本文是对ChatGPT的由来、训练过程以及实际落地场景的解释,主要内容包括如下三个方面:
1、ChatGPT是什么
2、ChatGPT的原理
3、ChatGPT的思考
4、ChatGPT的应用

ChatGPT可能是近期深度学习领域,讨论非常频繁的一个概念。但ChatGPT到底是一个什么,怎么给出一个定义呢。可以看下ChatGPT对自己的定义,如下图:
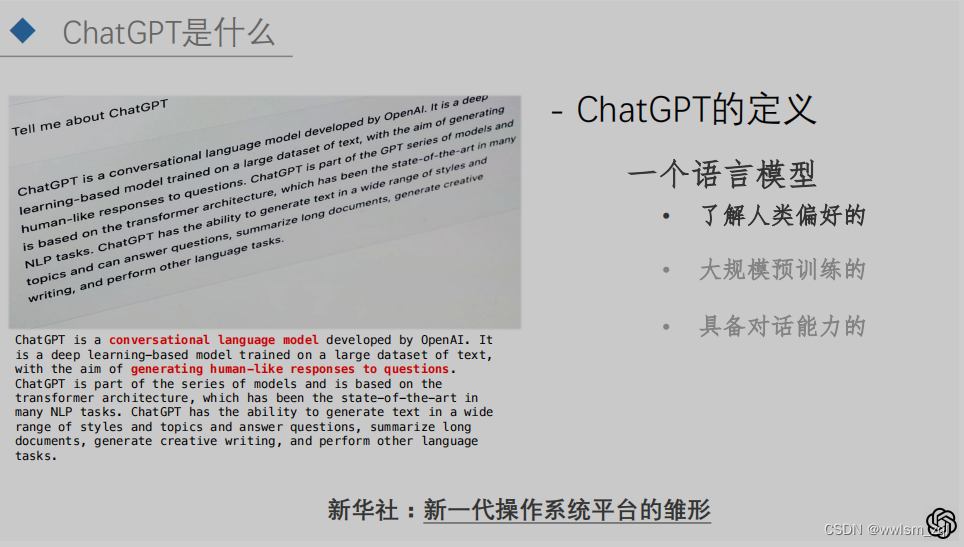
从定义以及我们使用过程中的感受,可以得到如下的结论:
对此,新华社也给出了“新一代操作系统平台的雏形的”评价,可见ChatGPT的横空出世确实带来了一些改变。
模型具有对话能力不是很新奇的事,之前腾讯的混元、百度的ERNIE等大模型都具备对话能力,让ChatGPT出圈并持续火爆的是ChatGPT在如下的测试中也取得了让人惊讶的成绩:

上述的测试不是简单的对话能够解决的,但ChatGPT同样表现得非常出彩,那为什么ChatGPT能够这么优秀?
过往大模型的发展方向,不外乎:更多的数据、更大的模型结构、更精细的处理方式以及更统一的输入输出等等。但这样训练的大模型,更像是一个图书馆,或者搜索引擎,只具备知识的储存能力和简单的检索能力。
我们以“女朋友生气了怎么办”这个问题为例,过往大模型从网络数据中经过预训练,得到许许多多的答案:你也生气;讲道理;沉默是金;快速认错……但具体哪个答案更符合人类的偏好和认知,模型是不知道的,模型只能根据网络上答案给出反馈。
但可能上述的答案上下文是故意作答、心理测试题、乱写等等情况下的答案,但这些过往的大模型是不知道的。
所以历史的大模型,在训练和使用阶段是没有人工参与的,没有学习到人类的认知和偏好:仅仅是历史数据(网络数据)是存储和检索。

ChatGPT出世前,OpenAI已经进行了一系列的探索,包括生成代码的codex系列和text-davinci系列。这一系列模型的探索过程,构成了指示学习,和RLHF学习方式叠加后,ChatGPT模型才终于横空出世。
监督学习+人工反馈+强化学习 -> ChatGPT
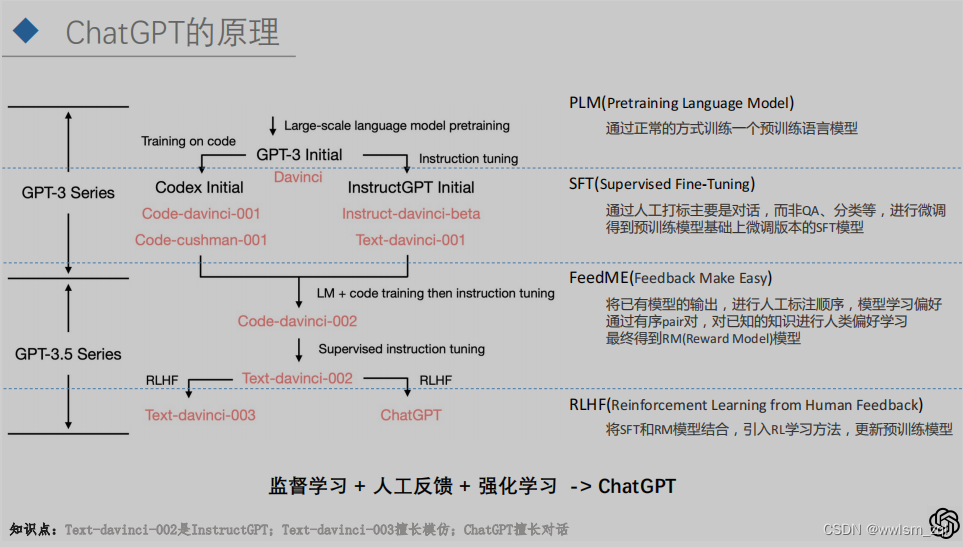
从OpenAI的官方博客,可以看出InstrctGPT和ChatGPT的训练过程如下,存在的差异非常细微:

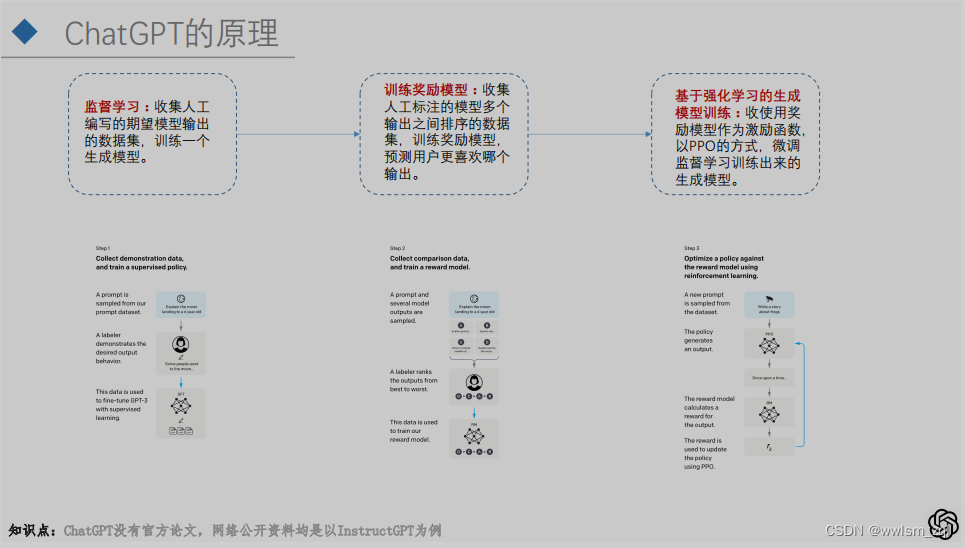
整体的训练思路,InstrctGPT和ChatGPT是相同的,均包括三个步骤:
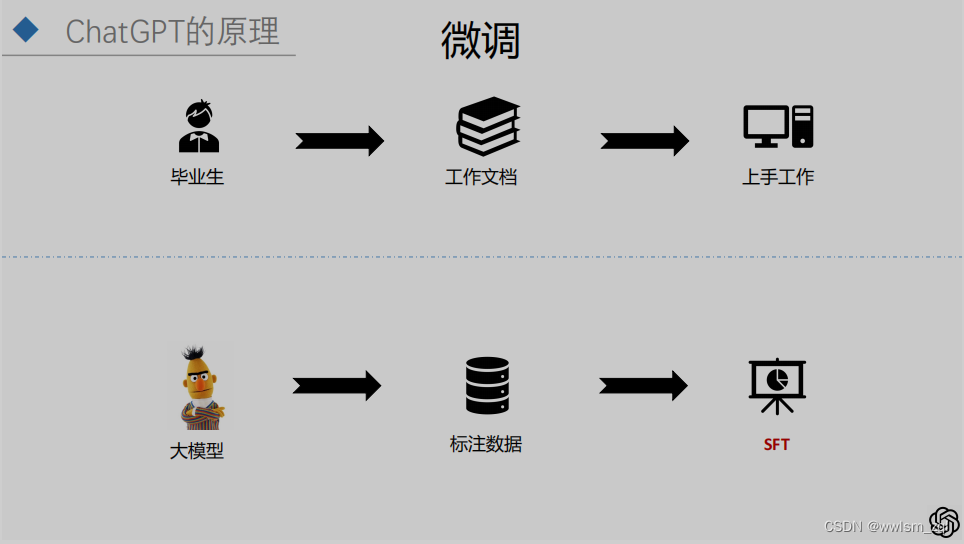
训练过程的第一步:微调。问题来源于早起的Platground的API,人工对问题进行答案的生成。和其他大模型的微调过程是一样的。
这一步的目的是得到后续优化的基模型,以及在强化学习过程中,提供损失函数的约束。

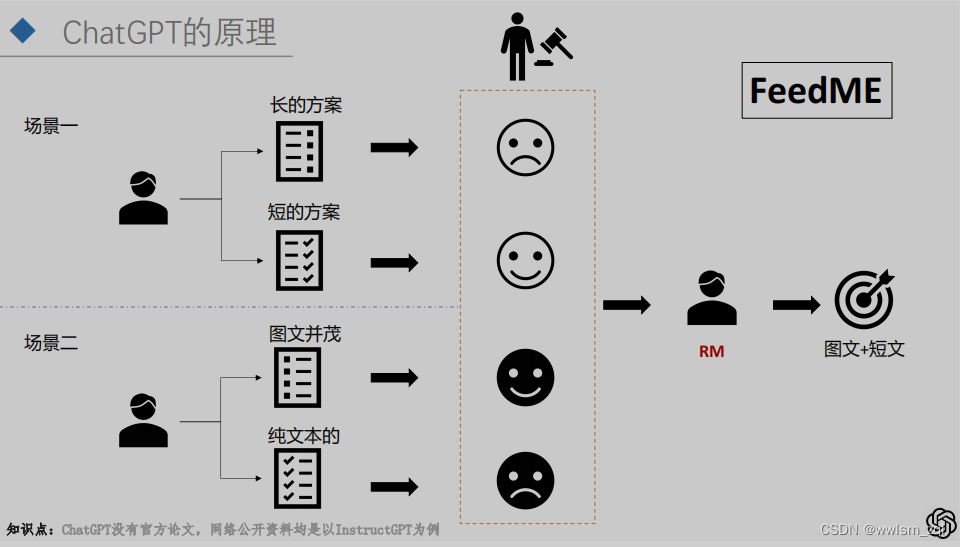
训练过程第二步:RM模型。在已经微调的SFT模型上,通过同一个问题的不同输出,进行人工优劣得分的标注,生成对应的序列。
例如对于问题P,得到的答案为A、B、C和D,人工对答案进行排序为:D>C>B=A,通过模型学习人工排序的结果。也就是让模型模仿人类排序的过程:对SFT模型的输出能够给出优劣的判断。
GPT是字粒度的输出,输出过程的每一步都是在概率分布上的采样,因此,同一个问题多次输入后,会得到不同的输出

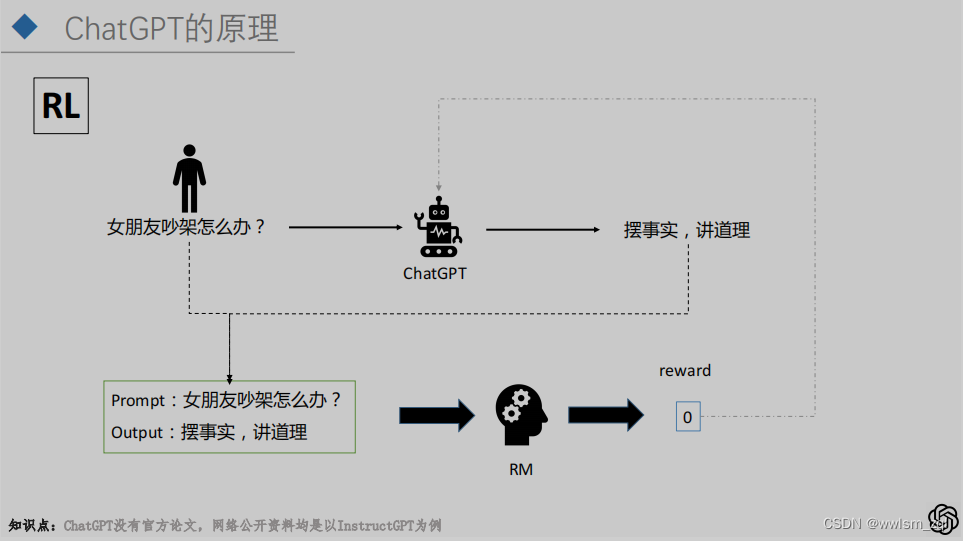
训练过程第三部:PPO策略的强化学习。在已有的SFT模型和RM模型上,结合PPO策略的强化学习,获得最终的ChatGPT/InstrctGPT。该步的大概流程如下:
通过损失函数可以看出,在实际的训练过程中,RM模型和最终的目标模型,均存在参数的更新

上面的三个步骤,就是InstrctGPT/ChatGPT的大概训练流程。总结起来就是下图:
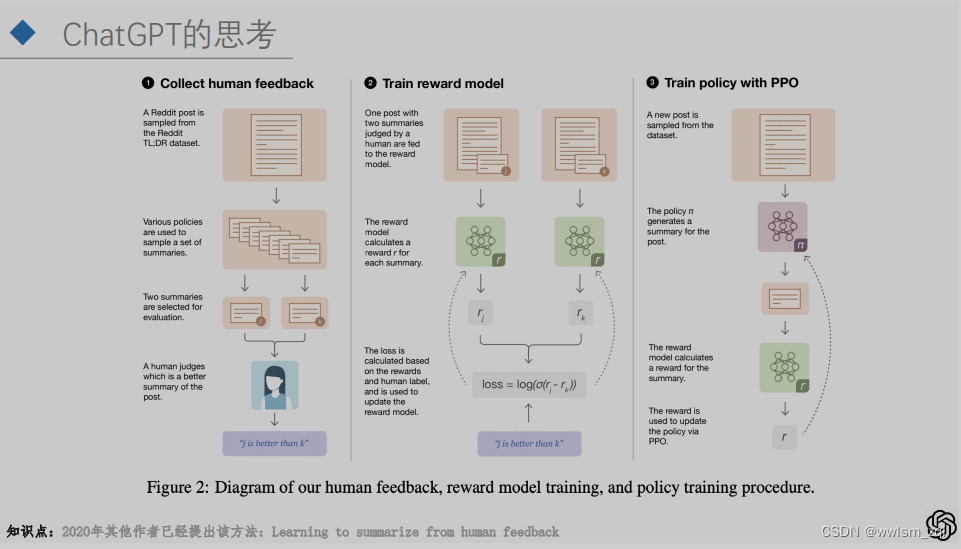
将人类的偏好和认知引入模型训练,并不是ChatGPT或者OpenAI的首创,在2020年一篇做摘要的论文就提出了该思想。只能说是OpenAI的“钞能力”将该方法发扬光大了。
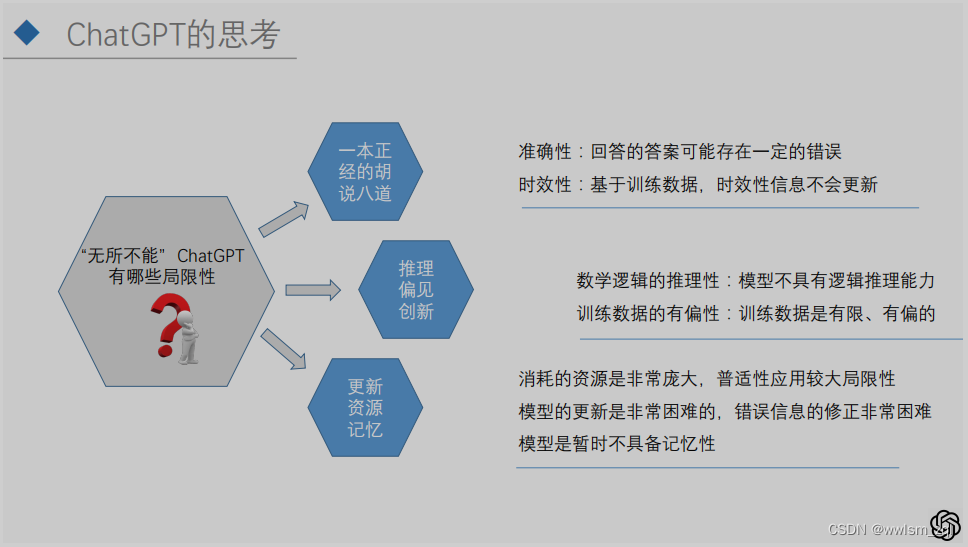
针对ChatGPT,目前其在聊天、翻译、脚本、代码、文案……等诸多领域已经崭露头角了,在ChatGPT表现其“无所不能”的同时,我们也可以考虑下其目前存在的问题有哪些呢。
目前来说,
随着ChatGPT的爆火,也带来了一些实际的落地应用,例如下面的几个应用,都是非常有意思的:


总的来说,期待ChatGPT后续的表现。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport: