📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
作为中国DBA联盟的一个成员,我比较关注国产数据库的动态,从2018 年OceanBase 2.0 版本正式发布,我就开始接触OceanBase了,官方也从不同渠道做了相关的技术分享,我基本每次都参加,同时在OceanBase官方社区也认识了一些志同道合的朋友。月初正好给客户做运维实施,客户在规划后期国产数据库的替代方案,让我给点意见。我也是让客户多关注关注OceanBase。打开官网,发现官方发布了新动态,于2022年11月4日发布了4.0社区版,于是怀着激动的心情去体验了一把,看到一些熟悉的小伙伴在OceanBase问答社区如火如荼的讨论4.0版本的新特性,我也班门弄斧下,谈谈我的拙见。
OceanBase V4.0 版本在保证功能特性不丢失的前提下,重新审视了数据库与分布式系统两个领域最基础的设计,全新推出业内首个单机分布式一体化架构,重点构建 HTAP 和云化两个基础能力属性。与此同时,该版本也从架构上解决了 V3.2 版本的设计瓶颈,支持更多用户业务关注的多个核心能力,在内核功能、兼容性、稳定性、性能上取得突破。
首先OceanBase 4.0 首推的单机分布式一体化架构,一方面它具备单机数据库高性能、低成本的优势,这个优势可以帮助客户降低成本;另外一方面具备分布式数据库高可用、可扩展、面向云,面向未来的优势,帮助客户更好地挖掘数据价值,也就是说,通过 OceanBase 4.0 可以同时帮助客户降本增效,赢得未来。即便在单机部署模式下,仍然可以实现分布式部署的完整功能,包括 Oracle/MySQL 兼容性、TP 事务处理能力、AP 并行分析查询能力、租户资源隔离等。既能够支持分布式多机场景,也能够支持应用在单机场景,既能用在一些比较大规格、高配置的机器,也能够用在低配置的机器,既能用在关系型数据模型,也能够用在多模模型,既能够处理 OLTP 核心业务场景,也能够用来处理 OLAP 实时分析场景。
其次快速部署及易用性方面,OceanBase一直在这方面做改进。OceanBase 全家桶不再像以前版本那样一个个下载安装了,在我接下来的的通过OceanBase 全家桶部署安装过程中,大家就能感受到时绝对的是实至名归。由原来需要 5 步手动安装部署,优化为3个步骤,简单明了,两分钟可以完成体验demo。官方承诺大家可以在 4C8G(即 CPU 4 核心,内存 8 GB)的环境下轻松启动和使用。可以说只用3分钟,就能让你拥有一款单机 OB 分布式数据库。平时我比较关注国产数据库的发展,也做过其他的国产数据库相关评测及体验,就拿opengauss、达梦、TiDB的来说,感觉对环境要求比较高,部署过程较为繁琐,非常耗时,这样很影响对数据库的体验感。同时在Docker 部署的国产数据库方面不多,OceanBase支持在Docker容器部署,这对平时做测试有很大帮助,发布后的第一时间,我也是通知了共事的小伙伴,大家一起体验了版本的一些新特性,比如并行处理,数据压缩,多租户模式资源的灵活调整等,确实很不错,性能很棒。部署更加便捷,让用户能够更好的体验OceanBase,OceanBase 4.0 的核心目标是要让我们的DBA小伙伴们更简单地使用数据库。
最后,明显发现这次的OceanBase全家桶安装包里面包含了 OBD、OceanBase 数据库、 OBProxy、obagent、Grafana 和 Prometheus ,一应俱全啊。随着业务种类的增加、服务器数量的增长、网络环境的越发复杂以及发布更加频繁,从而不可避免地带来了线上事故的增多,因此需要对服务器到应用的全方位监控,提前预警,急需一个工具来解决这个问题,而OceanBase通过Grafana、Prometheus 的结合,完美的解决了这个问题。可以在众多国产数据库中,OceanBase的工具是最多也是最齐全的,敏捷的诊断 SQL Diagnoser工具、日志数据链路工具、集群管理平台、OMS数据迁移服务,导入/导出工具等。各个工具各司其职,无缝配合。
以下是自己虚拟机环境做的OceanBase4.0社区版本单机分布式部署详细过程,部署过程中也遇到了一些问题点分享给大家,一起交流学习。
[root@rhel76 ~]# cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.6 (Maipo)
[root@rhel76 ~]# vi /etc/fstab
#添加如下内容
tmpfs /dev/shm tmpfs defaults,size=8G 0 0
[root@rhel76 ~]# mount -o remount /dev/shm
[root@rhel76 ~]# df -h /dev/shm/
Filesystem Size Used Avail Use% Mounted on
tmpfs 8G 0 8G 0% /dev/shm
OB 3时代的时候显然会比较麻烦,经常遇到由于资源不足导致启动失败。通过以上方法,给操作系统分配了8G的内存,OceanBase 社区版4.0版本已经支持4c8g的配置来安装了,这对电脑配置低的小伙伴确实是个福音,另外对于 CPU 和内存使用做了大量的优化,实测在 4C8G 环境下跑的很流畅,4C8G轻松部署,相比Tidb、达梦数据库,基本上我的电脑小风扇已经转起来了。目前主流的PC一般可以达到8C16G,这很大程度上能让更多的喜欢OB的用户能随时随地随心所欲的去搞起来。
##设置Hostname
[root@rhel76 ~]# hostnamectl set-hostname OceanBase
hostnamectl set-hostname永久主机名 是对/etc/hostname文件的内容进行修改
第一步下载安装包,全家桶安装包all-in-one package大小一共 246MB,是为了方便用户能够一键安装 OceanBase 相关组件推出的一站式安装包。OBD、OceanBase 数据库、 OBProxy、obagent、Grafana 和 Prometheus ,一应俱全啊。将所有组件提前做好适配测试并给出推荐组合版本。
第二步就是通过以下tar -xzf命令解压安装包。
最后一步我就是一键安装,用户只需要不到2分钟的等待,部署更快,体验感更强。当安装 grafana 或 prometheus 时,会输出 grafana 或 prometheus 访问地址,整个安装过程很流畅,而且日志输出的非常详细。安装结束后通过执行which obd 和 which obclient 检测是否安装成功,如果可以找到 obd 和 obclient 表示安装成功。
[root@oceanbase ~]# cd oceanbase-all-in-one/bin/
[root@oceanbase bin]# ./install.sh
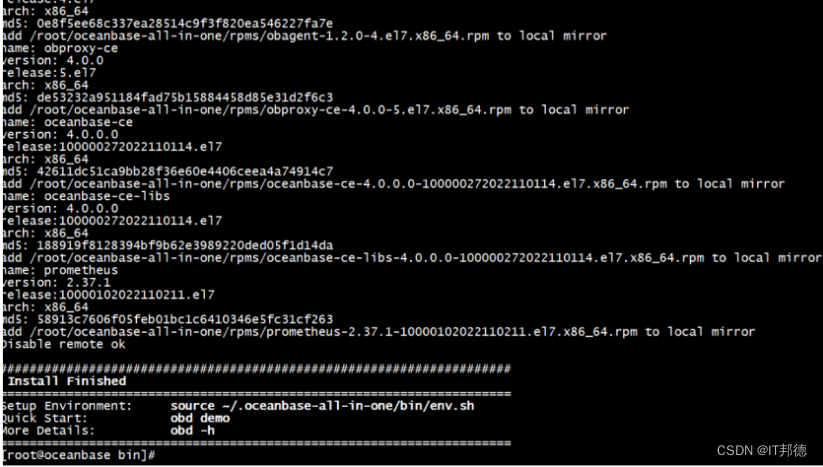
在这里我使用 obd demo 快速部署单机,部署并启动 OceanBase 数据库。
[root@oceanbase ~]# cd oceanbase-all-in-one
[root@oceanbase oceanbase-all-in-one]# obd demo
集群的管理命令也很便捷,都可以实现一键管理,相对其他集群管理的数据库,OB这块做的简单明了,集群可随时创建,也可随时销毁释放资源。之前体验其他国产数据库,常发生集群销毁不干净而导致二次安装失败。
关闭集群:obd cluster stop demo
销毁集群:obd cluster destroy demo
查看集群: obd cluster list
最后再看看如何连接OceanBase租户,MySQL 命令行客户端或者图形化工具上也是能连接 OceanBase 的租户。此外,OceanBase 也提供专属的命令行客户端工具 ODC 。ODC 是对 OceanBase 适配性最好的客户端工具。新创建的业务租户的管理员(root)密码默认是空的,需要改密码。
# 使用 OBClient 客户端连接到 OceanBase 数据库
[root@oceanbase ~]# obclient -h127.0.0.1 -uroot -P2881
# 修改sys租户管理员密码
obclient [(none)]> alter user root identified by ‘jem’;
OceanBase 数据库具有多租户的特性,在集群层面实现了实例资源的池化。在 OceanBase 数据库中,每一个租户即一个实例(类比 MySQL instance)。租户与租户之间数据、权限、资源隔离,每个租户拥有自己独立的访问端口及 CPU、内存访问资源。
OceanBase 数据库可以灵活的调整租户资源分配情况(CPU、内存),并且整个过程对上层业务透明。通过多租户机制,OceanBase 集群可以帮助用户高效的利用资源,在保证可用性和性能的前提下,优化成本,并且做到按照需求弹性扩容。
多租户只需要三步,unit资源配置、创建资源池、创建租户即可搞定。
可以看到集群下两个租户的资源、数据、权限都是隔离的。这种多租户隔离,可以解决租户的在线DDL,数据存储高压缩比这些痛点。租户提供分区表的水平拆分方案,提供原生的 SQL 和事务能力,对业务透明。并且支持在线扩容和缩容,内部数据迁移异步进行,具备高可用能力,不怕扩容和缩容过程中出现故障。所有的租户按需分配,弹性伸缩,具备高可用能力,类似于云数据库服务。运维人员只需要维护少数几套集群,就可以提供很多实例给业务使用,易用性非常好。
在启动集群的过程中,如如下报错,表示一个是用户最大打开文件数不够
[ERROR] OBD-1007: (127.0.0.1) open files must not be less than 20000 (Current value: 1024)
linux系统默认open files数目为1024, 有时应用程序会报Too many open files的错误,是因为open files 数目不够。这就需要修改ulimit和file-max。特别是提供大量静态文件访问的web服务器,缓存服务器(如squid), 更要注意这个问题。
1.修改file-max
# vi /etc/sysctl.conf, 加入以下内容,重启生效
fs.file-max=102400
net.nf_conntrack_max = 1024000
net.netfilter.nf_conntrack_max = 1024000
2.修改ulimit的open file,系统默认的ulimit对文件打开数量的限制是1024
# vi /etc/security/limits.conf //加入以下配置,重启即可生效
* hard nofile 102400
* soft nofile 102400
其实OceanBase 在社区和用户的驱动下得到了飞速发展,能力不断突破。核心内核引擎的 300 万行代码完全对外开放开源。并且不断完善OceanBase 的生态工具,核心目标就是从“能用”到“更好用”,在易用性上怎样做监控、怎样做运维、怎样做数据同步链路可视化是下足了功夫,不断的提升数据库自治能力。OceanBase 4.0 对多租户的能力及 DBPaaS 能力做了提升,帮助客户更好地进行资源整合,可以同时支持 CPU 的隔离及IOPS 的强隔离。测试表明,同等硬件的环境之下,OceanBase 社区版 4.0 版本的性能是 Greenplum6.22 的 5-6 倍,部分性能场景性能达到 20-60 倍。对比了 OceanBase 和 MySQL 的性能,当时使用的是 MySQL 企业版 8.0 与 OceanBase 的企业版4.0,在同等硬件条件下,OceanBase 企业版 4.0 的性能是 MySQL 企业版 8.0 的 1.9 倍。
单机分布式一体化架构要求兼具分布式的扩展性和集中式数据库的功能和单机性能。事务的 ACID( Atomicity,Consistency,Isolation,Durability)是数据库的基本要求,而分布式数据库的难点就在于如何在异常场景下保证事务的 ACID,核心就是如何基于重做日志(Redo log)实现故障恢复,以及基于重做日志实现异常场景下分布式事务的原子性。OceanBase 4.0 克服了这些技术难题,实现了在线水平扩展的同时不增加分布式相关 overhead,从而能够像集中式数据库一样部署在小规格的服务器上,做到单节点性能达到甚至超越集中式数据库的水平。当然,OceanBase 每个版本走向成熟都离不开大量真实业务场景的打磨。OceanBase 4.0 的很多创新和想法来源于用户的需求或者建议。真正的做到了与用户和开发者共同成长。
从分布式数据库的下游应用领域来看,当前分布式数据库主要应用于金融、电信、互联网等产生海量数据的行业,以及快递物流、餐饮服务、旅游服务等C端客户较多的行业。随着金融业务数据量的高速增长,数据系统管理弹性需求提升、数据系统访问查询需求提升,都对数据的存储、处理、挖掘都有更强的需求。当前金融应用层面开始普遍使用分布式架构,但数据库层面却仍然普遍采用集中式架构,这是由于金融行业对于数据存储的要求较为严格。不过随着分布式数据库技术的持续发展,国产金融级交易型分布式数据库已经在大型银行核心信用卡、账务系统等领域落地使用。互联网是分布式数据库最早开始使用的领域,这是由于互联网领域数据量大,面临的数据存储成本高,同时电商大促等场景下对于数据库的扩展性需求高,相信OceanBase分布式数据在用户不断的使用过程中,不段的改进和提升,肯定能够受到互联网企业的认可,引领国产数据库向更贴合用户需求的方向不断壮大,真正实现去IOE。OceanBase社区版 4.0确实给了我很多惊喜和对OceanBase未来版本演进的期待。

我们有一个目前在Rails2.3.12版和Ruby1.8.7版上运行的应用程序。我们想将我们的应用程序更新到Rails4.0和Ruby2.1.0。我们有大约200个模型和150个Controller。我想知道升级过程需要多大的努力。您还可以提供升级可以遵循的步骤。我们应该先升级Ruby然后再升级Rails还是相反? 最佳答案 您想要实现的目标将是史诗般的努力。我无法为您提供分步说明,因为不可能在一个答案中涵盖所有情况。我建议不要同时升级Ruby和Rails,而是分步升级。升级本身的复杂性是巨大的,但只要您的应用程序具有合理的测试覆盖
随着ruby被引入为新的编程救世主,我想知道是否有人基于易用性、运行所需的资源、可用性和易定制性而有偏好。两者有更好的吗? 最佳答案 好吧,任何基于Rails的社交网络应用程序的比较都应该包括insoshi(http://portal.insoshi.com/)。话虽这么说,这三个都非常相似,区别在于实现细节。Lovd和Insoshi都是完整的Rails应用程序;它旨在供您将它们用作入门工具包,并使用您自己的自定义功能对其进行扩展。另一方面,CommunityEngine是一个Rails插件。这意味着您可以更轻松地向现有Rail
我正在运行rspec测试以确保两个模型通过has_many和belongs_to相互关联。下面是我的测试。describe"testingforhasmanylinks"dobeforedo@post=Post.new(day:"Day1",content:"Test")@link=Link.new(post_id:@post.id,title:"google",url:"google.com")endit"inthepostmodel"do@post.links.first.url.should=="google.com"endend测试告诉我url是一个未定义的方法。我的测试有什么
现在我有21个“fsevent_watch”实例,其父进程和进程组是“ruby”。我正在开发一个Rails项目,但目前没有任何项目在运行。我之前启动的服务器是使用cntrl+C关闭的。我在Mac上。它是如何创建的?ruby应用关闭后不应该关闭吗? 最佳答案 这是由在您的Rails应用程序后台运行的spring服务器引起的。您可以通过以下方式检查spring状态,springstatus然后,停止spring服务器,springstop这将终止/关闭您看到的所有事件进程。 关于ruby-为
这让我发疯!我有两个模型Lion和Cheetah。两者都继承自Wildcat。classWildcat这里用的是STI。它们都通过ControllerWildcatsController进行处理。在那里,我有一个before_filer从params[:type]和所有其他东西中获取wildcat的type以使用正确的类.在我的routes.rb中,我创建了以下路线:resources:lions,controller:'wildcats',type:'Lion'resources:cheetahs,controller:'wildcats',type:'Cheetah'如果我现在想使
今天,我将尽可能地设置我的测试环境和工作流程。我正在向对Ruby测试充满热情和精通的你们寻求有关如何设置测试环境的实用建议。到一天结束时(太平洋标准时间早上6点?)我希望能够:键入一个1-command来为我在Github上找到的任何项目运行测试套件。为任何Github项目运行autotest,这样我就可以fork并做出可测试的贡献。使用Autotest和Shoulda从头开始构建gem。Foronereasonoranother,IhardlyeverruntestsforprojectsIclonefromGithub.Themajorreasonisbecauseunless
更详细地说,我有一个模块Narf,它为一系列类提供基本功能。具体来说,我想影响所有继承Enumerable的类。所以我在Enumerable中includeNarf。Array是默认包含Enumerable的类。然而,它不受Narf延迟包含在模块中的影响。有趣的是,在包含之后定义的类从Enumerable获取Narf。示例:#ThismoduleprovidesessentialfeaturesmoduleNarfdefnarf?puts"(from#{self.class})ZORT!"endend#IwantallEnumerablestobeabletoNarfmoduleEnu
我想知道是否有人在使用Rails4.0中的haml-railsgem时遇到过任何问题。有一个RailsCast那说有一些问题,但没有更多提及这一点。托管在GitHub上的gem也没有明确提及对Rails4.0的支持。那么这方面的进展如何? 最佳答案 我在Rails4项目中使用haml-rails(0.4),一切正常 关于ruby-on-rails-rails4.0上的haml-rails?,我们在StackOverflow上找到一个类似的问题: https:/
我刚刚遇到了一个关于关系和数据库的有趣情况。我正在编写一个ruby应用程序,我正在为我的数据库使用postgresql。我有一个父对象“用户”和一个相关对象“事物”,用户可以在其中拥有一个或多个事物。使用单独的表与仅将数据嵌入父表的字段中有什么优势?来自ActiveRecord的示例:使用相关表:defchangecreate_table:usersdo|i|i.text:nameendcreate_table:thingiesdo|i|i.integer:thingiei.text:discriptionendendclassUser使用嵌入式数据结构(多维数组)方法:defch
这是我在Rails中的第一个项目,即创建一个表来存储有关游戏的数据。我能够显示表格中有关获胜者得分、失败者得分等的数据。但是,我的表格列存在问题,其中包含每个游戏的删除链接。这是我在游戏Controller中删除方法的代码:defdelete@game=Game.find(params[:game])@game.destroy()redirect_to:action=>'index'end我的表格代码片段,其中包括link_to命令的行在我调用的路由文件中resources:games据我所知,这有助于生成基本路由。谁能帮我弄清楚为什么我的link_to不起作用?