随着低代码和无代码工具的出现,构建API比以往任何时候都更简单、更快。不过因为开发简单了,开发者很容易忽略一些潜在的问题,导致整个业务的下游影响。
在设计阶段多花点时间,可以确保API真正有用、安全、可扩展和稳定。
本文会讨论API开发者需要避免的10个常见错误,帮助我们开发更高质量的API。
API开发者需要避免的10个常见错误
1、API开发者的错误导致臃肿的响应
从编写代码的角度来看,调用返回整个对象,比返回特定的参数要容易得多。但问题是这种调用造成的问题大于其带来的价值。这些臃肿的响应参数对使用者毫无意义,还会影响两端的延迟和带宽。
所以需要在方法中建立灵活性,让使用者可以自由选择,是返回完整对象,或者所需的特定参数。
** 2、多个场景隔离调用**
单独的测试单个方法仅对单元测试有用,但这并不能保证同样的方法也能在应用生态系统中发挥作用。我们可以在单元测试中获得积极的结果,但在实际使用测试中会遇到错误。为避免此问题,我们需要在多个场景中运行每种方法,以确保效果。
3、不了解需要解决的问题
当需求与开发人员认为的问题之间存在脱节时,问题肯定会出现。这种不幸但常见的错误会让使用者失望,也会浪费我们的时间去返工重做。为了避免这个问题,需要评估整个工作流程以了解它是如何适应的。
4、API开发者的错误导致耗时的故障排除
当错误消息提示对消费者没有意义时,它会在两端造成不必要的工作。消费者必须花费数小时来解决问题。到最后,我们也不得不帮助他们,并最终进行一些返工以创建更有用的错误消息提示。我们需要通过准确地解释每一个错误的含义和出错的地方来创建有用的错误消息提示。此外,坚持使用众所周知的状态代码。
5、忽略可扩展性
随着时间的推移、使用量的增加,对系统提出了更高的要求。应用程序编程接口需要适当地处理需求和扩展。在设计阶段规划可扩展性可以帮助避免这个问题。
6、缺少帮助文档
当缺少帮助文档时,没人会深入使用我们新开发的应用程序编程接口。此问题会导致满意度降低和无休止的故障排除。提供解释如何使用API的综合帮助文档。确保文档保持最新;这让使用者知道如何使用任何功能。
7、输入验证不足
当我们没有在数据验证上花费足够的时间时,总会有人发现导致问题的漏洞。它可以简单到在看似无害的字段中传递无效数据。花点时间验证使用者发送的每个输入,以最小化发生这种情况的机会。
8、高轮询请求处理不当
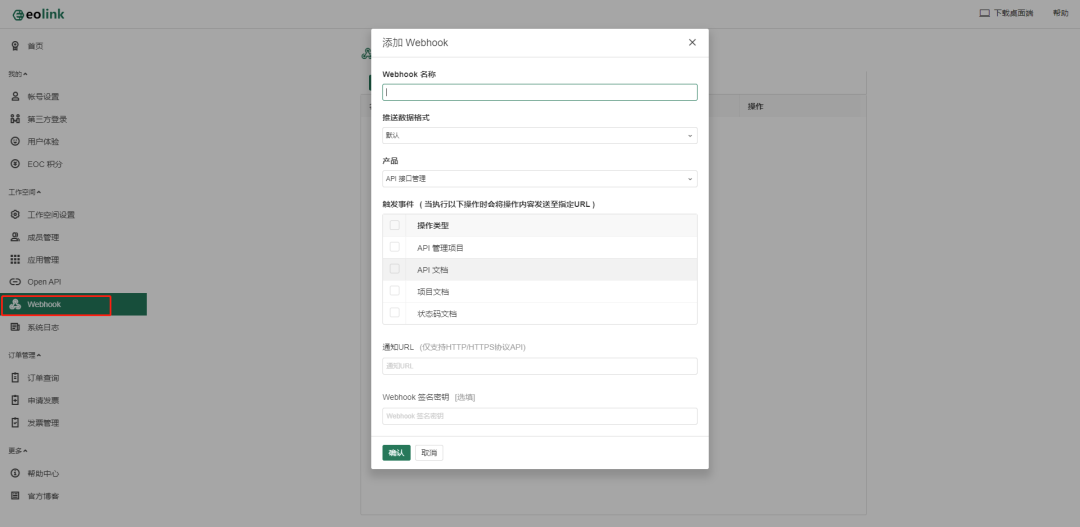
寻找最新数据的使用者高频提出请求,容易给系统带来不必要的压力。与其让客户请求更新,不如使用webhooks之类的框架,在数据发生变化时推送更新的数据。这可以减少不必要的轮询。
9、冗余端点
冗余端点是支持和重构的噩梦。当多个端点返回相同的数据时,就会发生这种API开发的错误,因为我们需要对引用该数据的所有端点进行更新。在实施新端点以支持各种用例时,请密切关注更新,确保没有端点包含可能会重复使用的相同信息。
10、没有针对性能进行优化
发送多个请求来完成一项任务会导致延迟和带宽开销。我们可以通过将这些小请求批量处理为一次调用来优化性能。这些批量的处理请求对于想要为同一进程发送大量请求的使用者非常有用。
使用 Eolink 创建功能齐全的API
开发健全的、可扩展且有用的API并不一定很复杂。如果我们遵循一些额外的步骤并避免这 10 个容易出现的API开发错误,就可以最大限度地减少返工并创建一个提供大量价值的全功能 API。除此之外,使用Eolink这类可视化的API开发工具,也可以帮助我们快速轻松地构建 API。
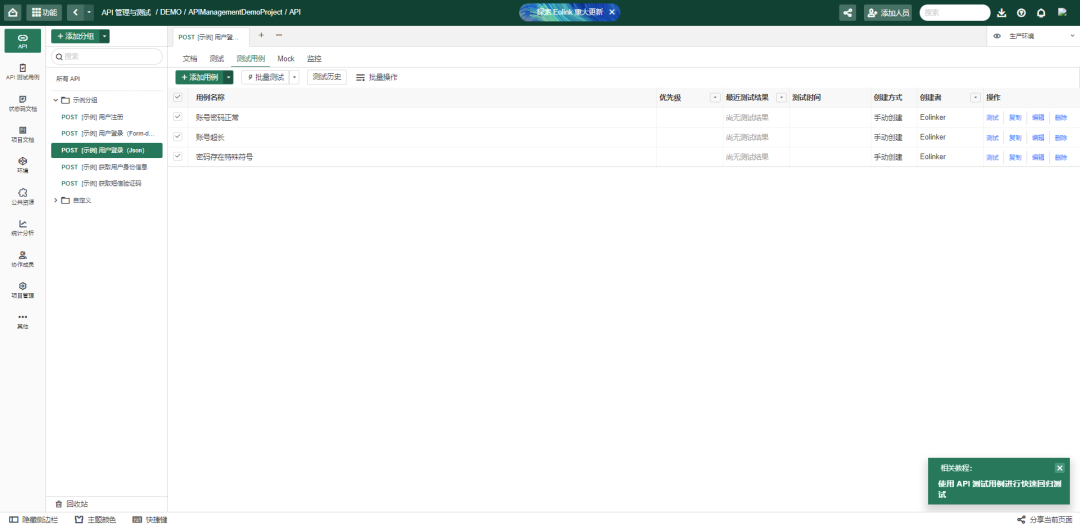
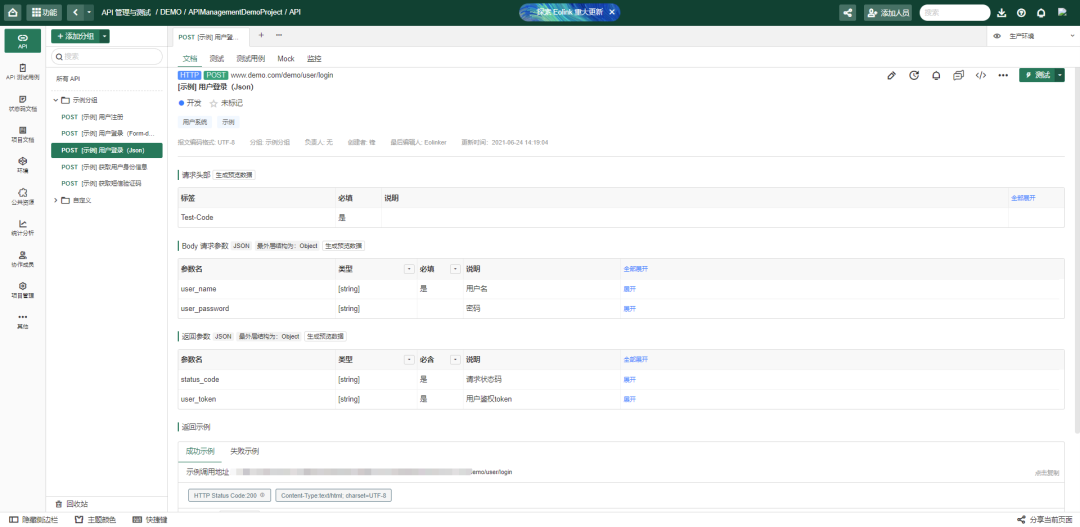
图中所使用的的接口管理工具是eolink,可以对不同类型的接口进行测试,在测试流程中也支持添加不同步骤,感兴趣可以自行使用:www.eolink.com
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我是rails的新手,想在form字段上应用验证。myviewsnew.html.erb.....模拟.rbclassSimulation{:in=>1..25,:message=>'Therowmustbebetween1and25'}end模拟Controller.rbclassSimulationsController我想检查模型类中row字段的整数范围,如果不在范围内则返回错误信息。我可以检查上面代码的范围,但无法返回错误消息提前致谢 最佳答案 关键是您使用的是模型表单,一种显示ActiveRecord模型实例属性的表单。c
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file