1.准备工作
(1)由于是使用存储过程,mysql从5.0版开始支持存储过程,那么需要mysql的版本在5.0或者以上。如何查看mysql的版本,使用下面sql语句查看:
(2)创建两张表,表结构一致,但使用的存储引擎不一样,如下所示,普通表使用mysql5.5版本后默认的INNODB存储引擎,内存表使用MEMORY存储引擎。
由于MEMORY存储不常用这里简单说一下其特点:MEMORY引擎表结构创建在磁盘上,数据全部放在内存中,访问速度较快,但是当MySQL重启后或者一旦系统奔溃的话,数据都会消失,结构还存在。
# 创建普通表
CREATE TABLE `user_info` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` VARCHAR ( 30 ) NOT NULL COMMENT '用户名',
`phone` VARCHAR ( 11 ) NOT NULL COMMENT '手机号',
`status` TINYINT ( 1 ) NULL DEFAULT NULL COMMENT '用户状态:停用0,启动1',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY ( `id` ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 10001 CHARACTER
SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户信息表';
# 创建内存表
CREATE TABLE `memory_user_info` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` VARCHAR ( 30 ) NOT NULL COMMENT '用户名',
`phone` VARCHAR ( 11 ) NOT NULL COMMENT '手机号',
`status` TINYINT ( 1 ) NULL DEFAULT NULL COMMENT '用户状态:停用0,启动1',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY ( `id` ) USING BTREE
) ENGINE = MEMORY AUTO_INCREMENT = 10001 CHARACTER
SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户信息内存表';2.主要实现步骤
(1)创建自动生成数据的函数,插入时使用;
(2)创建插入内存表数据存储过程,调用已创建好的数据生成函数;
(3)创建内存表数据插入普通表存储过程;
(4)调用存储过程。
(5)数据查看验证
3.创建自动生成数据的函数
(1)生成n个随机数字
DELIMITER //
DROP FUNCTION
IF
EXISTS randomNum // CREATE FUNCTION randomNum (
n INT,
chars_str VARCHAR ( 10 )) RETURNS VARCHAR ( 255 ) BEGIN
DECLARE
return_str VARCHAR ( 255 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = concat(
return_str,
substring( chars_str, FLOOR( 1 + RAND()* 10 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER;函数运行截图:
脚本所用到的mysql函数及其功能如下:
a.concat():将多个字符串连接成一个字符串。
b.Floor():向下取整。
c.substring(string, position, length)
第一个参数:string指的是需要截取的原字符串。
第二个参数:position指的是从哪个位置开始截取子字符串,这里字符的位置编码序号是从1开始,若position为负数则从右往左开始数位置。
第三个参数:length指的是需要截取的字符串长度,如果不写,则默认截取从position开始到最后一位的所有字符。
d.RAND():只能生成0到1之间的随机小数。
(2)创建随机生成手机号函数
DELIMITER //
DROP FUNCTION
IF
EXISTS getPhone // CREATE FUNCTION getPhone () RETURNS VARCHAR ( 11 ) BEGIN
DECLARE
head CHAR ( 3 );
DECLARE
phone VARCHAR ( 11 );
DECLARE
bodys VARCHAR ( 65 ) DEFAULT "130 131 132 133 134 135 136 137 138 139 186 187 189 151 157";
DECLARE
STARTS INT;
SET STARTS = 1+floor ( rand()* 15 )* 4;
SET head = trim(
substring( bodys, STARTS, 3 ));
SET phone = trim(
concat(
head,
randomNum ( 8, '0123456789' )));
RETURN phone;
END //
DELIMITER;函数运行截图:

(3)创建随机生成用户名函数
DELIMITER //
DROP FUNCTION
IF
EXISTS randName // CREATE FUNCTION randName ( n INT ) RETURNS VARCHAR ( 255 ) CHARSET utf8mb4 DETERMINISTIC BEGIN
DECLARE
chars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE
return_str VARCHAR ( 30 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = concat(
return_str,
substring( chars_str, FLOOR( 1 + RAND() * 62 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER;函数运行截图:

(4)随机生成用户状态函数
DELIMITER //
DROP FUNCTION
IF
EXISTS randStatus // CREATE FUNCTION randStatus ( ) RETURNS TINYINT ( 1 ) BEGIN
DECLARE
user_status INT ( 1 ) DEFAULT 0;
SET user_status =
IF
( FLOOR( RAND() * 10 ) <= 4, 1, 0 );
RETURN user_status;
END //
DELIMITER;函数运行截图:
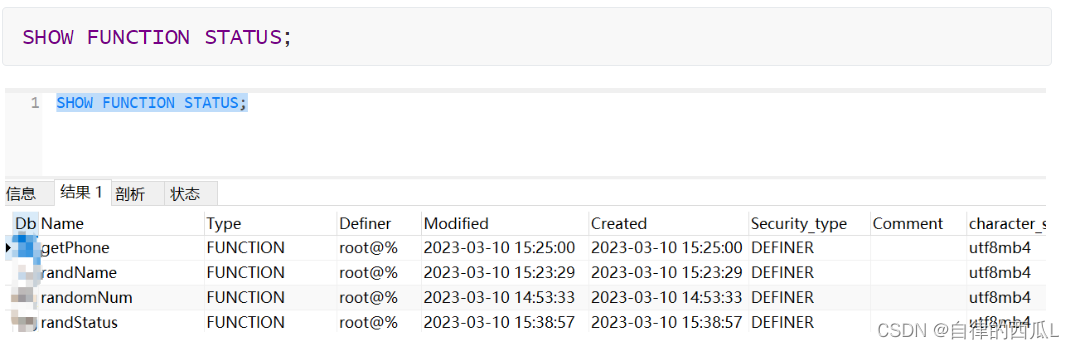
(5)查看数据库中所有自定义函数信息
4.创建存储过程
(1)创建插入内存表数据存储过程
DELIMITER //
DROP PROCEDURE
IF
EXISTS add_memory_user_info // CREATE PROCEDURE `add_memory_user_info` ( IN n INT ) BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
( i <= n ) DO
INSERT INTO memory_user_info ( `name`, `phone`, `status`, `create_time` )
VALUES
(
randName ( 20 ),
getPhone (),
randStatus (),
NOW());
SET i = i + 1;
END WHILE;
END //
DELIMITER;入参n是多少就表示往内存表memory_user_info插入多少条数据
存储过程运行截图:

(2)创建内存表数据插入普通表存储过程
DELIMITER //
DROP PROCEDURE
IF
EXISTS add_user_info // CREATE PROCEDURE `add_user_info` ( IN n INT, IN count INT ) BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
( i <= n ) DO
CALL add_memory_user_info ( count );
INSERT INTO user_info SELECT
*
FROM
memory_user_info;
DELETE
FROM
memory_user_info;
SET i = i + 1;
END WHILE;
END //
DELIMITER;这是最主要的存储过程,也是入口,利用对内存表的循环插入和删除来实现批量生成数据,不需要更改mysql默认的max_heap_table_size值(默认值是16M),max_heap_table_size 的作用是配置用户创建内存临时表的大小,配置的值越大,能存进内存表的数据就越多。
存储过程运行截图:

(3)查看存储过程的状态
-- 查看数据库所有的存储过程
SHOW PROCEDURE STATUS;
-- 模糊查询存储过程
SHOW PROCEDURE STATUS LIKE 'add%';模糊查询结果:

5.调用存储过程
mysql称存储过程的执行为调用,因此mysql执行存储过程的语句为CALL。CALL接受存储过程的名字以及需要传递给它的任意参数。
通过调用add_user_info存储过程,不断循环插入内存表memory_user_info,再从内存表获取数据插入普通表user_info,然后删除内存表数据,以此循环直至循环结束。循环100次,每次生成10000条数据,共生成一百万条数据。
CALL add_user_info(100,10000);6.数据查看验证
在普通表数据达到6万条时,已经耗时大概在23分钟左右,以这个时间推算,100万数据生成预计需要6小时左右。耗时的点主要是在四个随机生成字段数据的函数上。如果字段数据不要求随机,那么将会快很多。
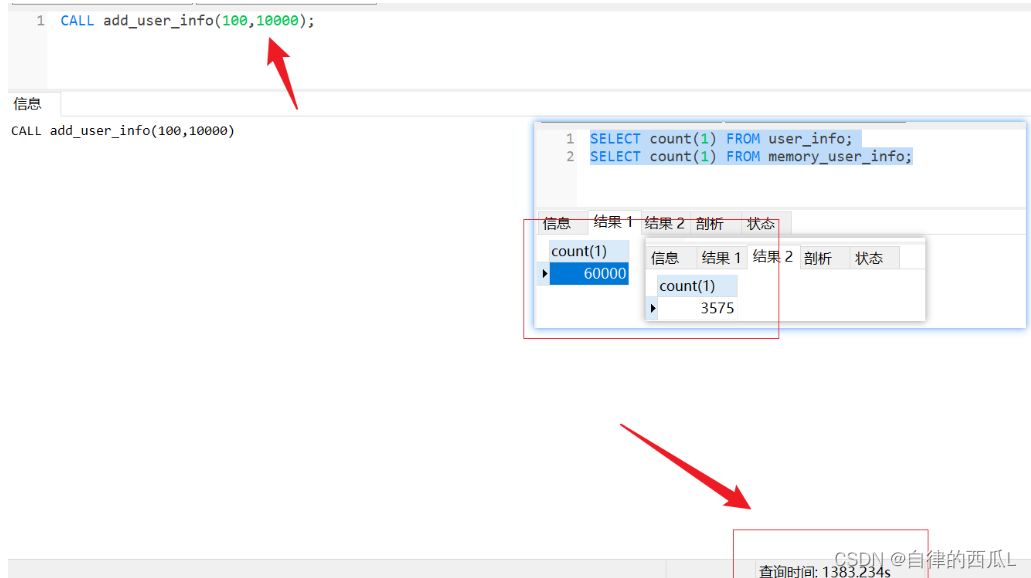
数据记录如下效果:

我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
我正在使用mechanize登录网站,然后检索页面。我遇到了一些问题,我怀疑这是由于cookie中的某些值造成的。当Mechanize登录网站时,我假设它存储了cookie。如何通过Mechanize打印出存储在cookie中的所有数据? 最佳答案 代理有一个cookie方法。agent=Mechanize.newpage=agent.get("http://www.google.com/")agent.cookiesagent.cookies.to_scookie返回一个Mechanize::Cookiesobject
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化