Hive 搭建
前言:安装 Hive 之前请先确保你当前已经安装好了 Hadoop,并且运行正常。
本文中使用的 Hadoop 版本为 hadoop-3.1.3、Hive 版本为 hive-3.1.2、MySQL 版本为 MySQL 5.7。
集群其它生态安装与配置:
rpm -qa | grep mysql
rpm -qa | grep mariadb
# 强制删除
rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64

curl -O https://repo.mysql.com//mysql57-community-release-el7-11.noarch.rpm

如果出现错误:curl: (6) Could not resolve host: repo.mysql.com; 未知的错误,是由于 DNS 解析的问题导致的。
解决方法: 编辑文件 vim /etc/resolv.conf,在其中添加如下内容:
options timeout:2 attempts:3 rotate single-request-reopen
; generated by /usr/sbin/dhclient-script
nameserver 8.8.8.8
这样就可以正常获取下载源了。
yum localinstall mysql57-community-release-el7-11.noarch.rpm
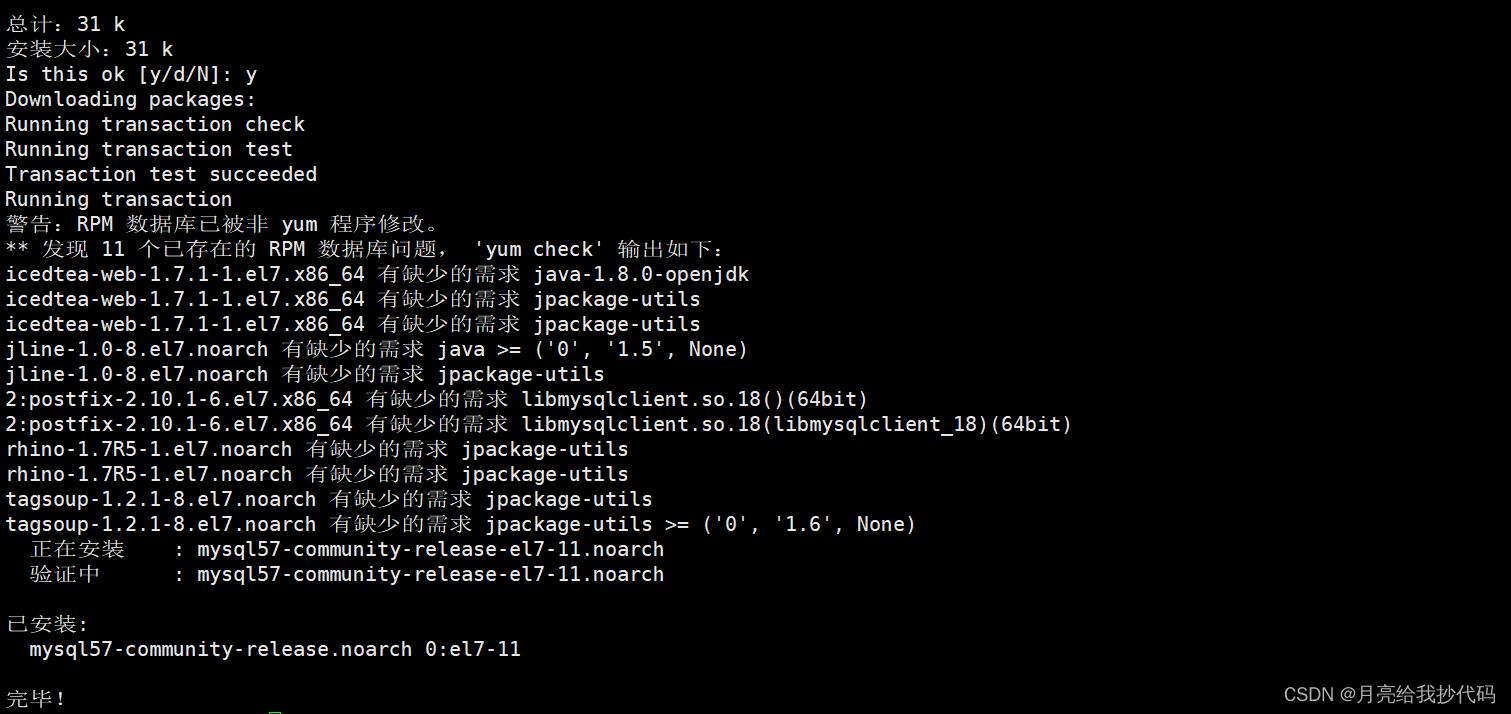
yum repolist enabled | grep "mysql.*-community.*"

yum install mysql-community-server
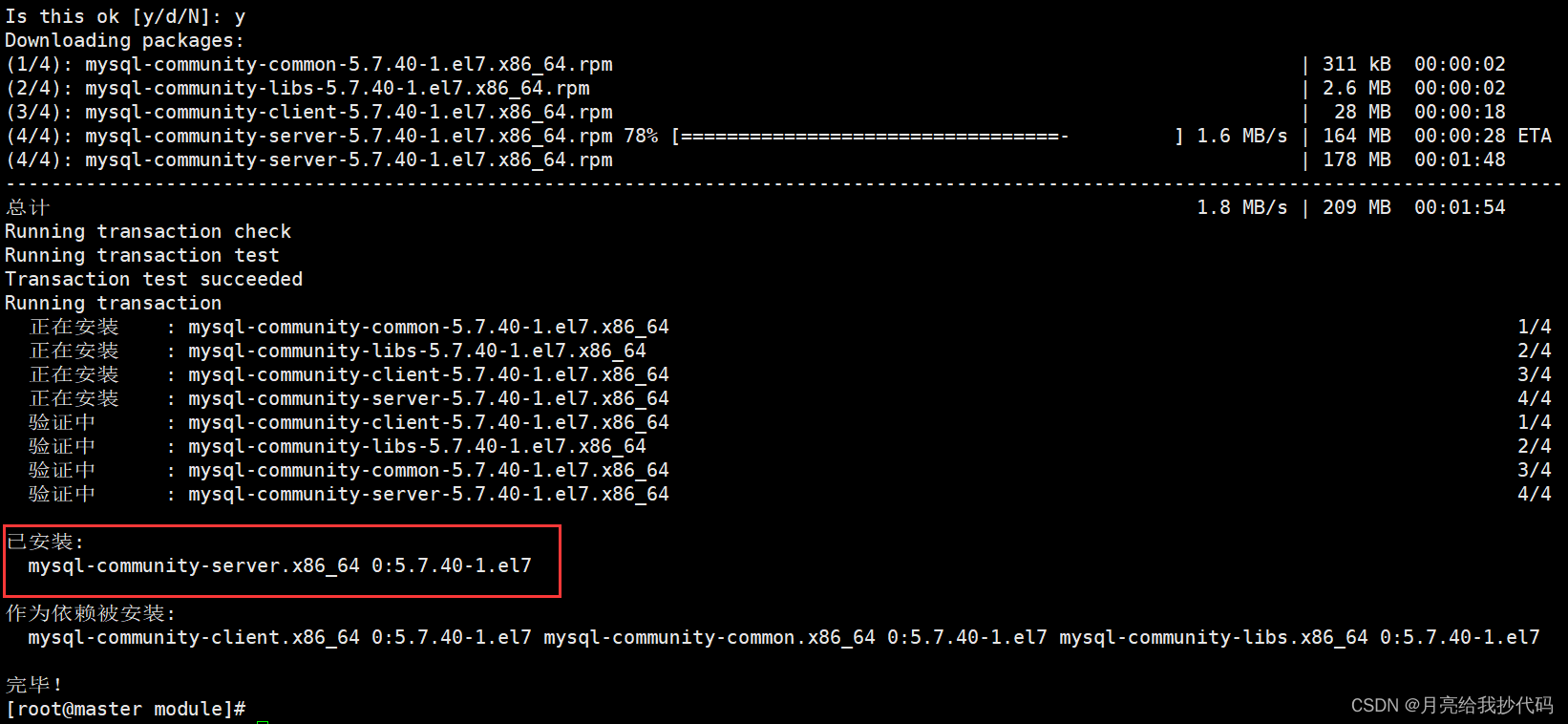
如果安装过程中出现如下错误时:

