回顾大数据的发展历程,一句话概括就是海量数据的高效处理。在当今快节奏、不断变化的市场环境下,优秀的开发效率已经成为企业数字化转型的必备条件。
数栈离线开发BatchWorks 是一款专注离线数据ELT开发的产品,采用先进的大数据生态底层技术,具备高性能且功能丰富的大数据处理能力,对大数据离线计算、数据仓库建设提供有效支撑,是企业建设数据中台、数据仓库,加速数字化转型的基础设施。
BatchWorks 经过6年多的打磨已经服务于包括金融、教育、政企、零售等多个行业在内的300+客户,在开发效率提升方面发挥了巨大的价值。本文将从多个项目实施过程中遇到的6个典型场景来介绍一下离线开发BatchWorks 在开发效率提升上的一些解决方案,与大家共同探讨。
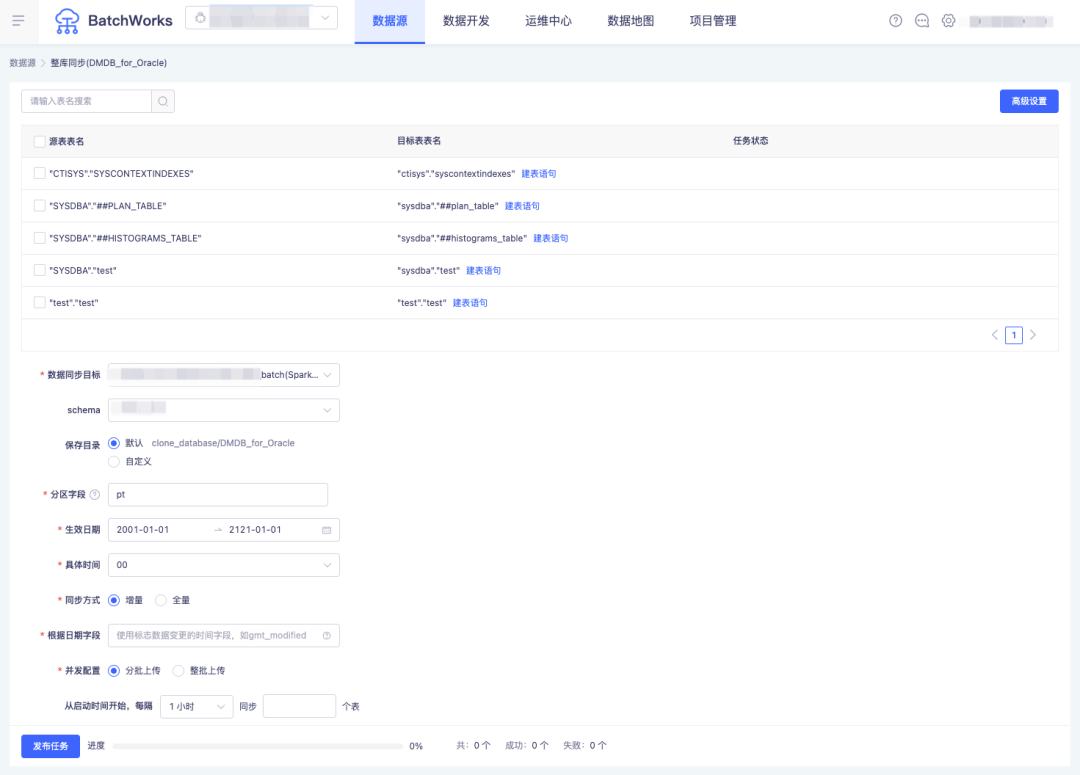
问:客户数仓计划从 Oracle 迁移到 Hadoop,初始化需要完成几万张表的数据同步,如何快速进行大批量 hive 表的创建并做数据抽取?
答:BatchWorks 支持连接数据源进行关系型数据库到包括 Hive 在内的多目标数据库之间的整库同步,可一次性完成大批量表的自动创建和同步任务的生成,支持按日期增量和全量两种数据同步方式。考虑到同一时间点启动大量数据同步任务会造成数据库压力过大,还可支持任务并发数的配置。
问:一条业务线上有20+产品,每个产品的数据分析由一个 SQL 任务完成,所有产品的任务逻辑完全一致且需要保持变更同步,而实际业务在快速变化,数据开发每次调整业务逻辑都需要每个 SQL 任务分别手动变更,经常出现调整错漏的情况,如何解决?
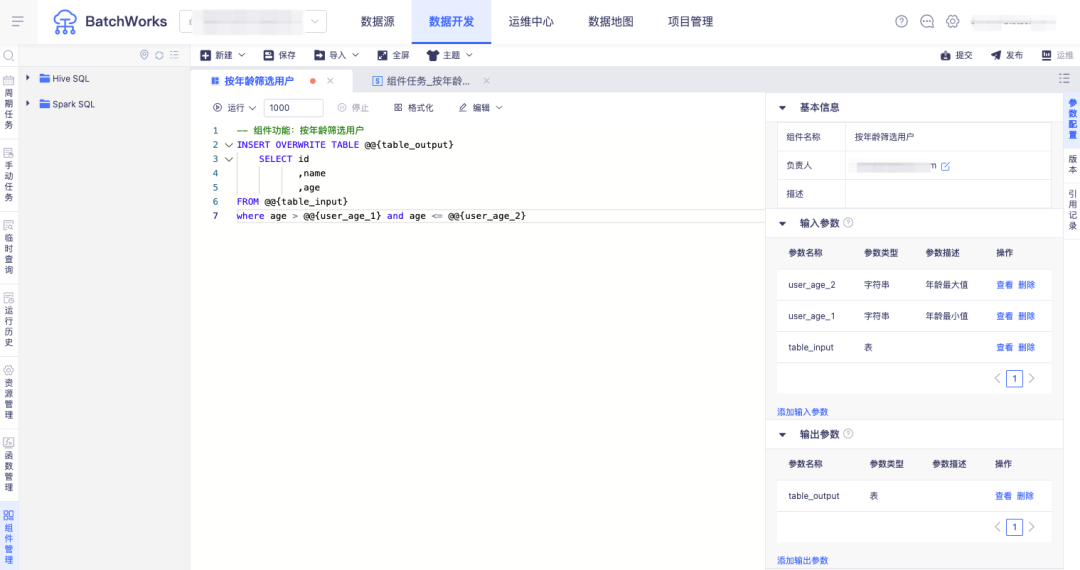
答:增加“组件”功能,用户可把在大量任务中通用的业务 SQL 逻辑抽象出来作为组件进行维护,不同的产品只需引用组件并配置输入输出表和字符参数,即可快速完成任务配置。当业务变更时只要调整组件的逻辑就能实现所有引用此组件任务的同步变更。
一个简单例子:业务方需要对不同产品的用户群体做年龄分层,可创建组件做年龄筛选,配置以下输入输出参数:
• 输入参数:数据来源表
• 输出参数:年龄层中的最大最小值(字符串)、数据输出表
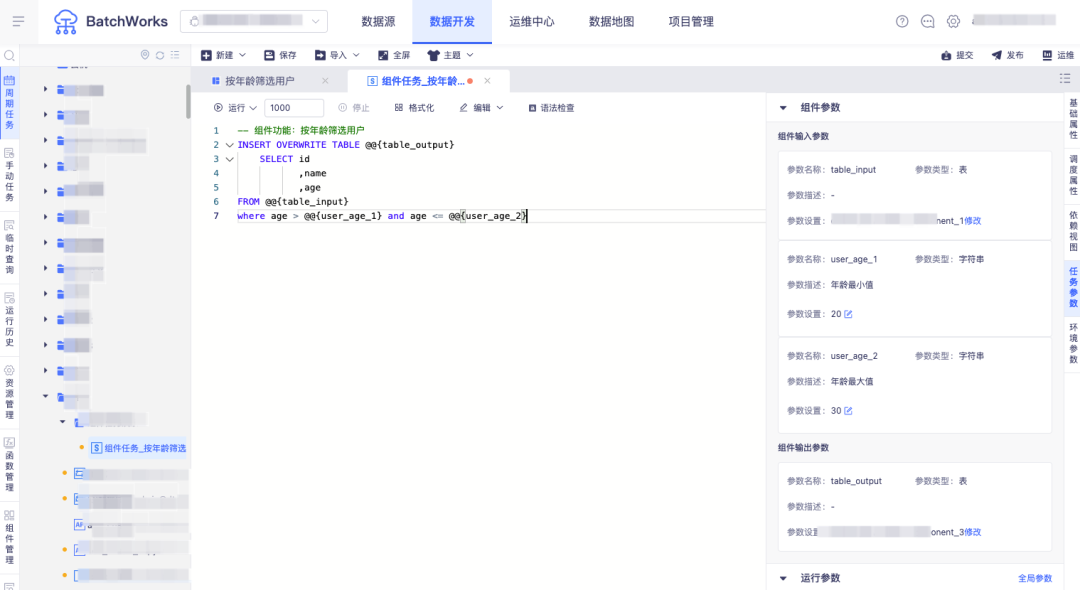
实现从产品1中筛选出年龄为20-30的用户数据,在创建任务时选择上述组件配置年龄输入参数和数据来源表,并指定写入的结果表:
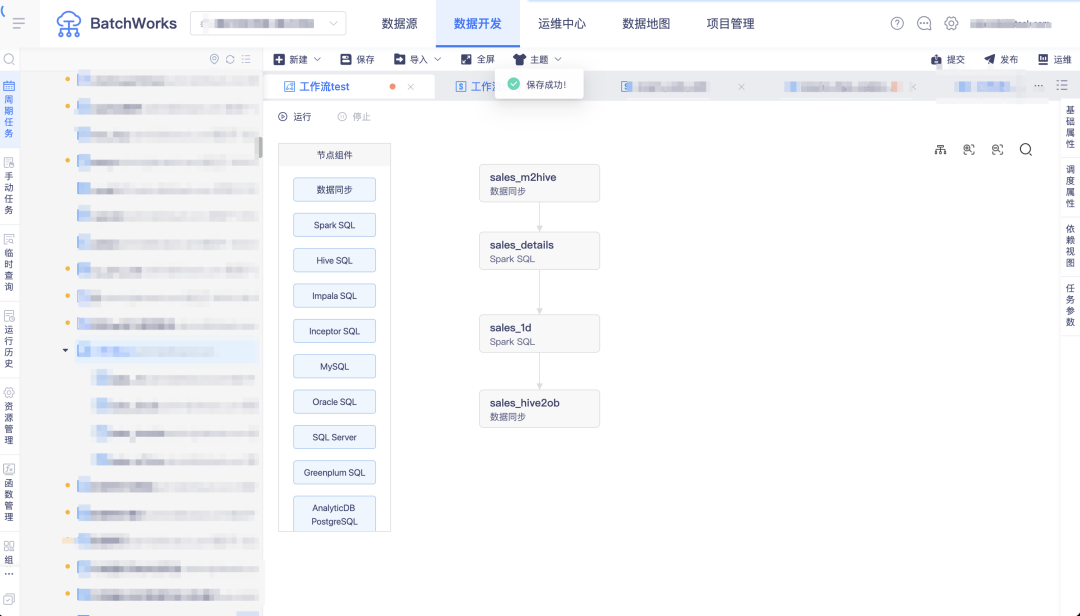
问:任务存在上下游依赖时,下游任务可能需要直接使用上游部分任务的计算结果,同时用户不希望建太多临时表,或产生一些额外的重复计算,如何解决?
答:BatchWorks 支持了任务上下游参数传递功能,上游任务的计算结果可进行周期性存储,直接被下游计算引用。
一个简单例子:从业务库完成销售明细表数据采集清洗,按天汇总后将销售金额最高的门店数据输出 sales_1d 任务,从 sales_details 中通过输入参数获取日期数据,然后将当天最高销售数据对应的门店通过输出参数输出传递至下游的同步任务,同步任务筛选此门店数据同步至 oceanbase。
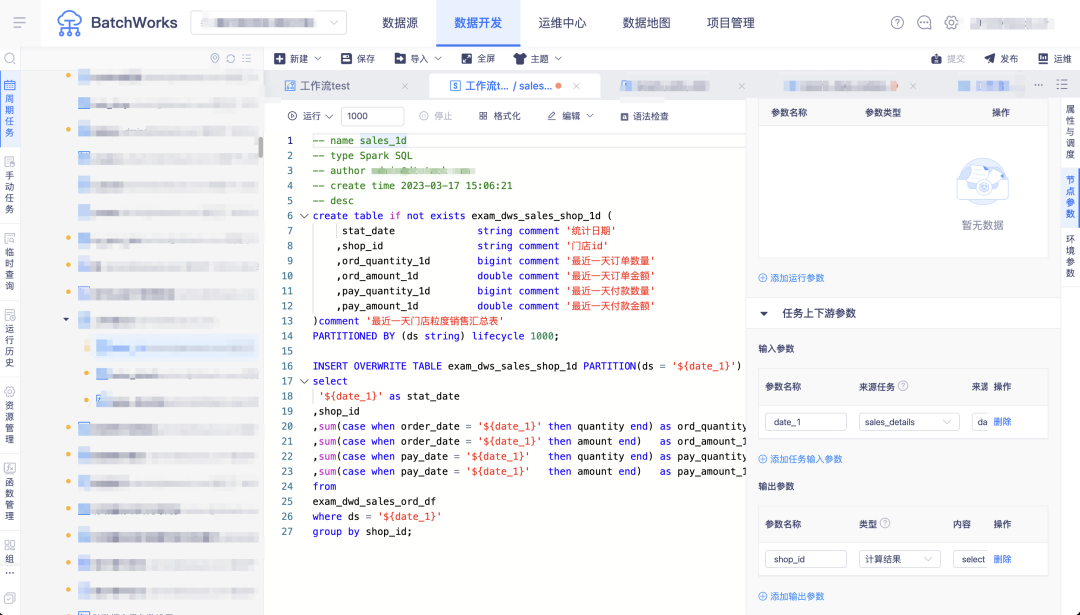
问:当任务较多且依赖关系复杂时,依赖关系的配置会占用一定的工作量,尤其在对任务做了修改后,依赖关系可能会有更新不及时/漏更新的情况,发现问题时往往已经到了下游环节,如何解决?
答:BatchWorks 支持了上游任务依赖自动解析推荐/自动依赖功能,选择此功能进行依赖任务配置时,平台将对当前任务进行 SQL 解析,得到来源表和结果表,并寻找来源表的产出任务,用户可从这些推荐任务里选择全部或部分任务添加到上游依赖,也可直接选择自动依赖,当 SQL 调整时自动进行上游依赖的更新。
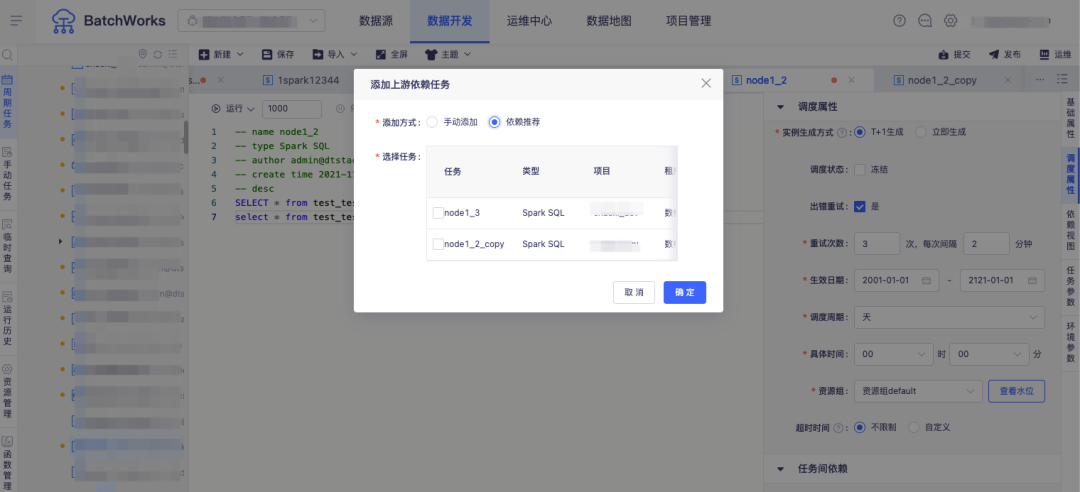
问:离线实例的运行流程涉及实例上游依赖检查、到达计划时间检查、资源检查、质量校验等多个环节,运行过程出现异常时仅通过日志难以直观地进行问题溯源,问题处理不及时直接影响下游业务,如何解决?
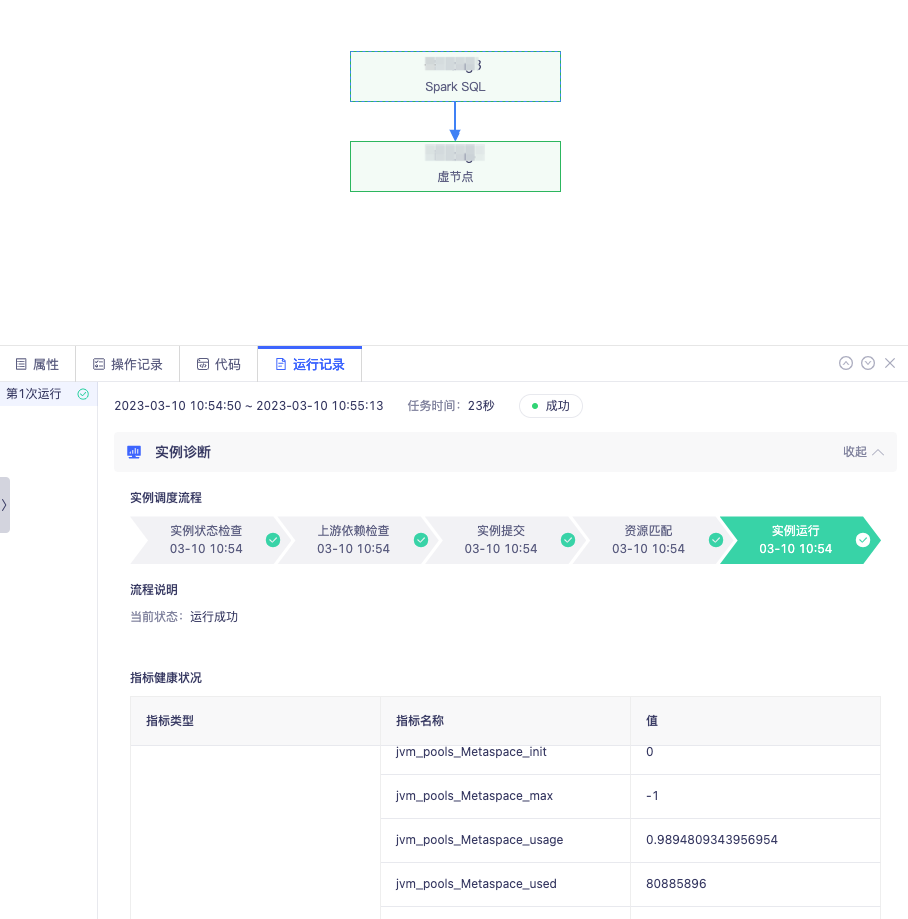
答:BatchWorks 支持实例诊断功能对实例的运行过程进行分析,将实例调度流程及每个流程当前的状态、节点时间全部展示,用户可直观地看到当前实例的运行阶段和异常原因。
比如在进行上游依赖异常检查时,BatchWorks 将构建以当前实例为末位节点的异常依赖树,寻找直接导致其未运行的根源任务组,快速直达阻塞点。此外针对 SparkSQL,可监控其指标健康状况并给出调参建议,针对 HiveSQL 可观测运行过程中资源使用变化情况,从而可进一步进行任务调优。

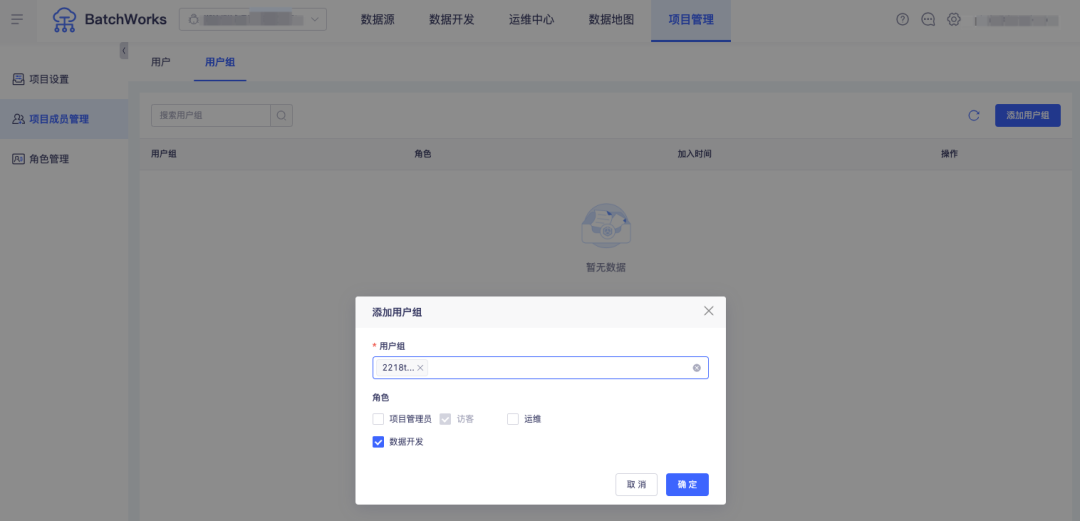
问:某公司的数据开发团队不定期会有一些人员调整,因业务量大、开发项目比较多,人员调整后开发平台上的维护十分繁琐。例如有新员工入职,需要将其添加到相关的多个开发项目中并赋予不同的角色,任务告警值班时需要添加进对应的告警规则中等等,增加管理员的用户管理成本且容易缺漏,如何解决?
答:BatchWorks 的用户中心支持以用户组为单位的用户管理,每个用户可被添加进一个或多个用户组。项目添加用户、告警圈选用户时均可以用户组的方式进行配置。后续增删用户时仅需在用户中心的用户组内进行操作,即可完成人员->项目/角色等的快速调整。
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt