Self-attention 有一个进阶的版本,叫做 Multi-head Self-attention, Multi-head Self-attention,其实今天的使用是非常地广泛的 。
在LHY2021作业 4 裡面,助教原来的 code 4 有,Multi-head Self-attention,它的 head 的数目是设成 2,那刚才助教有给你提示说,把 head 的数目改少一点 改成 1,其实就可以过medium baseline
但并不代表所有的任务,都适合用比较少的 head,有一些任务,比如说翻译,比如说语音辨识,其实用比较多的 head,你反而可以得到比较好的结果至於需要用多少的 head,这个又是另外一个hyperparameter,也是你需要调的那為什麼我们会需要比较多的 head 呢,你可以想成说相关这件事情我们在做这个 Self-attention 的时候,我们就是用 q 去找相关的 k,但是相关这件事情有很多种不同的形式,有很多种不同的定义,所以也许我们不能只有一个 q,我们应该要有多个 q,不同的 q 负责不同种类的相关性
所以假设你要做 Multi-head Self-attention 的话,你会怎麼操作呢?
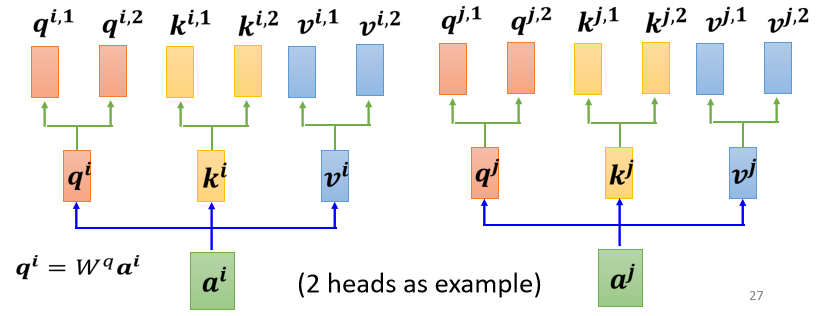
1.先把 a 乘上一个矩阵得到 q
2.再把 q 乘上另外两个矩阵,分别得到 跟
,那这边还有 这边是用两个上标,i 代表的是位置,然后这个 1 跟 2 代表是,这个位置的第几个 q,所以这边有
跟
,代表说我们有两个 head
我们认為这个问题,裡面有两种不同的相关性,是我们需要產生两种不同的 head,来找两种不同的相关性。既然 q 有两个,那 k 也就要有两个,那 v 也就要有两个,从 q 得到和
,从 k 得到
和
,从 v 得到 ,那其实就是把 q 把 k 把 v,分别乘上两个矩阵,得到这个不同的 head,就这样子而已,对另外一个位置,也做一样的事情。
只是现在,它在算这个 attention 的分数的时候,它就不要管那个
了
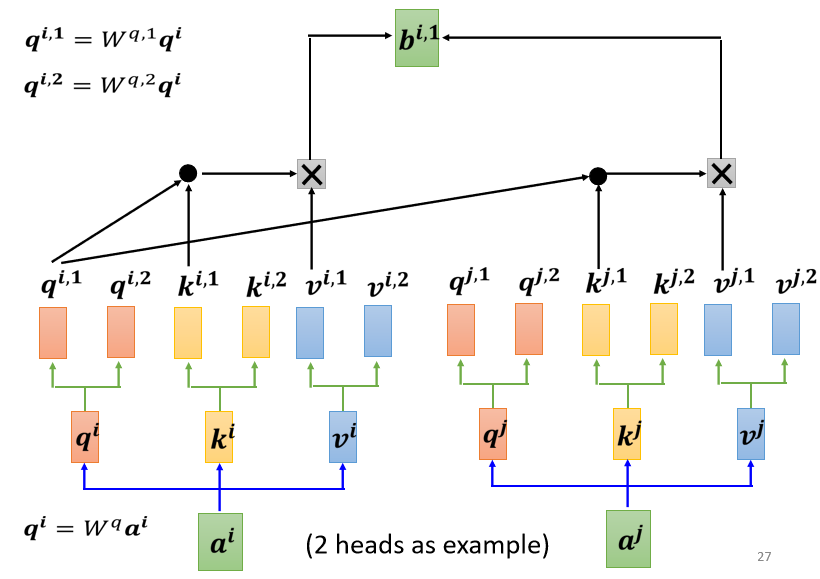
所以 就跟
算 attention
就跟算
attention,也就是算这个 dot product,然后得到这个 attention 的分数
然后今天在做 weighted sum 的时候,也不要管 了,看
就好,所以你把 attention 的分
数乘 ,把 attention 的分数乘
,然后接下来就得到
这边只用了其中一个 head,那你会用另外一个 head,也做一模一样的事情
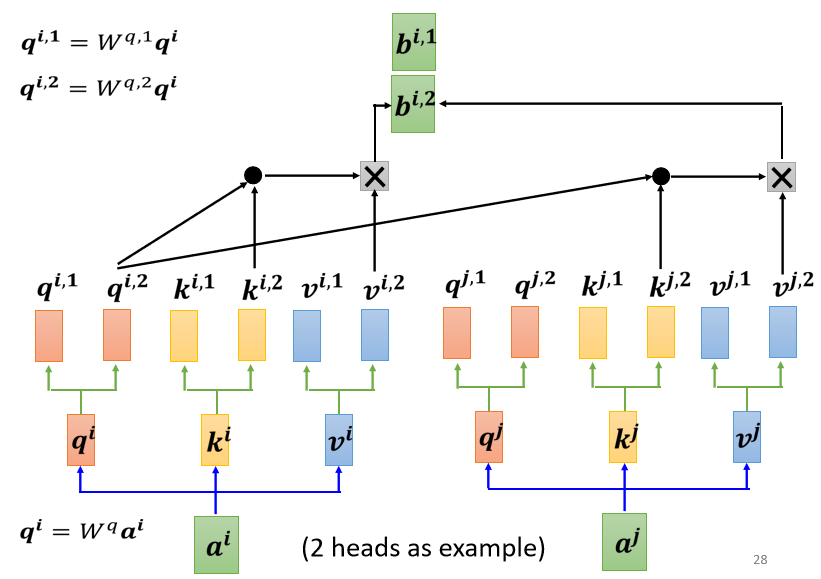
如果你有多个 head,有 8 个 head 有 16 个 head,那也是一样的操作,那这边是用两个 head 来当作例子,来给你看看有两个 head 的时候,是怎麼操作的,现在得到的bi1和bi2
然后接下来你可能会把 跟
,把它接起来,然后再通过一个 transform。
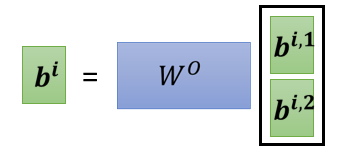
也就是再乘上一个矩阵,然后得到 bi,然后再送到下一层去,那这个就是 Multi-head attention,一个这个Self-attention 的变形
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
在previousquestion中我想出了如何在多个服务器上启动经过密码验证的sshsession来运行单个命令。现在我需要能够执行“sudo”命令。问题是,net-ssh-multi没有分配sudo需要运行的伪终端(pty),导致以下错误:[127.0.0.1:stderr]sudo:sorry,youmusthaveattytorunsudo根据documentation,可以通过调用channel对象的方法来分配伪终端,但是,以下代码不起作用:它会生成上面的“notty”错误:require'net/ssh'require'net/ssh/multi'Net::SSH::Mul
我有以下代码#coloursarandomcellwithacorrectcolourdefcolour_random!whiletruedocol,row=rand(columns),rand(rows)cell=self[row,col]ifcell.empty?thencell.should_be_filled??cell.colour!(1):cell.colour!(0)breakendendend做什么并不重要,尽管它应该很明显。关键是Rubocop给了我一个警告Neveruse'do'withmulti-line'while为什么我不应该那样做?那我该怎么办呢?
我正在使用Ruby-Tk为OSX开发一个桌面应用程序,我想为该应用程序提供一个AppleEvents接口(interface)。这意味着应用程序将定义它将响应的AppleScript命令的字典(对应于发送到应用程序的Apple事件),并且用户/其他应用程序可以使用AppleScript命令编写Ruby-Tk应用程序的脚本。其他脚本语言支持此类功能——Python通过位于http://appscript.svn.sourceforge.net/viewvc/appscript/py-aemreceive/的py-aemreceive库和Tcl通过位于http://tclae.source
Method#unbind返回对该方法的UnboundMethod引用,稍后可以使用UnboundMethod#bind将其绑定(bind)到另一个对象.classFooattr_reader:bazdefinitialize(baz)@baz=bazendendclassBardefinitialize(baz)@baz=bazendendf=Foo.new(:test1)g=Foo.new(:test2)h=Bar.new(:test3)f.method(:baz).unbind.bind(g).call#=>:test2f.method(:baz).unbind.bind(h).
显示等待需要用到两个类:WebDriverWait和expected_conditions两个类WebDriverWait:指定轮询间隔、超时时间等expected_conditions:指定了很多条件函数(也可以自定义条件函数)具体可以参考官网:selenium.webdriver.support.expected_conditions—Selenium4.5documentationfromseleniumimportwebdriverfromselenium.webdriver.common.byimportByfromselenium.webdriver.support.uiimpor
关于轴承相关的项目之前做的大都是故障识别诊断类型的,少有涉及回归预测的,周末的时候宅家发现一个轴承寿命加速实验的数据集就想着拿来做一下寿命预测。首先看下数据集如下:直接百度即可搜到,这里就不再赘述了。Learning_set为训练集Test_set为测试集我这里为了简单处理直接使用Learning_set作为总数据集,随机划分指定比例作为测试集。当然了你也可以选择分别读取加载两部分的数据分别作为训练集和测试集都可以的。每个目录下都是一堆csv文件,样例如下:样例数据内容如下:9,11,19,1.1879e+05,0.059,-0.3729,11,19,1.1883e+05,0.603,-0.0
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。社区在12个月前审查了是否重新打开此问题,并将其关闭:原始关闭原因未解决最近学习了Ruby编程语言,总的来说是一门很好的语言。但是我很惊讶地发现它并不像我预期的那么简单。更准确地说,“最小惊喜规则”在我看来并不是很受尊重(当然这是相当主观的)。例如:x=trueandfalseputsx#displaystrue!和著名的:puts"zeroistrue
我收到错误AWS::S3::Errors::InvalidRequest不支持您提供的授权机制。请使用AWS4-HMAC-SHA256.当我尝试将文件上传到新法兰克福地区的S3存储桶时。所有适用于USStandard区域。脚本:backup_file='/media/db-backup_for_dev/2014-10-23_02-00-07/slave_dump.sql.gz's3=AWS::S3.new(access_key_id:AMAZONS3['access_key_id'],secret_access_key:AMAZONS3['secret_access_key'])s3_
【摘 要】近年来,基于自注意力机制的神经网络在计算机视觉任务中得到广泛的应用。随着智能交通系统的广泛应用,面对复杂多变的交通场景,车牌识别任务的难度不断提高,准确识别的需求更加迫切。因此提出一个基于自注意力的免矫正的车牌识别方法T-LPR。首先对图像进行切片和序列化,并使用3D卷积对切片序列进行特征提取,从而得到图像的嵌入向量序列。然后将嵌入向量序列输入基于TransformerEncoder的编码器中,学习各个嵌入向量之间的关系并输出最终的编码结果。最后使用分类器进行分类。在多个公共数据集上的实验结果表明,所提方法对各类困难场景下的车牌识别都非常有效。【关键词】车牌识别 ; 图像嵌入向量 ;