重新导入一个新的公钥即可:
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
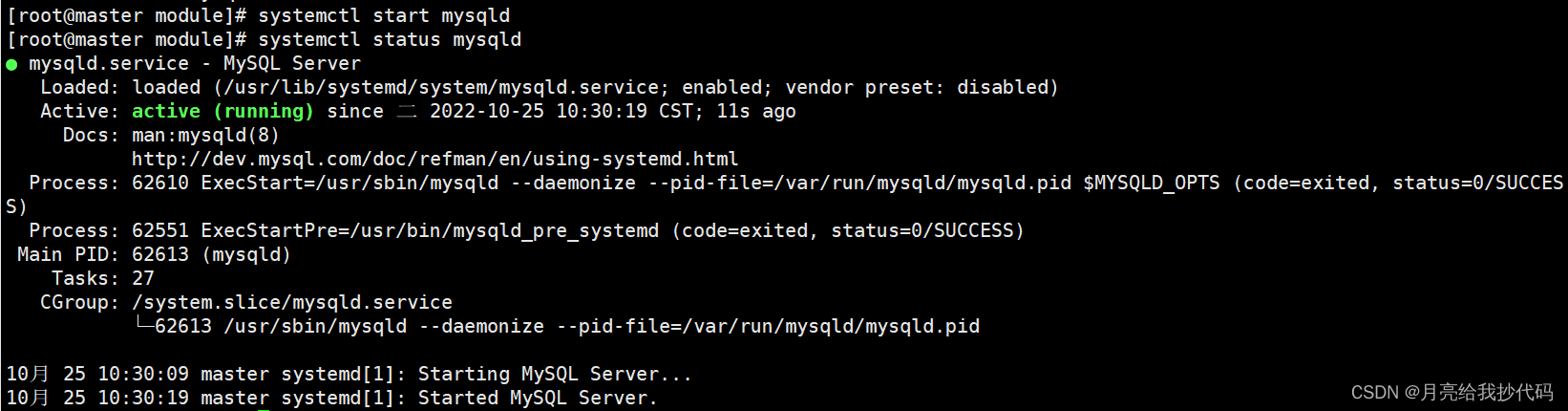
systemctl start mysqld
systemctl status mysqld
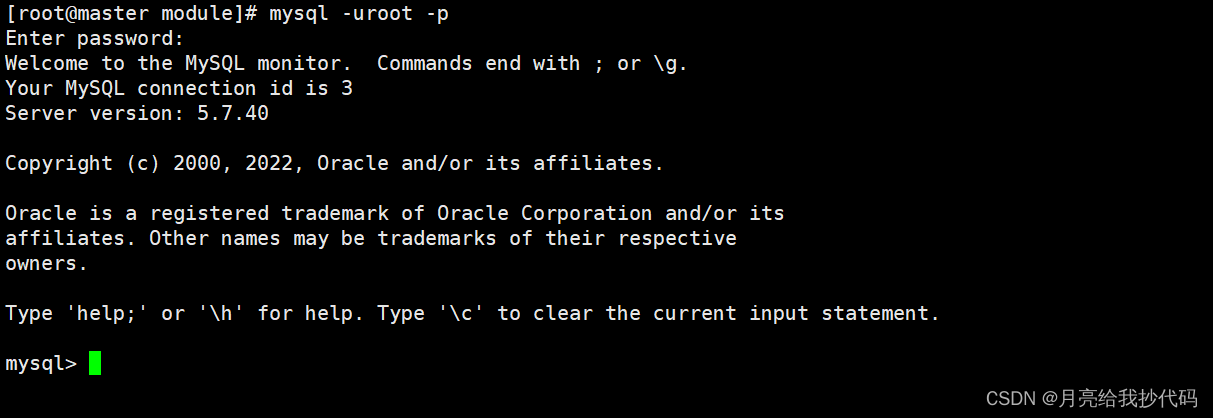
# 查看临时密码
cat /var/log/mysqld.log | grep password

# 输入临时密码进入 MySQL
mysql -uroot -p
# 进入后必须先修改密码!
set password = password("新密码");
如果你的密码过于简单,会出现如下错误:
Your password does not satisfy the current policy requirements.
修改其安全等级即可:
# 必须按顺序执行
set global validate_password_policy=0;
set global validate_password_length=1;

修改权限(允许所有用户连接):
update mysql.user set host='%' where user='root';
# 刷新权限
flush privileges;
MySQL 安装完成!
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
# 修改一下文件夹名称
cd /opt/module
mv apache-hive-3.1.2-bin/ hive-3.1.2
cp mysql-connector-java-5.1.37-bin.jar /opt/module/hive-3.1.2/lib/
vi /etc/profile
#HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
添加完成后使其立即生效:source /etc/profile
这一步也可以不做,只是后面启动 Hive 时会有一堆警告信息。
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak
cd $HIVE_HOME/conf
# 创建 hive-site.xml 文件
vi hive-site.xml
在文件中添加如下内容(结合自身配置的 MySQL 进行修改):
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 显示表头 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 显示当前库 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 配置元数据远程连接地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
</configuration>
# 进入 MySQL
mysql -uroot -p000000
# 创建元数据库(注意与 hive-site.xml 配置文件中连接的库保持一致)
create database if not exists metastore;
# 退出
quit;
# 初始化 Hive 元数据库
$HIVE_HOME/bin/schematool -initSchema -dbType mysql -verbose

请先启动 Hadoop 集群。
# 进入 Hive
$HIVE_HOME/bin/hive
# 创建任意库,检测是否正常。
create database if not exists test;

可以看到运行正常,这样我们的 Hive 就已经搭建完成啦!
hive-site.xml 中添加如下两项参数: <!-- 配置 hiveserver2 连接 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>
<!-- 设置权限用户 -->
<property>
<name>hive.users.in.admin.role</name>
<value>root</value>
</property>
注意更换成你自己连接的主机地址。
在 hadoop 的核心配置文件 core-site.xml 中添加如下两项参数:
指定集群可以连接的用户,我这里设置为 root 用户。
假如我想指定用户名为 master,则配置项中的 root 必须改为 master,如:hadoop.proxyuser.master.hosts。
<!-- 设置集群的连接用户 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
添加完成后注意分发该文件到其它机器,然后重启 Hadoop。
Hadoop 重启完成后,启动 hive 元数据服务与 hiveserver2 服务:
nohup hive --service metastore &
nohup hive --service hiveserver2 &
进入 Hive,选择需要操作的库,设置权限为 admin
set role admin;
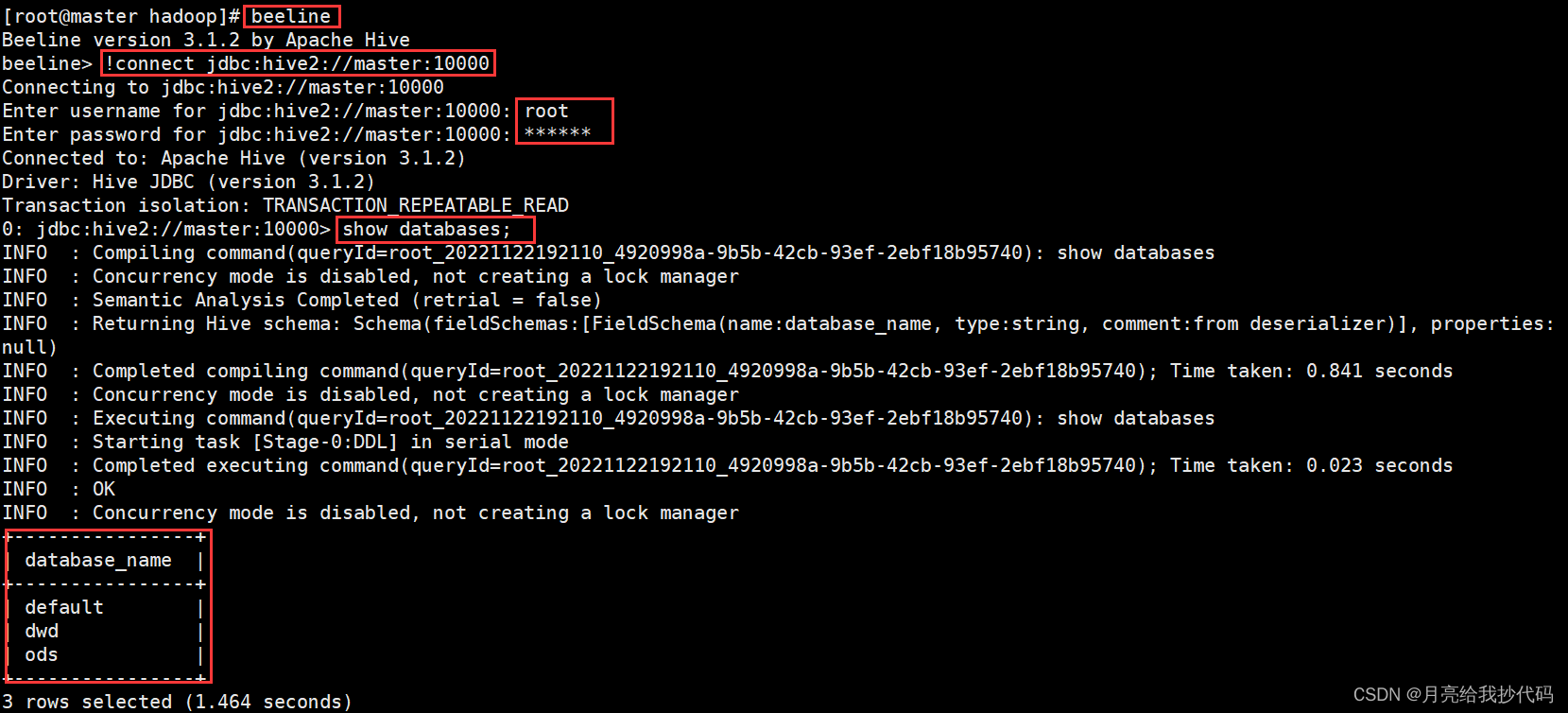
连接测试:
连接你绑定的地址并根据提示输入 Hadoop 核心配置文件中指定的用户与其密码。
beeline
!connect jdbc:hive2://master:10000
根据提示输入账号密码
如果你在通过 hiveserver2 服务远程插入数据时出现如下错误:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask
解决方法:
在插入的目标库中设置属性 set hive.stats.autogather=false;,关闭配置自动统计列的统计信息。
使用 hiveserver2 服务时异常停止,JVM 内存溢出:
FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Java heap space Exception in thread "HiveServer2-Handler-Pool: Thread-652" java.lang.OutOfMemoryError: GC overhead limit exceeded
解决方法:
修改 Hive 中 conf 目录下的 hive-env.sh 文件,将 export HADOOP_HEAPSIZE=1024 进行调整,可以修改为 4096,视情况而定;

保存退出,重新启动服务就可以啦。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
当我创建一个Rails应用程序时,控制台:railsnewfoo我的代码可以使用字符串“foo”吗?puts"Yourapp'snameis"+app_name_bar 最佳答案 Rails.application.class将为您提供应用程序的全名(例如YourAppName::Application)。从那里您可以使用Rails.application.class.parent获取模块名称。 关于ruby-on-rails-应用程序的名称是否可以作为变量使用?,我们在StackOve
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
我已经找到了几个使用datamapper的示例,并且能够让它们正常工作。不过,所有这些示例都是针对sqlite数据库的。我正在尝试将数据映射器与postgresql一起使用。我将datamapper中的调用从sqlite3更改为postgres,并且我已经安装了dm-postgres-adapter。但它仍然不起作用。我还需要做什么? 最佳答案 与SQLite不同,PostgreSQL不将数据库存储在单个文件中。在你拥有createdyourdatabase之后,尝试这样的事情:DataMapper.setup:default,{: