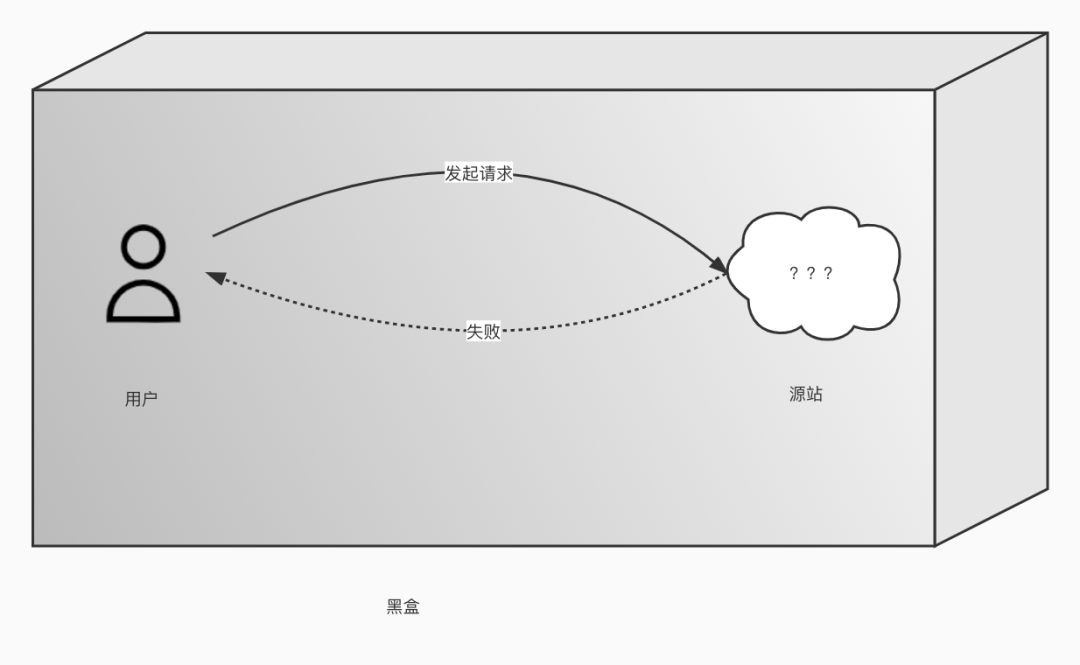
 这时候工程师大脑中会有一堆问号。简单说一下这个问题是如何排查的。
这时候工程师大脑中会有一堆问号。简单说一下这个问题是如何排查的。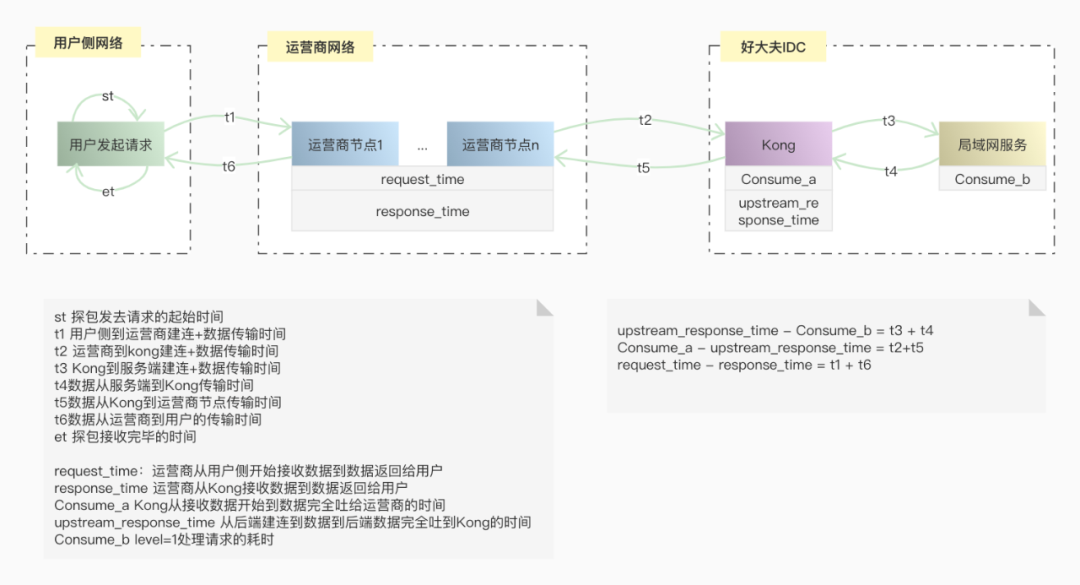 从图中可以看出,上传失败存在几个关键的环节中:用户侧、网络节点、入口网关、后端服务。
从图中可以看出,上传失败存在几个关键的环节中:用户侧、网络节点、入口网关、后端服务。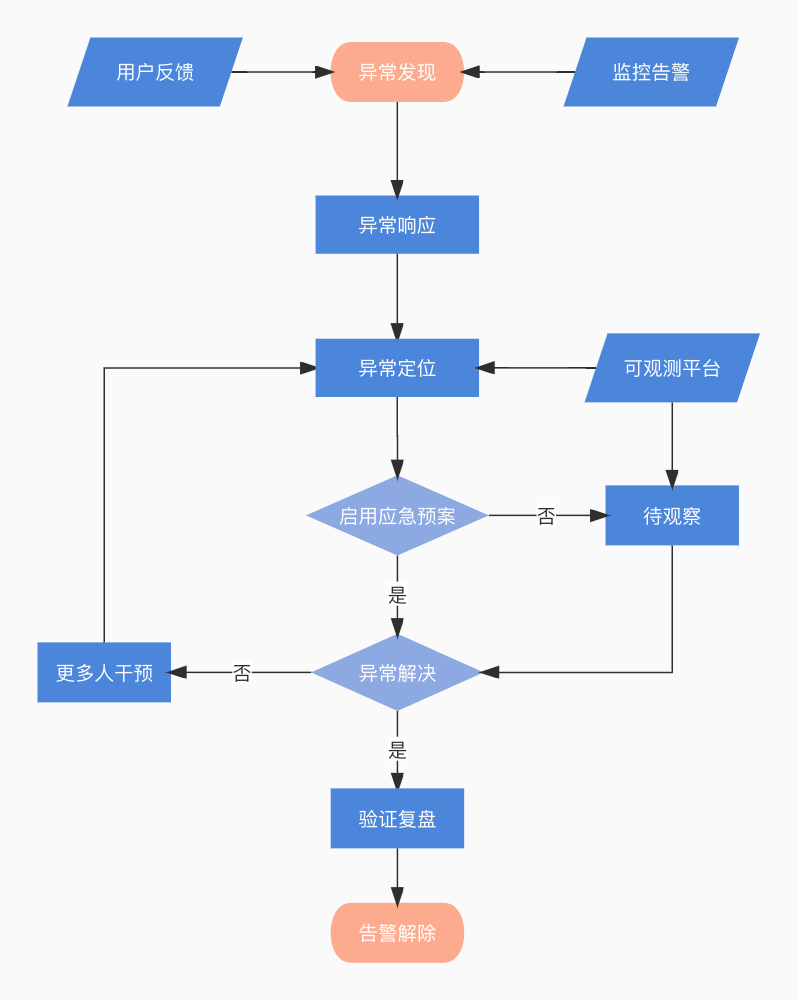 总结一下提效异常定位,首要任务就是需要量化异常,让异常可被观测到。其次就是友好的界面提示一步步引导大家定位问题。接下来一起探讨一下如何建设小程序上传图片整体链路的可观测性,去尝试建模分析异常定位这个工程问题。
总结一下提效异常定位,首要任务就是需要量化异常,让异常可被观测到。其次就是友好的界面提示一步步引导大家定位问题。接下来一起探讨一下如何建设小程序上传图片整体链路的可观测性,去尝试建模分析异常定位这个工程问题。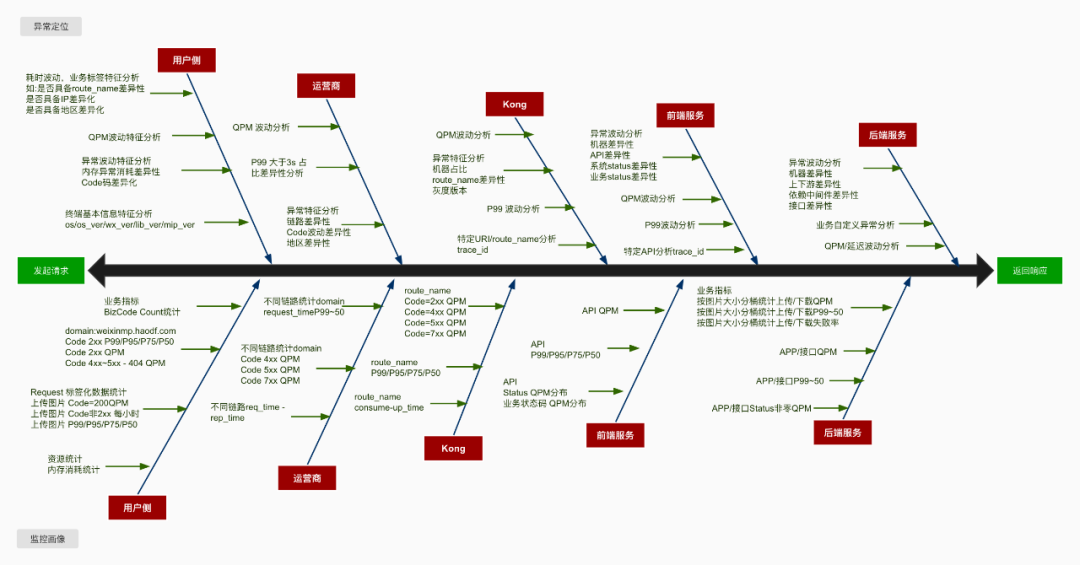 这里总结一些经验:”两点一线,分两面,一面监控画像,一面异常定位“。为了尽可能的观测各个环节,我们需要梳理一个脉络,如请求的开始到结束,抓住这两点,连成一线,分两面,一面关注长期趋势,一面关注异常分析。具体提炼 SLI 可参考 Google VALET(Volume、Available、Latency、Error、Ticket)模型。从图中我们可以看出,评估链路各个环节是否有风险或者有异常,需要一个参考系,长期的指标趋势和经验阈值都是参考的数据源。故而设置 SLO 有两种模式,第一根据经验设置固定阈值,如 QPS 峰值不得大于 10k;第二是设置相对值,如 code=404 环比增加 20%。有了这些准备工作,提炼了以下 SLI 和 SLO,大家可以参考一下。
这里总结一些经验:”两点一线,分两面,一面监控画像,一面异常定位“。为了尽可能的观测各个环节,我们需要梳理一个脉络,如请求的开始到结束,抓住这两点,连成一线,分两面,一面关注长期趋势,一面关注异常分析。具体提炼 SLI 可参考 Google VALET(Volume、Available、Latency、Error、Ticket)模型。从图中我们可以看出,评估链路各个环节是否有风险或者有异常,需要一个参考系,长期的指标趋势和经验阈值都是参考的数据源。故而设置 SLO 有两种模式,第一根据经验设置固定阈值,如 QPS 峰值不得大于 10k;第二是设置相对值,如 code=404 环比增加 20%。有了这些准备工作,提炼了以下 SLI 和 SLO,大家可以参考一下。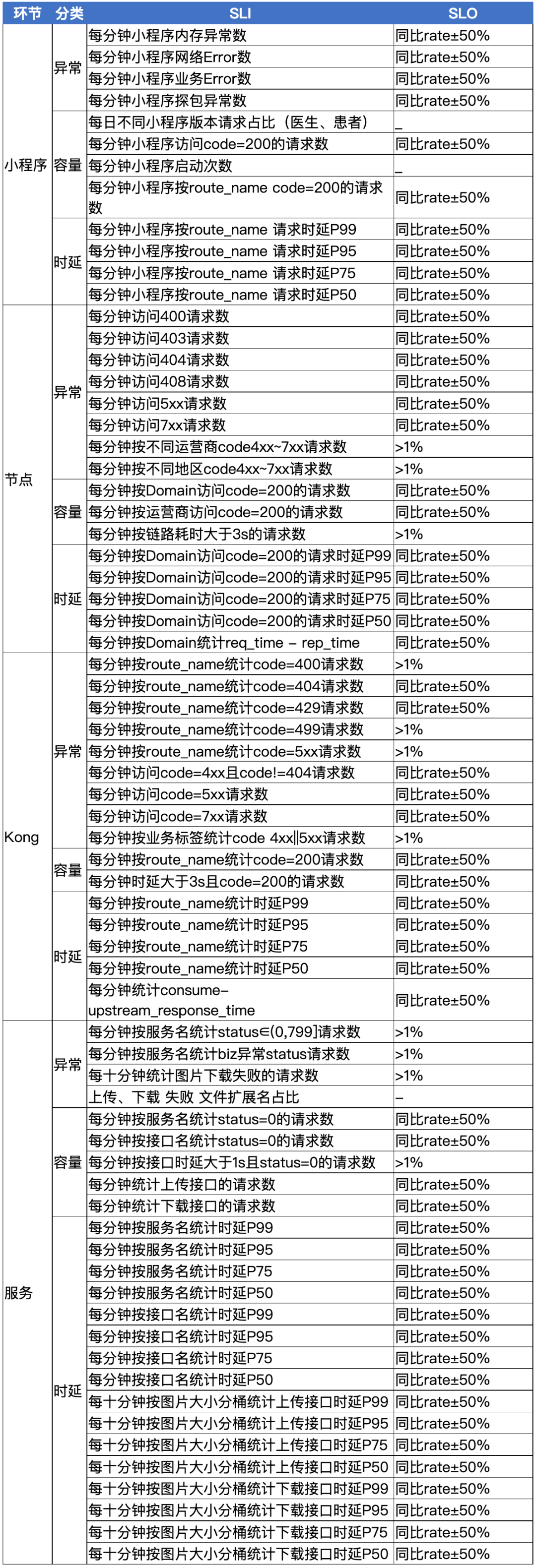 为了异常的可观测性,需要按不同的维度去细分 SLI,这次上传图片异常是由于微信灰度了特定的基础库,改造后需要收集终端相关信息,如设备平台,设备型号,微信版本,微信基础库版本以及小程序版本。在为上传图片链路建模分析的时候,也一直在考虑能否将这些经验延伸到小程序整体的可观测性中呢?于是进一步细化了分析维度,按不同的小程序包,统计了不同 code 码、路由、domain 的请求数及时延。这样就能更好地支持下钻,并能迁移到整个小程序异常分析中。接下来一起看一下如何落地改造各个环节以便 SLI 的收集。
为了异常的可观测性,需要按不同的维度去细分 SLI,这次上传图片异常是由于微信灰度了特定的基础库,改造后需要收集终端相关信息,如设备平台,设备型号,微信版本,微信基础库版本以及小程序版本。在为上传图片链路建模分析的时候,也一直在考虑能否将这些经验延伸到小程序整体的可观测性中呢?于是进一步细化了分析维度,按不同的小程序包,统计了不同 code 码、路由、domain 的请求数及时延。这样就能更好地支持下钻,并能迁移到整个小程序异常分析中。接下来一起看一下如何落地改造各个环节以便 SLI 的收集。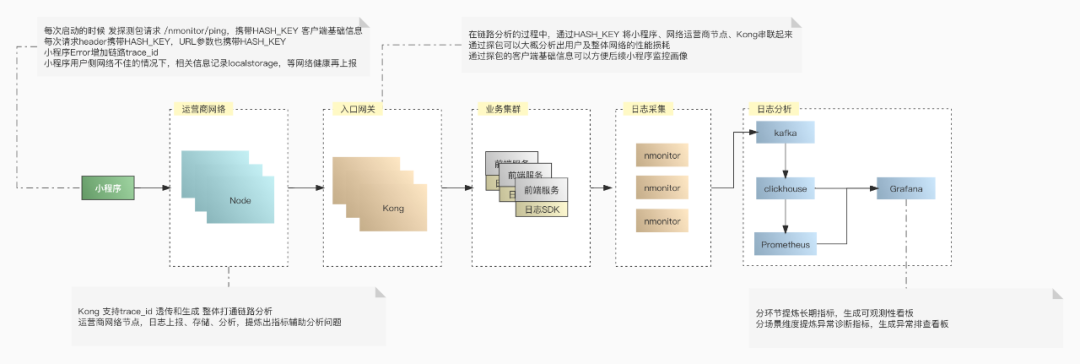 在改造的过程中也遇到了不少问题。
在改造的过程中也遇到了不少问题。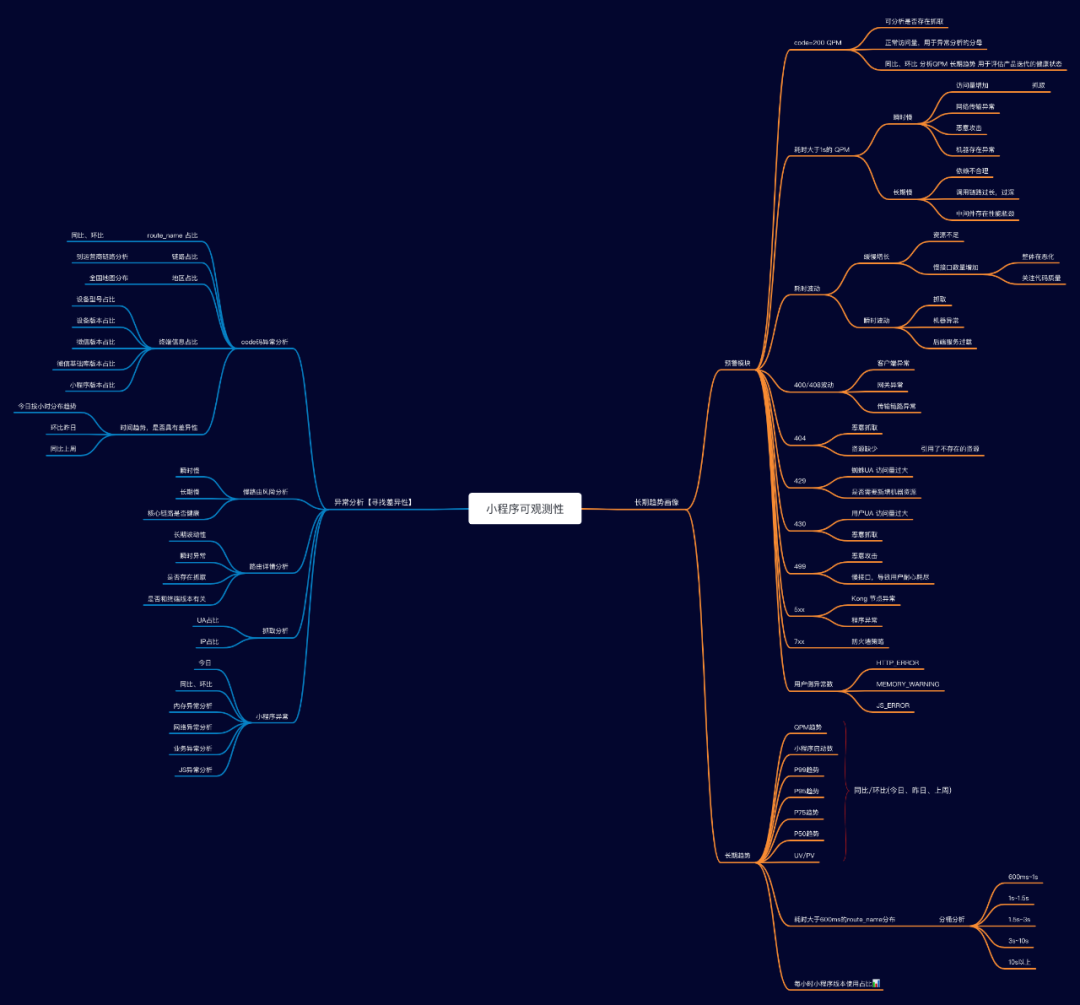 我们一起看一下具体的看板。
我们一起看一下具体的看板。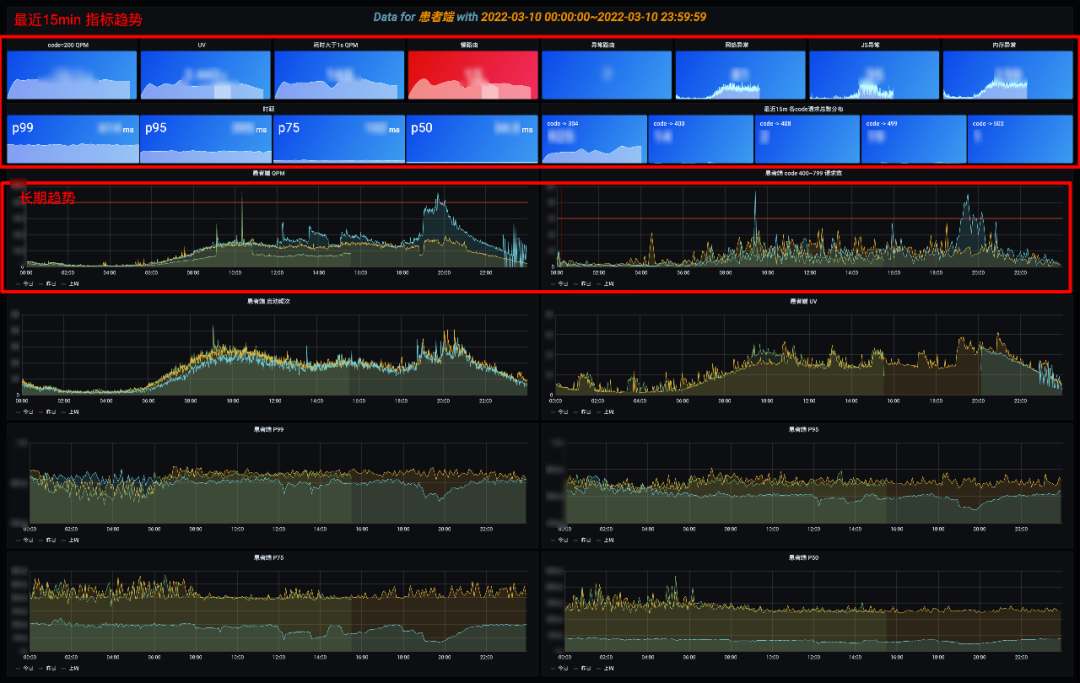 首页看板用于大盘投屏使用的,包括两个部分,上部分是最近 15min 的瞬时数据,大于某个经验阈值会标红显示,下部分是长期趋势,比对同比和环比,各个面板都支持下钻分析。首页一定要清爽,列出最关心的 SLI,如 QPS/UV、慢路由请求数、异常请求数。根据时延和 ErrorCode 分布,下钻到具体的分析页面。也可以通过分析长期趋势,查看小程序整体的状态,如慢路由风险是否在增加。
首页看板用于大盘投屏使用的,包括两个部分,上部分是最近 15min 的瞬时数据,大于某个经验阈值会标红显示,下部分是长期趋势,比对同比和环比,各个面板都支持下钻分析。首页一定要清爽,列出最关心的 SLI,如 QPS/UV、慢路由请求数、异常请求数。根据时延和 ErrorCode 分布,下钻到具体的分析页面。也可以通过分析长期趋势,查看小程序整体的状态,如慢路由风险是否在增加。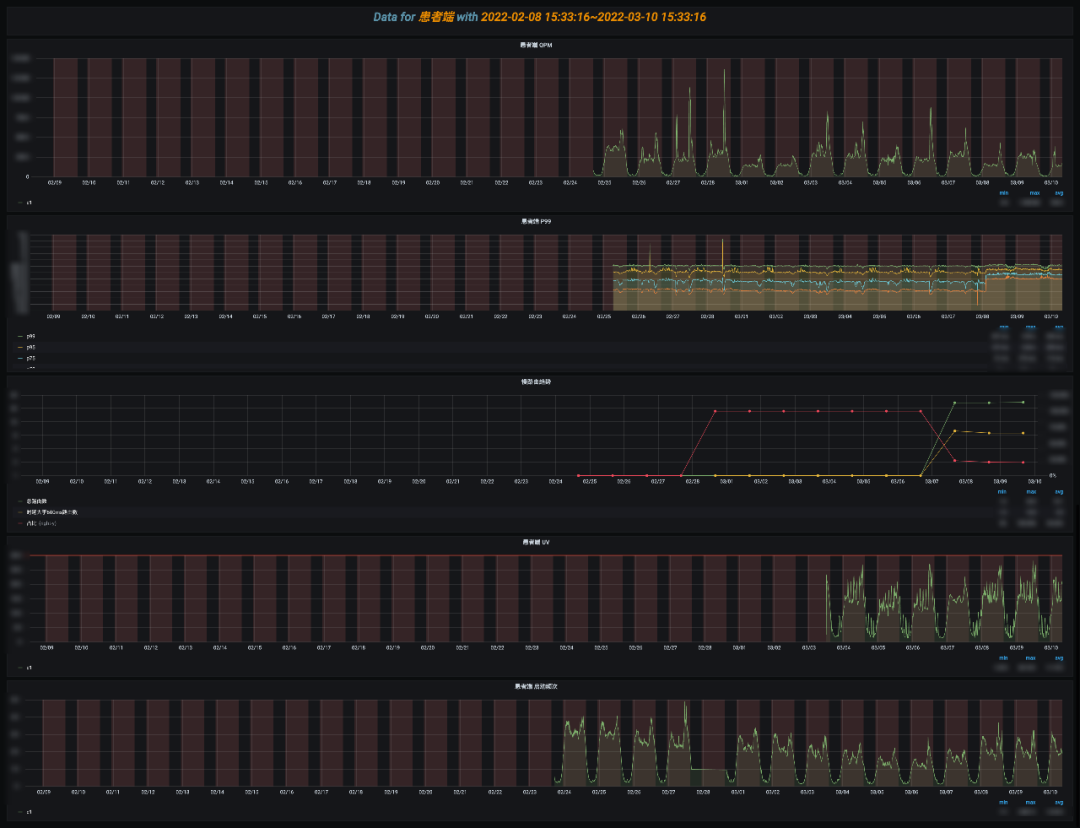 通过首页跳转到长期趋势分析,可以查看最近 1 周/1 月/1 年的宏观趋势,这块可以结合项目上线计划,分析上线节点前后的变化,如 UV 是否有增加,慢路由是否有增多的趋势,还可继续下钻分析具体哪些路由慢了。
通过首页跳转到长期趋势分析,可以查看最近 1 周/1 月/1 年的宏观趋势,这块可以结合项目上线计划,分析上线节点前后的变化,如 UV 是否有增加,慢路由是否有增多的趋势,还可继续下钻分析具体哪些路由慢了。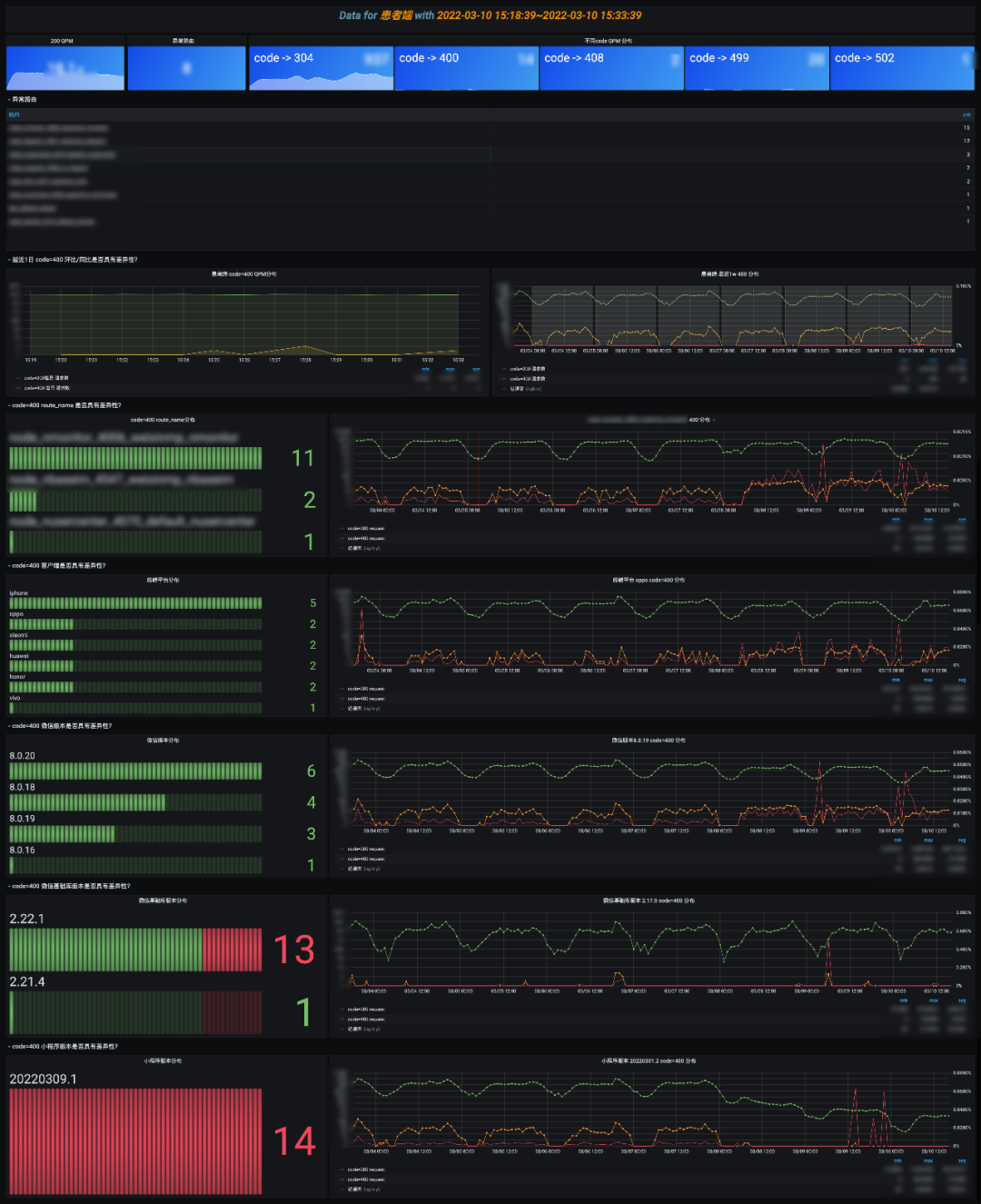 在首页可以观察异常 code 分布,下钻到具体的 code 分析页,这里模拟分析一下 code=400 量增加的场景。整个过程其实是一个模型匹配问答的模式。
在首页可以观察异常 code 分布,下钻到具体的 code 分析页,这里模拟分析一下 code=400 量增加的场景。整个过程其实是一个模型匹配问答的模式。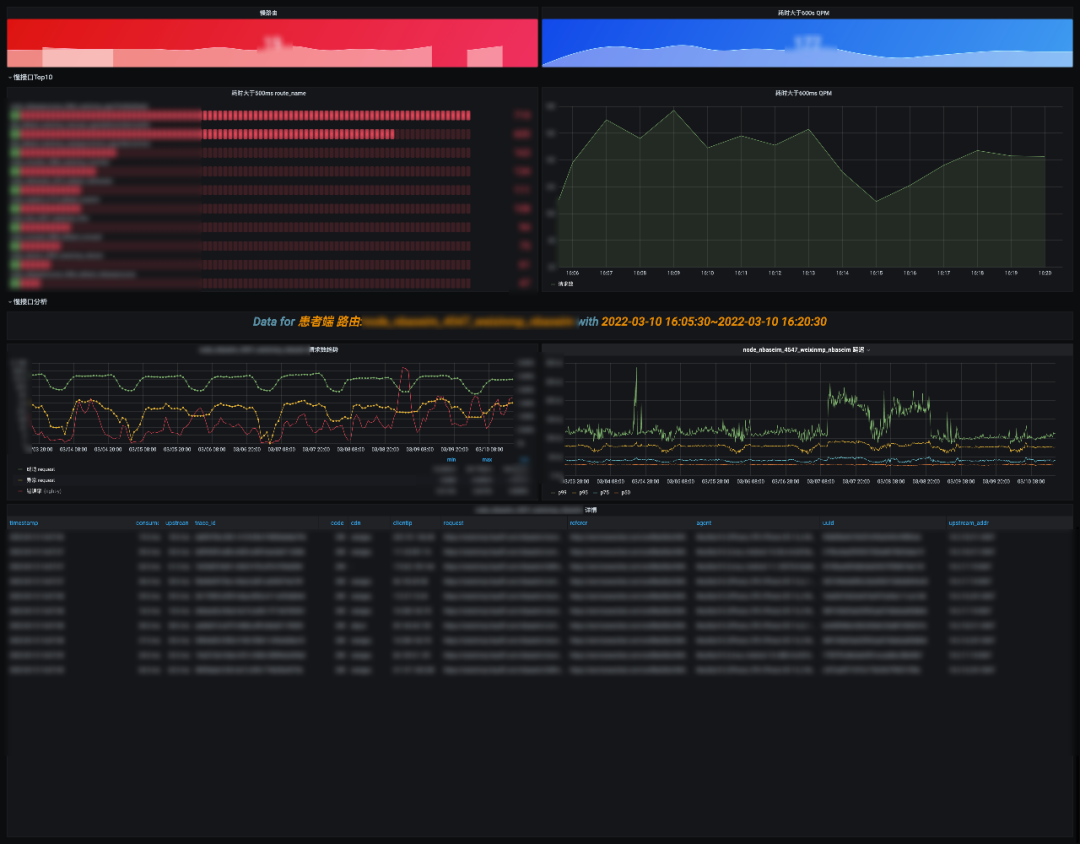 慢,会影响用户体验,随着业务的发展,如果不关注性能问题,整个接口会朝熵增的方向恶化,可能会越来越慢。一般重点关注 Top10 的慢路由,可以分析是长期慢,还是突发抓取的慢,结合 APM 链路分析,整个请求慢在哪,是依赖中间件慢还是请求路径过长抑或是存在其他慢风险。这部分依然可下钻到”NO5.路由详情分析“,”NO6.抓取分析“。
慢,会影响用户体验,随着业务的发展,如果不关注性能问题,整个接口会朝熵增的方向恶化,可能会越来越慢。一般重点关注 Top10 的慢路由,可以分析是长期慢,还是突发抓取的慢,结合 APM 链路分析,整个请求慢在哪,是依赖中间件慢还是请求路径过长抑或是存在其他慢风险。这部分依然可下钻到”NO5.路由详情分析“,”NO6.抓取分析“。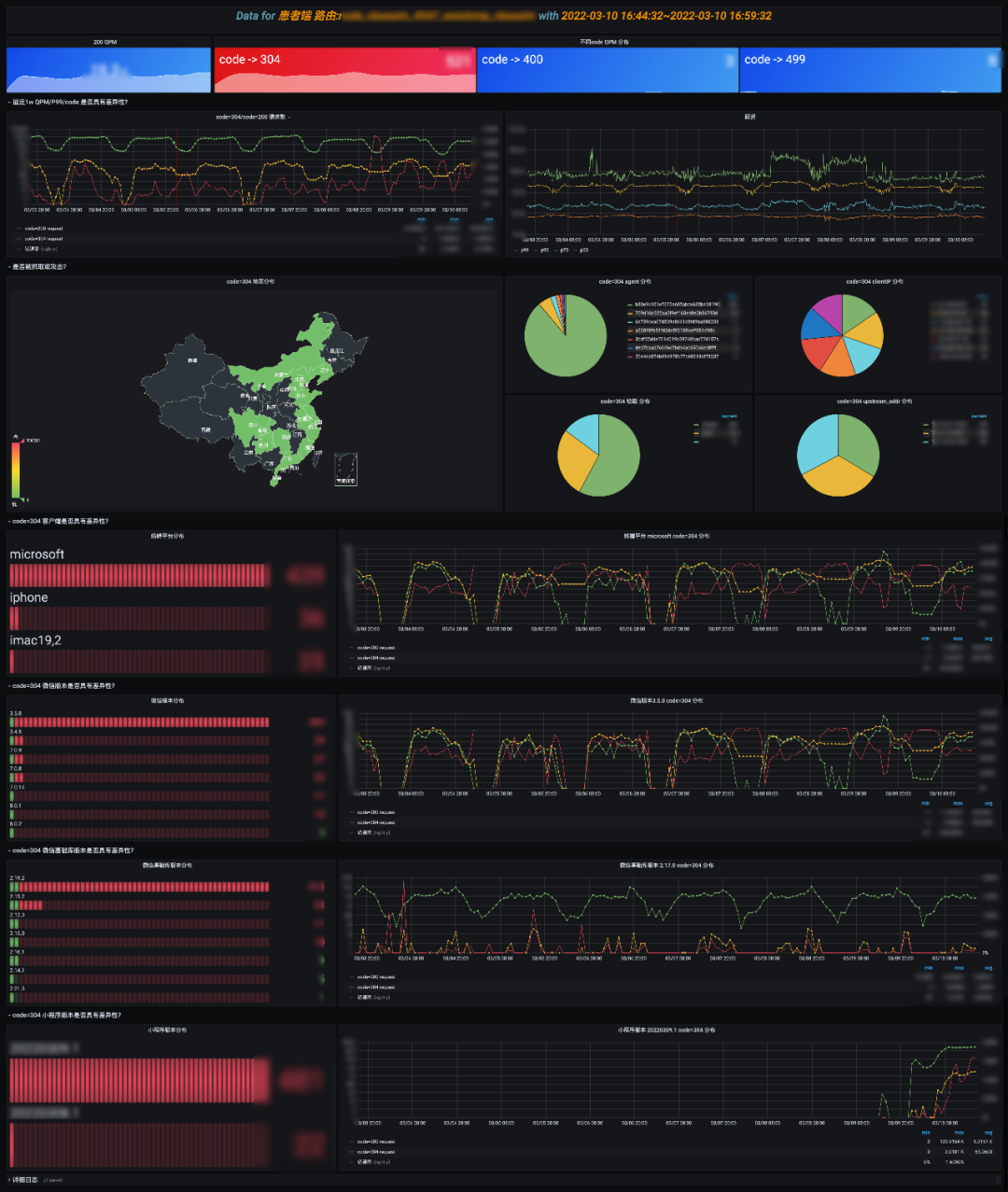 这部分依然在做问答题,主要是围绕给定的 route_name 展开分析的。
这部分依然在做问答题,主要是围绕给定的 route_name 展开分析的。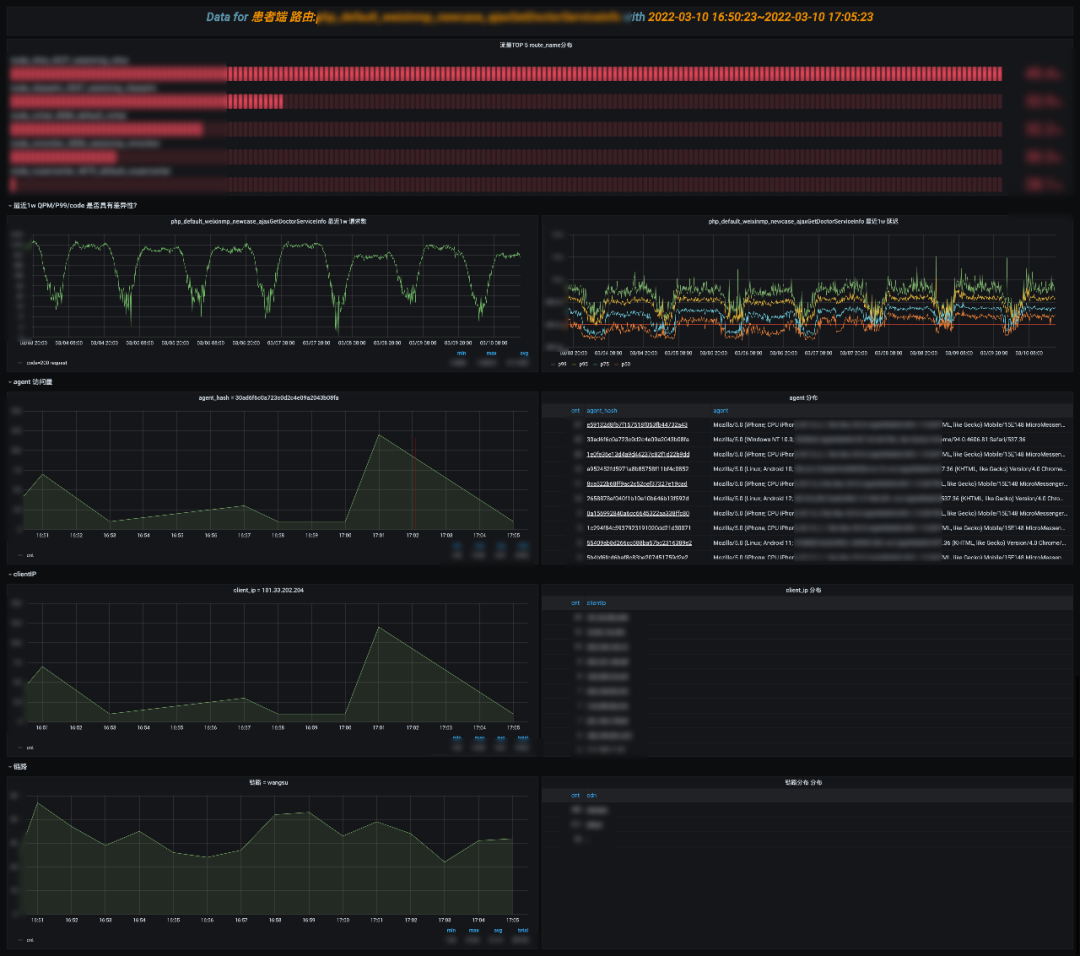 抓取分析就比较简单了,判断 UA 和 ClientIP 访问占比,抓取一般特征是单个 UA 访问量突增,ClientIP 比较集中,结合 QPM 长期趋势,判断是正常访问还是抓取。
抓取分析就比较简单了,判断 UA 和 ClientIP 访问占比,抓取一般特征是单个 UA 访问量突增,ClientIP 比较集中,结合 QPM 长期趋势,判断是正常访问还是抓取。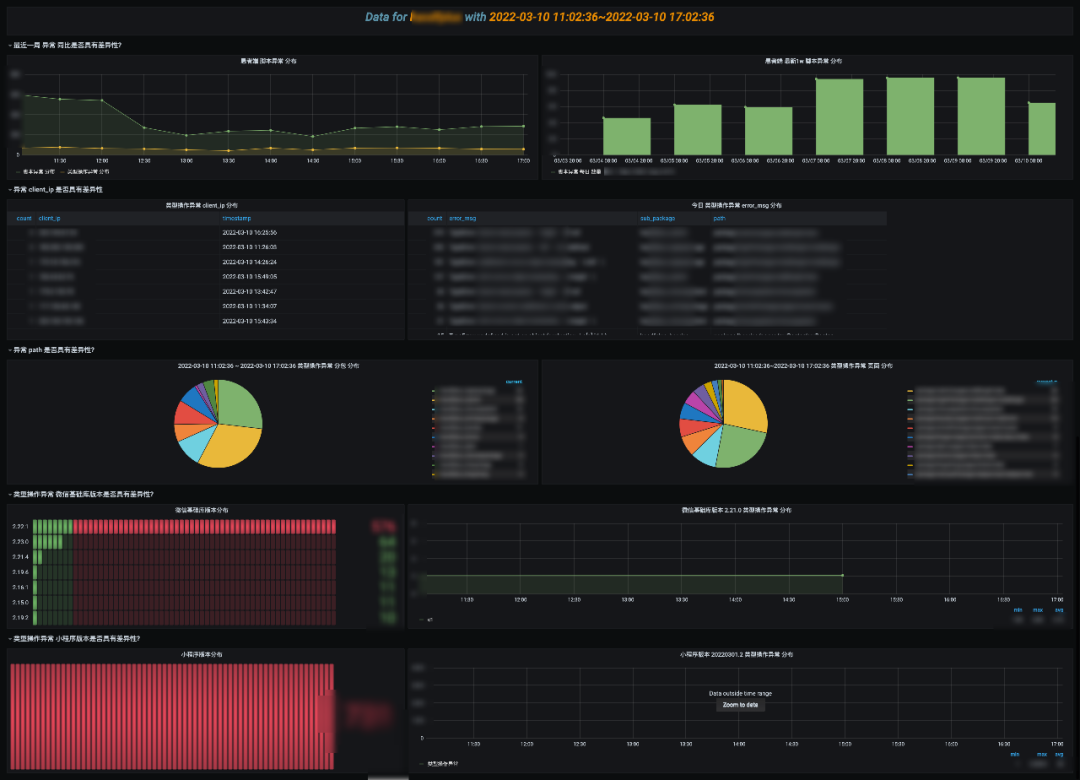
我正在试验RSpec并考虑一个仅在测试套件通过时才更改随机种子的系统。我试图在after(:suite)block中实现它,该block在RSpec::Core::ExampleGroup对象的上下文中执行。虽然RSpec::Core::Example有一个方法“exception”,允许您检查是否有任何测试失败,但在上似乎没有类似的方法RSpec::Core::ExampleGroup或示例列表的任何访问器。那么,如何检查测试是通过还是失败?我知道这可以使用自定义格式化程序来跟踪是否有任何测试失败,但格式化过程影响测试的实际运行似乎不是一个好主意。 最佳答
1.现象服务重启后,通过dockerstart方式无法启动实例,报出错误:Errorresponsefromdaemon:errorcreatingoverlaymountto/var/lib/docker/overlay2/xxx/merged:nosuchfileordirectorydockersave导出镜像也报出2.网上各种尝试摸索无效果修改daemon.json中的storage-driver为overlay,重启无效果。禁用selinux,临时或永久方式都无效果。修改/etc/docker/daemon.json中的storage-driver为overlay2,无效果。修改/l
我正在使用RubyonRails3.0.9、RSpec-rails2和FactoryGirl。我正在尝试陈述一个工厂协会模型,但我遇到了麻烦。我有一个factories/user.rb文件,如下所示:FactoryGirl.definedofactory:user,:class=>Userdoattribute_1attribute_2...association:account,:factory=>:users_account,:method=>:build,:email=>'foo@bar.com'endend和一个factories/users/account.rb文件,如下所示
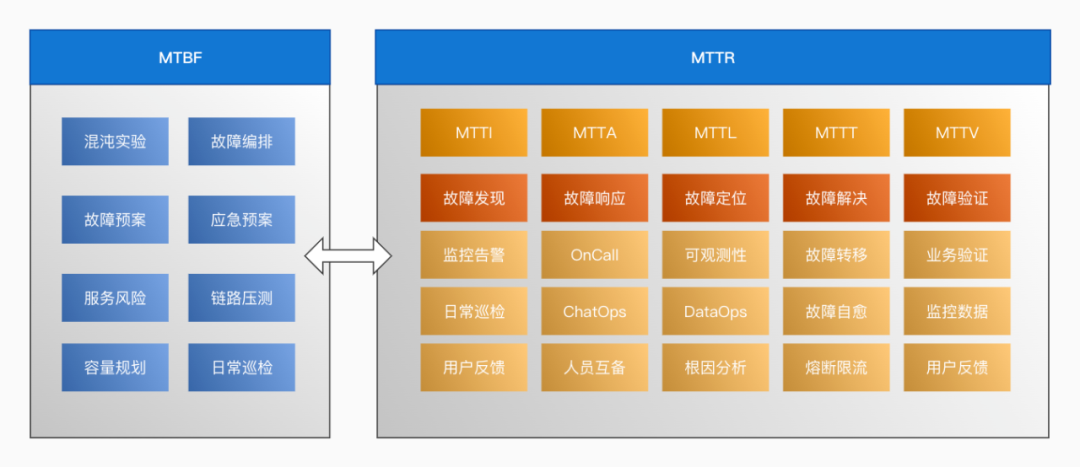
急促的告警铃声响彻寂静的夜晚。对运维人来说,晚间值守耗费更大的精力,往往一个简单的磁盘使用率告警通知,就不得不爬起来进行处理,毕竟告警无小事,对于小问题,运维人也不能心存侥幸心理。虽然有着值班人员和团队的支撑,但频繁的告警还是让运维人员精疲力竭,如何让系统的稳定性提高,减轻一线人员的工作量,减轻一线人员的压力?通过智能运维,实现故障自愈将成为不可避免的选择。故障自愈是提升企业网络系统可用性和降低故障处理的人力投入,实现故障自愈从"人工处理"到"无人值守"的变革。通过实时发现告警,进行预诊断分析,判断告警类型和级别,如果是一般告警,平台进行自动恢复,如果是严重复杂告警则通过告警通知、运维工单等形
我正在学习Ruby。我的背景是C++/Java/C#。总的来说,我喜欢这种语言,但我有点困惑为什么有这么多不同的方法来完成同一件事,每种方法都有自己略微不同的语义。以创建字符串为例。我可以使用''、""、q%、Q%或仅使用%来创建字符串。一些形式支持插值。其他形式允许我指定字符串定界符。为什么有五种创建字符串文字的方法?为什么我会使用非内插字符串?%语法相对于带引号的文字有什么优势?我知道Ruby中的冗余一定是有值(value)的,但我未经训练的眼睛看不清楚。请赐教。 最佳答案 WhywouldIeverusenon-interpo
【车载开发系列】UDS诊断—DTC故障码基础回顾UDS诊断---DTC故障码基础回顾【车载开发系列】UDS诊断---DTC故障码基础回顾一.什么是DTC故障码二.DTC故障码的作用三.什么是自诊断需求四.故障自诊断范围是什么五.DTC故障码的格式及组成六.DTC之故障所属系统七.DTC之故障类型八.DTC之所属子系统九.DTC之故障失效类型十.DTC故障码的表示十一.故障指示的概念十二.什么是故障快照信息十三.什么是故障扩展信息十四.故障扩展信息和快照信息的作用十五.DTC故障码的状态位十六.状态码的作用是什么十七.DTC故障信息存储机制十八.什么是故障自恢复策略十九.与操作DTC故障码相关的
据我所知,Ruby中基本上有三种不同的闭包;方法、过程和lambdas。我知道它们之间存在差异,但是我们不能只是拥有一种可以容纳所有可能用例的类型吗?通过调用self.method(method_name)已经可以像procs和lambdas一样传递方法。,我所知道的procs和lambdas之间的唯一显着区别是当您尝试使用return时,lambdas检查arity和procs会做一些疯狂的事情。.那么我们不能将它们全部合并为一个并完成它吗? 最佳答案 AsfarasIcantell,thereareessentiallythre
我目前正在尝试在搜索进行时在我的搜索栏上显示一个简单的加载程序。我计划在从我的表单控件观察到的valueChanges的订阅回调中将一个变量设置为值“loading”,并在完整的回调中将其设置为一个空字符串。但是,永远不会调用完整的回调。我也尝试在finally上添加一个回调,但它也从未被调用过。我的代码:searchBox:Control=newControl();loadingClass:string="";constructor(){this.searchBox.valueChanges.debounceTime(400).distinctUntilChanged().subsc
基类是否有可能在允许子类订阅Angular2中的可观察对象之前捕获某些错误。例如exportclassSomeBaseClass{constructor(private_http:Http,private_location:Location){}protected_fetchData(url):Observable{constheaders=newHeaders();headers.append('Authorization','Tokenfoo');returnthis._http.get(url,{headers}).map(response=>response.json()).c
我遇到了一些Googlemap/Javascript问题。我想我知道问题出在哪里,但就是不知道解决办法。我的问题的一个例子是here.无论您点击什么标记,第二个都会出现。我显然将错误的信息传递到我的事件监听器中,但我似乎无法获得正确的代码。这是代码的一部分:首先,这是我的部分代码:if(GBrowserIsCompatible()&&mapResults!=null){//ReadintheJSONvarmapDetailsArray=loadJSON();//Createamapvarmap=newgoogle.maps.Map2(document.getElementById(el