当一个模块被另一个模块引用例化时,高层模块可以对低层模块的参数值进行改写。这样就允许在编译时将不同的参数传递给多个相同名字的模块,而不用单独为只有参数不同的多个模块再新建文件。
参数覆盖有 2 种方式:1)使用关键字 defparam,2)带参数值模块例化。
可以用关键字 defparam 通过模块层次调用的方法,来改写低层次模块的参数值。
例如对一个单口地址线和数据线都是 4bit 宽度的 ram 模块的 MASK 参数进行改写:
//instantiation
defparam u_ram_4x4.MASK = 7 ;
ram_4x4 u_ram_4x4
(
.CLK (clk),
.A (a[4-1:0]),
.D (d),
.EN (en),
.WR (wr), //1 for write and 0 for read
.Q (q) );
ram_4x4 的模型如下:
module ram_4x4
(
input CLK ,
input [4-1:0] A ,
input [4-1:0] D ,
input EN ,
input WR , //1 for write and 0 for read
output reg [4-1:0] Q );
parameter MASK = 3 ;
reg [4-1:0] mem [0:(1<<4)-1] ;
always @(posedge CLK) begin
if (EN && WR) begin
mem[A] <= D & MASK;
end
else if (EN && !WR) begin
Q <= mem[A] & MASK;
end
end
endmodule
对此进行一个简单的仿真,testbench 编写如下:
`timescale 1ns/1ns
module test ;
parameter AW = 4 ;
parameter DW = 4 ;
reg clk ;
reg [AW:0] a ;
reg [DW-1:0] d ;
reg en ;
reg wr ;
wire [DW-1:0] q ;
//clock generating
always begin
#15 ; clk = 0 ;
#15 ; clk = 1 ;
end
initial begin
a = 10 ;
d = 2 ;
en = 'b0 ;
wr = 'b0 ;
repeat(10) begin
@(negedge clk) ;
en = 1'b1;
a = a + 1 ;
wr = 1'b1 ; //write command
d = d + 1 ;
end
a = 10 ;
repeat(10) begin
@(negedge clk) ;
a = a + 1 ;
wr = 1'b0 ; //read command
end
end // initial begin
//instantiation
defparam u_ram_4x4.MASK = 7 ;
ram_4x4 u_ram_4x4
(
.CLK (clk),
.A (a[AW-1:0]),
.D (d),
.EN (en),
.WR (wr), //1 for write and 0 for read
.Q (q)
);
//stop simulation
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
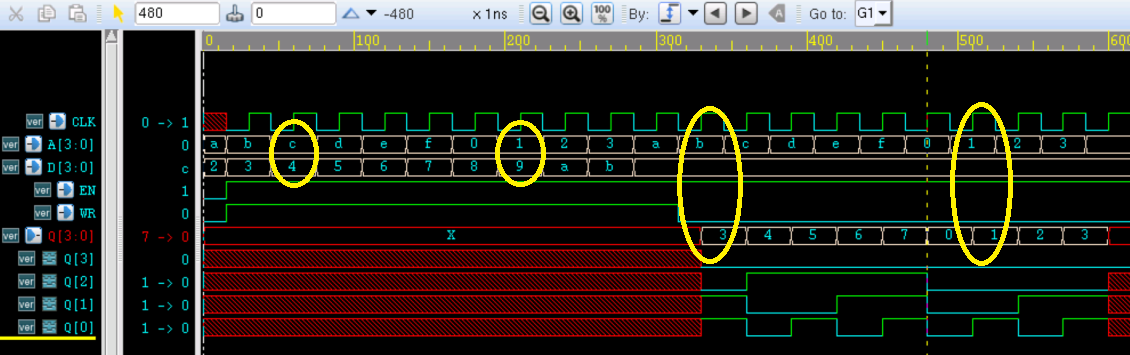
仿真结果如下:
图中黄色部分,当地址第一次为 c 时写入数据 4, 当第二次地址为 c 时读出数据为 4;可知此时 ram 行为正确,且 MASK 不为 3。 因为 ram 的 Q 端 bit2 没有被屏蔽。
当第一次地址为 1 时写入数据为 9,第二次地址为 1 时读出的数据却是 1,因为此时 MASK 为 7,ram 的 Q 端信号 bit3 被屏蔽。由此可知,MASK 参数被正确改写。
第二种方法就是例化模块时,将新的参数值写入模块例化语句,以此来改写原有 module 的参数值。
例如对一个地址和数据位宽都可变的 ram 模块进行带参数的模块例化:
ram #(.AW(4), .DW(4))
u_ram
(
.CLK (clk),
.A (a[AW-1:0]),
.D (d),
.EN (en),
.WR (wr), //1 for write and 0 for read
.Q (q)
);
ram 模型如下:
module ram
#( parameter AW = 2 ,
parameter DW = 3 )
(
input CLK ,
input [AW-1:0] A ,
input [DW-1:0] D ,
input EN ,
input WR , //1 for write and 0 for read
output reg [DW-1:0] Q
);
reg [DW-1:0] mem [0:(1<<AW)-1] ;
always @(posedge CLK) begin
if (EN && WR) begin
mem[A] <= D ;
end
else if (EN && !WR) begin
Q <= mem[A] ;
end
end
endmodule
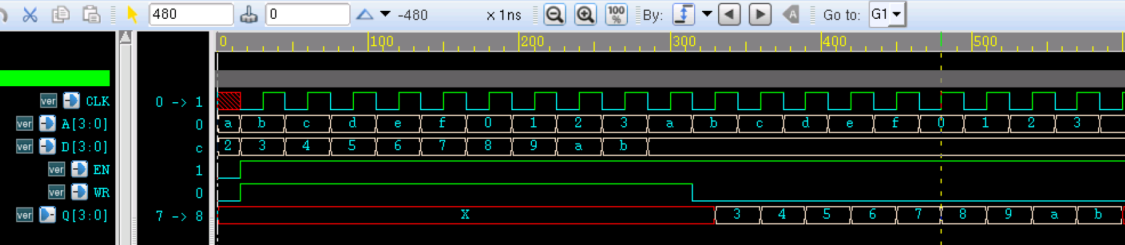
仿真时,只需在上一例的 testbench 中,将本次例化的模块 u_ram 覆盖掉 u_ram_4x4, 或重新添加之即可。
仿真结果如下。由图可知,ram 模块的参数 AW 与 DW 均被改写为 4, 且 ram 行为正确。
(1) 和模块端口实例化一样,带参数例化时,也可以不指定原有参数名字,按顺序进行参数例化,例如 u_ram 的例化可以描述为:
ram #(4, 4) u_ram (......) ;
(2) 当然,利用 defparam 也可以改写模块在端口声明时声明的参数,利用带参数例化也可以改写模块实体中声明的参数。例如 u_ram 和 u_ram_4x4 的例化分别可以描述为:
defparam u_ram.AW = 4 ;
defparam u_ram.DW = 4 ;
ram u_ram(......);
ram_4x4 #(.MASK(7)) u_ram_4x4(......);
(3) 那能不能混合使用这两种模块参数改写的方式呢?当然能!前提是所有参数都是模块在端口声明时声明的参数或参数都是模块实体中声明的参数,例如 u_ram 的声明还可以表示为(模块实体中参数可自行实验验证):
defparam u_ram.AW = 4 ;
ram #(.DW(4)) u_ram (......); //也只有我这么无聊才会实验这种写法
(4) 那如果一个模块中既有在模块在端口声明时声明的参数,又有在模块实体中声明的参数,那这两种参数还能同时改写么?例如在 ram 模块中加入 MASK 参数,模型如下:
module ram
#( parameter AW = 2 ,
parameter DW = 3 )
(
input CLK ,
input [AW-1:0] A ,
input [DW-1:0] D ,
input EN ,
input WR , //1 for write and 0 for read
output reg [DW-1:0] Q );
parameter MASK = 3 ;
reg [DW-1:0] mem [0:(1<<AW)-1] ;
always @(posedge CLK) begin
if (EN && WR) begin
mem[A] <= D ;
end
else if (EN && !WR) begin
Q <= mem[A] ;
end
end
endmodule
此时再用 defparam 改写参数 MASK 值时,编译报 Error:
//都采用defparam时会报Error
defparam u_ram.AW = 4 ;
defparam u_ram.DW = 4 ;
defparam u_ram.MASK = 7 ;
ram u_ram (......);
//模块实体中parameter用defparam改写也会报Error
defparam u_ram.MASK = 7 ;
ram #(.AW(4), .DW(4)) u_ram (......);
重点来了!!!如果你用带参数模块例化的方法去改写参数 MASK 的值,编译不会报错,MASK 也将被成功改写!
