docker-compose其实广义上理解是和k8s一样属于容器的编排工具,区别在于docker-compose用于单机上面基于提前定义好的docker编排yaml文件,在单机上可以一次性启动多个容器(当然你也可以定义多个容器的编排文件,启动多个)而k8s是把多台机器作为统一资源进行docker容器调度,以下为一个docker-compose容器编排文件的样例,相信有一些docker基础的同学一看就明白了
version: '2'
services:
dataservice:
mysql:
image:
container_name:
.....
redis:
image:
container_name:
appservice:
springboot:
image:
container_name:
注意:image上面的不是容器名字,而是docker-compose中的service的概念,image下面的container_name才是容器名,docker-compose概念解释:
对于单机上面需要固定运行的容器编排,docker-compose非常方便
docker-compose安装很简单,docker- compose就是一个二进制文件,所以我们只需要下载并且放到系统的PATH环境变量目录下面即可
##下载docker-compose二进制文件,这里我们用rancher的开源资源站来下载(资源站只提供X86_64安装文件)
wget http://rancher-mirror.rancher.cn/docker-compose/v1.20.1/docker-compose-Linux-x86_64
##添加可执行权限
mv docker-compose-Linux-x86_64 docker-compose && chmod +x docker-compose
##移动至PATH目录
mv docker-compose /bin/docker-compose
docker安装这里不再介绍啦,在我的此篇博文有详细的docker离线以及在线安装步骤
开始搭建之前先来一张prometneus生态的官方架构图

说明:
prometheus不同于其他监控体系的地方在于它是主动去拉监控指标数据,而监控指标数据一般都是一些第三方基于prometheus提供的开发库开发的exporter进行采集并提供一个http端口把这些指标暴露出来,prometheus主动去配置的http端口基于配置的时间间隔去拉取监控指标数据(prometneus官方也提供了一些exporter,比如node-exporter),prometheus其实更像是一个时序数据库,以时间为主键,具体的指标名以及指标名下的标签为字段的一个巨大的数据库,这么说可能不太好理解,以下查询为例更方便理解:
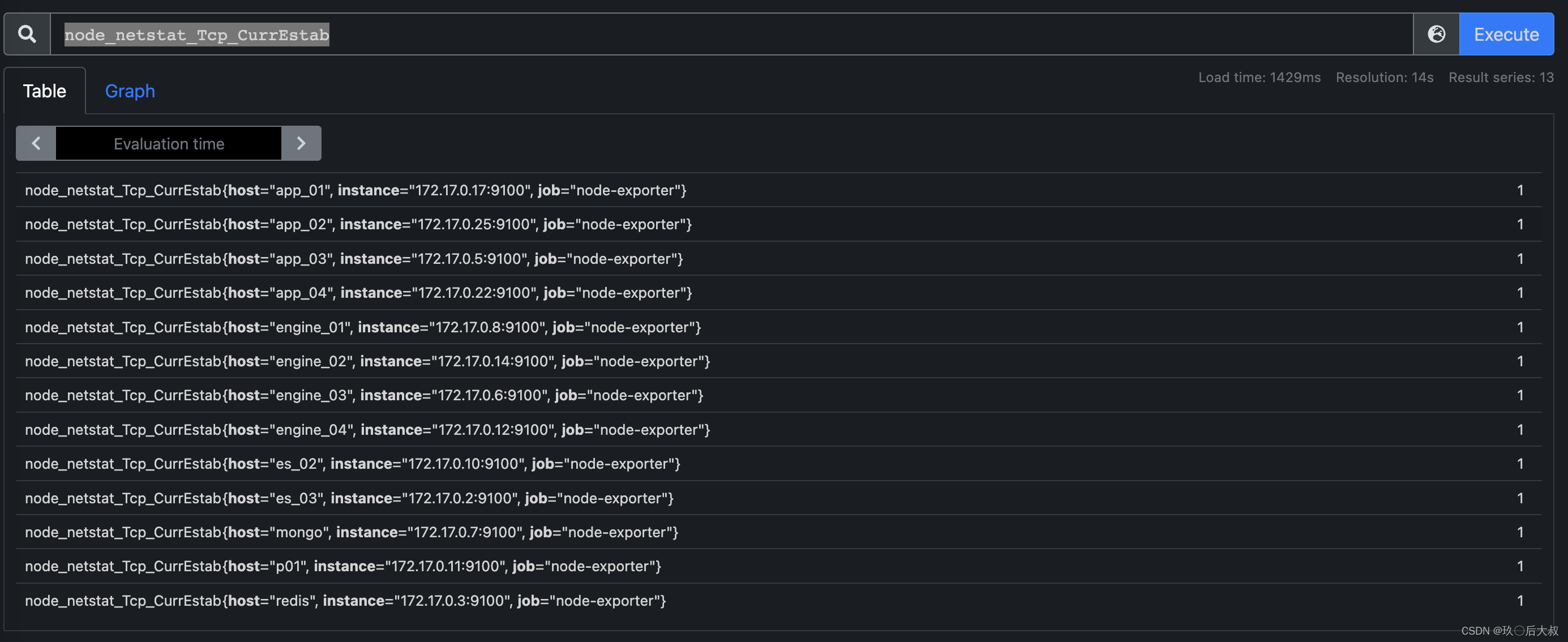
node_netstat_Tcp_CurrEstab为node-exporter采集的监控服务器连接数的一个监控指标,那么监控下面的标签是说明他是部署在哪台机器以及他是属于哪个exporter采集过来的指标,我们再来详细查询一下

这样指定标签我们就把该指标详细标签下的值查询出来了,再来看

我们可以查询该指标一段时间内的详细值,那么问题来了,2m中查询出来为什么是8条数据,那是因为prometheus配置的是15s采集一次
既然是一个数据库,那么就必须有他的查询语言,prometheus官方定义为PromQL,以上其实就是他的查询语言,当然还有更复杂的
那么为什么说到prometheus就一定要说grafana,grafana中强大的面板设置足够美观以及客观的到把你的监控数据呈现出来,我们只需要在面板下配置好prometheus的查询语句,grafana接入prometheus数据源(叫数据源也更好的体现了prometheus作为数据库的本质)就会调用prometheus的查询接口在面板上呈现数据。
node_exporter:
image: prom/node-exporter:latest
container_name: node_exporter
command:
- '--path.rootfs=/host'
pid: host
restart: unless-stopped
environment:
- TZ=Asia/Shanghai
ports:
- 9100:9100
volumes:
- '/:/host:ro,rslave'
此docker-compose默认为一个service就可以省去services了
docker-cmpose -f node-exporter up -d 启动容器,这样我们就在9100端口暴露的监控指标数据,比如我们浏览器访问http://192.168.0.1:9100/metrics 就能看到采集的监控指标数据了(默认暴露在metrics路径下)
prometheus:
