
有没有人和我一样,遇到同样的困惑:当我使用 Prometheus 来搭建监控体系的时候,每当有一个组件需要监控,我就要为其增加一个 exporter,如果有 10 个组件,我就要增加 10 个 exporter,先不说这 10 个 exporter 的质量如何(因为大部分 exporter 都是广大网友自己开发的),光学习成本、部署成本以及维护成本都让人头疼。
有没有一个组件,就能搞定大部分指标采集的?
Categraf 就是这样的一个采集器。
惊不惊喜,意不意外?
Categraf 是一个监控采集 Agent,类似 Telegraf、Grafana-Agent、Datadog-Agent,希望对所有常见监控对象提供监控数据采集能力,采用 All-in-one 的设计,不但支持指标采集,也希望支持日志和调用链路的数据采集。
相比于其他采集器,Categraf 的优势在于:
安装很简单,下面简单介绍二进制安装的方式。
# 下载
$ wget https://download.flashcat.cloud/categraf-v0.2.38-linux-amd64.tar.gz
# 解压
$ tar xf categraf-v0.2.38-linux-amd64.tar.gz
# 进入目录
$ cd categraf-v0.2.38-linux-amd64/修改配置文件,在 conf/config.toml 中,修改的部分如下:
[[writers]]
url = "http://127.0.0.1:17000/prometheus/v1/write"
[heartbeat]
enable = true
然后启动 Categraf。
$ nohup ./categraf &>categraf.log &配置详解我们上面部署 Categraf 的时候没有指定配置文件,它就会默认读取 conf 目录下的配置文件,conf 目录的结构如下:
[global]
# 是否打印配置内容
print_configs = false
# 机器名,作为本机的唯一标识,会为时序数据自动附加一个 agent_hostname=$hostname 的标签
# hostname 配置如果为空,自动取本机的机器名
# hostname 配置如果不为空,就使用用户配置的内容作为hostname
# 用户配置的hostname字符串中,可以包含变量,目前支持两个变量,
# $hostname 和 $ip,如果字符串中出现这两个变量,就会自动替换
# $hostname 自动替换为本机机器名,$ip 自动替换为本机IP
# 建议大家使用 --test 做一下测试,看看输出的内容是否符合预期
# 这里配置的内容,再--test模式下,会显示为 agent_hostname=xxx 的标签
hostname = ""
# 是否忽略主机名的标签,如果设置为true,时序数据中就不会自动附加agent_hostname=$hostname 的标签
omit_hostname = false
# 时序数据的时间戳使用ms还是s,默认是ms,是因为remote write协议使用ms作为时间戳的单位
precision = "ms"
# 全局采集频率,15秒采集一次
interval = 15
# 配置文件来源,目前支持local和http两种配置,如果配置为local就读取本地的配置,如果配置为http,需要在[http]模块配置http来源
providers = ["local"]
# 全局附加标签,一行一个,这些写的标签会自动附到时序数据上
# [global.labels]
# region = "shanghai"
# env = "localhost"
# 日志模块
[log]
# 默认的log输出,到标准输出(stdout)
# 如果指定为文件, 则写入到指定的文件中
file_name = "stdout"
# 当日志输出到文件时该配置生效,用于限制日志文件大小
max_size = 100
# 日志保留天数
max_age = 1
# 备份日志个数
max_backups = 1
# 是否使用本地时间格式化日志
local_time = true
# 是否用gzip对日志进行压缩
compress = false
# 发给后端的时序数据,会先被扔到 categraf 内存队列里,每个采集插件一个队列
# chan_size 定义了队列最大长度
# batch 是每次从队列中取多少条,发送给后端backend
[writer_opt]
batch = 1000
chan_size = 1000000
# 后端backend配置,在toml中 [[]] 表示数组,所以可以配置多个writer
# 每个writer可以有不同的url,不同的basic auth信息
[[writers]]
url = "http://127.0.0.1:17000/prometheus/v1/write"
# 认证用户,默认为空
basic_auth_user = ""
# 认证密码,默认为空
basic_auth_pass = ""
## 请求头信息
# headers = ["X-From", "categraf", "X-Xyz", "abc"]
# 超时配置:单位是 ms
timeout = 5000
dial_timeout = 2500
max_idle_conns_per_host = 100
# 如果providers配置为http,就需要在这个地方进行配置
[http]
# 是否开启
enable = false
# 地址信息
address = ":9100"
print_access = false
run_mode = "release"
# ibex配置,用于配置ibex-server的地址,用于实现故障自愈
[ibex]
enable = false
## ibex刷新频率
interval = "1000ms"
## ibex server 地址
servers = ["127.0.0.1:20090"]
## 脚本临时保存目录
meta_dir = "./meta"
# 心跳上报给n9e
[heartbeat]
enable = true
# 上报 os version cpu.util mem.util 等元信息
url = "http://127.0.0.1:17000/v1/n9e/heartbeat"
# 上报频率,单位是 s
interval = 10
# 认证用户
basic_auth_user = ""
# 认证密码
basic_auth_pass = ""
## header 头信息
# headers = ["X-From", "categraf", "X-Xyz", "abc"]
# 超时配置,单位 ms
timeout = 5000
dial_timeout = 2500
max_idle_conns_per_host = 100[logs]
# api_key http模式下生效,用于鉴权, 其他模式下占位符
api_key = "ef4ahfbwzwwtlwfpbertgq1i6mq0ab1q"
# 是否开启log-agent
enable = false
# 日志接收地址,可以配置tcp、http以及kafka
send_to = "127.0.0.1:17878"
# 日志发送协议:http/tcp/kafka
send_type = "http"
# kafka模式下的topic
topic = "flashcatcloud"
# 是否进行压缩
use_compress = false
# 是否使用tls
send_with_tls = false
# 批量发送的等待时间
batch_wait = 5
# 日志偏移量记录,用于断点续传
run_path = "/opt/categraf/run"
# 最大打开文件数
open_files_limit = 100
# 扫描目录日志评论
scan_period = 10
# udp采集的buffer大小
frame_size = 9000
# 是否采集pod的stdout/stderr日志
collect_container_all = true
# 全局处理规则, 该处不支持多行合并。多行日志合并需要在logs.items中配置
# [[logs.Processing_rules]]
# 日志采集配置
[[logs.items]]
# 日志类型,支持file/journald/tcp/udp
type = "file"
# 日志路径,支持统配符,用统配符,默认从最新位置开始采集
## 如果类型是file,则必须配置具体的路径; 如果类似是journald/tcp/udp,则配置端口
path = "/opt/tomcat/logs/*.txt"
# 日志的label 标识日志来源的模块
source = "tomcat"
# 日志的label 标识日志来源的服务
service = "my_service"其中,日志采集规则可以在全部logs.Processing_rules中配置,也可以在logs.items.logs_processing_rules中进行配置。
规则类型主要分为以下几种:
(1)不发送匹配到的日志行
type = "exclude_at_match"
name = "exclude_xxx_users"
pattern="\\w+@flashcat.cloud"
表示日志中匹配到@flashcat.cloud 的行 不发送(2)只发送匹配到的日志行
type = "include_at_match"
name = "include_demo"
pattern="^2022*"
表示日志中匹配到2022开头的行 才发送(3)对日志内容进行替换处理
type = "mask_sequences"
name = "mask_phone_number"
replace_placeholder = "[186xxx]"
pattern="186\\d{8}"
表示186的手机号会被[186xxx] 代替(4)多行合并
type = "multi_line"
name = "new_line_with_date"
pattern="\\d{4}-\\d{2}-\\d{2}" (多行规则不需要添加^ ,代码会自动添加)
表示以日期为日志的开头,多行的日志合并为一行进行采集Categraf 本身以及可以完成很多指标的采集,如果你本身已经有了完整的 Promtheus 体系,但是想用 N9e,Categraf 也支持采集 Prometheus 指标。
[prometheus]
# 是否启动prometheus agent
enable=false
# 原来prometheus的配置文件
# 或者新建一个prometheus格式的配置文件
scrape_config_file="/path/to/in_cluster_scrape.yaml"
## 日志级别,支持 debug | warn | info | error
log_level="info"
# 以下配置文件,保持默认就好了
## wal file storage path ,default ./data-agent
# wal_storage_path="/path/to/storage"
## wal reserve time duration, default value is 2 hour
# wal_min_duration=2比如这里配置 Prometheus 自动采集 kube-state-metrics 指标的 scrape 配置:
global:
scrape_interval: 15s
external_labels:
scraper: ksm-test
cluster: test
scrape_configs:
- job_name: "kube-state-metrics"
metrics_path: "/metrics"
kubernetes_sd_configs:
- role: endpoints
api_server: "https://172.31.0.1:443"
tls_config:
ca_file: /etc/kubernetes/pki/ca.crt
cert_file: /etc/kubernetes/pki/apiserver-kubelet-client.crt
key_file: /etc/kubernetes/pki/apiserver-kubelet-client.key
insecure_skip_verify: true
scheme: http
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: kube-system;kube-state-metrics;http-metrics
remote_write:
- url: "http://172.31.62.213/prometheus/v1/write"然后在prometheus.toml配置中使用scrape_config_file加载上面的文件即可。
这里不做多的解释。
假如我们服务器上有一个 nginx 进程,我们要对其进程监控,我们要修改conf/input.procstat/procstat.toml配置,如下:
# # collect interval
interval = 15
[[instances]]
# # executable name (ie, pgrep <search_exec_substring>)
search_exec_substring = "nginx"
# # pattern as argument for pgrep (ie, pgrep -f <search_cmdline_substring>)
# search_cmdline_substring = "n9e server"
# # windows service name
# search_win_service = ""
metrics_name_prefix="nginx"
# # search process with specific user, option with exec_substring or cmdline_substring
# search_user = ""
# # append some labels for series
labels = { region="cloud", product="n9e" }
# # interval = global.interval * interval_times
# interval_times = 1
# # mode to use when calculating CPU usage. can be one of 'solaris' or 'irix'
# mode = "irix"
# sum of threads/fd/io/cpu/mem, min of uptime/limit
gather_total = true
# will append pid as tag
gather_per_pid = false
# gather jvm metrics only when jstat is ready
# gather_more_metrics = [
# "threads",
# "fd",
# "io",
# "uptime",
# "cpu",
# "mem",
# "limit",
# "jvm"
# ]我们指定了进程名,并且为指标增加了nginx的前缀和label。
配置完成后,重启 Categraf 即可。
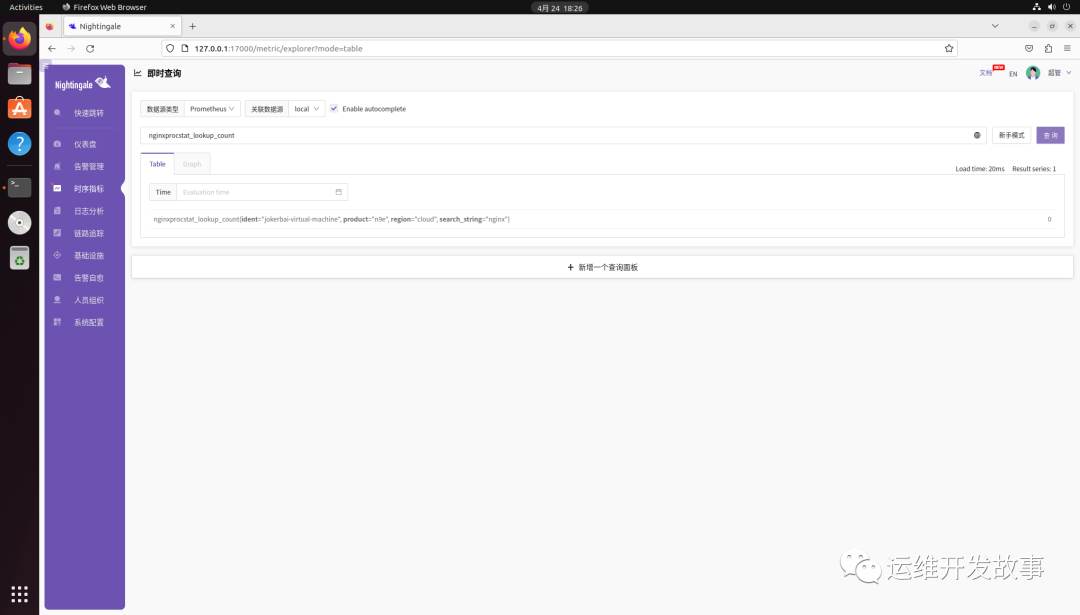
然后就可以看到指标数据,如下:
如果想给采集的目标增加标签,直接修改 labels 标签,比如增加group="ops",如下:
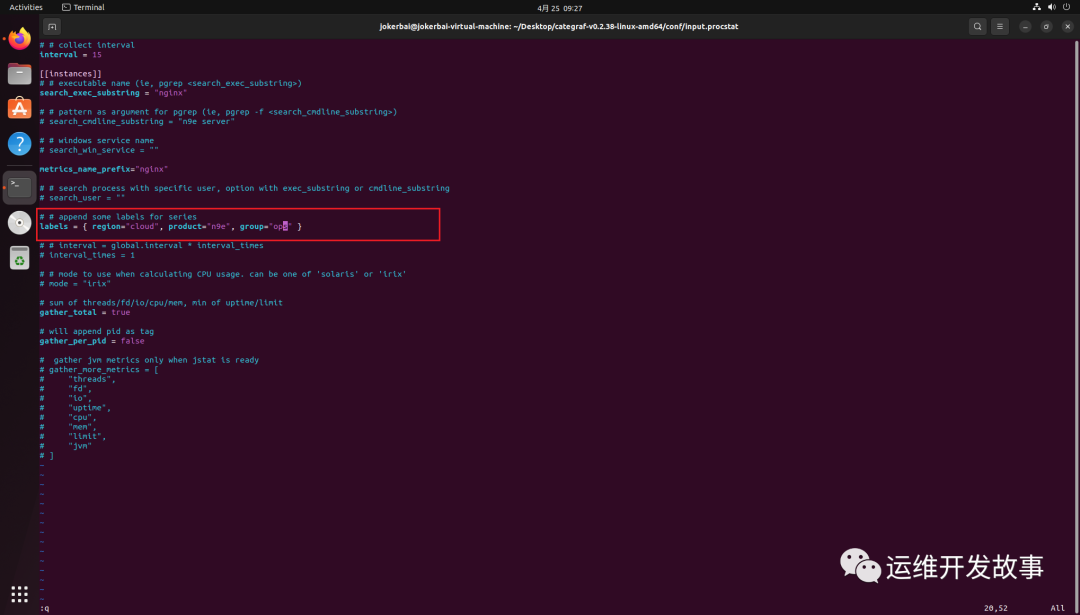
然后重启 Categraf 即可。
其他插件的配置类似,可以自行实验。
到目前位置,Categraf 支持的插件非常多,粗略数了一下,大概有 60 种,涵盖大部分的中间件、云平台,可以说功能非常丰富。
从能力上将,大部分场景都可以只使用 Categraf 替代,但是对于插件需求很多的情况,对于 Categraf 的整体性能是否会有影响以及 Categraf 会不会很耗系统资源还未可知。
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
是否可以在我的服务器上运行任何工具来监控多个Rails应用程序?我需要监控每个应用程序收到的请求数、每个应用程序使用了多少内存、使用了多少CPU以及其他类似的统计信息。我需要查看每个单独的Rails应用程序的统计信息。 最佳答案 我建议你试试NewRelicRPM.免费版:RPMLiteisthemostwidelyusedsolutionforbasicwebapplicationmonitoring.RPMLiteprovidesapplicationmonitoringforunlimitedJava,RubyorJRubya
我正在寻找一种方法来监视流上的事件,以便我可以确定是否有任何内容通过流。如果有,我将开始使用rtmpdump进行录制。我想象这是通过运行一个每60秒检查一次流的cron任务来实现的。如果它确定流正在通过,则调用rtmpdump开始记录它。如果没有,则什么都不做,并在60秒后再次检查。由于rtmpdump只是在没有流数据时出现错误,因此尝试使用它来监视流似乎不是一个好主意,但也许我错了。如果我在逐个案例的基础上手动执行此操作会很容易,但我正在尝试自动执行自动录制流的任务(如果它们可用)。有没有人遇到过这样做的方法?也许我可以在命令行(linux)中使用其他一些工具?如果有帮助,我正在使用
每5分钟(例如)ping20个网站的列表以了解该网站是否响应HTTP202的最佳方法是什么?最简单的想法是将20个URLS保存在数据库中,然后运行数据库并对每个URL执行ping操作。但是,当一个人不回答时会发生什么?之后的人会怎样?此外,是否有更好但更简单的解决方案?恐怕该列表会增长到20000个网站,然后没有足够的时间在我需要ping的5分钟内全部ping通它们。基本上,我是在描述PingDom、UptimeRobot等的工作原理。我正在使用node.js和RubyonRails构建这个系统。我也倾向于使用MongoDB来保存所有ping和监控结果的历史记录。建议?非常感谢!
我们有一个带有广泛管理部分的应用程序。我们对功能有点满意(就像您一样),并且正在寻找一些快速简便的方法来监控“谁使用什么”。理想情况下,一个简单的gem将允许我们在每个用户的基础上跟踪Controller/操作,以构建使用的功能和未使用的功能的图片。任何你会推荐的..谢谢主场 最佳答案 我不知道有什么流行的gem或插件可以解决这个问题;过去,我在ApplicationController中将这种审计实现为before_filter:从内存中:classApplicationControllercurrent_user,:contro
我有一堆长时间运行的Ruby脚本,我想确保每30秒左右运行一次。我通常通过简单地启动命令rubyscript-name.rb我如何配置monit来管理这些脚本?更新:我试着关注thismethodtocreateawrapperscript然后它会启动ruby进程,但它似乎没有创建.pid文件并且键入“./wrapper-scriptstop”什么也没做:/我应该在ruby中编写pid还是使用包装脚本来创建monit所需的pid? 最佳答案 MonitWiki有很多配置示例:http://mmonit.com/wiki/Mo
我们想设置自动化作业(通过Jenkins)以在第三方API出现故障或他们部署了不兼容的API时发出警报。我说的是针对真实的HTTPAPI进行测试,而不是模拟,但是因为我们已经使用rspec编写了模拟,所以我不确定我们是否应该通过编写两个独立的睾丸来重复这项工作。有人有这方面的经验吗?(如果其他工具可以提供帮助,我不限于Ruby/Rspec) 最佳答案 你看过VCR了吗??使用它,您可以“记录您的测试套件的HTTP交互并在未来的测试运行期间重播它们以进行快速、确定性、准确的测试”。在测试来自外部API的预期响应时,我将它与RSpec一
我正在使用Sidekiqworker在用户首次登录后完成对Facebook的一些请求。通常该任务大约需要20秒左右。我想在同步完成后立即使用ajax请求将一些信息加载到页面上,但不确定使用Javascript检查作业完成情况的最佳方式。一种可能性是配置Sidekiqworker在完成其余工作后设置cookie。然后我可以使用setTimeout函数在调用加载函数之前继续检查cookie。但我不确定这是否是最好的方法。我可以改用Redis吗? 最佳答案 Paul,最初你必须看一下这个PubSubonRailstutorial!当异步事
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭7年前。Improvethisquestion使用哪个进行过程监控?为什么?
网络上是否有关于如何使用Monit监控delayed_job的示例??我能找到的所有东西都使用God,但我拒绝使用上帝,因为在Ruby中长时间运行的进程通常很糟糕。(上帝邮件列表中的最新帖子?GodMemoryUsageGrowsSteadily。)更新:delayed_job现在带有samplemonitconfig基于这个问题。 最佳答案 下面是我如何让它工作的。使用collectiveideaforkofdelayed_job除了积极维护之外,这个版本还有一个不错的script/delayed_job可以与monit一起使用的