ES索引备份还原
es数据出于线上数据安全考虑,对于es已有的索引数据可以进行安全备份,通常可以将es备份到共享文件目录或者一些其它的数据存储的文件系统eg:HDFS、Amazon S3、Azure Cloud。备份会生成索引的快照存储到指定的仓库路径下,当需要进行数据还原的时候,就可以通过访问备份还原的接口快速实现数据还原。
ES备份存储的仓库可以为:Shared filesystem(NAS等)、 Amazon S3, HDFS和Azure Cloudde等常用文件系统,本文档只提供备份到Shared filesystem和HDFS
步骤:
1)、搭建集群共享目录 (这里使用NFS也可以使用其它共享目录技术)
安装NFS服务端:
a、选择集群中某一个节点,可以选择ES的Master节点,检查是否安装NFS
rpm -qa | grep nfs
rpm -qa | grep rpcbind
b、如果没有安装,则安装NFS
yum install nfs-utils rpcbind
离线环境需要自己去下载相关包安装
c、设置开机启动
systemctl enable rpcbind.service
systemctl enable nfs-server.service
d、启动NFS
systemctl start rpcbind.service
systemctl start nfs-server.service
e、创建共享目录
mkdir /mont/backups/my_backup 具体目录名可以自己设置
chown -R 用户名 /mont/backups/my_backup
这里的用户名必须是启动ES的用户
f、设置可以访问的地址和权限
vi /etc/exports 添加下面内容:
/mont/backups/my_backup *(rw,sync,no_root_squash,no_subtree_check)
代表所有网段都可以访问,如果想配置为特定ip,可以添加为es集群中所有节点的ip
g、刷新配置并查看
exportfs -a 刷新配置并立刻生效
showmount -e ip 这里ip为当前创建共享目录主机ip
配置NFS客户端(所有除开上一步中的外的所有ES节点都需执行如下操作)
a、检查是否安装NFS
rpm -qa | grep nfs
rpm -qa | grep rpcbind
b、如果没有安装,则安装NFS
yum install nfs-utils rpcbind
离线环境需要自己去下载相关包安装
c、设置开机启动
systemctl enable rpcbind.service
systemctl enable nfs-server.service
d、启动NFS
systemctl start rpcbind.service
systemctl start nfs-server.service
e、创建共享目录
mkdir /mont/backups/my_backup 保持和NFS服务端目录一致
chmod -R 用户名 /mont/backups/my_backup
这里的用户名必须是启动ES的用户
f、挂载目录
showmount -e ip ip为NFS服务端ip
mount -t nfs ip:/mont/backups/my_backup /mont/backups/my_backup ip同上
h、设置开机挂载
vi /etc/fstab
ip:/mont/backups/my_backup /mont/backups/my_backup nfs defaults 0 0
ip为NFS服务端ip
2)、修改es配置
修改elasticsearch.yml,配置path.repo的属性为上述共享目录,然后重启集群
3)、注册快照仓库

通过post操作可以对备份仓库信息作出变更
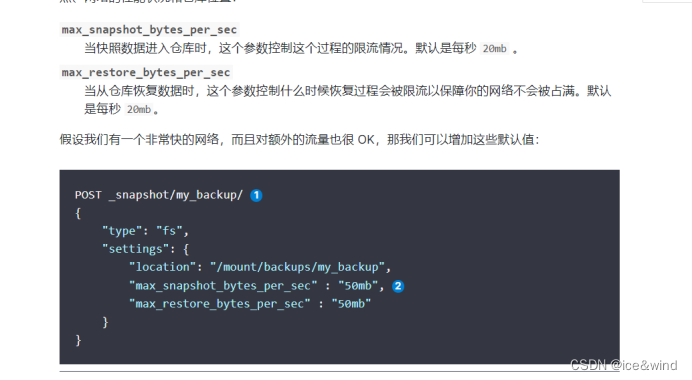
4)、创建快照
创建所有索引快照:

my_backup:仓库名
snapshot_1:快照名
创建部分索引快照:
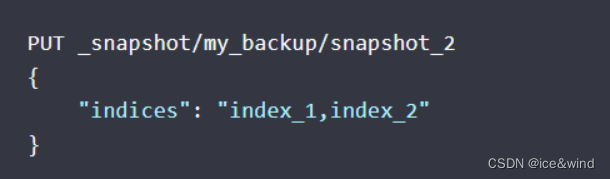
my_backup:仓库名
snapsot_2:快照名
通过indices属性可以指定哪些索引需要生成快照信息
5)、快照删除

my_backup:仓库名
snapshot_2:快照名,查看存在的快照可用:

