需要源码和数据集请点赞关注收藏后评论区留言私信~~~
QA问答是Question-and-Answer的缩写,根据用户提出的问题检索答案,并用用户可以理解的自然语言回答用户,问答型客服注重一问一答处理,侧重知识的推理。
从应用领域视角,可将问答系统分为限定域问答系统和开放域问答系统。
根据支持问答系统产生答案的文档库、知识库,以及实现的技术分类,可分为自然语言的数据库问答系统、对话式问答系统、阅读理解系统、基于常用问题集的问答系统、基于知识库的问答系统等。
典型的问答系统包含问题输入 问题理解 信息检索 信息抽取 答案排序 答案生成和结果输出等,首先由用户提出问题,检索操作通过在知识库中查询得到相关信息,并依据特定规则从提取到的信息中抽取相应的候选答案特征向量,最后筛选候选答案结果输出给用户

1: 问题处理 问题处理流程识别问题中包含的信息,判断问题的主题信息和主题范畴归属,比如是属于一般类问题还是属于特定主题类问题,然后提取与主题相关的关键信息,比如人物信息、地点信息和时间信息等。
2 :问题映射 根据用户咨询的问题,进行问题映射消除歧义。通过字符串相似度匹配和同义词表等解决映射问题,根据需要执行拆分和合并操作。
3 :查询构建 通过对输入问题进行处理,将问题转化为计算机可以理解的查询语言,然后查询知识图谱或者数据库,通过检索获得相应备选答案。
4 :知识推理 根据问题属性进行推理,问题基本属性如果属于知识图谱或者数据库中的已知定义信息,则可以从知识图谱或者数据库中查找,直接返回答案。如果问题属性是未定义类问题,则需要通过机器算法推理生成答案。
5: 消岐排序 根据知识图谱中查询返回的一个或者多个备选答案,结合问题属性进行消歧处理和优先级排序,输出最佳答案。
定制性智能客服程序一般需要实现选择语料库,去除噪声信息后 根据算法对预料进行训练,最后提供人机接口问答对话,基于互联网获得的医学语料库,并通过余弦相似度基本原理,设计并开发以下问答型智能医疗客服应用程序
项目结构如下

下面是csv文件中定义的一些病例

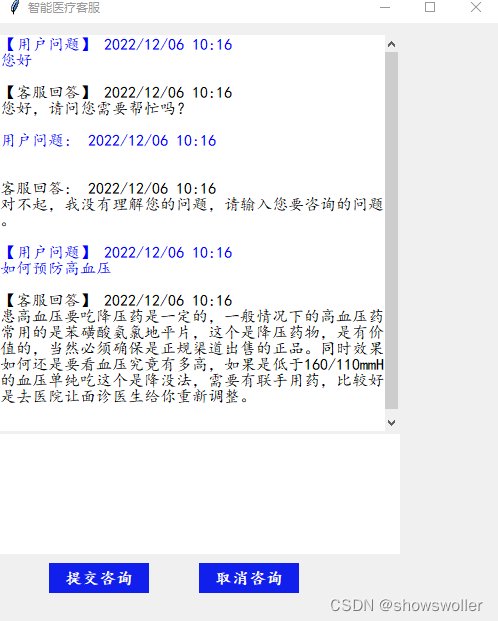
预先定义好的欢迎语句


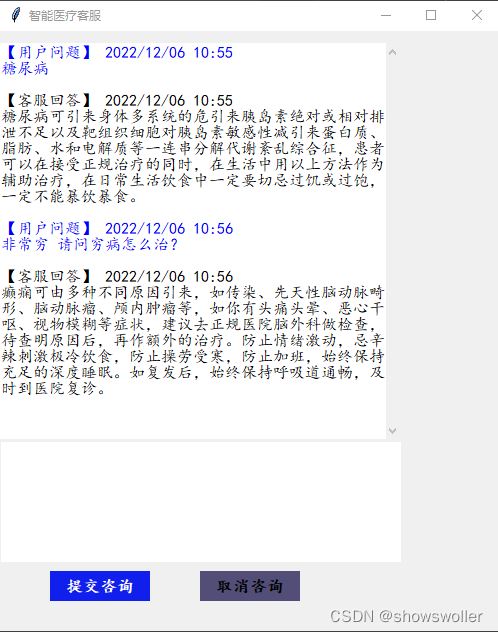
运行chatrobot文件 弹出以下窗口 输出问题后点击提交咨询即可

对于语料库中没有的问题会自动推断给出答案(通常不太准确)
部分代码如下 全部代码和数据集请点赞关注收藏后评论区留言私信
# -*- coding:utf-8 -*-
from fuzzywuzzy import fuzz
import sys
import jieba
import csv
import pickle
print(sys.getdefaultencoding())
import logging
from fuzzywuzzy import fuzz
import math
from scipy import sparse
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from scipy.sparse import lil_matrix
from sklearn.naive_bayes import MultinomialNB
import warnings
from tkinter import *
import time
import difflib
from collections import Counter
import numpy as np
filename = 'label.csv'
def tokenization(filename):
corpus = []
label = []
question = []
answer = []
with open(filename, 'r', encoding="utf-8") as f:
data_corpus = csv.reader(f)
next(data_corpus)
for words in data_corpus:
word = jieba.cut(words[1])
tmp = ''
for x in word:
tmp += x
corpus.append(tmp)
question.append(words[1])
label.append(words[0])
answer.append(words[2])
with open('corpus.h5','wb') as f:
pickle.dump(corpus,f)
with open('label.h5','wb') as f:
pickle.dump(label,f)
with open('question.h5', 'wb') as f:
pickle.dump(question, f)
with open('answer.h5', 'wb') as f:
pickle.dump(answer, f)
return corpus,label,question,answer
def train_model():
with open('corpus.h5','rb') as f_corpus:
corpus = pickle.load(f_corpus)
with open('label.h5','rb') as f_label:
label = pickle.load(f_label,encoding='bytes')
vectorizer = CountVectorizer(min_df=1)
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
words_frequency = vectorizer.fit_transform(corpus)
word = vectorizer.get_feature_names()
saved = tfidf_calculate(vectorizer.vocabulary_,sparse.csc_matrix(words_frequency),len(corpus))
model = MultinomialNB()
model.fit(tfidf,label)
with open('model.h5','wb') as f_model:
pickle.dump(model,f_model)
with open('idf.h5','wb') as f_idf:
pickle.dump(saved,f_idf)
return model,tfidf,label
class tfidf_calculate(object):
def __init__(self,feature_index,frequency,docs):
self.feature_index = feature_index
self.frequency = frequency
self.docs = docs
self.len = len(feature_index)
def key_count(self,input_words):
keys = jieba.cut(input_words)
count = {}
for key in keys:
num = count.get(key, 0)
count[key] = num + 1
return count
def getTfidf(self,input_words):
count = self.key_count(input_words)
result = lil_matrix((1, self.len))
frequency = sparse.csc_matrix(self.frequency)
for x in count:
word = self.feature_index.get(x)
if word != None and word>=0:
word_frequency = frequency.getcol(word)
feature_docs = word_frequency.sum()
tfidf = count.get(x) * (math.log((self.docs+1) / (feature_docs+1))+1)
result[0, word] = tfidf
return result
if __name__=="__main__":
tokenization(filename)
train_model()
创作不易 觉得有帮助请点赞关注收藏~~~
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit