目录
在我们的项目开发中,我们会发现有一些数据库表字段是每个表都有的,例如 : 创建时间,创建人 ,更新时间,更新人。
而我们目前的针对这些字段我们的目前的处理方式就是 增加或者修改的时候一个一个的去赋值。

如果都按照上面的方法进行操作的话,那我们就需要在每个业务方法中进行操作,这样会不会显得我们的代码过于冗余、繁琐。
这个时候我们就可以使用Mybatis Plus提供的公共字段自动填充功能。
Mybatis Plus公共字段自动填充,也就是在插入或者更新的时候为指定字段赋予指定的值,使用它的好处就是可以统一对这些字段进行处理,避免了重复代码。
在上述的问题分析中,我们提到有四个公共字段,需要在新增/更新中进行赋值操作, 具体情况如下:
| 字段名 | 赋值时机 | 说明 |
| createTime | 插入(INSERT) | 当前时间 |
| updateTime | 插入(INSERT) , 更新(UPDATE) | 当前时间 |
| createUser | 插入(INSERT) | 当前登录用户ID |
| updateUser | 插入(INSERT) , 更新(UPDATE) | 当前登录用户ID |
接下来我们就开始编写代码。
首先第一步就是在实体类的属性上加入 @TableField 注解,指定自动填充的策略。
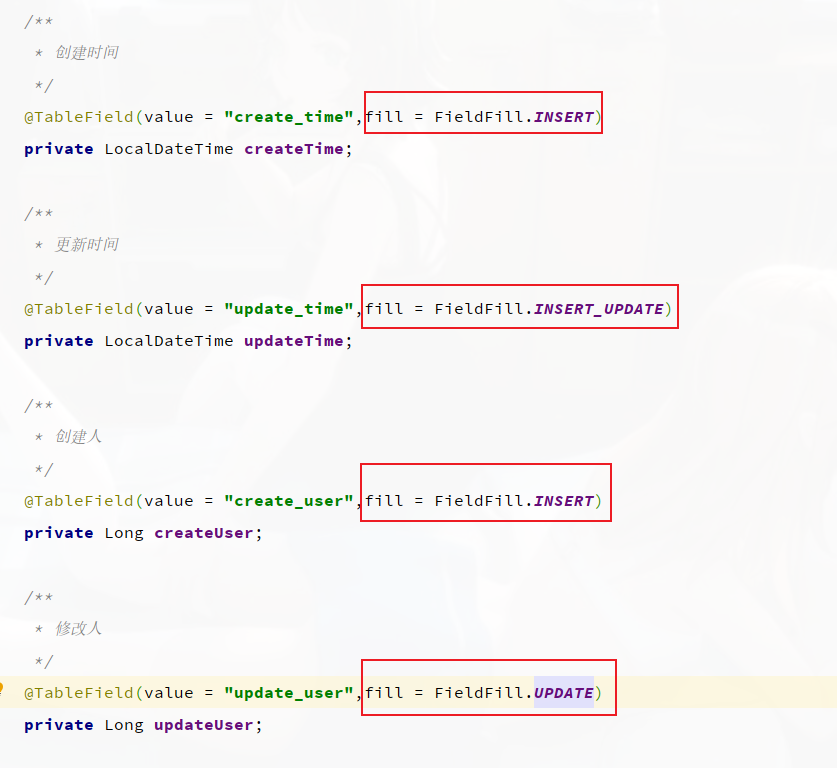
注 :
fill : 字段自动填充策略

添加好注解后,我们就需要按照框架要求编写元数据对象处理器这样的一个类,在此类中统一为公共字段赋值,注意!此类需要实现MetaObjectHandler接口。

创建好类,我们就可以开始编写操作代码了。

细心的朋友已经发现,我们上面只填充了时间,并没有填充创建人和更新人,现在我们就来完善一下。
本来我想的是,我登录的时候是将用户id存入了HttpSession中,现在我从HttpSession中获取不就行了?
但是 ,MyMetaObjectHandler类中是不能直接获得HttpSession对象的,所以我们需要通过其他方式来获取登录用户id。
这里我们使用JAVA 给我们提供的一个类,ThreadLocal。
在了解 ThreadLocal 之前我们先了解当我们在增加/修改员工信息时, 我目前项目业务的执行流程是什么样子的,如下图:

客户端发送的每次http请求,对应的在服务端都会分配一个新的线程来处理,在处理过程中涉及到下面类中的方法都属于相同的一个线程:
- LoginCheckFilter (登录过滤器) 的doFilter方法
- Controller的方法
- MyMetaObjectHandler的insertFill/updateFill方法
我们可以在上述类的方法中加入如下代码(获取当前线程ID,并输出):
long id = Thread.currentThread().getId();
log.info("线程id为:{}",id);执行功能进行验证,通过观察控制台输出可以发现,一次请求对应的线程id是相同的。
ThreadLocal并不是一个Thread,而是Thread的局部变量。当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问当前线程对应的值。
| public void set(T value) | 设置当前线程的线程局部变量的值 |
| public T get() | 返回当前线程所对应的线程局部变量的值 |
| public void remove() | 删除当前线程所对应的线程局部变量的值 |
- 我们可以先在LoginCheckFilter(登录过滤器) 的doFilter方法中获取当前登录用户id。并调用ThreadLocal的set方法来设置当前线程的线程局部变量的值(用户id)。
- 在MyMetaObjectHandler的insertFill/updateFill方法中调用ThreadLocal的get方法来获得当前线程所对应的线程局部变量的值(用户id)。
- 如果在后续的操作中, 我们需要在Controller / Service中要使用当前登录用户的ID, 可以直接从ThreadLocal直接获取。
首先为了使用方便,我们可以编写一个基于ThreadLocal封装的工具类,主要get 和 set 方法。
/**
* @description: 基于ThreadLocal封装工具类,用户保存和获取当前登录用户id
* @author: Jie
* @date: 2022/8/12 14:18
**/
public class BaseContext {
private static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
/**
* @description: 设置值
* @author: Jie
* @date: 2022/8/12 14:18
* @param: [id] 线程id
**/
public static void setCurrentId(Long id){
threadLocal.set(id);
}
/**
* @description: 获取值
* @author: Jie
* @date: 2022/8/12 14:18
**/
public static Long getCurrentId(){
return threadLocal.get();
}
}然后在LoginCheckFilter(登录过滤器)的doFilter方法中调用BaseContext来设置当前登录用户的id。
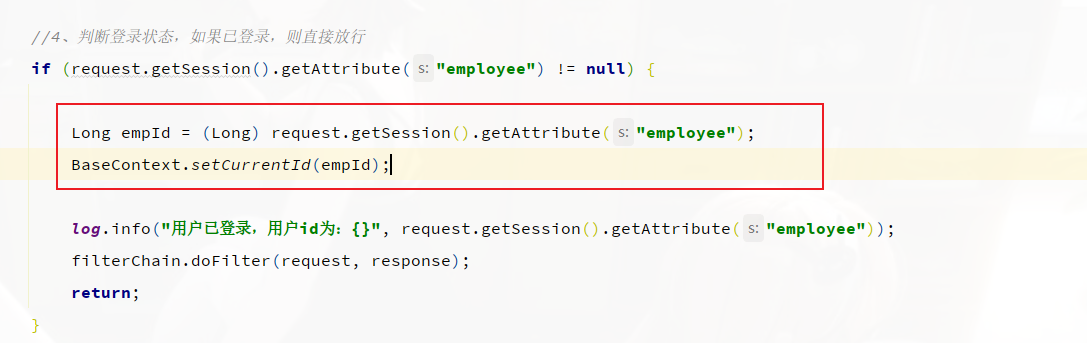
接下来我们就可以 在MyMetaObjectHandler的方法中调用BaseContext获取登录用户的id。

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解