image: prom/prometheus:latest
restart: always
container_name: prometheus
hostname: prometheus
environment:
- TZ=Asia/Shanghai
ports:
- 9090:9090
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
- '--storage.tsdb.retention.time=7d'
- '--web.external-url=prometheus'
volumes:
- /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/promdata:/prometheus
此docker-compose默认为一个service就可以省去services了
参数介绍:
/opt/prometheus/prometheus.yml(注意此处为宿主机目录)配置文件示例:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'node-exporter'
static_configs:
- targets: ['192.168.0.1:9100']
labels:
host: myhost01
##job_name 说明prometheus需要采集哪些job以及从哪里采集,上面说到默认暴露在metrices路径下,prometheus默认也是去metrices路径下拉取指标,添加label prometheus就会在此处配置的exporter采集的所有监控指标数据里面添加一个标签为host:myhost01,当服务器需要有一些值来说明时,这个非常有用
docker-compose -f prometheus.yaml up -d 启动容器,浏览器访问http://192.168.0.1:9090/prometheus 就能看到prometheus的原生控制台了
grafana:
image: grafana/grafana:latest
restart: always
container_name: grafana
hostname: grafana
environment:
- TZ=Asia/Shanghai
volumes:
# - /opt/grafana/defaults.ini:/etc/grafana/grafana.ini
- /data/grafana:/var/lib/grafana
ports:
- 3000:3000
docker-compose -f grafana.yaml up -d 启动grafana,配置文件/opt/grafana/defaults.ini此处注释掉了,如果后续有一些基于配置文件的频繁改动,可以把容器中的配置文件/etc/grafana/grafana.ini ,docker cp 出来在放到宿主机/opt/grafana/defaults.ini此处,然后docker-compose -f grafana.yaml up -d重启启动容器即可。
浏览器访问http://192.168.0.1:3000 即可进去grafana登录页面,默认登陆账号密码为admin/admin,首次登陆会强制要求改密码

点击此处添加prometheus数据源

我们选择prometheus
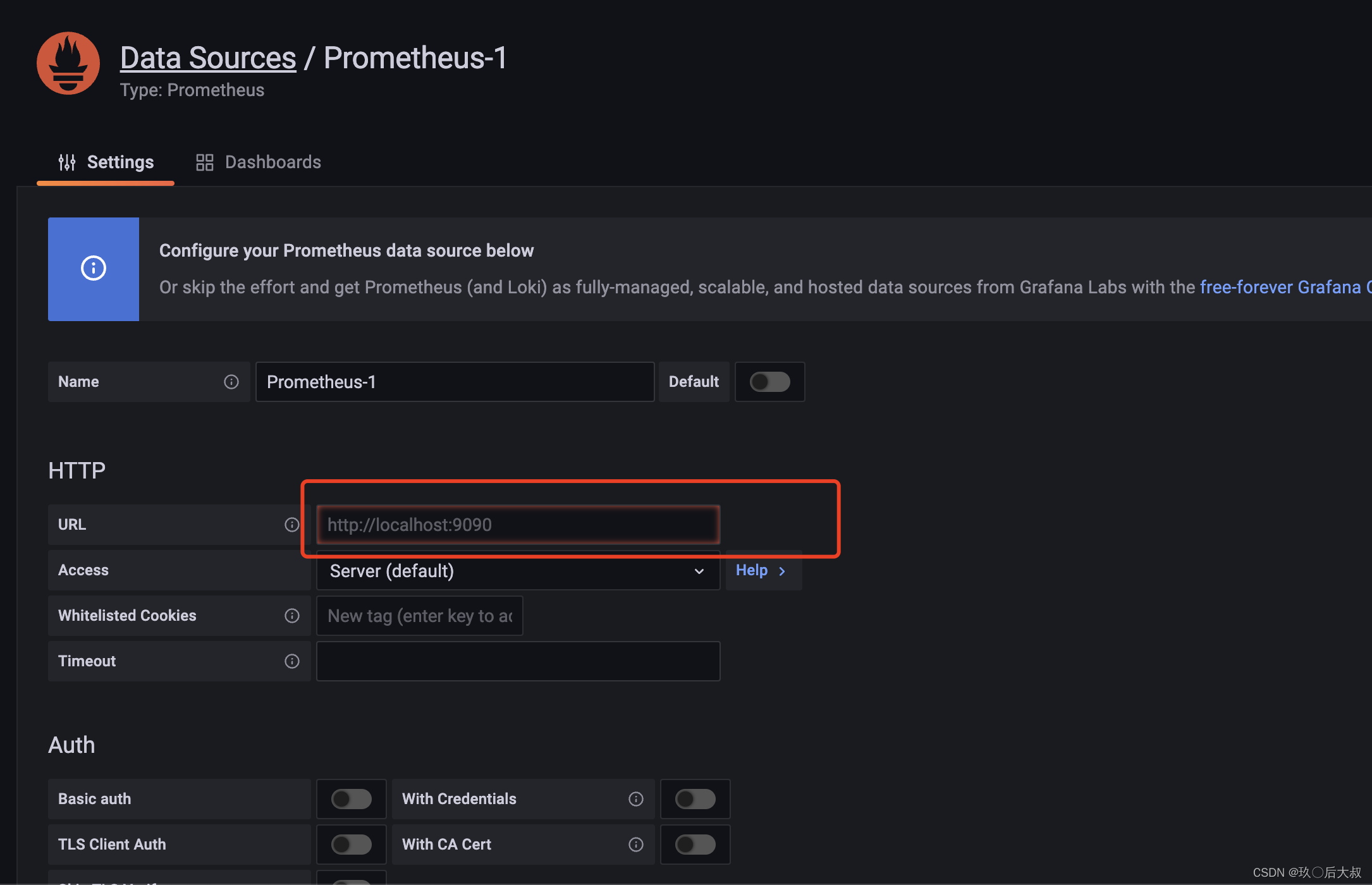
这一页我们只需填写我们的prmetheus地址即可,其他保持默认就可以了,prometheus地址填写http://192.168.0.1:9090(注意如果prometheus启动yaml文件中配置了–web.external-url=prometheus,那么此处应该为http://192.168.0.1:9090/prometheus,否则获取不到数据源)

点击save & test
下面我们导入一个node-exporter的监控面板,监控面板在grafana中其实就是一个json文件,grafana官网有很多面板,每一个面板在官网有一个id,并提供了面板json文件的下载
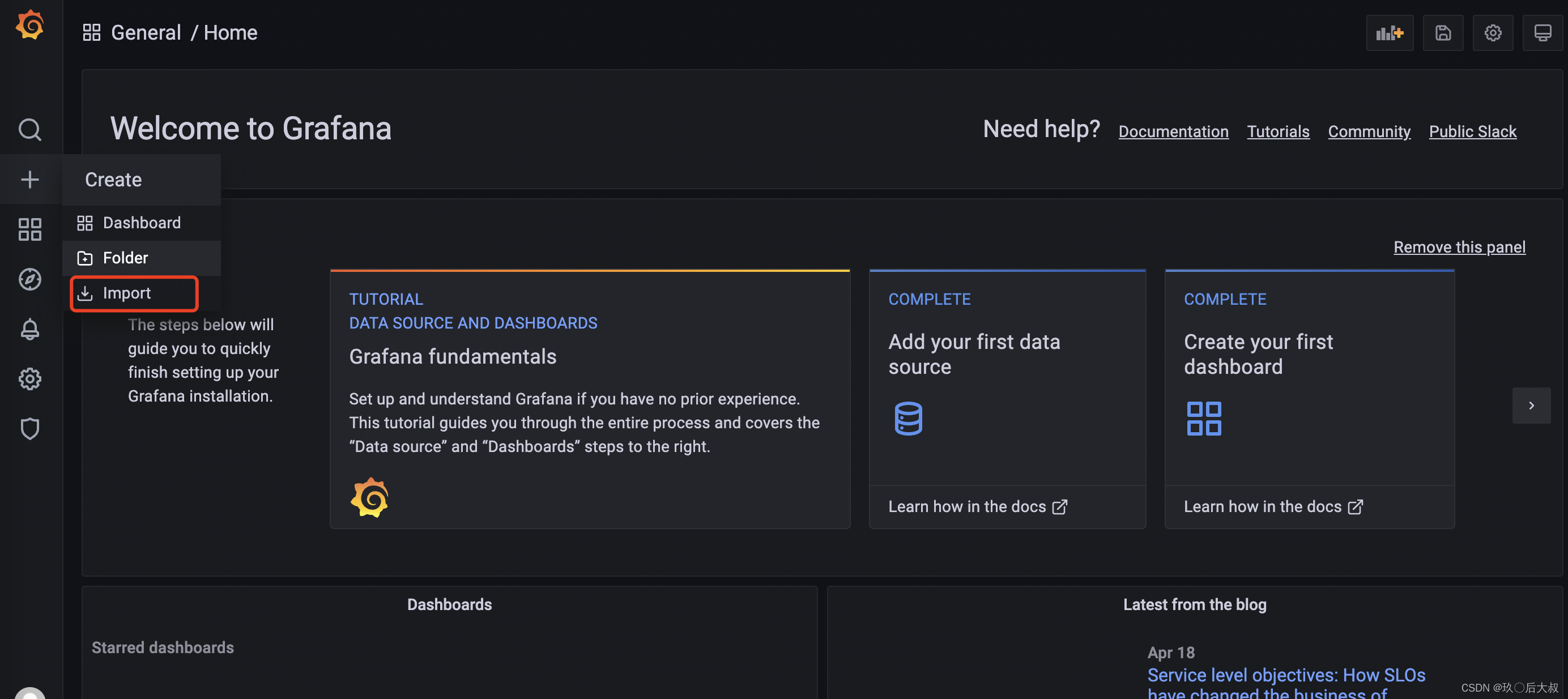
进入grafana 首页,点击import
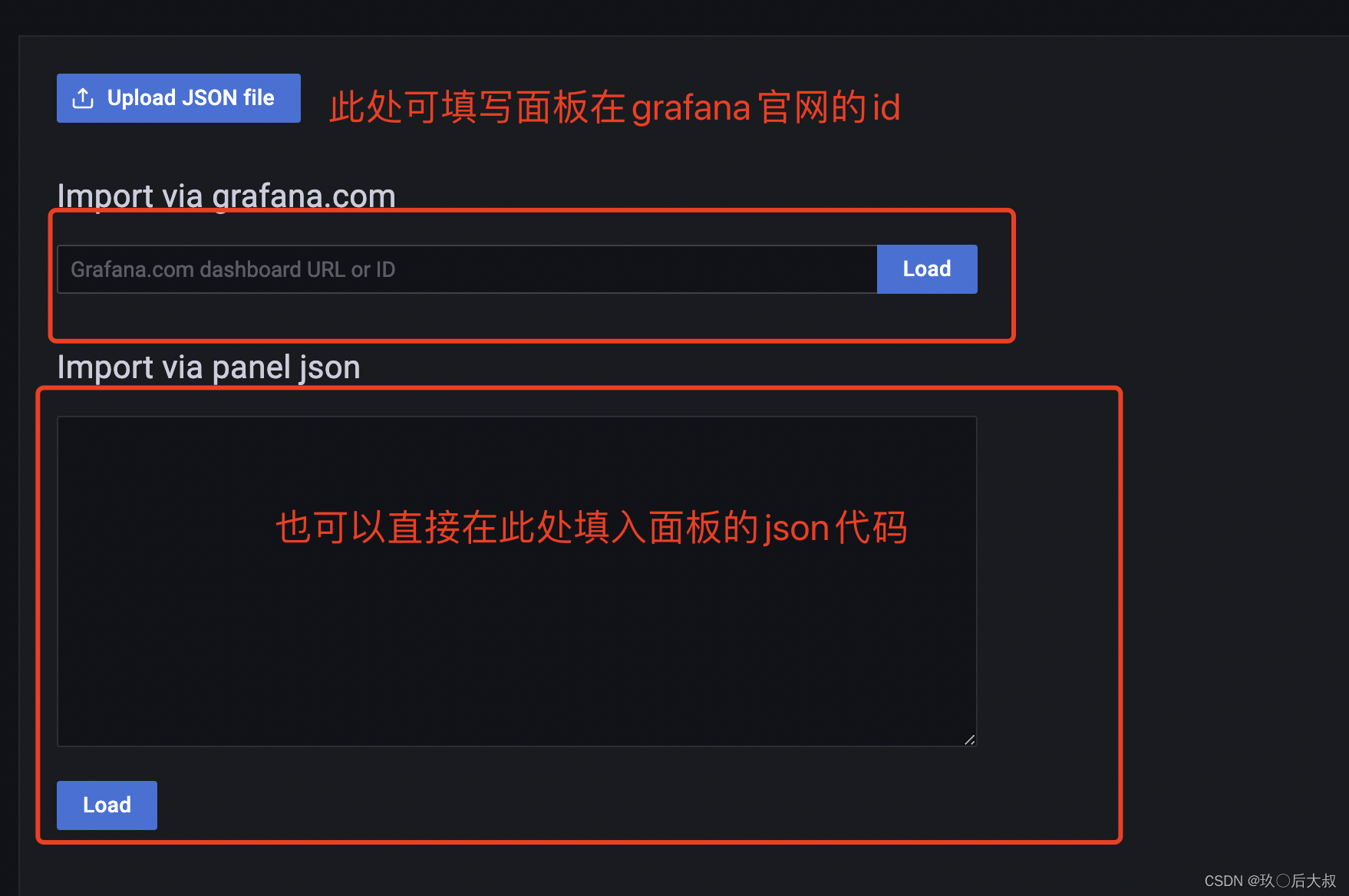
garafan 面板官网:https://grafana.com/grafana/dashboards/
当你的服务器可以连接外网,填入面板id即可,如果服务器不能联通外网,我们就需要去官网下载面板json文件进行导入
此处我们填入面板id:8919

导入完成后点击左上角图标进去首页然后点击此处我们就可以选择我们具体查看那个面板啦(如果面板比较多的话),点击我们刚刚选择的面板,就可以看到监控啦

监控的思考:
下边介绍报警搭建,如果觉得写得还不错,点个赞,你的举手之劳是我强大的动力。
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
我是Cucumber测试的新手。我创建了两个特征文件:events.featurepartner.feature并将我的步骤定义放在step_definitions文件夹中:./step_definitions/events.rbpartner.rbCucumber似乎在所有.rb文件中查找步骤信息。有没有办法限制该功能查看特定的步骤定义文件?我之所以要这样做,是因为即使我使用了--guess标志,我也会遇到不明确的匹配错误。我之所以要这样做,有以下几个原因。我正在测试CMS,并希望在不同的功能中测试每种不同的内容类型(事件和合作伙伴)。事件.特征Feature:AddpartnerA
我在下面有一个步骤定义,它执行我想要它执行的操作,即它根据“PAGES”哈希的“page”元素检查页面的url。Then(/^Ishould(still)?beatthe"(.*)"page$/)do|still,page|BROWSER.url.should==PAGES[page]end步骤定义用于两者我应该在...页面我应该还在...页面但是,我不需要将“still”传递到block中。我只需要它是可选的以匹配步骤但不传递到block中。我该怎么做?谢谢。 最佳答案 您想将“静止”组标记为非捕获。这是通过使用?:启动组来完成的
在我的mac上安装几个东西时遇到这个问题,我认为这个问题来自将我的豹子升级到雪豹。我认为这个问题也与macports有关。/usr/local/lib/libz.1.dylib,filewasbuiltfori386whichisnotthearchitecturebeinglinked(x86_64)有什么想法吗?更新更具体地说,这发生在安装nokogirigem时日志看起来像:xslt_stylesheet.c:127:warning:passingargument1of‘Nokogiri_wrap_xml_document’withdifferentwidthduetoproto
我们想测试cucumber的步骤定义。我们希望能够检查的一件事是我们期望失败的测试实际上失败了。为此,我们想编写我们知道会失败的场景并将它们添加到我们的测试套件中,但标记或以其他方式表示它们以便当且仅当它们失败时它们“通过”。如何解决这个问题? 最佳答案 您应该测试负面状态。失败的步骤只是通过步骤的倒数。所以做这样的事情:Then/ishouldnotbetrue/dosome_value.should_notbe_trueend这就是我进行失败测试的方式。您还可以捕获异常等,并验证block是否确实抛出该异常lambdadosom
我正在尝试使用docker运行一个Rails应用程序。通过github的sshurl安装的gem很少,如下所示:Gemfilegem'swagger-docs',:git=>'git@github.com:xyz/swagger-docs.git',:branch=>'my_branch'我在docker中添加了keys,它能够克隆所需的repo并从git安装gem。DockerfileRUNmkdir-p/root/.sshCOPY./id_rsa/root/.ssh/id_rsaRUNchmod700/root/.ssh/id_rsaRUNssh-keygen-f/root/.ss
我已经阅读了有关此主题的stackoverflow帖子以及包括APrimeronRubyMethodLookup在内的几篇文章,WhatisthemethodlookuppathinRuby.此外,我查看了RubyMetaprogramming2中的对象模型章节,在几个聊天室中询问,并做了thisredditthread。.除了学习C,我已经尽我所能来解决这个问题。如上述资源所述,这6个位置在接收对象(如fido_instance)的方法查找期间(按顺序)被检查。:fido_instance的单例类IClass(来自扩展模块)IClass(来自前置模块)类IClass(来自包含的模块)
我在Heroku上构建了一个必须在Docker容器内运行的RoR应用程序。为此,我使用officialDockerfile.因为它在Heroku中很常见,所以我需要一些附加组件才能使这个应用程序完全运行。在生产中,变量DATABASE_URL在我的应用程序中可用。但是,如果我尝试其他一些使用环境变量(在我的例子中是Mailtrap)的加载项,变量不会在运行时复制到实例中。所以我的问题很简单:如何让docker实例在Heroku上执行时知道环境变量?您可能会问,我已经知道我们可以在docker-compose.yml中指定一个environment指令。我想避免这种情况,以便能够通过项目