众所周知Redis有以下几种常见的数据类型 String(字符串)、List(列表)、Set(集合)、Hash(哈希)、Sorted set(有序集合)、Stream(流)、Geo(地理空间索引)、Bitmap(位图)、HyperLogLog(基数统计)等。
我们最常用的就是String(字符串)类型,String类型既可以存储字符串,也可以存储数字,甚至可以直接进行数值运算。
redis> set key1 value1
OK
redis> get key1
"value1"
redis> set key 1
Ok
redis> INCR key
(integer) 2
Redis是使用标准C语言编写的,而Redis String类型底层使用SDS(Simple Dynamic String 简单动态字符串),但是却没有使用C语言字符串使用,这到底是为什么呢?
Redis的优点是快、安全、节省内存,在设计Redis String实现的时候,也深刻的体现了Redis的这三个优点。
提到Redis字符串的优点,需要先看一下C语言字符串的缺点,毕竟没有对比就没有伤害。
C语言字符串是使用char数组存储,以'\0'作为字符串结束,比如字符串”Redis“在C语言中存储结构就是下面这样:
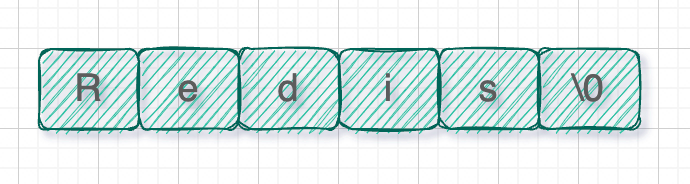
那么这种存储方式有什么缺点呢?
C语言字符串这种特殊规定,就导致无法存储特殊字符。如果某个字符串中间包含'\0'字符,读取字符串的时候就无法读取到完整字符,遇到'\0'就结束了,像下面这样,只能读取到前半部分“Red”。

如果存储到C语言的字符串,无法完整读取,肯定是不安全的,所以C语言无法存储包含特殊字符的字符串(例如二进制数据)。
如果想要获取字符串的长度,需要遍历整个字符串,时间复杂度是O(n),查询效率较低。
开发中最常用的功能是拼接字符串,每次拼接字符串的时候,都要提前进行扩容。如果忘记扩容了,就会出现缓存区溢出。
扩容过程是非常耗时的,而且每次拼接字符串的时候都需要提交扩容。想象一下,如果使用HashMap的时候,每次put操作都需要进行扩容,性能将会差到什么程度。
由于C语言字符串有这么多缺点,而Redis又追求极致性能,所以只能自己实现一套,看一下Redis字符串底层是怎么实现的?
Redis3.0版本之前的底层结构是这样的:
struct sdshdr {
// 记录buf数组中已使用字节的数量
// 等于SDS所保存字符串的长度
int len;
// 记录buf数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
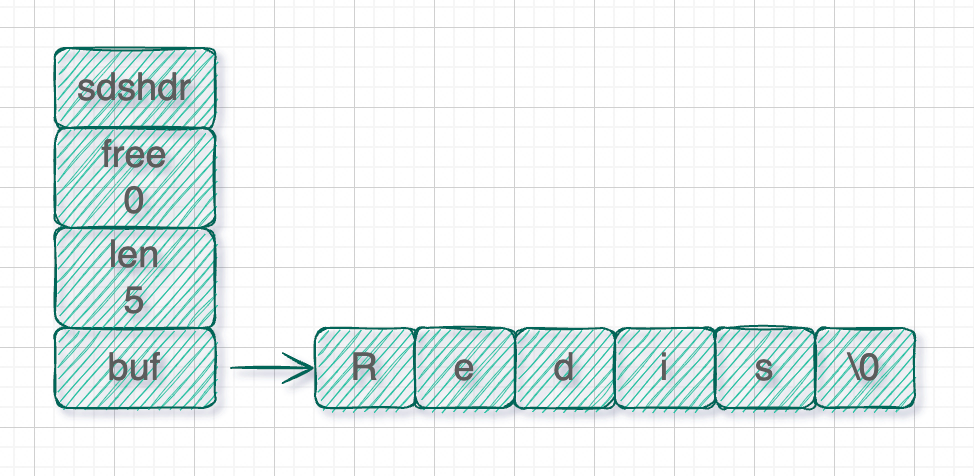
而最新Redis7.0版本,sds底层结构是这样的,分成5个实现:

为什么会有5种实现呢?
看一下每种实现的len和alloc的类型就明白了,sdshdr8里面的类型是uint8_t,sdshdr16里面的类型是uint16_t,sdshdr32里面的类型是uint32_t,sdshdr64里面的类型是uint64_t,用来存储不同长度的字符串。使用合适的类型,可以节约大量内存。
Redis自己实现的字符串解决了C语言字符串遇到的问题,并且有以下几个优点:
sds简化版的存储结构是这样的:
struct sdshdr {
// 已经使用的字节数量
int len;
// char数组总字节数量
int alloc;
// 字节数组,用于保存字符串
char buf[];
};
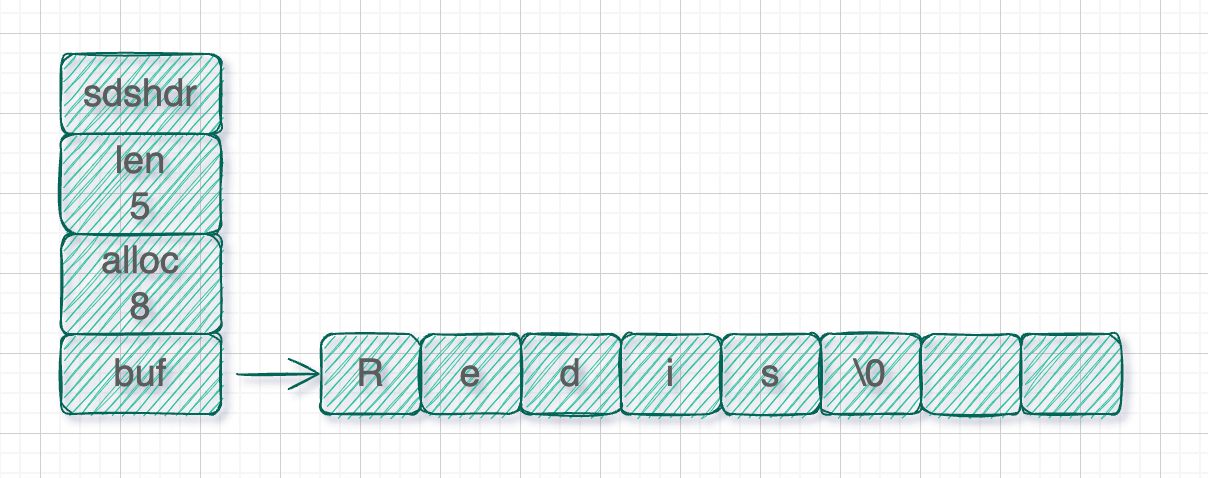
可以看出,Redis的字符串并不是用'\0'表示结尾,而是使用len记录了字符串的长度。想要取出完整的字符串,只需要遍历len长度即可。
Redis的字符串使用len记录了字符串的长度,想要获取整个字符串的长度,无需遍历字符串,只需要查询len值即可,时间复杂度是O(1)。
Redis采用空间换时间的做法,增加了存储空间,加快了查询性能。
Redis的字符串使用len记录了字符串的长度,使用alloc记录整个数组的长度,(alloc - len)表示未使用的空间长度。
如果新增的拼接字符串长度小于未使用空间,就不用扩容了。
Redis字符串还实现空间预分配和惰性空间释放的优化策略,减少扩容次数。
简单理解就是拼接字符串导致扩容的时候会多增加一些空闲空间,缩短字符串的时候并不立即释放这些空闲空间。
我是「一灯架构」,如果本文对你有帮助,欢迎各位小伙伴点赞、评论和关注,感谢各位老铁,我们下期见

我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)