
前面我们了解到 Deployment 只是保证了支撑服务的微服务Pod的数量,但是没有解决如何访问这些服务的问题。一个Pod只是一个运行服务的实例,随时可能在一个节点上停止,在另一个节点以一个新的IP启动一个新的Pod,因此不能以确定的IP和端口号提供服务。
要稳定地提供服务需要服务发现和负载均衡能力。服务发现完成的工作,是针对客户端访问的服务,找到对应的后端服务实例。在K8S集群中,客户端需要访问的服务就是Service对象。每个Service会对应一个集群内部有效的虚拟IP,集群内部通过虚拟IP访问一个服务。
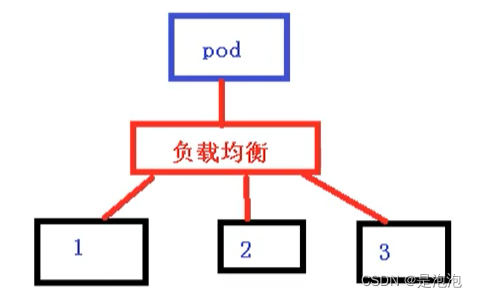
在K8S集群中,微服务的负载均衡是由kube-proxy实现的。kube-proxy是k8s集群内部的负载均衡器。它是一个分布式代理服务器,在K8S的每个节点上都有一个;这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的kube-proxy就越多,高可用节点也随之增多。与之相比,我们平时在服务器端使用反向代理作负载均衡,还要进一步解决反向代理的高可用问题。
因为Pod每次创建都对应一个IP地址,而这个IP地址是短暂的,每次随着Pod的更新都会变化,假设当我们的前端页面有多个Pod时候,同时后端也多个Pod,这个时候,他们之间的相互访问,就需要通过注册中心,拿到Pod的IP地址,然后去访问对应的Pod
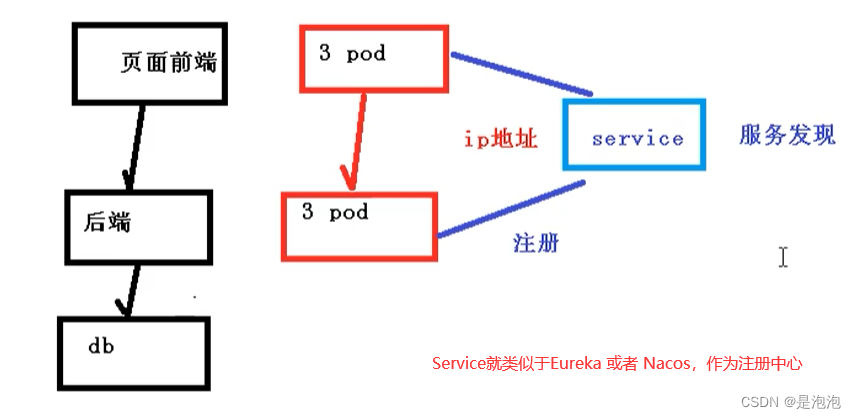
页面前端的Pod访问到后端的Pod,中间会通过Service一层,而Service在这里还能做负载均衡,负载均衡的策略有很多种实现策略,例如:
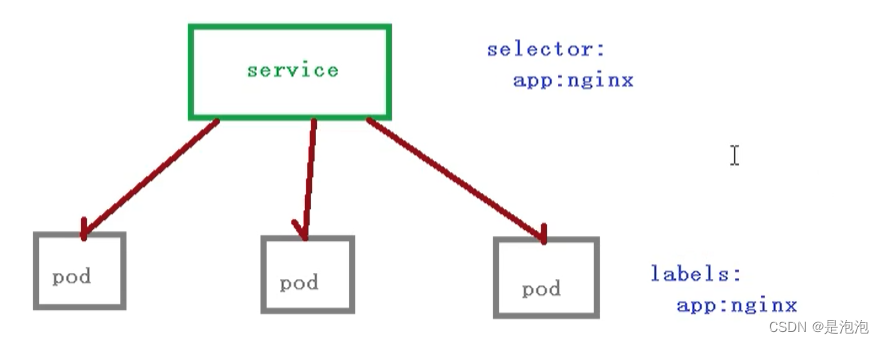
这里Pod 和 Service 之间还是根据 label 和 selector 建立关联的 【和Controller一样】
我们在访问service的时候,其实也是需要有一个ip地址,这个ip肯定不是pod的ip地址,而是 虚拟IP vip
Service常用类型有三种
我们可以导出一个文件 包含service的配置信息
kubectl expose deployment web --port=80 --target-port=80 --dry-run -o yaml > service.yaml
service.yaml 如下所示
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: web
status:
loadBalancer: {}
如果我们没有做设置的话,默认使用的是第一种方式 ClusterIp,也就是只能在集群内部使用,我们可以添加一个type字段,用来设置我们的service类型
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: web
type: NodePort
status:
loadBalancer: {}
修改完命令后,我们使用创建一个pod
kubectl apply -f service.yaml
然后能够看到,已经成功修改为 NodePort类型了,最后剩下的一种方式就是LoadBalanced:对外访问应用使用公有云
node一般是在内网进行部署,而外网一般是不能访问到的,那么如何访问的呢?
如果我们使用LoadBalancer,就会有负载均衡的控制器,类似于nginx的功能,就不需要自己添加到nginx上
在 kubernetes 中,Pod 是有生命周期的,如果 Pod 重启它的 IP 很有可能会发生变化。如果我们的服务都是将 Pod 的 IP 地址写死,Pod 挂掉或者重启,和刚才重启的 pod 相关联的其他服务将会找不到它所关联的 Pod,为了解决这个问题,在 kubernetes 中定义了 service 资源对象,Service 定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,service 是一组 Pod 的逻辑集合, 这一组 Pod 能够被 Service 访问到,通常是通过标签选择器实现的。
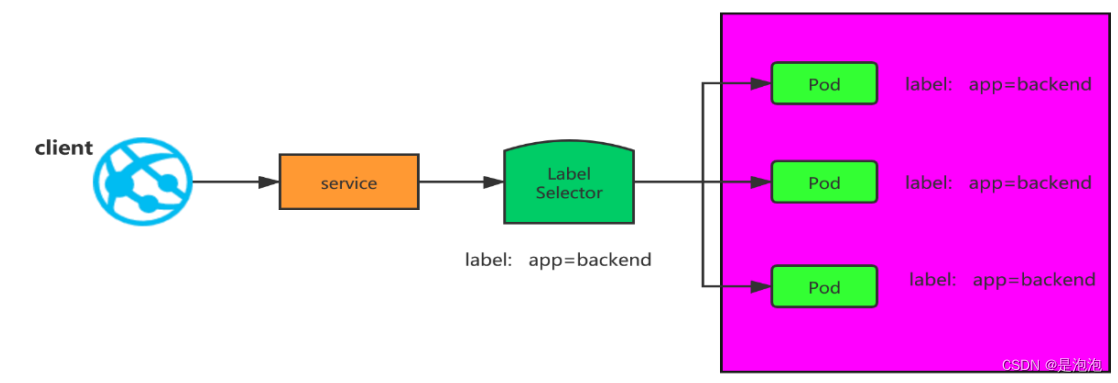
1、pod ip 经常变化,service 是 pod 的代理,我们客户端访问,只需要访问 service,就会把请求代理到 Pod
2、pod ip 在 k8s 集群之外无法访问,所以需要创建 service,这个 service 可以在 k8s 集群外访问 的。
service 是一个固定接入层,客户端可以通过访问 service 的 ip 和端口访问到 service 关联的后端 pod,这个 service 工作依赖于在 kubernetes 集群之上部署的一个附件,就是 kubernetes 的 dns 服务 (不同 kubernetes 版本的 dns 默认使用的也是不一样的,1.11 之前的版本使用的是 kubeDNS,较新的版本使用的是 coredns),service 的名称解析是依赖于 dns 附件的,因此在部署完 k8s 之后需要再部署 dns 附件,kubernetes 要想给客户端提供网络功能(比如分配ip),需要依赖第三方的网络插件(flannel,calico 等)。每个 K8s 节点上都有一个组件叫做 kube-proxy,kube-proxy 这个组件将始终监视着 apiserver 中有关 service 资源的变动信息,需要跟 master 之上的 apiserver 交互,随时连接到 apiserver 上获取任何一个与 service 资源相关的资源变动状态,这种是通过 kubernetes 中固有的一种请求方法 watch(监视) 来实现的,一旦有 service 资源的内容发生变动(如创建,删除),然后操作会被存在etcd里,然后会把我们的请求调度到后端特定的 pod 资源之上的规则,这个规则可能是 iptables,也可能是 ipvs,取决于 service 的实现方式(可以自己配置规则)。比如创建了一个新的svc,svc会有一个ip,这个ip的网段是创建集群的时候配置的(默认是10),不过这个ipping不通,是只存在于防火墙规则里的虚拟ip。
k8s 在创建 Service 时,会根据标签选择器 selector(lable selector)来查找 Pod,据此创建与 Service 同名的 endpoint 对象,当 Pod 地址发生变化时,endpoint 也会随之发生变化,service 接收前端 client 请求的时候,就会通过 endpoint,找到转发到哪个 Pod 进行访问的地址。(至于转发到哪个节点的 Pod,由负载均衡 kube-proxy 决定)
[root@k8smaster node]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.11.139:6443 15d
[root@k8smaster node]# kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE
kube-apiserver-k8smaster 1/1 Running 4 15d 192.168.11.139 k8smaster
apiserver是绑定了宿主机的网络ip,apiserver这个pod,封装的k8sapiservice服务端口是443,这个service关联的pod是apiserver,ednpoints列表里编写的也是apiserverpod的ip和端口
1、Node Network(节点网络):物理节点或者虚拟节点的网络,如 ens33 接口上的网路地址
[root@k8smaster node]# ip addr
ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:94:59:0f brd ff:ff:ff:ff:ff:ff
inet 192.168.11.139/24 brd 192.168.11.255 scope global noprefixroute dynamic ens3
2、Pod network(pod 网络),创建的 Pod 具有的 IP 地址
[root@k8smaster node]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
frontend-d5tr9 1/1 Running 0 23h 10.244.2.30 k8snode <none>
Node Network 和 Pod network 这两种网络地址是我们实实在在配置的,其中节点网络地址是配置在节点接口之上,而 pod 网络地址是配置在 pod 资源之上的,因此这些地址都是配置在某些设备之上的,这些设备可能是硬件,也可能是软件模拟的
3、Cluster Network(集群地址,也称为 service network),这个地址是虚拟的地址(virtual ip),没有配置在某个接口上,只是出现在 service 的规则当中。
[root@xianchaomaster1 ~]# kubectl get svc
[root@k8smaster node]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 15d
创作不易,如果觉得内容对你有帮助,麻烦给个三连关注支持一下我!如果有错误,请在评论区指出,我会及时更改!
目前正在更新的系列:从零开始学k8s
感谢各位的观看,文章掺杂个人理解,如有错误请联系我指出~

这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。我需要从基于ruby的应用程序使用AmazonSimpleNotificationService,但不知道从哪里开始。您对从哪里开始有什么建议吗?
我正在开发一个Rails应用程序,我需要在其中找到给定特定偏移量或时区的夏令时开始和结束日期。我基本上在我的数据库中保存了从用户浏览器接收到的时区偏移量(“+3”,“-5”),我想在它出现时修改它由于夏令时的变化。我知道Time实例变量有dst?和isdst方法,如果存储在它们中的日期在夏令时与否。>Time.new.isdst=>true但是使用它来查找夏令时的开始和结束日期会占用太多资源,而且我还必须为我拥有的每个时区偏移量执行此操作。我想知道更好的方法。 最佳答案 好的,基于你所说的和@dhouty'sanswer:您希望能够
我有一台生产机器和一台开发机器,都运行ubuntu8.10并且都运行最新的phusionpassenger。当我在osx上的本地开发机器上使用ruby1.9.1时,我想知道外面的人是否已经在使用带有ruby1.9.1甚至1.9.2的phusionpassenger?如果是这样,请告诉我们您的设置!此外,有没有办法在apache上使用phusionpassenger同时运行ruby1.8.7(ree)和1.9.1?感谢您的指点,我在任何地方都找不到任何提示... 最佳答案 是的,从某些2.2.x版本开始就正式支持它,我不记
date_select方法只能设置:start_year,但我想设置开始日期(例如3个月前的日期)(但没有这样的选项)。那么,我可以将开始日期设置为date_select方法吗?或者,要制作这样的选择框,我应该使用select_tag和options_for_select吗?或者,有什么解决办法吗?谢谢, 最佳答案 有可能……例如:start_year–设置年份选择的开始年份。默认为Time.now.year-5参见thisresource. 关于ruby-Rails3-我可以将开始日期
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
我有一些使用delayed_job的小程序。在我的本地主机上一切正常,但是当我将我的应用程序部署到Heroku并单击应该由delayed_job执行的链接时,没有任何反应,“任务”只是保存到表delayed_job中。Inthisarticleonherokublog写入时,执行delayed_job表中的任务,当运行此命令时rakejobs:work。但是我怎样才能运行这个命令呢?命令应该放在哪里?在代码中,还是从终端控制台? 最佳答案 如果您正在运行Cedar堆栈,请从终端控制台运行以下命令:herokurunrakejobs:
我是Ruby分析的新手,看起来像ruby-prof是一个受欢迎的选择。我刚刚安装了gem并调用了我的程序:ruby-prof./my-prog.rb但是,输出非常冗长,因为包含所有Ruby核心和标准库方法以及其他gem的分析数据。例如,前三行是:8.790.0110.0100.0000.0013343*String#%7.280.0780.0090.0000.0692068*Array#each4.930.0380.0060.0000.0321098*Array#map这对我来说不是什么有用的信息,因为我已经知道我的程序经常处理字符串和数组,并且大概已经对这些类进行了优化。我只关心我代
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。多年来,我一直在使用多种语言进行编程,并且认为自己总体上相当擅长。但是,我从未编写过任何自动化测试:没有单元测试,没有TDD,没有BDD,什么都没有。我已经尝试开始为我的项目编写适当的测试套件。我可以看到在进行任何更改后能够自动测试项目中所有代码的理论值(value)。我可以看到像RSpec和Mocha这样的测试框架应该如何使设置和运行所述测试变得相当容易