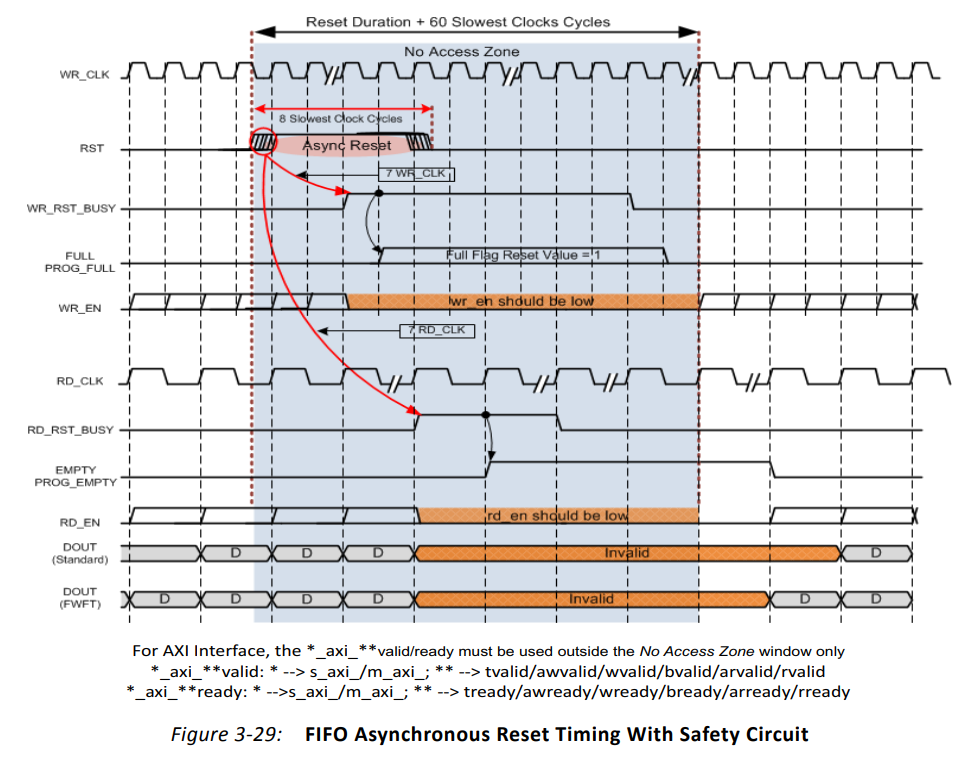
下图是一个带有安全电路的异步复位时序,我们平常使用FIFO时应该要遵守这个时序:
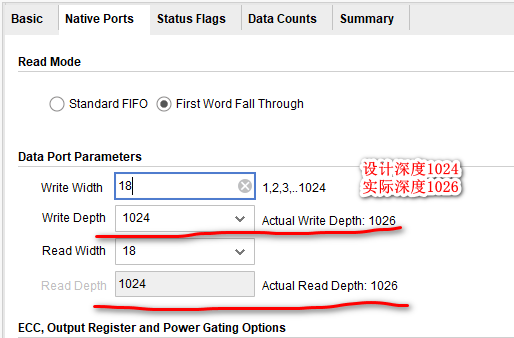
特别需要注意的一点是,由于实现方式的不同,设计的FIFO的实际深度可能会与期望值不同,我们可以在Vivado FIFO IP核的定制界面来获取实际深度的信息:
参考资料1:pg057-fifo-generator
参考资料2:ug473_7Series_Memory_Resources
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最