ram #(.AW(4), .DW(4), .MASK(7)) u_ram (......);
可能的解释为,在编译器看来,如果有模块在端口声明时的参数,那么实体中的参数将视为 localparam 类型,使用 defparam 将不能改写模块实体中声明的参数。
也可能和编译器有关系,大家也可以在其他编译器上实验。
(5)建议,对已有模块进行例化并将其相关参数进行改写时,不要采用 defparam 的方法。除了上述缺点外,defparam 一般也不可综合。
(6)而且建议,模块在编写时,如果预知将被例化且有需要改写的参数,都将这些参数写入到模块端口声明之前的地方(用关键字井号 # 表示)。这样的代码格式不仅有很好的可读性,而且方便调试。
其实,介绍到这里,大家完全可以用前面学习到的 Verilog 语言知识,去搭建硬件电路的小茅草屋。对,是小茅草屋。因为硬件语言对应实际硬件电路的这种特殊性,在用 Verilog 建立各种模型时必须考虑实际生成的电路是什么样子的,是否符合实际要求。有时候 rtl 仿真能通过,但是最后生成的实际电路可能会工作异常。
所以,要为你的小茅草屋添砖盖瓦,还需要再学习下进阶部分。当然,进阶部分也只能让你的小茅草屋变成硬朗的砖瓦房,能抵挡风雪交加,可能遇到地震还是会垮塌。
如果你想巩固下你的砖瓦房,去建一套别墅,那你需要再学习下 Verilog 高级篇知识,例如 PLI(编程语言接口)、UDP(用户自定义原语),时序约束和时序分析等,还需要多参与项目工程积累经验,特别注意一些设计技巧,例如低功耗设计、异步设计等。当然学会用 SystemVerilog 去全面验证,又会让你的建筑增加一层防护盾。
但是如果你想把数字电路、Verilog 所有的知识学完,去筑一套防炮弹的总统府,那真的是爱莫能助。因为,学海无涯,回头没岸哪。
限于篇幅,这里只介绍下进阶篇。有机会,高级篇,技巧篇,也一并补上。
目录一、inout在设计文件中的使用方法1.1、inout的第一种使用方法1.2、inout实现的第二种使用方法1.3、inout使用总结 二、inout在仿真测试中的使用方法一、inout在设计文件中的使用方法在FPGA的设计过程中,有时候会遇到双向信号(既能作为输出,也能作为输入的信号叫双向信号)。比如,IIC总线中的SDA信号就是一个双向信号,QSPIFlash的四线操作的时候四根信号线均为双向信号。在Verilog中用关键字inout定义双向信号,这里总结一下双向信号的处理方法。1.1、inout的第一种使用方法 实际上,双向信号的本质是由一个三态门组成的,三态门可以输出高电平,低电
这道题开始于here.但随着我对雷神的了解越来越多,情况发生了很大变化。我正在尝试创建一个带参数的Thor::Group子命令。奇怪的是,如果没有参数,它就可以工作。我可以使用Thor::Group作为子命令吗?这在我输入时有效:foocounterfoo/bin/foomoduleFooclassCLI但是当我输入时这不起作用:foocounter5moduleFooclassCLI','Countupfromtheinput.')endclassCounter:numeric,:desc=>"Thenumbertostartcounting"desc"Prints2numbersb
我正在按照我一直在研究的研讨会实现“服务对象”,我正在构建一个redditAPI应用程序。我需要对象返回一些东西,所以我不能只执行初始化程序中的所有内容。我有这两个选择:选项1:类需要实例化classSubListFromUserdefuser_subscribed_subs(client)@client=client@subreddits=sort_subs_by_name(user_subs_from_reddit)endprivatedefsort_subs_by_name(subreddits)subreddits.sort_by{|sr|sr[:name].downcase}
我是Ruby新手,在Ubuntu12.04机器上安装了Ruby1.9.3。每当我在终端中不带任何参数地运行ruby命令时,它就会挂起并且什么都不做。它在我的WindowsXP安装上做同样的事情。这是预期的行为吗?来自Python/Java背景,我期待某种输出。 最佳答案 这是预料之中的。当您只运行ruby时,它会停在那里,等待来自STDIN的程序,后跟一个文件结束符,然后执行该程序。如果你想要交互,比如当你运行python时,你需要Ruby的irb。 关于ruby-使用不带参数的'rub
我有一个gem,里面有这样的代码:defread(file)@file=File.newfile,"r"end现在的问题是,假设你有一个像这样的目录结构:app/main.rbapp/templates/example.txt和main.rb有如下代码:require'mygem'example=MyGem.read('templates/example.txt')它出现了FileNotFound:templates/example.txt。如果example.txt与main.rb在同一个目录中,它会工作,但如果它在一个目录中,则不会。为了解决这个问题,我在read()中添加了一个名
如果我有4个具有以下层次结构的类:classMainClass如何在不遍历和创建每个其他类的实例的情况下获得MainClass的子类列表?在新的IRBsession中,我可以进去说irb(main)>MainClass.descendants=>[]但是,如果我遍历并创建每个子类的实例,我将看到以下内容irb(main)>SubClassA.new=>#irb(main)>SubClassB.new=>#irb(main)>SubClassC.new=>#irb(main)>MainClass.descendants=>[SubClassA(...),SubClassB(...),Su
有时,当我编写单元测试时,我需要在不调用initialize方法的情况下实例化一个类。例如,当构造函数实例化其他类时,无论如何我都会用stub替换它们。例如:classSomeClassThatIWillTestdefinitialize@client=GoogleAnalyticsClient.new@cache=SuperAdvancedCacheSystem.newend#...end在测试中,我可能会将@client和@cache替换为stub,因此我宁愿从未调用构造函数。有什么黑魔法可以帮助我解决这个问题吗? 最佳答案 当
例如,如果我有一个用户模型并且我只需要验证登录(这可能发生在通过ajax验证表单时),那么如果我使用用户模型中定义的相同模型验证而不实际实例化会很棒一个用户实例。所以在Controller中我可以编写如下代码User.valid_attribute?(:login,"loginvalue")无论如何我可以做到这一点吗? 最佳答案 由于验证是在实例上运行的(并且它们使用实例的错误属性作为错误消息的容器),所以您不能在没有实例化对象的情况下使用它们。话虽如此,您可以将此所需行为隐藏到类方法中:classUservalue)unlessm
有没有办法在包含ruby模块时使用参数?我有一个Assetable模块,它包含在许多类中。我希望能够即时生成attr_accessor。moduleAssetableextendActiveSupport::Concernincludeddo(argument).timesdo|i|attr_accessor"asset_#{i}".to_symattr_accessible"asset_#{i}".to_symendendend 最佳答案 有一个技巧:创建一个从模块继承的类,这样您就可以像类一样将任何参数传递给模块。class
根据documentationformodulesandclasses,调用super(不带参数或括号)使用相同的参数调用父方法:Whenusedwithoutanyargumentssuperusestheargumentsgiventothesubclassmethod.为“参数变量”分配一个新值似乎会改变这种行为:classMyClassdeffoo(arg)puts"MyClass#foo(#{arg.inspect})"endendclassMySubclass输出:MySubclass#foo("initalvalue")MyClass#foo("initalvalue")