故事从一个“美好”的早上开始…
大清早的来到公司,打开电脑,emm, 还是熟悉的味道,鱼儿被我摸熟了的味道…就在开始准备一天的摸鱼之旅的时候,一种不详的预感涌上心头。
“小李啊!公司那个文档中心的项目,上线了。但是SEO效果不太理想啊。这段时间,你跟进一下,争取达到预期的效果”。组长不知道啥时候已经站在了我的身后。
“没问题,保证完成任务”。此时此刻我的内心独白是:“啥玩意?SEO?那不是给百度充钱就行吗?我一个前端做啥SEO?”
好吧,作为一个刚来公司一个多月的新人,我有拒绝的权利吗?我没有。就这样,开始了我骂骂咧咧的SEO之旅…
首先说说,什么是SEO
SEO(Search Engine Optimization):汉译为搜索引擎优化。是一种方式:利用搜索引擎的规则提高网站在有关搜索引擎内的自然排名。
上述是百度百科的解释。通俗的来说,SEO就是利用各种有效方式,让自己的网站可以被别人在浏览器上搜索到,并且在搜索结果的前列。
了解了什么是SEO,那SEO到底有啥作用。引用一段网上的一段说明:
1、提升网站的流量;通过SEO来提高网站的自然排名,从而提高网站的流量。
2、提高目标客户的精准性;SEO人员可以针对用户的访问数据对网站进行相应的优化,更容易提高目标用户的精准性;
3、提高网站的关键词排名,从而提高品牌知名度。
通过上述的了解,我们可以得出一点。并不是所有的网站都需要做SEO。只要这个网站需要被别人使用或浏览我们才需要做SEO比如: 稀土掘金,博客园。我们发布在上面的文章需要被别人浏览,所以这些平台就需要做SEO。而像是公司使用的一些管理平台、查询平台就并不需要做SEO。
在了解怎么做SEO之前,我们有必要先了解一下,在我们发布完网站,和用户能搜索到我们的网站,这个之间,浏览器到底干了些啥。
说了那么多。那到底怎么去做SEO? 其实做SEO的方式有很多种,比如给百度充钱…

还比如,在代码的层面进行SEO。那接下来就重点说下,在我们的前端项目中能进行哪些SEO操作
我们公司需要进行SEO的项目就是用的nuxt框架。其实在接触这个项目之前,我并没有接触过这个框架。但是经常看到别人的博客,说是用nuxt框架做SEO。所以在我的潜意识里面一直觉得,用了nuxt这个框架,就可以实现SEO了,我的网站就可以被别人搜索到了。但事实却并非如此。
那nuxt这个框架到底是用来干啥的呢。主要作用是提供两种方案:生成静态站点、服务端渲染。我大概说明一下这两种方案到底是个啥:
生成静态站点:就是将我们网站内的每一个页面,变成一个静态页面(以htm、html等结尾的页面),用户打开的网页实际上就是一个html静态页。
服务端渲染:就是将我们的网页,放到服务端生成。当用户打开一个页面之后,服务端返回的实际上是一个html文件。
以上的两种方式,都是有利于SEO的。为什么这么说呢,有很多可能没接触过SEO的小伙伴都可能都在吐槽了,上面的两种方案,怎么就有利于SEO了?
这里就不得不说到另外一款框架了,就是大家耳熟能详的框架:Vue。
用过Vue这款框架的小伙伴,都知道,Vue框架中的一个核心技术就是:虚拟DOM。所谓虚拟DOM,通俗的讲就是通过js渲染出的DOM。下述代码块中的ele_div,就可以说是虚拟DOM。
const ele_div = document.createElement('div');
document.body.appendChild(ele_div)
而虚拟DOM是不利于SEO的。为什么?因为虚拟DOM是通过js渲染出来的。通过上述的了解,我们发布完网站之后,浏览器会爬取我们的页面信息,但是这个时候,服务端返回的是一个js文件,之后才会慢慢的将js渲染成真实的DOM。而浏览器(搜索引擎)并不会等待网站去渲染真实DOM,这个时候浏览器抓取不到页面的有用信息。最终会导致,这个页面无法被收录。从而用户无法搜索到我们的网页。
现在再回头说一下为什么上述的两种方案有利于SEO,因为上述的两种方案中,浏览器进入到我们的页面的时候,浏览器访问到的就是一个html文件,搜索引擎可以有效的抓取页面的信息,从而收录。而收录是用户能搜索到我们网站的先决条件。
上述的两种方案都可以进行SEO,那我们应该选取哪种方案呢。这就要看具体的应用场景了。如果你的网站,页面数量相对固定,没有太多的变更,可以使用静态站点生成的技术。比如react官网就是使用该技术方案。如果你的网站可能经常会更新,比如稀土掘金,会有大量更新的文章,就需要使服务端渲染的技术。我司用的也是服务端渲染的技术方案。
那nuxt中是怎么做服务端渲染的呢?
title: '网站或网页的标题'
meta: [
{ hid: 'keywords', name: 'keywords', content: '关键字'},
{ hid: 'description', name: 'description', content: '网站描述' },
],
配置的这些网页信息,正是搜索引擎需要抓取的,从而有利于收录
在做SEO的过程中,网站的内容也是一个重要的作用点,比如你的网站内容和标题没有任何关系,大概率也不会被收录。下面列举一下有利于SEO的优化点:
其实上述的这些优化点,大部分都是网上查找到的,当我看到这么多注意点的时候,内心只有一个想法:求求了,直接给百度充钱吧…
当我们想着,有些页面可能并不希望被用户搜索到,该咋整呢,答案就是:robots
1.User-agent:Googlebot(谷歌)| Baiduspider(百度)| Slurp(Yahoo)| *(所有的搜索引擎)
// 定义哪些类型的搜索引擎可以抓取当前网站
2.Disallow:/admin
// 禁止搜索引擎爬取的文件夹或文件
3.Allow: /admin/test.js
// 允许搜索引擎爬取的文件夹或文件
如果你没有使用robots,那你网站的收录页面中就可能会有如下链接

你发布了一个网站,但是收录量一直不太好咋整,sitemap是你的不二选择。
是什么:可以是一个xml文件,其中包含了网站的各个页面的列表,有助于搜索引擎发现并了解网页的信息。
怎么用:可以使用线上的工具,直接生成。(因为没有使用过,不作推荐)。也可以自己手动生成,以nuxt项目为例,大致流程如下:
1.安装@nuxtjs/sitemap
2.在config中的module中注册
3.创建sitemap.js文件,在文件中合成要被搜索引擎发现的链接
4.在config中引入,并直接回填
import sitemap from 。。。
export default {
sitemap //直接引入
}
5.在robot.txt中引入
Sitemap:网站域名/sitemap.xml
最终生成的数据格式大致如下:
<urlset>
<url>
<!--必填标签,这是具体某一个链接的定义入口,每一条数据都要用<url>和</url>包含在里面 -->
<loc>http://www.yoursite.com/yoursite.html</loc>
<!--必填,URL 链接地址,长度不得超过 256 字节-->
<lastmod>2009-12-14</lastmod>
<!--可以不提交该标签,用来指定该链接的最后更新时间-->
<changefreq>daily</changefreq>
<!--可以不提交该标签,用这个标签告诉此链接可能会出现的更新频率 -->
<priority>0.8</priority>
<!--可以不提交该标签,用来指定此链接相对于其他链接的优先权比值,此值定于 0.0-1.0 之间-->
</url>
</urlset>
生成了sitemap之后有没有什么方法查看sitemap.xml文件吗,答案是有的。我们只需要在自己的网站后面直接拼接sitemap.xml, 回车输入即可,如下所示:

看到这,就有小伙伴就可能会问了,sitemap可以查看,那上文中所说的收录量有没有办法查看呢?结果是肯定的,我们只需要在浏览器搜索栏中输入site:项目域名即可,以vue官网为例:site:cn.vuejs.org/ 。
特殊提示,不要携带上网站的写协议(https:// )。
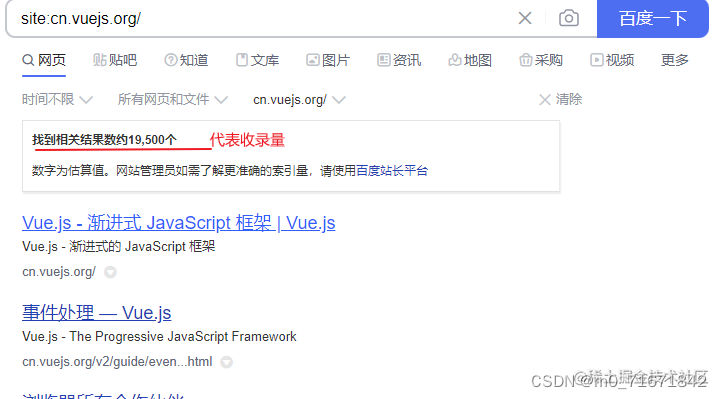
我们知道,搜索引擎收录网站页面之前,会沿着你的菜单链接,一个一个进入你的不同网页。当你网站有大量跳转链接时。搜索引擎就会吐槽了:小老弟,你这么多链接,我一个一个找,我也会累。所以百度提供了一种方式,就是urls.txt
作用:将当前网站所有的链接放到一个urls.txt中,搜索引擎直接爬取提供的链接,无需一个一个页面查找
使用:在项目的根目录下面,创建一个urls.txt文件,文件中填入你想让搜索引擎抓取的页面链接。之后在百度站长平台进行提交
站长平台链接:https://ziyuan.baidu.com/badlink/index
上述五种方式,就是我们可以在代码层面进行的操作。不难看出上述的操作,大部分操作都是让网页可以更好的被搜索引擎抓取,更好的收录。但是收录等于SEO吗?并不是。用户在搜索一个关键字的时候,会出现很多结果,对于那些排名靠后的网站,用户可能压根就不会点击。所以提高我们网站的排名很有必要。那作为一个前端还能通过哪些手段提高网站的排名呢,一起看看。
死链提交
什么是死链:简单地讲,死链接指原来正常,后来失效的链接
什么是死链提交:死链会影响网页的seo,当一个网页被收录之后,出现死链,会影响用户体验。搜索引擎会觉得,你这网站不是一个优质的网站,从而会影响网站的排名,所以我们需要手动的提交死链。
使用死链提交:在项目的根目录下面,创建一个.txt文件(文件名无要求),文件中填入网站中的死链,之后在百度站长平台进行提交。
外链
什么是外链:比如我把我们公司的网址放到现在这个页面,https://mddoc.shmedo.cn/ 。现在这个地址就是一个外链。就是说我们现在的网站,出现在了其他的网站上,其他网站上的那个我们的链接就是一个外链。
外链的作用:当我们拥有很多外链的时候,搜索引擎也会通过外链找到我们的网页,提升网页的收录量。当这些外链是一些优质的外链(外链所在的网址是一些优质的页面,将这个外链称之为优质的外链)时,搜索引擎会觉得,这些优质的网站愿意引用你们的网站,那你们的网站肯定也不错。提升了网站在搜索引擎中的好感度,从而有利于网站排名。
怎么使用外链:有专门的平台可以做外链,不过要花钱…花钱是不可能的。给你们提供一个思路哈,可以在那些点赞评论数比较高的博客下面,在评论区写上自己的网站链接。我是没干过哈,你们可以试一下。
一名前端能进行的SEO操作:

最后,感谢各位看官,观看至此。不好的地方,还请包涵。不对的地方,还请指正。
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我正在开发一个Rails应用程序,我需要在其中找到给定特定偏移量或时区的夏令时开始和结束日期。我基本上在我的数据库中保存了从用户浏览器接收到的时区偏移量(“+3”,“-5”),我想在它出现时修改它由于夏令时的变化。我知道Time实例变量有dst?和isdst方法,如果存储在它们中的日期在夏令时与否。>Time.new.isdst=>true但是使用它来查找夏令时的开始和结束日期会占用太多资源,而且我还必须为我拥有的每个时区偏移量执行此操作。我想知道更好的方法。 最佳答案 好的,基于你所说的和@dhouty'sanswer:您希望能够
我有一台生产机器和一台开发机器,都运行ubuntu8.10并且都运行最新的phusionpassenger。当我在osx上的本地开发机器上使用ruby1.9.1时,我想知道外面的人是否已经在使用带有ruby1.9.1甚至1.9.2的phusionpassenger?如果是这样,请告诉我们您的设置!此外,有没有办法在apache上使用phusionpassenger同时运行ruby1.8.7(ree)和1.9.1?感谢您的指点,我在任何地方都找不到任何提示... 最佳答案 是的,从某些2.2.x版本开始就正式支持它,我不记
date_select方法只能设置:start_year,但我想设置开始日期(例如3个月前的日期)(但没有这样的选项)。那么,我可以将开始日期设置为date_select方法吗?或者,要制作这样的选择框,我应该使用select_tag和options_for_select吗?或者,有什么解决办法吗?谢谢, 最佳答案 有可能……例如:start_year–设置年份选择的开始年份。默认为Time.now.year-5参见thisresource. 关于ruby-Rails3-我可以将开始日期
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
我有一些使用delayed_job的小程序。在我的本地主机上一切正常,但是当我将我的应用程序部署到Heroku并单击应该由delayed_job执行的链接时,没有任何反应,“任务”只是保存到表delayed_job中。Inthisarticleonherokublog写入时,执行delayed_job表中的任务,当运行此命令时rakejobs:work。但是我怎样才能运行这个命令呢?命令应该放在哪里?在代码中,还是从终端控制台? 最佳答案 如果您正在运行Cedar堆栈,请从终端控制台运行以下命令:herokurunrakejobs:
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。多年来,我一直在使用多种语言进行编程,并且认为自己总体上相当擅长。但是,我从未编写过任何自动化测试:没有单元测试,没有TDD,没有BDD,什么都没有。我已经尝试开始为我的项目编写适当的测试套件。我可以看到在进行任何更改后能够自动测试项目中所有代码的理论值(value)。我可以看到像RSpec和Mocha这样的测试框架应该如何使设置和运行所述测试变得相当容易
有没有办法使用vim结束Rubyblock?例如moduleSomeModule#defsome_methodendend我想用一个命令从光标所在的位置移动到block的末尾,这可能吗?我读过thisdocumentation,但它似乎不适用于.rb文件,我在某些地方读到它只适用于C(虽然还没有尝试过)。提前致谢。 最佳答案 rubyforge好像有官方包对此有一些支持:TheRubyftpluginnowincludesRubyspecificimplementationsforthe[[,]],[],][,[m,]m,[M,an
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭7年前。Improvethisquestion我需要认真阅读Ruby1.9.1和即将推出的Rails3/Merb的变化。人们可以推荐任何文章阅读吗?并不是真的在寻找一个答案,只是在寻找人们正在使用的资源汇编,以跟上即将发生的事情和当前存在的事情,所以如果你路过,请告诉我你在看什么。谢谢!
应用将在Heroku上运行依赖包括回形针哈姆指南针设计aws-s3支持或反对的理由?对其他版本的ruby有什么建议吗?更新Heroku目前不支持1.9.2,但预计很快会基于thispost.Rails3.0正式支持1.9.2(但不支持1.9.1),所以我决定继续使用它。更新Heroku在其beta堆栈上支持1.9.2。 最佳答案 我会说是的。当您准备好推出您的应用程序时(2-3个月?),应该解决越来越多的兼容性问题。此外,如果您遇到任何问题,您可以提交补丁并为更快的1.9.2兼容性做出贡献!;)但是为了回答您的问题,考虑到您要使