上一章我们聊了聊通过一致性正则的半监督方案,使用大量的未标注样本来提升小样本模型的泛化能力。这一章我们结合FGSM,FGM,VAT看下如何使用对抗训练,以及对抗训练结合半监督来提升模型的鲁棒性。本章我们会混着CV和NLP一起来说,VAT的两篇是CV领域的论文,而FGM是CV迁移到NLP的实现方案,一作都是同一位作者大大。FGM的tensorflow实现详见Github-SimpleClassification
我们会集中讨论3个问题

下面我们看下如何在模型训练过程中引入对抗样本,并训练模型给出正确的预测
这里的对抗训练和GAN这类生成对抗训练不同,这里的对抗主要指微小扰动,在CV领域可以简单解释为肉眼不可见的轻微扰动(如下图)

不过两类对抗训练的原理都可以被经典的min-max公式涵盖
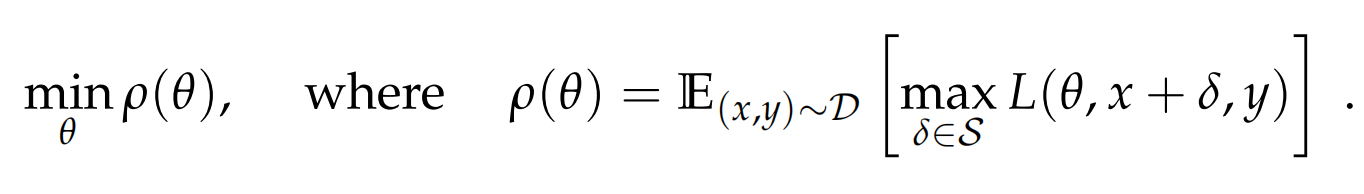
以上损失函数的视角,也可以切换成成极大似然估计的视角,也就是FGM中如下的公式,通过计算r,来使得扰动后y的条件概率最小化

于是问题就被简化成了如何计算扰动。最简单的方案就是和梯度下降相同沿用当前位置的一阶导数,梯度下降是沿graident去最小化损失,那沿反方向进行扰动不就可以最大化损失函数。不过因为梯度本身是对当前位置拟合曲线的线性化,所以需要控制步长来保证局部的线性,反向传播中我们用learning rate来控制步长,这里则需要控制扰动的大小。同时对抗扰动本身也需要控制扰动的幅度,不然就不符合微小扰动这个前提,放到NLP可以理解为为了防止扰动造成语义本身产生变化。
FGSM使用了\(l_{\infty}\) norm来对梯度进行正则化,只保留了方向信息丢弃了gradient各个维度上的scale
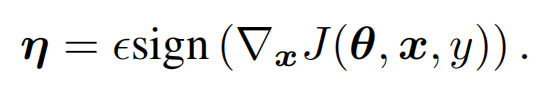
而FGM中作者选择了l2 norm来对梯度进行正则化,在梯度上更多了更多的信息,不过感觉在模型初始拟合的过程中也可能引入更多的噪音。

有了对抗样本,下一步就是如何让模型对扰动后的样本给出正确的分类结果。所以最简单的训练方式就是结合监督loss,和施加扰动之后的loss。FGSM中作者简单用0.5的权重来做融合。所以模型训练的方式是样本向前传递计算Loss,冻结梯度,计算扰动,对样本施加扰动再计算Loss,两个loss加权计算梯度。不过部分实现也有只保留对抗loss的操作,不妨作为超参对不同任务进行调整~
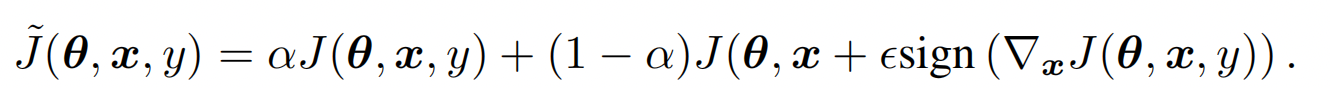
在使用对抗扰动时有两个需要注意的点
对于CV任务扰动位置有3个选择,输入层,隐藏层,或者输出层,对于NLP任务因为输入离散,所以输入层被替换成look up之后的embedding层。
作者基于万能逼近定理【简单说就是一个线性层+隐藏层如果有unit足够多可以逼近Rn上的任意函数0】指出因为输出层本身不满足万能逼近定理条件,所以对输出层(linear-softmax layer)扰动一般会导致模型underfit,因为模型会没有足够的能力来学习如何抵抗扰动。
而对于激活函数范围在[-inf, inf]的隐藏层进行扰动,会导致模型通过放大隐藏层scale来忽略扰动的影响。
因此一般是对输入层进行扰动,在下面FGM的实现中作者对word embedding进行归一化来规避上面scale的问题。不过这里有一个疑问就是对BERT这类预训练模型是不能对输入向量进行归一化的,那么如何保证BERT在微调的过程中不会通过放大输入层来规避扰动呢?后来想到的一个点是在探测Bert Finetune对向量空间的影响中提到的,微调对BERT各个层的影响是越接近底层影响越小的,所以从这个角度来说也是针对输入层做扰动更合理些~
以上的对抗训练只适用于标注样本,因为需要通过loss来计算梯度方向,而未标注样本无法计算loss,最简单的方案就是用模型预估来替代真实label。于是最大化loss的扰动,变成使得预测分布变化最大的扰动。
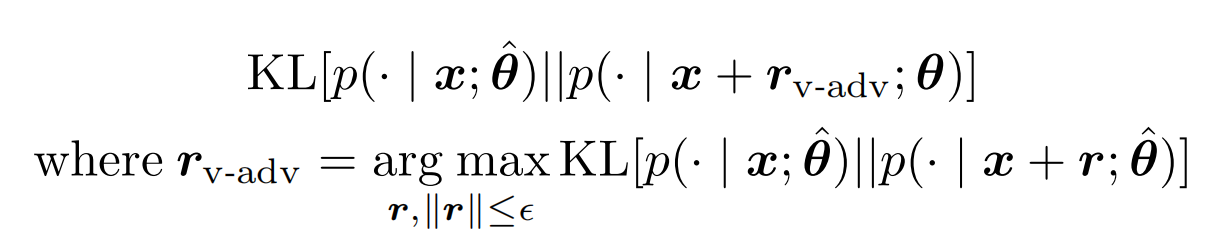
以上的虚拟扰动r无法直接计算,于是泰勒展开再次登场,不过这里因为把y替换成了模型预估p,所以一阶导数为0,于是最大化KL近似为最大化二阶导数的部分
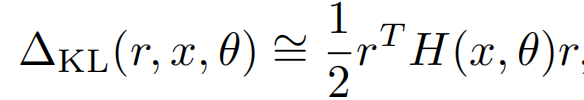
而以上r的求解,其实就是求解二阶海森矩阵的最大特征值对应的特征向量,以下u就是最大特征值对应的单位特征向量
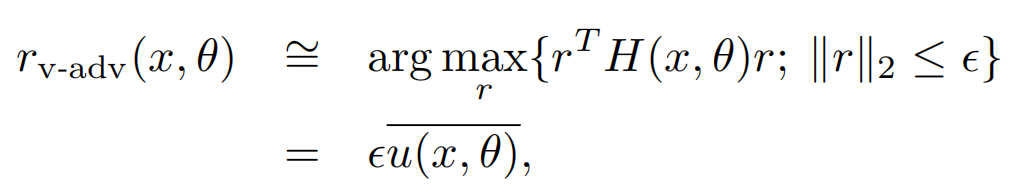
因为海森矩阵的计算复杂度较高,一般会采用迭代近似的方式来计算(详见REF12),简单说就是随机向量d(和u非正交),通过反复的下述迭代会趋近于u

而以上Hd同样可以被近似计算,因为上面KL的一阶导数为0,所以我们可以用KL~rHr的一阶差分来估计Hd,于是也就得了d的近似值
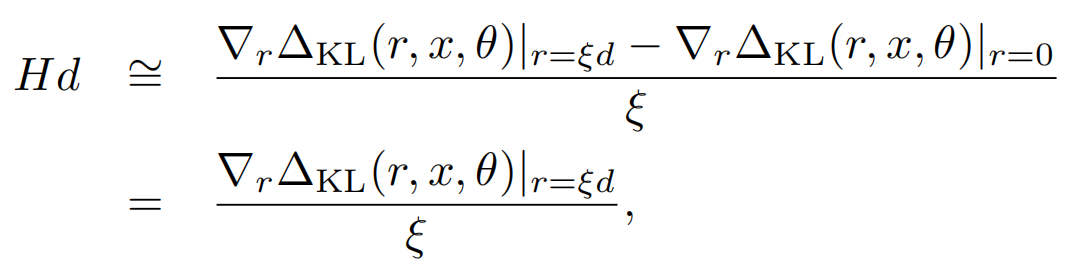
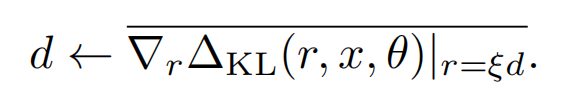

哈哈近似了一圈估计有的盆友们已经蒙圈了,可以对照着下面的计算方案再回来理解下上面的公式,计算虚拟扰动的算法如下(其中1~4可以多次迭代)
这里暂时没有实现VAT因为时间复杂度有些高,之后有需要再补上VAT的部分
对抗扰动可以理解为一种正则方案,核心是为了提高模型鲁棒性,也就是样本外的泛化能力,这里给出两个视角

这里和上一章我们提到的半监督之一致性正则有着相通之处,一致性正则强调模型应该对轻微扰动的样本给出一致的预测,但并没有对扰动本身进行太多的探讨,而对抗训练的核心在于如何对样本进行扰动。但核心都是扩充标注样本的覆盖范围,让标注样本的近邻拥有一致的模型预测。
FGM论文是在LSTM,Bi-LSTM上做的测试会有比较明显的2%左右ErrorRate的下降。我在BERT上加入FGM在几个测试集上尝试指标效果并不明显,不过这里开源数据上测试集和训练集相似度比较高,而FGM更多是对样本外的泛化能力的提升。不过我在公司数据上使用FMG输出的预测概率的置信度会显著下降,一般bert微调会容易得到0.999这类高置信度预测,而加入FGM之后prob的分布变得更加合理,这个效果更容易用正则来进行解释。以下也给出了两个比赛方案链接里面都是用fgm做了优化也有一些insights,感兴趣的朋友可能在你的测试集上也实验下~
不过一言以蔽之,FGM的对抗方案,主要通过正则来约束模型学习,更多是锦上添花,想要学中送碳建议盆友们脚踏实地的去优化样本,优化标注,以及确认你的任务目标定义是否合理~
Reference
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',