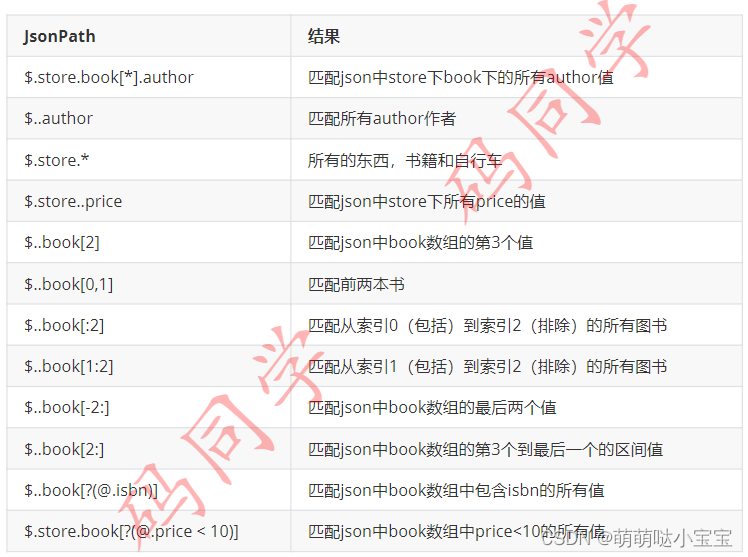
jsonpath是使用一种简单的方法提取给定的json文档的部分内容,我们做接口测试时,目前主要流行的数据结构是json,遇到复杂的json格式,使用jsonpath提取数据
| 操作 | 说明 |
|---|---|
| $ | 查询根元素, |
| @ | 当前接口由过滤词处理 |
| * | 通配符, |
| . . | 深度扫描 |
| . | 表示子节点 |
| [“(,”)] | 括号表示子项 |
| [(,)] | 数组索引或者索引 |
| [start:end] | 数组切片 |
| [?()] | 过滤表达式,表达式要求值为一个布尔值 |
2、过滤器运算符
过滤器是筛选数组的逻辑表达式,一个典型的过滤器是[?@.age>18)],其中@正在处理的当前节点,可以使用逻辑运算符&&和||创建更复杂的过滤器,字符串文字必须用单引号或者双引号括起来,(?@.color==‘blue’)]或者[?@.color==‘blue’)])
在线调试jsonpath:http://www.e123456.com/aaaphp/online/jsonpath/?
jsonpath示例:
提取token:
token = jsonpath.jsonpath(res.json(),'$.data')[0]
#1、第一个参数表示要解析的对象
#2、第二个参数你要提取的数据对应的jsonpath表达式
#3、如果表达式能够取到值,不管是1个还是多个,返回的都是列表,所以我们在后面加了[0]
#4、如果表达式匹配不到数据,那么它返回的值是False
按照一定的维度进行分类,每个分类可以当作一个sheet工作表
| 变量名称 | 变量值 |
|---|---|
| host | http://82.156.74.26:9099 |
| username | 18866668888 |
| password | 123456 |
data类型:
{
"data":{
"xxx":"xxxxxxx"
}
}
params类型
{
"params":{
"xxx":"xxxxxxx"
}
}
json类型:
{
"json":{
"xxx":"xxxxxxx"
}
}
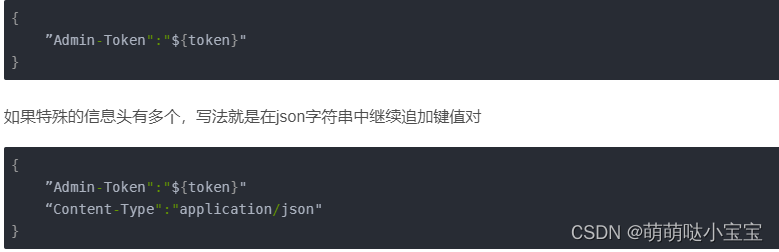
混合参数(既有data,也有params,有json
{
"data":{
"xxx":"xxxxxxx"
}
"json":{
"xxx":"xxxxxxx"
}
"params":{
"xxx":"xxxxxxx"
}
}
| 接口名称 | 默认参数 |
|---|---|
| 登录 | { “data”: { “username”: “ u s e r n a m e " , " p a s s w o r d " : " {username}", "password": " username","password":"{password}” }} |
| 新增客户 | { “json”: { “entity”: { “customer_name”: “沙陌001”, “mobile”: “18729399607”, “telephone”: “01028375678”, “website”: “http://mtongxue.com/”, “next_time”: “2022-05-12 00:00:00”, “remark”: “这是备注”, “address”: “北京市,北京城区,昌平区”, “detailAddress”: “霍营地铁口”, “location”: “”, “lng”: “”, “lat”: “” } }} |
| 新建联系人 | { “json”: { “entity”: { “name”: “沙陌001联系人”, “customer_id”: “${customerId}”, “mobile”: “18729399607”, “telephone”: “01028378782”, “email”: “sdsdd@qq.com”, “post”: “采购部员工”, “address”: “这是地址”, “next_time”: “2022-05-10 00:00:00”, “remark”: “这是备注” } }} |
| 测试集合名称 | 是否被执行 |
|---|---|
| 新增客户接口测试集合 | y |
| 新增联系人接口集合 | y |


依赖于设计去创建项目结构
在common这个package下新建excel_util.py文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Time : 2022/6/16 16:40
@Author : liudan
@File : excel_util.py
@Desc :
"""
import openpyxl
#读取全局变量sheet工作表
def get_variables(wb):
sheet_data = wb['全局变量']
variables = {} #用来存储读取到的变量,名称是key,值是value
line_count = sheet_data.max_row #获取总行数
for l in range(2,line_count+1):
key = sheet_data.cell(l,1).value
value = sheet_data.cell(l,2).value
variables[key] = value
return variables
#读取接口默认参数
def get_api_default_params(wb):
sheet_data = wb['接口默认参数']
api_default_params = {} # 用来存储读取到的变量,名称是key,值是value
line_count = sheet_data.max_row # 获取总行数
for l in range(2, line_count + 1):
key = sheet_data.cell(l, 1).value
value = sheet_data.cell(l, 2).value
api_default_params[key] = value
return api_default_params
#读取要执行的测试集合
def get_casesuitename(wb):
sheet_data = wb['测试集合管理']
case_suite_name = [] # 用来存储读要执行的测试集合名称
line_count = sheet_data.max_row # 获取总行数
for l in range(2, line_count + 1):
flag = sheet_data.cell(l, 2).value
if flag == 'y':
suite_name = sheet_data.cell(l, 1).value
case_suite_name.append(suite_name)
return case_suite_name
#需要根据要执行的测试用例集合名称来读取对应的测试用例数据
def read_testcases(wb,suite_name):
sheet_data = wb[suite_name]
line_count = sheet_data.max_row #总行数
cols_count = sheet_data.max_column #总列数
"""
规定读取出来的测试数据存储结构如下:
{
“新增客户正确”:[
['apiname','接口地址','请求方式',...],
['apiname','接口地址','请求方式',...],
]
’新增客户失败“:[
['apiname','接口地址','请求方式',...],
]
'新增客户失败-手机号格式不正确‘[
['apiname','接口地址','请求方式',...],
]
}
"""
cases_info = {} #用来存储当前测试集合中的所有用例的信息
for l in range(2,line_count+1):
case_name = sheet_data.cell(l,2).value #测试用例名称
lines = [] #用来存储当前行的测试数据
for c in range(3,cols_count+1):
cell = sheet_data.cell(l,c).value #单元格数据
if cell == None:
cell = ''
lines.append(cell)
#判断当前用例名称是否已存在与case_info中
#如果不存在,那就直接赋值
#如果存在,在原来的基础上赋值
if case_name not in cases_info:
cases_info[case_name] = [lines]
else:
cases_info[case_name].append(lines)
return cases_info
#整合所有要执行的测试用例数据,将其转换成pytest参数化需要的数据个够格式
def get_all_testcases(wb):
"""
整合后的数据结构是
[
['新增客户接口测试集合','新增客户正确',[[],[]]]
['新增客户接口测试集合','新增客户失败-用户名为空',[[],[]]]
]
:param wb:
:return:
"""
test_data = [] #用来存储所有测试数据
#获取所有要执行的测试用例集合名称
case_suite_name = get_casesuitename(wb)
for suite_name in case_suite_name:
#遍历读取每个要执行的测试集合sheet工作表中的测试用例数据
cur_cases_info = read_testcases(wb,suite_name) #是字典
for key,value in cur_cases_info.items():
#key是测试用例名称,value是测试用例多行数据信息
case_info = [suite_name,key,value]
test_data.append(case_info)
return test_data
if __name__ == '__main__':
wb = openpyxl.load_workbook(r'../testcases/CRM系统接口测试用例.xlsx')
print(get_variables(wb))
print(get_api_default_params(wb))
print(get_casesuitename(wb))
print(read_testcases(wb, '新建联系人接口测试集合'))
print('-------------------------------------')
print(get_all_testcases(wb))
在common这个package下新建requests_util.py文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Time : 2022/6/16 18:55
@Author : liudan
@File : requests_util.py
@Desc :
"""
import requests
import jsonpath
session = requests.session()
class RequestsClient:
def send(self,url,method,**kwargs):
try:
self.resp = session.request(url=url,method=method,**kwargs)
except BaseException as e:
raise BaseException(f'接口发起异常:{e}')
return self.resp
#针对jsonpath的数据提取
#第一个参数指的是匹配的数据jsonpath表达式
#第二个参数指的是想要返回匹配到的第几个,默认是0,表示第一个
def extract_resp(self,json_path,index=0):
#注意有的接口是没有返回信息的,返回信息为空
text = self.resp.text #获取返回信息的字符串形式
if text != '':
resp_json = self.resp.json() #获取响应信息的json格式
#如果能匹配到值,那么res就是个列表
#如果匹配不到res就返回False
res = jsonpath.jsonpath(resp_json,json_path)
if res:
#如果index<0,我认为你想要匹配所有的结果
if index < 0:
return res
else:
return res[index]
else:
print("没有匹配到任何数据")
else:
raise BaseException('接口返回信息为空,无法提取')
if __name__ == '__main__':
client = RequestsClient()
client.send(
url = 'http://82.156.74.26:9099/login',
method = 'post',
data = {
"username":"18866668888",
"password":123456
},)
print(client.extract_resp('$.Admin-Token'))
在我们测试的时候,有的参数并不能够写死,所以这个时候我们希望某些参数在每次执行的时都是动态变化的,那么就需要我们封装一些辅助随机函数来帮助我们完成数据的动态变化
在common下新建一个 util_func.py文件,在其中写上我们所需要的辅助该函数
随机数生成可以用第三方库:faker
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Time : 2022/6/17 10:59
@Author : liudan
@File : util_func.py
@Desc :
"""
import hashlib
import time
from faker import Faker
fake = Faker(locale='zh_CN')
def rdm_phone_number():
return fake.phone_number()
def cur_timestamp(): #到毫秒级的时间戳
return int(time.time()*1000)
def cur_date(): #2022-12-25
return fake.date_between_dates()
def cur_date_time(): #2022-12-25 10:4:2
return fake.date_time_between_dates()
def rdm_date(pattern="%Y-%m-%d"):
return fake.date(pattern=pattern)
def rdm_date_time():
return fake.date_time()
def rdm_future_date_time(end_date): #未来30天
return fake.future_datetime(end_date=end_date)
def md5(data):
data = str(data)
return hashlib.md5(data.encode('UTF-8')).hexdigest()
if __name__ == '__main__':
print(rdm_phone_number())
print(cur_date())
print(cur_date_time())
print(rdm_date())
print(rdm_date_time())
print(rdm_future_date_time('+60d'))
print(md5('admin'))
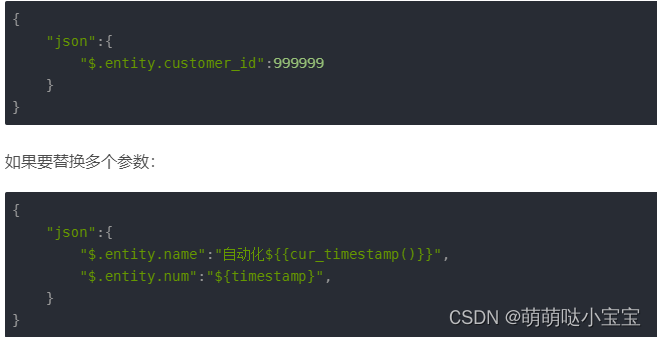
在excel中需要动态函数的时候,调用规则是 m d 5 ( a d m i n ) , {{md5(admin)}}, md5(admin),{{rdm_future_date_time(‘+60d’)}}
| 元字符 | 描述 |
|---|---|
| \ | 转义字符 |
| * | 匹配前面的子表达式任意次,0~n |
| + | 匹配前面的子表达式一次或多次(大于等于1次) |
| ? | 匹配前面的子表达式零次或一次 {0,1} |
| {n} | 匹配确定的n次 |
| {n,m} | 最少匹配n次且最多匹配m次 |
| .点 | 匹配除“\n”和"\r"之外的任何单个字符 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 [‘o’, ‘o’, ‘o’, ‘o’] |
| \d | 匹配一个数字字符。等价于[0-9] |
| [a-z] | 字符范围。匹配指定范围内的任意字符 |
我正在尝试将JsonPath用于.NET(http://code.google.com/p/jsonpath/downloads/list),但我无法找到有关如何解析Json字符串和JsonPath字符串并获得结果的示例。有人用过吗? 最佳答案 您遇到的问题是JsonPath的C#版本不包含Json解析器,因此您必须将它与另一个处理序列化和反序列化的Json框架一起使用。JsonPath的工作方式是使用一个名为IJsonPathValueSystem的接口(interface)来遍历已解析的Json对象。JsonPath自带一个内置
大家好,我想知道是否有人知道使用正则表达式或通配符运算符(或者SQL中的'%LIKE%')的方法,这样我就可以使用JSONPath在大量JSON数据中进行搜索。例如(是的,我正在解析,而不是eval()在应用程序中处理我的数据):varobj=eval('({"hey":"canyoufindme?"})');我希望能够像这样查看数据:$.[?(@.hey:contains(find))]//(injQueryterminology)参数的内容是{"key":"value"}中的部分或全部值在我的数据中配对。目前我只找到关于>的文档,,=,和!=关系运算符,它没有给我太多的灵activ
我有这个测试数据:[{id:1,l:'a',sub:[]},{id:2,l:'b',sub:[{id:4,l:'d'},{id:5,l:'e'},{id:6,l:'f',sub:[{id:7,l:'g'}]}]},{id:3,l:'c',sub:[]}];我正在尝试获取带有id:7的对象的路径。我尝试了很多JSONPath查询,但我似乎无法找到如何使JSONPath遍历所有sub键并在其中进行搜索。如何匹配id:7的对象?这是我的测试插件:http://plnkr.co/edit/RoSeRo0L1B2oH3wC5LdU?p=preview 最佳答案
我一直在研究JSONPath,虽然它看起来做得很好,但我想知道是否有人使用过它并且可以评论它的可用性,或者可以推荐替代方案?如果有一个JQuery插件可以做这样的事情,那将是真正的巧妙之处。我一直在搜索插件并空手而归。无论如何,在我花时间了解JSONPath(它有一些我不热衷的方面)之前,或者在我重新发明轮子之前,我想我会看看是否有人对此有看法......为了让你明白我的意思,想象一下这个Javascript对象:varCharacters=[{id:"CuriousGeorge",species:"Monkey",mood:"curious",appendage:[{type:"ha
我有一些JSON,以下是其中的一个小样本:{"results":{"div":[{"class":"sylEntry","div":[{"class":"sT","id":"sOT","p":"Mon11/17,Computerworktime"},{"class":"des","id":"dOne","p":"AllclassesSiebel0218"}],"id":"sylOne"}]}}我只想检索类"sT"的div元素的"p"内容。我想使用一个循环并做这样的事情:vararrayOfResults=$.results..div.p不起作用,因为我只想检索类"sT"的div元素的p
我编写了SpringControllerJunits。我使用JsonPath使用["$..id"]从JSON中获取所有ID。我有以下测试方法:mockMvc.perform(get(baseURL+"/{Id}/info",ID).session(session)).andExpect(status().isOk())//Success.andExpect(jsonPath("$..id").isArray())//Success.andExpect(jsonPath("$..id",Matchers.arrayContainingInAnyOrder(ar)))//Failed.an
我正在尝试使用Jsonpath按值过滤我的Json中的数组。我想在下面的JSON中获取国家/地区的long_name。为此,我按types[0]=="country"过滤了adress_components,但它似乎不起作用。我试过的JsonPath:$.results[0].address_components[?(@['types'][0]=="country")].long_name我想要的结果是:“加拿大”。JSON:{"results":[{"address_components":[{"long_name":"5510-5520","short_name":"5510-55
所以我正在处理以下json:{"id":"","owner":"somedude","metaData":{"request":{"ref":null,"contacts":[{"email":null,"name":null,"contactType":"R"},{"email":null,"name":"Dante","contactType":"S"}]}}}我想检索联系人的name类型为S并且只有返回的第一个。将jsonpath与此路径一起使用"$..contacts[?(@.contactType=='S')].name"始终返回字符串数组,因为过滤操作始终将结果返回为数组。
爬虫总结目录爬虫总结一、静态页面html代码的获取1.请求数据①requests(1)基本使用(2)Requests进阶:使用Session(3)防盗链处理(4)代理ip②urllib&urllib3③selenium(webdriver)2.节点获取/内容匹配①re1.语法2.实战②bs41.语法2.实战③xpath1.语法2.实战④PyQuery1.语法2.实战⑤jsonpath1.语法2.实战二、多线程和线程池1.多线程2.线程池3.线程实战三、协程1.协程程序基本语法2.协程常用的库3.协程实战四、保存数据1.保存到Excelxls(xlwt)2.保存到数据库db(sqlite3)3.
问题:我有一项服务将JSON字符串作为输入。JSON架构在某些字段并不总是存在的情况下每次都不同。当它们存在时,如何使用Jayway的JsonPath查询这些字段的值?我尝试过的:我使用Option.DEFAULT_PATH_LEAF_TO_NULL作为Jayway的readmepage解释Configurationconfig=Configuration.defaultConfiguration().addOptions(Option.DEFAULT_PATH_LEAF_TO_NULL);if(JsonPath.isPathDefinite(attribute.jsonPath)){