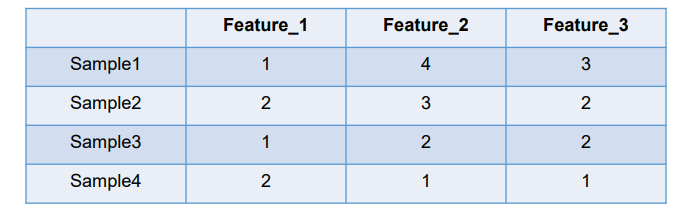
我们拿feature2来说明:这里feature2有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。

对于2种状态、3种状态、甚至更多状态都可以这样表示,所以我们可以得到这些样本特征的新表示,入下图:
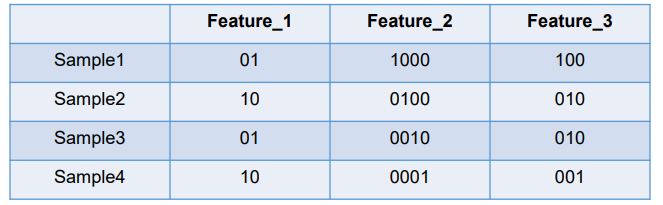
one-ho编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为
Sample_1--->[0,1,1,0,0,0,1,0,0]
Sample_2--->[1,0,0,1,0,0,0,1,0]
one hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
我们首先对预料库分词,并获取其中所有的词,然后对每个此进行编号:
1我;2爱;3爸爸;4妈妈;5中国
然后使用one hot对每段话提取特征向量:
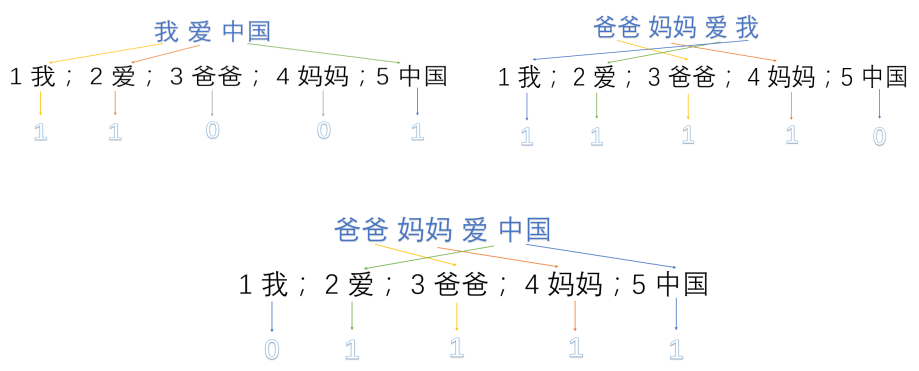
因此我们得到了最终的特征向量为
我爱中国->(1,1,0,0,1)
爸爸妈妈爱我->(1,1,1,1,0)
爸爸妈妈爱中国->(0,1,1,1,1)
优缺点分析
优点:
缺点:
import numpy as np
samples = ['他 毕业 于 哈佛大学', '他 就职 于 工科院计算机研究所']
# 分完词之后一般要将词典索引做好,一般叫token_index
token_index = {}
for sample in samples:
for word in sample.split():
if word not in token_index:
token_index[word] = len(token_index)+1
print(len(token_index))
print(token_index)
# 构造one—hot编码
results = np.zeros(shape=(len(samples), len(token_index)+1, max(token_index.values())+1))
for i, sample in enumerate(samples): # 索引
for j, word in list(enumerate(sample.split())): # 对list组进行链接
index = token_index.get(word) # 索引和word对应
print(i, j, index, word)
results[i, j, index] = 1
print(results)
# 改进的算法
results2 = np.zeros(shape=(len(samples),max(token_index.values())+1) )
for i, sample in enumerate(samples):
for _, word in list(enumerate(sample.split())):
index = token_index.get(word)
results2[i, index] = 1
print(results2)
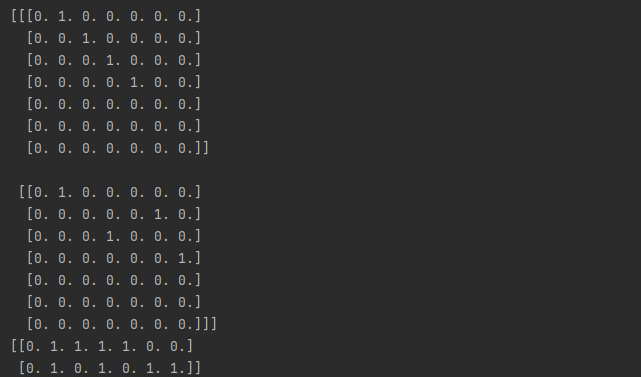
运行结果

Keras分词器Tokenizer的办法介绍
Tokenizer是一个用于向量化文本,或将文本转换为序列(即单词在字典中的下标形成的列表,从1算起)的类。Tokenizer实际上只是生成了一个字典,并且统计了词频等信息,并没有把文本转成须要的向量示意。from keras.preprocessing.text import Tokenizer引入模块tokenizer = Tokenizer()生成词典tokenizer.fit_on_texts()
string = ['他 毕业 于 哈佛大学', '他 就职 于 工科院计算机研究所']
# 构建单词索引
tokenizer = Tokenizer()
tokenizer.fit_on_texts(samples)
print(tokenizer.word_index)
将句子序列转换成token矩阵tokenizer.texts_to_matrix()
tokenizer.texts_to_matrix(samples) #如果string中的word出现在了字典中,那么在矩阵中出现的位置处标1
tokenizer.texts_to_matrix(string,mode='count') #如果string中的word出现在了字典中,那么在矩阵中出现的位置处标记这个word出现的次数
句子转换成单词索引序列tokenizer.texts_to_sequences
sequences = tokenizer.texts_to_sequences(samples)
print(sequences)
分词器被训练的文档(文本或者序列)数量tok.document_count
依照数量由大到小Order排列的token及其数量tok.word_counts
完整代码:
from keras.preprocessing.text import Tokenizer
samples = ['他 毕业 于 哈佛大学', '他 就职 于 工科院计算机研究所']
# 构建单词索引
tokenizer = Tokenizer()
tokenizer.fit_on_texts(samples)
word_index = tokenizer.word_index
print(word_index)
print(len(word_index))
sequences = tokenizer.texts_to_sequences(samples)
print(sequences)
one_hot_results = tokenizer.texts_to_matrix(samples)
print(one_hot_results)
运行结果

我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我有三个模型:classReleaseItem:pack_release_itemsendclassPack:pack_release_itemsendclassPackReleaseItem问题是,在执行期间,如果我将一个包添加到release_item,它并不知道该包是一个包。例如:Loadingdevelopmentenvironment(Rails2.1.0)>>item=ReleaseItem.new(:filename=>'MAESTRO.TXT')=>#>>pack=Pack.new(:filename=>'legion01.zip',:year=>1998)=>#>>i
我正在尝试在Ruby中复制Convert.ToBase64String()行为。这是我的C#代码:varsha1=newSHA1CryptoServiceProvider();varpasswordBytes=Encoding.UTF8.GetBytes("password");varpasswordHash=sha1.ComputeHash(passwordBytes);returnConvert.ToBase64String(passwordHash);//returns"W6ph5Mm5Pz8GgiULbPgzG37mj9g="当我在Ruby中尝试同样的事情时,我得到了相同sha
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
查看Ruby代码,它具有以下proc_arity:staticVALUEproc_arity(VALUEself){intarity=rb_proc_arity(self);returnINT2FIX(arity);}更多的是C编码风格问题,但为什么staticVALUE在单独的一行而不是像这样的:staticVALUEproc_arity(VALUEself) 最佳答案 它来自UNIX世界,因为它有助于轻松grep函数的定义:$grep-n'^proc_arity'*.c或使用vim:/^proc_arity
我创建了一个由于“在运行时执行的单例元类定义”而无法编码的对象(这段代码的描述是否正确?)。这是通过以下代码执行的:#defineclassXthatmyusesingletonclassmetaprogrammingfeatures#throughcallofmethod:break_marshalling!classXdefbreak_marshalling!meta_class=class我该怎么做才能使对象编码正确?是否可以从对象instance_of_x的classX中“移除”单例组件?我真的需要一个建议,因为我们的一些对象需要通过Marshal.dump序列化机制进行缓存。
我有以下代码,它下载一个文件,然后将文件的内容读入一个变量。使用该变量,它执行一个命令。这个配方不会收敛,因为/root/foo在编译阶段不存在。我可以通过多个聚合和一个来解决这个问题ifFile.exist但我想用一个收敛来完成它。关于如何做到这一点有什么想法吗?execute'download_joiner'docommand"awss3cps3://bucket/foo/root/foo"not_if{::File.exist?('/root/foo')}endpassword=::File.read('/root/foo').chompexecute'join_domain'd
我创建了一个文件,这样我就可以在lib/foo/bar_woo.rb中的许多模型之间共享一个方法。在bar_woo.rb中,我定义了以下内容:moduleBarWoodefhelloputs"hello"endend然后在我的模型中我正在做类似的事情:defMyModel解释器提示它期望bar_woo.rb定义Foo::BarWoo。《使用Rails进行敏捷Web开发》一书指出,如果文件包含类或模块,并且文件使用类或模块名称的小写形式命名,那么Rails将自动加载文件。因此我不需要它。定义代码的正确方法是什么,在我的模型中调用代码的正确方法是什么? 最佳答案