my_backup:仓库名,其余为固定参数
HDFS快照/还原插件是针对最新的Apache Hadoop 2.x(当前为2.7.1)构建的。如果您使用的发行版与Apache Hadoop协议不兼容,请考虑使用自己的发行版替换plugin文件夹内的Hadoop库(可能必须调整所需的安全权限)
步骤:
1)、安装repository-hdfs插件
2)、注册仓库
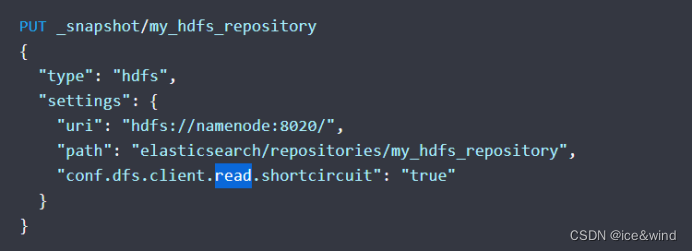
my_hdfs_repository:仓库名
uri:hdfs访问路径
path:hdfs上存储目录
如果hadoop设置了kerberos安全认证则:
把kerberos认证文件放到es config目录下repository-hdfs目录之中并命名为:krb5.keytab
然后创建hdfs快照仓库:
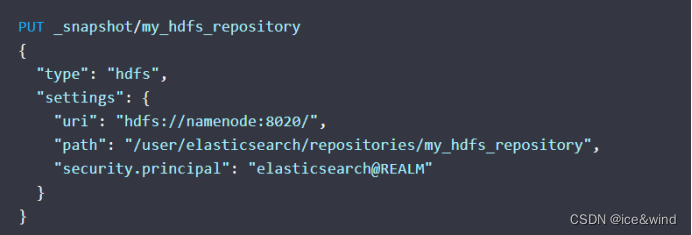
如果每个节点使用的是不同的服务主体则需要使用_HOST参数:
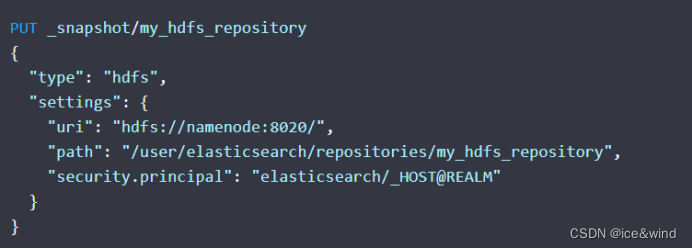
其余步骤参考方案一
还原快照所有:

my_backup:索引仓库名
snapshot_1:快照名
还原快照特定索引:
POST /_snapshot/my_backup/snapshot_1/_restore{
"indices": "index_1",
}
index_1:需要还原的索引名
my_backup:仓库名
snapshot_1:快照名
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我发现自己需要这个。假设cart是一个包含用户列表的模型。defindex_of_itemcart.users.each_with_indexdo|u,i|ifu==current_userreturniendend获取此类关联索引的更简单方法是什么? 最佳答案 indexArray上的方法与您的index_of_item方法相同,例如cart.users.index(current_user)返回数组中第一个对象的索引==给obj。如果未找到匹配项,则返回nil。 关于ruby-on-
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
假设我有一个可枚举对象enum,现在我想获取第三个项目。我知道一种通用方法是转换成数组,然后使用索引访问,如:enum.to_a[2]但这种方式会创建一个临时数组,效率可能很低。现在我使用:enum.each_with_index{|v,i|breakvifi==2}但这非常丑陋和多余。执行此操作最有效的方法是什么? 最佳答案 你可以使用take剥离前三个元素,然后剥离last从take给你的数组中获取第三个元素:third=enum.take(3).last如果您根本不想生成任何数组,那么也许:#Ifenumisn'tanEnum
在我的场景中,Logstash收到的系统日志行的“时间戳”是UTC,我们在Elasticsearch输出中使用事件“时间戳”:output{elasticsearch{embedded=>falsehost=>localhostport=>9200protocol=>httpcluster=>'elasticsearch'index=>"syslog-%{+YYYY.MM.dd}"}}我的问题是,在UTC午夜,Logstash在外时区(GMT-4=>America/Montreal)结束前将日志发送到不同的索引,并且索引在20小时(晚上8点)之后没有日志,因为“时间戳”是UTC。我们已
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
我一直在努力学习如何处理由数组组成的数组。假设我有这个数组:my_array=[['ORANGE',1],['APPLE',2],['PEACH',3]我将如何找到包含'apple'的my_array索引并删除该索引(删除子数组['APPLE',2]因为'apple'包含在该索引的数组中)?谢谢-我非常感谢这里的帮助。 最佳答案 您可以使用Array.select过滤掉项目:>>a=[['ORANGE',1],['APPLE',2],['PEACH',3]]=>[["ORANGE",1],["APPLE",2],["PEACH",3
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但